index skip scan的一些實驗。
index skip scan的基本介紹。
表employees (sex, employee_id, address) ,有一個組合索引(sex, employee_id). 在索引跳躍的情況下,我們可以邏輯上把他們看成兩個索引,一個是(男,employee_id),一個是(女,employee_id).
select * from employees where employee_id=1;
發出這個查詢後,oracle先進入sex為男的入口,查詢employee_id=1的條目。再進入sex為女的入口,查詢employee_id=1的條目。
ORACLE官方說,在前導列唯一值較少的情況下,才會用到index skip can。這個其實好理解,就是入口要少。
事實上.jpg
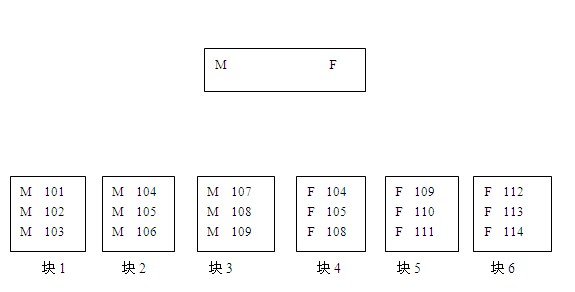
看上面的這幅圖。
我有個疑問,就是ORACLE是透過什麼樣的掃描方式找到所需要的塊的,假如我現在要查詢employee_id是109的記錄,從圖可以看出來,109的記錄存在與塊3和塊5上。但是ORACLE能透過skip scan定位到這兩個塊呢?幾種可能。
1)先找到入口M,然後從第一個塊掃起,掃到第三個塊的時候發現了109,停止掃描。然後找到入口F,從塊4掃起,掃描到塊5的時候發現了109,由於索引已經是有序的了,後面的不用再掃了。
2)先找到入口M,然後把包含M的塊都掃描一下,過濾出109的記錄。找到入口F,然後把包含F的塊都掃描一下,過濾出109的記錄
3)透過根節點和分支節點的資訊,非常精準的一下子定位到這兩個塊上。
到底是那一種呢?
看下面的實驗。
SQL> create table wxh_tbd as select * from dba_objects;
表已建立。
SQL> update wxh_tbd set object_id=1 where object_id in
2 (select object_id from (select min(object_id) object_id ,owner from wxh_tbd group by owner));
已更新18行。
SQL> commit;
提交完成。
SQL> update wxh_tbd set object_id=100000000 where object_id in
2 (select object_id from (select max(object_id) object_id ,owner from wxh_tbd group by owner));
已更新18行。
SQL> commit;
SQL> create index t on wxh_tbd(owner,object_id);
索引已建立。
我的這個測試庫裡一共有18個schema,透過上面的步驟,我們做到了每個schema下面有一個最小的object_id 即1,一個最大的object_id即100000000.透過以下兩個語句的邏輯讀我們就可以知道,ORACLE到底是透過三種方式裡的哪種來定位塊了。
select /*+ index_ffs(wxh_tbd) */ count(*) from wxh_tbd where object_id=1;
select count(*) from wxh_tbd where object_id=1;
select count(*) from wxh_tbd where object_id=100000000;
實驗1)看看如果是採用的index fast scan大概需要多少邏輯讀。(這種情況下的邏輯讀與上面提到的方法三應該差別不大)
SQL> set autotrace trace stat
SQL> select /*+ index_ffs(wxh_tbd) */ count(*) from wxh_tbd where object_id=1;
統計資訊
----------------------------------------------------------
0 recursive calls
0 db block gets
156 consistent gets
實驗2)object_id為1的時候SQL> select count(*) from wxh_tbd where object_id=1;
執行計劃
----------------------------------------------------------
Plan hash value: 2915554405
-------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 5 | 19 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 5 | | |
|* 2 | INDEX SKIP SCAN| T | 1 | 5 | 19 (0)| 00:00:01 |
-------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OBJECT_ID"=1)
filter("OBJECT_ID"=1)
統計資訊
----------------------------------------------------------
0 recursive calls
0 db block gets
14 consistent gets
實驗3)看看object_id為100000000的時候的邏輯讀。
SQL> select count(*) from wxh_tbd where object_id=100000000;
執行計劃
----------------------------------------------------------
Plan hash value: 2915554405
-------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 5 | 19 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 5 | | |
|* 2 | INDEX SKIP SCAN| T | 1 | 5 | 19 (0)| 00:00:01 |
-------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OBJECT_ID"=100000000)
filter("OBJECT_ID"=100000000)
統計資訊
----------------------------------------------------------
1 recursive calls
0 db block gets
14 consistent gets
如果ORACLE採用的是上面假想的方式1掃描資料塊,那麼實驗2的邏輯讀應該遠小於實驗3的邏輯讀。實驗2和實驗3的邏輯讀是相等的。這種可能性排除
如果ORACLE採用的是上面假想的方式2掃描資料塊,那麼實驗2和實驗3的邏輯讀應該都大約等於index fast full san的邏輯讀。可以是從實驗結果來看,遠不相等。
如果ORACLE採用的是上面假想的方式3掃描資料塊,那麼實驗2和實驗3的邏輯讀應該相等或接近,我們的實驗完全符合。
因此可以得出結論,ORACLE可以在SKIP SCAN中,選擇相應的入口後,可以根據某種結構(根塊?分支塊?頁塊?)精確定位到記錄的葉子塊。從中找出符合條件的記錄。
還拿這個圖為例,如果要查詢employee_id為109的條目,ORACLE進入到入口M後,直接就可以定位到塊3.而不需要掃描塊1和塊2.進入到入口F後,直接就可以定位到塊5,而不需要掃描塊4和塊6.
之所以想搞明白這個,是因為最近遇到了一個這麼的查詢,當時非常驚訝,謂詞都出現在了索引塊裡,怎麼會用到skip scan.
SQL> select count(*) from wxh_tbd where owner>'SCOTT' and object_id=5;
執行計劃
----------------------------------------------------------
Plan hash value: 2915554405
-------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 11 | 11 (10)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 11 | | |
|* 2 | INDEX SKIP SCAN| T | 1 | 11 | 11 (10)| 00:00:01 |
-------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OWNER">'SCOTT' AND "OBJECT_ID"=5 AND "OWNER" IS NOT NULL)
filter("OBJECT_ID"=5)
統計資訊
----------------------------------------------------------
1 recursive calls
0 db block gets
8 consistent gets
如果理解了上面的我所論述的,我相信理解這個就不困難了。上面的查詢對於index skip scan 是非常適合的。如果是index range的話,會掃描所有的首列大於'SCOTT'的索引,從中過濾掉object_id。而index skip的話,只需要找到大於'SCOTT'的入口,然後精確的定位到object_id即可。
表employees (sex, employee_id, address) ,有一個組合索引(sex, employee_id). 在索引跳躍的情況下,我們可以邏輯上把他們看成兩個索引,一個是(男,employee_id),一個是(女,employee_id).
select * from employees where employee_id=1;
發出這個查詢後,oracle先進入sex為男的入口,查詢employee_id=1的條目。再進入sex為女的入口,查詢employee_id=1的條目。
ORACLE官方說,在前導列唯一值較少的情況下,才會用到index skip can。這個其實好理解,就是入口要少。
事實上.jpg
看上面的這幅圖。
我有個疑問,就是ORACLE是透過什麼樣的掃描方式找到所需要的塊的,假如我現在要查詢employee_id是109的記錄,從圖可以看出來,109的記錄存在與塊3和塊5上。但是ORACLE能透過skip scan定位到這兩個塊呢?幾種可能。
1)先找到入口M,然後從第一個塊掃起,掃到第三個塊的時候發現了109,停止掃描。然後找到入口F,從塊4掃起,掃描到塊5的時候發現了109,由於索引已經是有序的了,後面的不用再掃了。
2)先找到入口M,然後把包含M的塊都掃描一下,過濾出109的記錄。找到入口F,然後把包含F的塊都掃描一下,過濾出109的記錄
3)透過根節點和分支節點的資訊,非常精準的一下子定位到這兩個塊上。
到底是那一種呢?
看下面的實驗。
SQL> create table wxh_tbd as select * from dba_objects;
表已建立。
SQL> update wxh_tbd set object_id=1 where object_id in
2 (select object_id from (select min(object_id) object_id ,owner from wxh_tbd group by owner));
已更新18行。
SQL> commit;
提交完成。
SQL> update wxh_tbd set object_id=100000000 where object_id in
2 (select object_id from (select max(object_id) object_id ,owner from wxh_tbd group by owner));
已更新18行。
SQL> commit;
SQL> create index t on wxh_tbd(owner,object_id);
索引已建立。
我的這個測試庫裡一共有18個schema,透過上面的步驟,我們做到了每個schema下面有一個最小的object_id 即1,一個最大的object_id即100000000.透過以下兩個語句的邏輯讀我們就可以知道,ORACLE到底是透過三種方式裡的哪種來定位塊了。
select /*+ index_ffs(wxh_tbd) */ count(*) from wxh_tbd where object_id=1;
select count(*) from wxh_tbd where object_id=1;
select count(*) from wxh_tbd where object_id=100000000;
實驗1)看看如果是採用的index fast scan大概需要多少邏輯讀。(這種情況下的邏輯讀與上面提到的方法三應該差別不大)
SQL> set autotrace trace stat
SQL> select /*+ index_ffs(wxh_tbd) */ count(*) from wxh_tbd where object_id=1;
統計資訊
----------------------------------------------------------
0 recursive calls
0 db block gets
156 consistent gets
實驗2)object_id為1的時候SQL> select count(*) from wxh_tbd where object_id=1;
執行計劃
----------------------------------------------------------
Plan hash value: 2915554405
-------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 5 | 19 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 5 | | |
|* 2 | INDEX SKIP SCAN| T | 1 | 5 | 19 (0)| 00:00:01 |
-------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OBJECT_ID"=1)
filter("OBJECT_ID"=1)
統計資訊
----------------------------------------------------------
0 recursive calls
0 db block gets
14 consistent gets
實驗3)看看object_id為100000000的時候的邏輯讀。
SQL> select count(*) from wxh_tbd where object_id=100000000;
執行計劃
----------------------------------------------------------
Plan hash value: 2915554405
-------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 5 | 19 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 5 | | |
|* 2 | INDEX SKIP SCAN| T | 1 | 5 | 19 (0)| 00:00:01 |
-------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OBJECT_ID"=100000000)
filter("OBJECT_ID"=100000000)
統計資訊
----------------------------------------------------------
1 recursive calls
0 db block gets
14 consistent gets
如果ORACLE採用的是上面假想的方式1掃描資料塊,那麼實驗2的邏輯讀應該遠小於實驗3的邏輯讀。實驗2和實驗3的邏輯讀是相等的。這種可能性排除
如果ORACLE採用的是上面假想的方式2掃描資料塊,那麼實驗2和實驗3的邏輯讀應該都大約等於index fast full san的邏輯讀。可以是從實驗結果來看,遠不相等。
如果ORACLE採用的是上面假想的方式3掃描資料塊,那麼實驗2和實驗3的邏輯讀應該相等或接近,我們的實驗完全符合。
因此可以得出結論,ORACLE可以在SKIP SCAN中,選擇相應的入口後,可以根據某種結構(根塊?分支塊?頁塊?)精確定位到記錄的葉子塊。從中找出符合條件的記錄。
還拿這個圖為例,如果要查詢employee_id為109的條目,ORACLE進入到入口M後,直接就可以定位到塊3.而不需要掃描塊1和塊2.進入到入口F後,直接就可以定位到塊5,而不需要掃描塊4和塊6.
之所以想搞明白這個,是因為最近遇到了一個這麼的查詢,當時非常驚訝,謂詞都出現在了索引塊裡,怎麼會用到skip scan.
SQL> select count(*) from wxh_tbd where owner>'SCOTT' and object_id=5;
執行計劃
----------------------------------------------------------
Plan hash value: 2915554405
-------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 11 | 11 (10)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 11 | | |
|* 2 | INDEX SKIP SCAN| T | 1 | 11 | 11 (10)| 00:00:01 |
-------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OWNER">'SCOTT' AND "OBJECT_ID"=5 AND "OWNER" IS NOT NULL)
filter("OBJECT_ID"=5)
統計資訊
----------------------------------------------------------
1 recursive calls
0 db block gets
8 consistent gets
如果理解了上面的我所論述的,我相信理解這個就不困難了。上面的查詢對於index skip scan 是非常適合的。如果是index range的話,會掃描所有的首列大於'SCOTT'的索引,從中過濾掉object_id。而index skip的話,只需要找到大於'SCOTT'的入口,然後精確的定位到object_id即可。
來自 “ ITPUB部落格 ” ,連結:http://blog.itpub.net/22034023/viewspace-680475/,如需轉載,請註明出處,否則將追究法律責任。
相關文章
- INDEX SKIP SCANIndex
- 理解index skip scanIndex
- index range scan,index fast full scan,index skip scan發生的條件IndexAST
- [轉貼]Skip Scan IndexIndex
- 關於INDEX SKIP SCANIndex
- 索引優化index skip scan索引優化Index
- INDEX SKIP SCAN適用場景Index
- 高效的SQL(index skip scan使用條件)SQLIndex
- oracle hint_skip scan_index_ssOracleIndex
- 跳躍式索引(Skip Scan Index)的淺析索引Index
- 跳躍式索引(Skip Scan Index)淺析 - 轉索引Index
- 【每日一摩斯】-Index Skip Scan Feature (212391.1)Index
- 跳躍式索引掃描(index skip scan) [final]索引Index
- 【TUNE_ORACLE】列出走了INDEX SKIP SCAN的SQL參考OracleIndexSQL
- INDEX UNIQUE SCAN,INDEX FULL SCAN和INDEX FAST FULL SCANIndexAST
- index fast full scan不能使用並行的實驗IndexAST並行
- [20180725]index skip-scan operation.txtIndex
- Index的掃描方式:index full scan/index fast full scanIndexAST
- mysql loose index scan的實現MySqlIndex
- oracle實驗記錄(INDEX fast full scan 的成本計算)OracleIndexAST
- rowid,index,INDEX FULL SCAN,INDEX FAST FULL SCAN|IndexAST
- Index Full Scan vs Index Fast Full ScanIndexAST
- Index Full Scan 與 Index Fast Full ScanIndexAST
- INDEX FULL SCAN和INDEX FAST FULL SCAN的區別IndexAST
- [20181201]奇怪的INDEX SKIP SCAN執行計劃.txtIndex
- index full scan 和 index fast full scan (IFS,FFS)的不同IndexAST
- INDEX FULL SCAN和INDEX FAST FULL SCAN區別IndexAST
- index full scan 和 index FAST full scan 區別IndexAST
- Index Full Scan 與 Index Fast Full Scan (Final)IndexAST
- Clustered Index Scan and Clustered Index SeekIndex
- 【INDEX_SS】使用HINT使SQL用索引跳躍掃描(Index Skip Scan)方式快速獲取資料IndexSQL索引
- skip_unusable_index parameterIndex
- Index Unique Scan (213)Index
- 關於Oracle 9i 跳躍式索引掃描(Index Skip Scan)的小測試 (轉)Oracle索引Index
- PostgreSQL DBA(119) - pgAdmin(LIMIT:Index Scan vs Bitmap Index Scan)SQLMITIndex
- Index Full Scan和Index Fast Full Scan行為差異分析(上)IndexAST
- Index Full Scan和Index Fast Full Scan行為差異分析(下)IndexAST
- Index Range Scan (214)Index