每個程式設計師都應該瞭解的 CPU 快取記憶體 英文原文:Memory part 2: CPU caches
現在的CPU比25年前要精密得多了。在那個年代,CPU的頻率與記憶體匯流排的頻率基本在同一層面上。記憶體的訪問速度僅比暫存器慢那麼一點點。但是,這一局面在上世紀90年代被打破了。CPU的頻率大大提升,但記憶體匯流排的頻率與記憶體晶片的效能卻沒有得到成比例的提升。並不是因為造不出更快的記憶體,只是因為太貴了。記憶體如果要達到目前CPU那樣的速度,那麼它的造價恐怕要貴上好幾個數量級。
如果有兩個選項讓你選擇,一個是速度非常快、但容量很小的記憶體,一個是速度還算快、但容量很多的記憶體,如果你的工作集比較大,超過了前一種情況,那麼人們總是會選擇第二個選項。原因在於輔存(一般為磁碟)的速度。由於工作集超過主存,那麼必須用輔存來儲存交換出去的那部分資料,而輔存的速度往往要比主存慢上好幾個數量級。
好在這問題也並不全然是非甲即乙的選擇。在配置大量DRAM的同時,我們還可以配置少量SRAM。將地址空間的某個部分劃給SRAM,剩下的部分劃給DRAM。一般來說,SRAM可以當作擴充套件的暫存器來使用。
上面的做法看起來似乎可以,但實際上並不可行。首先,將SRAM記憶體對映到程式的虛擬地址空間就是個非常複雜的工作,而且,在這種做法中,每個程式都需要管理這個SRAM區記憶體的分配。每個程式可能有大小完全不同的SRAM區,而組成程式的每個模組也需要索取屬於自身的SRAM,更引入了額外的同步需求。簡而言之,快速記憶體帶來的好處完全被額外的管理開銷給抵消了。因此,SRAM是作為CPU自動使用和管理的一個資源,而不是由OS或者使用者管理的。在這種模式下,SRAM用來複制儲存(或者叫快取)主記憶體中有可能即將被CPU使用的資料。這意味著,在較短時間內,CPU很有可能重複執行某一段程式碼,或者重複使用某部分資料。從程式碼上看,這意味著CPU執行了一個迴圈,所以相同的程式碼一次又一次地執行(空間區域性性的絕佳例子)。資料訪問也相對侷限在一個小的區間內。即使程式使用的實體記憶體不是相連的,在短期內程式仍然很有可能使用同樣的資料(時間區域性性)。這個在程式碼上表現為,程式在一個迴圈體內呼叫了入口一個位於另外的實體地址的函式。這個函式可能與當前指令的物理位置相距甚遠,但是呼叫的時間差不大。在資料上表現為,程式使用的記憶體是有限的(相當於工作集的大小)。但是實際上由於RAM的隨機訪問特性,程式使用的實體記憶體並不是連續的。正是由於空間區域性性和時間區域性性的存在,我們才提煉出今天的CPU快取概念。
我們先用一個簡單的計算來展示一下快取記憶體的效率。假設,訪問主存需要200個週期,而訪問快取記憶體需要15個週期。如果使用100個資料元素100次,那麼在沒有快取記憶體的情況下,需要2000000個週期,而在有快取記憶體、而且所有資料都已被快取的情況下,只需要168500個週期。節約了91.5%的時間。
用作快取記憶體的SRAM容量比主存小得多。以我的經驗來說,快取記憶體的大小一般是主存的千分之一左右(目前一般是4GB主存、4MB快取)。這一點本身並不是什麼問題。只是,計算機一般都會有比較大的主存,因此工作集的大小總是會大於快取。特別是那些執行多程式的系統,它的工作集大小是所有程式加上核心的總和。
處理快取記憶體大小的限制需要制定一套很好的策略來決定在給定的時間內什麼資料應該被快取。由於不是所有資料的工作集都是在完全相同的時間段內被使用的,我們可以用一些技術手段將需要用到的資料臨時替換那些當前並未使用的快取資料。這種預取將會減少部分訪問主存的成本,因為它與程式的執行是非同步的。所有的這些技術將會使快取記憶體在使用的時候看起來比實際更大。我們將在3.3節討論這些問題。 我們將在第6章討論如何讓這些技術能很好地幫助程式設計師,讓處理器更高效地工作。
3.1 快取記憶體的位置
在深入介紹快取記憶體的技術細節之前,有必要說明一下它在現代計算機系統中所處的位置。
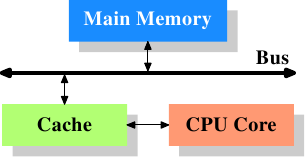
圖3.1: 最簡單的快取記憶體配置圖
圖3.1展示了最簡單的快取記憶體配置。早期的一些系統就是類似的架構。在這種架構中,CPU核心不再直連到主存。{在一些更早的系統中,快取記憶體像CPU與主存一樣連到系統匯流排上。那種做法更像是一種hack,而不是真正的解決方案。}資料的讀取和儲存都經過快取記憶體。CPU核心與快取記憶體之間是一條特殊的快速通道。在簡化的表示法中,主存與快取記憶體都連到系統匯流排上,這條匯流排同時還用於與其它元件通訊。我們管這條匯流排叫“FSB”——就是現在稱呼它的術語,參見第2.2節。在這一節裡,我們將忽略北橋。
在過去的幾十年,經驗表明使用了馮諾伊曼結構的 計算機,將用於程式碼和資料的快取記憶體分開是存在巨大優勢的。自1993年以來,Intel 並且一直堅持使用獨立的程式碼和資料快取記憶體。由於所需的程式碼和資料的記憶體區域是幾乎相互獨立的,這就是為什麼獨立快取工作得更完美的原因。近年來,獨立快取的另一個優勢慢慢顯現出來:常見處理器解碼 指令的步驟 是緩慢的,尤其當管線為空的時候,往往會伴隨著錯誤的預測或無法預測的分支的出現, 將快取記憶體技術用於 指令 解碼可以加快其執行速度。
在快取記憶體出現後不久,系統變得更加複雜。快取記憶體與主存之間的速度差異進一步拉大,直到加入了另一級快取。新加入的這一級快取比第一級快取更大,但是更慢。由於加大一級快取的做法從經濟上考慮是行不通的,所以有了二級快取,甚至現在的有些系統擁有三級快取,如圖3.2所示。隨著單個CPU中核數的增加,未來甚至可能會出現更多層級的快取。
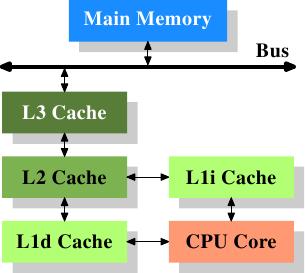
圖3.2: 三級快取的處理器
圖3.2展示了三級快取,並介紹了本文將使用的一些術語。L1d是一級資料快取,L1i是一級指令快取,等等。請注意,這只是示意圖,真正的資料流並不需要流經上級快取。CPU的設計者們在設計快取記憶體的介面時擁有很大的自由。而程式設計師是看不到這些設計選項的。
另外,我們有多核CPU,每個核心可以有多個“執行緒”。核心與執行緒的不同之處在於,核心擁有獨立的硬體資源({早期的多核CPU甚至有獨立的二級快取。})。在不同時使用相同資源(比如,通往外界的連線)的情況下,核心可以完全獨立地執行。而執行緒只是共享資源。Intel的執行緒只有獨立的暫存器,而且還有限制——不是所有暫存器都獨立,有些是共享的。綜上,現代CPU的結構就像圖3.3所示。
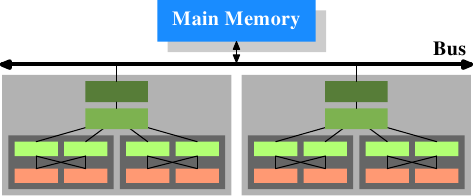
圖3.3 多處理器、多核心、多執行緒
在上圖中,有兩個處理器,每個處理器有兩個核心,每個核心有兩個執行緒。執行緒們共享一級快取。核心(以深灰色表示)有獨立的一級快取,同時共享二級快取。處理器(淡灰色)之間不共享任何快取。這些資訊很重要,特別是在討論多程式和多執行緒情況下快取的影響時尤為重要。
3.2 高階的快取操作
瞭解成本和節約使用快取,我們必須結合在第二節中講到的關於計算機體系結構和RAM技術,以及前一節講到的快取描述來探討。
預設情況下,CPU核心所有的資料的讀或寫都儲存在快取中。當然,也有記憶體區域不能被快取的,但是這種情況只發生在作業系統的實現者對資料考慮的前提下;對程式實現者來說,這是不可見的。這也說明,程式設計者可以故意繞過某些快取,不過這將是第六節中討論的內容了。
如果CPU需要訪問某個字(word),先檢索快取。很顯然,快取不可能容納主存所有內容(否則還需要主存幹嘛)。系統用字的記憶體地址來對快取條目進行標記。如果需要讀寫某個地址的字,那麼根據標籤來檢索快取即可。這裡用到的地址可以是虛擬地址,也可以是實體地址,取決於快取的具體實現。
標籤是需要額外空間的,用字作為快取的粒度顯然毫無效率。比如,在x86機器上,32位字的標籤可能需要32位,甚至更長。另一方面,由於空間區域性性的存在,與當前地址相鄰的地址有很大可能會被一起訪問。再回憶下2.2.1節——記憶體模組在傳輸位於同一行上的多份資料時,由於不需要傳送新CAS訊號,甚至不需要傳送RAS訊號,因此可以實現很高的效率。基於以上的原因,快取條目並不儲存單個字,而是儲存若干連續字組成的“線”。在早期的快取中,線長是32位元組,現在一般是64位元組。對於64位寬的記憶體匯流排,每條線需要8次傳輸。而DDR對於這種傳輸模式的支援更為高效。
當處理器需要記憶體中的某塊資料時,整條快取線被裝入L1d。快取線的地址通過對記憶體地址進行掩碼操作生成。對於64位元組的快取線,是將低6位置0。這些被丟棄的位作為線內偏移量。其它的位作為標籤,並用於在快取內定位。在實踐中,我們將地址分為三個部分。32位地址的情況如下:

如果快取線長度為2O,那麼地址的低O位用作線內偏移量。上面的S位選擇“快取集”。後面我們會說明使用快取集的原因。現在只需要明白一共有2S個快取集就夠了。剩下的32 - S - O = T位組成標籤。它們用來區分別名相同的各條線{有相同S部分的快取線被稱為有相同的別名。}用於定位快取集的S部分不需要儲存,因為屬於同一快取集的所有線的S部分都是相同的。
當某條指令修改記憶體時,仍然要先裝入快取線,因為任何指令都不可能同時修改整條線(只有一個例外——第6.1節中將會介紹的寫合併(write-combine))。因此需要在寫操作前先把快取線裝載進來。如果快取線被寫入,但還沒有寫回主存,那就是所謂的“髒了”。髒了的線一旦寫回主存,髒標記即被清除。
為了裝入新資料,基本上總是要先在快取中清理出位置。L1d將內容逐出L1d,推入L2(線長相同)。當然,L2也需要清理位置。於是L2將內容推入L3,最後L3將它推入主存。這種逐出操作一級比一級昂貴。這裡所說的是現代AMD和VIA處理器所採用的獨佔型快取(exclusive cache)。而Intel採用的是包容型快取(inclusive cache),{並不完全正確,Intel有些快取是獨佔型的,還有一些快取具有獨佔型快取的特點。}L1d的每條線同時存在於L2裡。對這種快取,逐出操作就很快了。如果有足夠L2,對於相同內容存在不同地方造成記憶體浪費的缺點可以降到最低,而且在逐出時非常有利。而獨佔型快取在裝載新資料時只需要操作L1d,不需要碰L2,因此會比較快。
處理器體系結構中定義的作為儲存器的模型只要還沒有改變,那就允許多CPU按照自己的方式來管理快取記憶體。這表示,例如,設計優良的處理器,利用很少或根本沒有記憶體匯流排活動,並主動寫回主記憶體髒快取記憶體行。這種快取記憶體架構在如x86和x86-64各種各樣的處理器間存在。製造商之間,即使在同一製造商生產的產品中,證明了的記憶體模型抽象的力量。
在對稱多處理器(SMP)架構的系統中,CPU的快取記憶體不能獨立的工作。在任何時候,所有的處理器都應該擁有相同的記憶體內容。保證這樣的統一的記憶體檢視被稱為“快取記憶體一致性”。如果在其自己的快取記憶體和主記憶體間,處理器設計簡單,它將不會看到在其他處理器上的髒快取記憶體行的內容。從一個處理器直接訪問另一個處理器的快取記憶體這種模型設計代價將是非常昂貴的,它是一個相當大的瓶頸。相反,當另一個處理器要讀取或寫入到快取記憶體線上時,處理器會去檢測。
如果CPU檢測到一個寫訪問,而且該CPU的cache中已經快取了一個cache line的原始副本,那麼這個cache line將被標記為無效的cache line。接下來在引用這個cache line之前,需要重新載入該cache line。需要注意的是讀訪問並不會導致cache line被標記為無效的。
更精確的cache實現需要考慮到其他更多的可能性,比如第二個CPU在讀或者寫他的cache line時,發現該cache line在第一個CPU的cache中被標記為髒資料了,此時我們就需要做進一步的處理。在這種情況下,主儲存器已經失效,第二個CPU需要讀取第一個CPU的cache line。通過測試,我們知道在這種情況下第一個CPU會將自己的cache line資料自動傳送給第二個CPU。這種操作是繞過主儲存器的,但是有時候儲存控制器是可以直接將第一個CPU中的cache line資料儲存到主儲存器中。對第一個CPU的cache的寫訪問會導致本地cache line的所有拷貝被標記為無效。
隨著時間的推移,一大批快取一致性協議已經建立。其中,最重要的是MESI,我們將在第3.3.4節進行介紹。以上結論可以概括為幾個簡單的規則:- 一個髒快取線不存在於任何其他處理器的快取之中。
- 同一快取線中的乾淨拷貝可以駐留在任意多個其他快取之中。
最後,我們至少應該關注快取記憶體命中或未命中帶來的消耗。下面是英特爾奔騰 M 的資料:
| To Where | Cycles |
|---|---|
| Register | <= 1 |
| L1d | ~3 |
| L2 | ~14 |
| Main Memory | ~240 |
這是在CPU週期中的實際訪問時間。有趣的是,對於L2快取記憶體的訪問時間很大一部分(甚至是大部分)是由線路的延遲引起的。這是一個限制,增加快取記憶體的大小變得更糟。只有當減小時(例如,從60奈米的Merom到45奈米Penryn處理器),可以提高這些資料。
表格中的數字看起來很高,但是,幸運的是,整個成本不必須負擔每次出現的快取載入和快取失效。某些部分的成本可以被隱藏。現在的處理器都使用不同長度的內部管道,在管道內指令被解碼,併為準備執行。如果資料要傳送到一個暫存器,那麼部分的準備工作是從儲存器(或快取記憶體)載入資料。如果記憶體載入操作在管道中足夠早的進行,它可以與其他操作並行發生,那麼載入的全部發銷可能會被隱藏。對L1D常常可能如此;某些有長管道的處理器的L2也可以。提早啟動記憶體的讀取有許多障礙。它可能只是簡單的不具有足夠資源供記憶體訪問,或者地址從另一個指令獲取,然後載入的最終地址才變得可用。在這種情況下,載入成本是不能隱藏的(完全的)。
對於寫操作,CPU並不需要等待資料被安全地放入記憶體。只要指令具有類似的效果,就沒有什麼東西可以阻止CPU走捷徑了。它可以早早地執行下一條指令,甚至可以在影子暫存器(shadow register)的幫助下,更改這個寫操作將要儲存的資料。
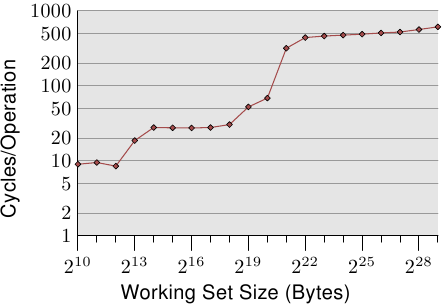
圖3.4: 隨機寫操作的訪問時間
圖3.4展示了快取的效果。關於產生圖中資料的程式,我們會在稍後討論。這裡大致說下,這個程式是連續隨機地訪問某塊大小可配的記憶體區域。每個資料項的大小是固定的。資料項的多少取決於選擇的工作集大小。Y軸表示處理每個元素平均需要多少個CPU週期,注意它是對數刻度。X軸也是同樣,工作集的大小都以2的n次方表示。
圖中有三個比較明顯的不同階段。很正常,這個處理器有L1d和L2,沒有L3。根據經驗可以推測出,L1d有213位元組,而L2有220位元組。因為,如果整個工作集都可以放入L1d,那麼只需不到10個週期就可以完成操作。如果工作集超過L1d,處理器不得不從L2獲取資料,於是時間飄升到28個週期左右。如果工作集更大,超過了L2,那麼時間進一步暴漲到480個週期以上。這時候,許多操作將不得不從主存中獲取資料。更糟糕的是,如果修改了資料,還需要將這些髒了的快取線寫回記憶體。
看了這個圖,大家應該會有足夠的動力去檢查程式碼、改進快取的利用方式了吧?這裡的效能改善可不只是微不足道的幾個百分點,而是幾個數量級呀。在第6節中,我們將介紹一些編寫高效程式碼的技巧。而下一節將進一步深入快取的設計。雖然精彩,但並不是必修課,大家可以選擇性地跳過。
3.3 CPU快取實現的細節
快取的實現者們都要面對一個問題——主存中每一個單元都可能需被快取。如果程式的工作集很大,就會有許多記憶體位置為了快取而打架。前面我們曾經提過快取與主存的容量比,1:1000也十分常見。
3.3.1 關聯性
我們可以讓快取的每條線能存放任何記憶體地址的資料。這就是所謂的全關聯快取(fully associative cache)。對於這種快取,處理器為了訪問某條線,將不得不檢索所有線的標籤。而標籤則包含了整個地址,而不僅僅只是線內偏移量(也就意味著,圖3.2中的S為0)。
快取記憶體有類似這樣的實現,但是,看看在今天使用的L2的數目,表明這是不切實際的。給定4MB的快取記憶體和64B的快取記憶體段,快取記憶體將有65,536個項。為了達到足夠的效能,快取邏輯必須能夠在短短的幾個時鐘週期內,從所有這些項中,挑一個匹配給定的標籤。實現這一點的工作將是巨大的。

Figure 3.5: 全關聯快取記憶體原理圖
對於每個快取記憶體行,比較器是需要比較大標籤(注意,S是零)。每個連線旁邊的字母表示位的寬度。如果沒有給出,它是一個單位元線。每個比較器都要比較兩個T-位寬的值。然後,基於該結果,適當的快取記憶體行的內容被選中,並使其可用。這需要合併多套O資料線,因為他們是快取桶(譯註:這裡類似把O輸出接入多選器,所以需要合併)。實現僅僅一個比較器,需要電晶體的數量就非常大,特別是因為它必須非常快。沒有迭代比較器是可用的。節省比較器的數目的唯一途徑是通過反覆比較標籤,以減少它們的數目。這是不適合的,出於同樣的原因,迭代比較器不可用:它的時間太長。
全關聯快取記憶體對 小快取是實用的(例如,在某些Intel處理器的TLB快取是全關聯的),但這些快取都很小,非常小的。我們正在談論的最多幾十項。對於L1i,L1d和更高階別的快取,需要採用不同的方法。可以做的就是是限制搜尋。最極端的限制是,每個標籤對映到一個明確的快取條目。計算很簡單:給定的4MB/64B快取有65536項,我們可以使用地址的bit6到bit21(16位)來直接定址快取記憶體的每一個項。地址的低6位作為快取記憶體段的索引。
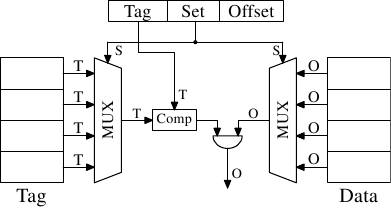
Figure 3.6: Direct-Mapped Cache Schematics
在圖3.6中可以看出,這種直接對映的快取記憶體,速度快,比較容易實現。它只是需要一個比較器,一個多路複用器(在這個圖中有兩個,標記和資料是分離的,但是對於設計這不是一個硬性要求),和一些邏輯來選擇只是有效的快取記憶體行的內容。由於速度的要求,比較器是複雜的,但是現在只需要一個,結果是可以花更多的精力,讓其變得快速。這種方法的複雜性在於在多路複用器。一個簡單的多路轉換器中的電晶體的數量增速是O(log N)的,其中N是快取記憶體段的數目。這是可以容忍的,但可能會很慢,在某種情況下,速度可提升,通過增加多路複用器電晶體數量,來並行化的一些工作和自身增速。電晶體的總數只是隨著快速增長的快取記憶體緩慢的增加,這使得這種解決方案非常有吸引力。但它有一個缺點:只有用於直接對映地址的相關的地址位均勻分佈,程式才能很好工作。如果分佈的不均勻,而且這是常態,一些快取項頻繁的使用,並因此多次被換出,而另一些則幾乎不被使用或一直是空的。
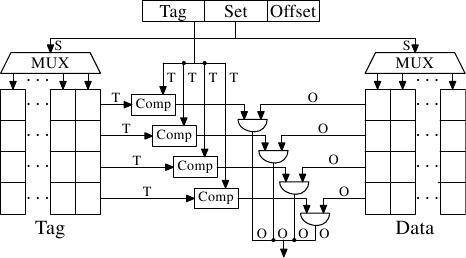
Figure 3.7: 組關聯快取記憶體原理圖
可以通過使快取記憶體的組關聯來解決此問題。組關聯結合快取記憶體的全關聯和直接對映快取記憶體特點,在很大程度上避免那些設計的弱點。圖3.7顯示了一個組關聯快取記憶體的設計。標籤和資料儲存分成不同的組並可以通過地址選擇。這類似直接對映快取記憶體。但是,小數目的值可以在同一個快取記憶體組快取,而不是一個快取組只有一個元素,用於在快取記憶體中的每個設定值是相同的一組值的快取。所有組的成員的標籤可以並行比較,這類似全關聯快取的功能。
其結果是快取記憶體,不容易被不幸或故意選擇同屬同一組編號的地址所擊敗,同時快取記憶體的大小並不限於由比較器的數目,可以以並行的方式實現。如果快取記憶體增長,只(在該圖中)增加列的數目,而不增加行數。只有快取記憶體之間的關聯性增加,行數才會增加。今天,處理器的L2快取記憶體或更高的快取記憶體,使用的關聯性高達16。 L1快取記憶體通常使用8。
| L2 Cache Size |
Associativity | |||||||
|---|---|---|---|---|---|---|---|---|
| Direct | 2 | 4 | 8 | |||||
| CL=32 | CL=64 | CL=32 | CL=64 | CL=32 | CL=64 | CL=32 | CL=64 | |
| 512k | 27,794,595 | 20,422,527 | 25,222,611 | 18,303,581 | 24,096,510 | 17,356,121 | 23,666,929 | 17,029,334 |
| 1M | 19,007,315 | 13,903,854 | 16,566,738 | 12,127,174 | 15,537,500 | 11,436,705 | 15,162,895 | 11,233,896 |
| 2M | 12,230,962 | 8,801,403 | 9,081,881 | 6,491,011 | 7,878,601 | 5,675,181 | 7,391,389 | 5,382,064 |
| 4M | 7,749,986 | 5,427,836 | 4,736,187 | 3,159,507 | 3,788,122 | 2,418,898 | 3,430,713 | 2,125,103 |
| 8M | 4,731,904 | 3,209,693 | 2,690,498 | 1,602,957 | 2,207,655 | 1,228,190 | 2,111,075 | 1,155,847 |
| 16M | 2,620,587 | 1,528,592 | 1,958,293 | 1,089,580 | 1,704,878 | 883,530 | 1,671,541 | 862,324 |
Table 3.1: 快取記憶體大小,關聯行,段大小的影響
給定我們4MB/64B快取記憶體,8路組關聯,相關的快取留給我們的有8192組,只用標籤的13位,就可以定址緩集。要確定哪些(如果有的話)的快取組設定中的條目包含定址的快取記憶體行,8個標籤都要進行比較。在很短的時間內做出來是可行的。通過一個實驗,我們可以看到,這是有意義的。
表3.1顯示一個程式在改變快取大小,快取段大小和關聯集大小,L2快取記憶體的快取失效數量(根據Linux核心相關的方面人的說法,GCC在這種情況下,是他們所有中最重要的標尺)。在7.2節中,我們將介紹工具來模擬此測試要求的快取記憶體。
萬一這還不是很明顯,所有這些值之間的關係是快取記憶體的大小為:
cache line size × associativity × number of sets
地址被對映到快取記憶體使用
O = log 2 cache line size
S = log 2 number of sets
在第3.2節中的圖顯示的方式。
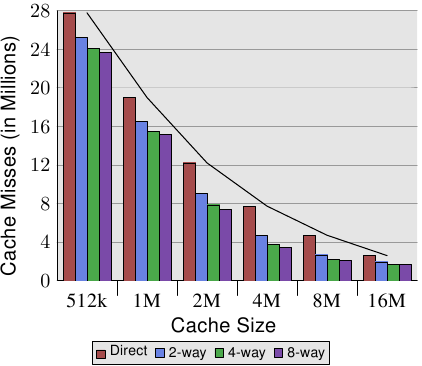
Figure 3.8: 快取段大小 vs 關聯行 (CL=32)
圖3.8表中的資料更易於理解。它顯示一個固定的32個位元組大小的快取記憶體行的資料。對於一個給定的快取記憶體大小,我們可以看出,關聯性,的確可以幫助明顯減少快取記憶體未命中的數量。對於8MB的快取,從直接對映到2路組相聯,可以減少近44%的快取記憶體未命中。組相聯快取記憶體和直接對映快取相比,該處理器可以把更多的工作集保持在快取中。
在文獻中,偶爾可以讀到,引入關聯性,和加倍快取記憶體的大小具有相同的效果。在從4M快取躍升到8MB快取的極端的情況下,這是正確的。關聯性再提高一倍那就肯定不正確啦。正如我們所看到的資料,後面的收益要小得多。我們不應該完全低估它的效果,雖然。在示例程式中的記憶體使用的峰值是5.6M。因此,具有8MB快取不太可能有很多(兩個以上)使用相同的快取記憶體的組。從較小的快取的關聯性的巨大收益可以看出,較大工作集可以節省更多。
在一般情況下,增加8以上的快取記憶體之間的關聯性似乎對只有一個單執行緒工作量影響不大。隨著介紹一個使用共享L2的多核處理器,形勢發生了變化。現在你基本上有兩個程式命中相同的快取, 實際上導致快取記憶體減半(對於四核處理器是1/4)。因此,可以預期,隨著核的數目的增加,共享快取記憶體的相關性也應增長。一旦這種方法不再可行(16 路組關聯性已經很難)處理器設計者不得不開始使用共享的三級快取記憶體和更高階別的,而L2快取記憶體只被核的一個子集共享。
從圖3.8中,我們還可以研究快取大小對效能的影響。這一資料需要了解工作集的大小才能進行解讀。很顯然,與主存相同的快取比小快取能產生更好的結果,因此,快取通常是越大越好。
上文已經說過,示例中最大的工作集為5.6M。它並沒有給出最佳快取大小值,但我們可以估算出來。問題主要在於記憶體的使用並不連續,因此,即使是16M的快取,在處理5.6M的工作集時也會出現衝突(參見2路集合關聯式16MB快取vs直接對映式快取的優點)。不管怎樣,我們可以有把握地說,在同樣5.6M的負載下,快取從16MB升到32MB基本已沒有多少提高的餘地。但是,工作集是會變的。如果工作集不斷增大,快取也需要隨之增大。在購買計算機時,如果需要選擇快取大小,一定要先衡量工作集的大小。原因可以參見圖3.10。
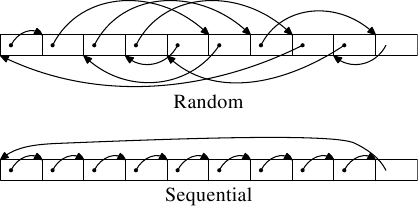
圖3.9: 測試的記憶體分佈情況
我們執行兩項測試。第一項測試是按順序地訪問所有元素。測試程式循著指標n進行訪問,而所有元素是連結在一起的,從而使它們的被訪問順序與在記憶體中排布的順序一致,如圖3.9的下半部分所示,末尾的元素有一個指向首元素的引用。而第二項測試(見圖3.9的上半部分)則是按隨機順序訪問所有元素。在上述兩個測試中,所有元素都構成一個單向迴圈連結串列。
3.3.2 Cache的效能測試
用於測試程式的資料可以模擬一個任意大小的工作集:包括讀、寫訪問,隨機、連續訪問。在圖3.4中我們可以看到,程式為工作集建立了一個與其大小和元素型別相同的陣列:
struct l {
struct l *n;
long int pad[NPAD];
};
n欄位將所有節點隨機得或者順序的加入到環形連結串列中,用指標從當前節點進入到下一個節點。pad欄位用來儲存資料,其可以是任意大小。在一些測試程式中,pad欄位是可以修改的, 在其他程式中,pad欄位只可以進行讀操作。
在效能測試中,我們談到工作集大小的問題,工作集使用結構體l定義的元素表示的。2N 位元組的工作集包含
2 N/sizeof(struct l)
個元素. 顯然sizeof(struct l) 的值取決於NPAD的大小。在32位系統上,NPAD=7意味著陣列的每個元素的大小為32位元組,在64位系統上,NPAD=7意味著陣列的每個元素的大小為64位元組。
單執行緒順序訪問
最簡單的情況就是遍歷連結串列中順序儲存的節點。無論是從前向後處理,還是從後向前,對於處理器來說沒有什麼區別。下面的測試中,我們需要得到處理連結串列中一個元素所需要的時間,以CPU時鐘週期最為計時單元。圖3.10顯示了測試結構。除非有特殊說明, 所有的測試都是在Pentium 4 64-bit 平臺上進行的,因此結構體l中NPAD=0,大小為8位元組。
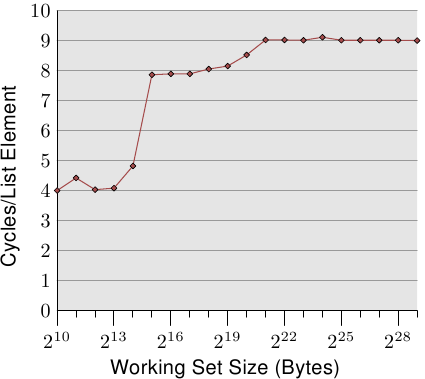
圖 3.10: 順序讀訪問, NPAD=0
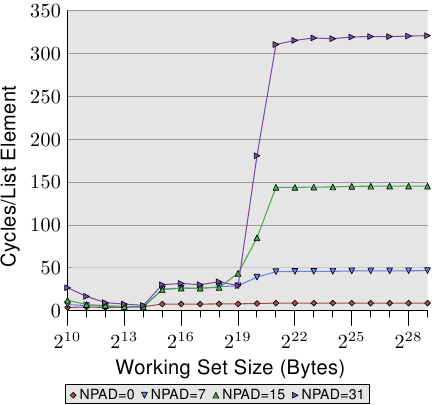
圖 3.11: 順序讀多個位元組
一開始的兩個測試資料收到了噪音的汙染。由於它們的工作負荷太小,無法過濾掉系統內其它程式對它們的影響。我們可以認為它們都是4個週期以內的。這樣一來,整個圖可以劃分為比較明顯的三個部分:
- 工作集小於214位元組的。
- 工作集從215位元組到220位元組的。
- 工作集大於221位元組的。
這樣的結果很容易解釋——是因為處理器有16KB的L1d和1MB的L2。而在這三個部分之間,並沒有非常銳利的邊緣,這是因為系統的其它部分也在使用快取,我們的測試程式並不能獨佔快取的使用。尤其是L2,它是統一式的快取,處理器的指令也會使用它(注: Intel使用的是包容式快取)。
測試的實際耗時可能會出乎大家的意料。L1d的部分跟我們預想的差不多,在一臺P4上耗時為4個週期左右。但L2的結果則出乎意料。大家可能覺得需要14個週期以上,但實際只用了9個週期。這要歸功於處理器先進的處理邏輯,當它使用連續的記憶體區時,會 預先讀取下一條快取線的資料。這樣一來,當真正使用下一條線的時候,其實已經早已讀完一半了,於是真正的等待耗時會比L2的訪問時間少很多。
在工作集超過L2的大小之後,預取的效果更明顯了。前面我們說過,主存的訪問需要耗時200個週期以上。但在預取的幫助下,實際耗時保持在9個週期左右。200 vs 9,效果非常不錯。
我們可以觀察到預取的行為,至少可以間接地觀察到。圖3.11中有4條線,它們表示處理不同大小結構時的耗時情況。隨著結構的變大,元素間的距離變大了。圖中4條線對應的元素距離分別是0、56、120和248位元組。
圖中最下面的這一條線來自前一個圖,但在這裡更像是一條直線。其它三條線的耗時情況比較差。圖中這些線也有比較明顯的三個階段,同時,在小工作集的情況下也有比較大的錯誤(請再次忽略這些錯誤)。在只使用L1d的階段,這些線條基本重合。因為這時候還不需要預取,只需要訪問L1d就行。
在L2階段,三條新加的線基本重合,而且耗時比老的那條線高很多,大約在28個週期左右,差不多就是L2的訪問時間。這表明,從L2到L1d的預取並沒有生效。這是因為,對於最下面的線(NPAD=0),由於結構小,8次迴圈後才需要訪問一條新快取線,而上面三條線對應的結構比較大,拿相對最小的NPAD=7來說,光是一次迴圈就需要訪問一條新線,更不用說更大的NPAD=15和31了。而預取邏輯是無法在每個週期裝載新線的,因此每次迴圈都需要從L2讀取,我們看到的就是從L2讀取的時延。
更有趣的是工作集超過L2容量後的階段。快看,4條線遠遠地拉開了。元素的大小變成了主角,左右了效能。處理器應能識別每一步(stride)的大小,不去為NPAD=15和31獲取那些實際並不需要的快取線(參見6.3.1)。元素大小對預取的約束是根源於硬體預取的限制——它無法跨越頁邊界。如果允許預取器跨越頁邊界,而下一頁不存在或無效,那麼OS還得去尋找它。這意味著,程式需要遭遇一次並非由它自己產生的頁錯誤,這是完全不能接受的。在NPAD=7或者更大的時候,由於每個元素都至少需要一條快取線,預取器已經幫不上忙了,它沒有足夠的時間去從記憶體裝載資料。另一個導致慢下來的原因是TLB快取的未命中。TLB是儲存虛實地址對映的快取,參見第4節。為了保持快速,TLB只有很小的容量。如果有大量頁被反覆訪問,超出了TLB快取容量,就會導致反覆地進行地址翻譯,這會耗費大量時間。TLB查詢的代價分攤到所有元素上,如果元素越大,那麼元素的數量越少,每個元素承擔的那一份就越多。
為了觀察TLB的效能,我們可以進行另兩項測試。第一項:我們還是順序儲存列表中的元素,使NPAD=7,讓每個元素佔滿整個cache line,第二項:我們將列表的每個元素儲存在一個單獨的頁上,忽略每個頁沒有使用的部分以用來計算工作集的大小。(這樣做可能不太一致,因為在前面的測試中,我計算了結構體中每個元素沒有使用的部分,從而用來定義NPAD的大小,因此每個元素佔滿了整個頁,這樣以來工作集的大小將會有所不同。但是這不是這項測試的重點,預取的低效率多少使其有點不同)。結果表明,第一項測試中,每次列表的迭代都需要一個新的cache line,而且每64個元素就需要一個新的頁。第二項測試中,每次迭代都會在一個新的頁中載入一個新的cache line。
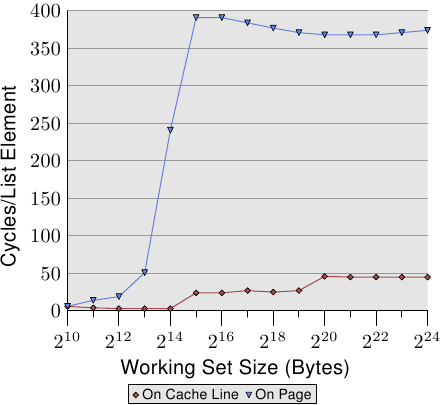
圖 3.12: TLB 對順序讀的影響
結果見圖3.12。該測試與圖3.11是在同一臺機器上進行的。基於可用RAM空間的有限性,測試設定容量空間大小為2的24次方位元組,這就需要1GB的容量將物件放置在分頁上。圖3.12中下方的紅色曲線正好對應了圖3.11中NPAD等於7的曲線。我們看到不同的步長顯示了快取記憶體L1d和L2的大小。第二條曲線看上去完全不同,其最重要的特點是當工作容量到達2的13次方位元組時開始大幅度增長。這就是TLB快取溢位的時候。我們能計算出一個64位元組大小的元素的TLB快取有64個輸入。成本不會受頁面錯誤影響,因為程式鎖定了儲存器以防止記憶體被換出。
可以看出,計算實體地址並把它儲存在TLB中所花費的週期數量級是非常高的。圖3.12的表格顯示了一個極端的例子,但從中可以清楚的得到:TLB快取效率降低的一個重要因素是大型NPAD值的減緩。由於實體地址必須在快取行能被L2或主存讀取之前計算出來,地址轉換這個不利因素就增加了記憶體訪問時間。這一點部分解釋了為什麼NPAD等於31時每個列表元素的總花費比理論上的RAM訪問時間要高。
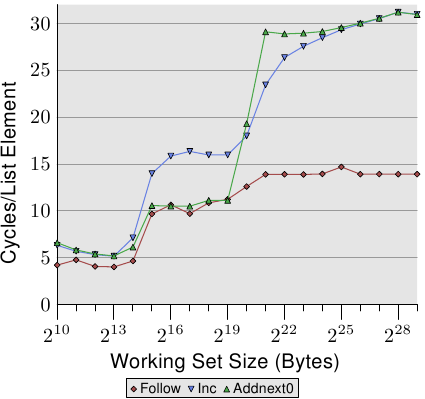
圖3.13 NPAD等於1時的順序讀和寫
通過檢視連結串列元素被修改時測試資料的執行情況,我們可以窺見一些更詳細的預取實現細節。圖3.13顯示了三條曲線。所有情況下元素寬度都為16個位元組。第一條曲線“Follow”是熟悉的連結串列走線在這裡作為基線。第二條曲線,標記為“Inc”,僅僅在當前元素進入下一個前給其增加thepad[0]成員。第三條曲線,標記為"Addnext0", 取出下一個元素的thepad[0]連結串列元素並把它新增為當前連結串列元素的thepad[0]成員。
在沒執行時,大家可能會以為"Addnext0"更慢,因為它要做的事情更多——在沒進到下個元素之前就需要裝載它的值。但實際的執行結果令人驚訝——在某些小工作集下,"Addnext0"比"Inc"更快。這是為什麼呢?原因在於,系統一般會對下一個元素進行強制性預取。當程式前進到下個元素時,這個元素其實早已被預取在L1d裡。因此,只要工作集比L2小,"Addnext0"的效能基本就能與"Follow"測試媲美。
但是,"Addnext0"比"Inc"更快離開L2,這是因為它需要從主存裝載更多的資料。而在工作集達到2 21位元組時,"Addnext0"的耗時達到了28個週期,是同期"Follow"14週期的兩倍。這個兩倍也很好解釋。"Addnext0"和"Inc"涉及對記憶體的修改,因此L2的逐出操作不能簡單地把資料一扔了事,而必須將它們寫入記憶體。因此FSB的可用頻寬變成了一半,傳輸等量資料的耗時也就變成了原來的兩倍。
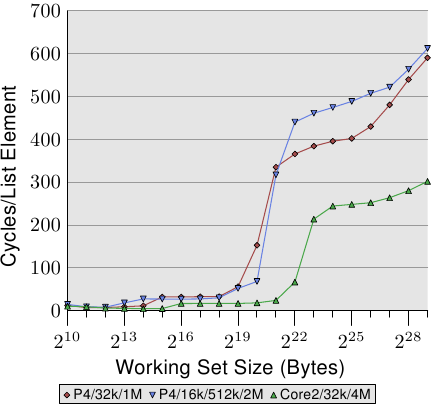
圖3.14: 更大L2/L3快取的優勢
決定順序式快取處理效能的另一個重要因素是快取容量。雖然這一點比較明顯,但還是值得一說。圖3.14展示了128位元組長元素的測試結果(64位機,NPAD=15)。這次我們比較三臺不同計算機的曲線,兩臺P4,一臺Core 2。兩臺P4的區別是快取容量不同,一臺是32k的L1d和1M的L2,一臺是16K的L1d、512k的L2和2M的L3。Core 2那臺則是32k的L1d和4M的L2。
圖中最有趣的地方,並不是Core 2如何大勝兩臺P4,而是工作集開始增長到連末級快取也放不下、需要主存熱情參與之後的部分。
| Set Size |
Sequential | Random | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| L2 Hit | L2 Miss | #Iter | Ratio Miss/Hit | L2 Accesses Per Iter | L2 Hit | L2 Miss | #Iter | Ratio Miss/Hit | L2 Accesses Per Iter | |
| 220 | 88,636 | 843 | 16,384 | 0.94% | 5.5 | 30,462 | 4721 | 1,024 | 13.42% | 34.4 |
| 221 | 88,105 | 1,584 | 8,192 | 1.77% | 10.9 | 21,817 | 15,151 | 512 | 40.98% | 72.2 |
| 222 | 88,106 | 1,600 | 4,096 | 1.78% | 21.9 | 22,258 | 22,285 | 256 | 50.03% | 174.0 |
| 223 | 88,104 | 1,614 | 2,048 | 1.80% | 43.8 | 27,521 | 26,274 | 128 | 48.84% | 420.3 |
| 224 | 88,114 | 1,655 | 1,024 | 1.84% | 87.7 | 33,166 | 29,115 | 64 | 46.75% | 973.1 |
| 225 | 88,112 | 1,730 | 512 | 1.93% | 175.5 | 39,858 | 32,360 | 32 | 44.81% | 2,256.8 |
| 226 | 88,112 | 1,906 | 256 | 2.12% | 351.6 | 48,539 | 38,151 | 16 | 44.01% | 5,418.1 |
| 227 | 88,114 | 2,244 | 128 | 2.48% | 705.9 | 62,423 | 52,049 | 8 | 45.47% | 14,309.0 |
| 228 | 88,120 | 2,939 | 64 | 3.23% | 1,422.8 | 81,906 | 87,167 | 4 | 51.56% | 42,268.3 |
| 229 | 88,137 | 4,318 | 32 | 4.67% | 2,889.2 | 119,079 | 163,398 | 2 | 57.84% | 141,238.5 |
表3.2: 順序訪問與隨機訪問時L2命中與未命中的情況,NPAD=0
與我們預計的相似,最末級快取越大,曲線停留在L2訪問耗時區的時間越長。在220位元組的工作集時,第二臺P4(更老一些)比第一臺P4要快上一倍,這要完全歸功於更大的末級快取。而Core 2拜它巨大的4M L2所賜,表現更為卓越。
對於隨機的工作負荷而言,可能沒有這麼驚人的效果,但是,如果我們能將工作負荷進行一些裁剪,讓它匹配末級快取的容量,就完全可以得到非常大的效能提升。也是由於這個原因,有時候我們需要多花一些錢,買一個擁有更大快取的處理器。
單執行緒隨機訪問模式的測量
前面我們已經看到,處理器能夠利用L1d到L2之間的預取消除訪問主存、甚至是訪問L2的時延。
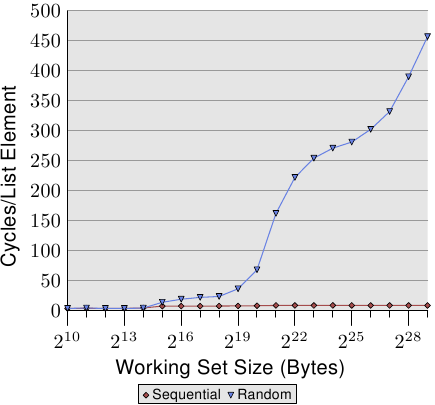
圖3.15: 順序讀取vs隨機讀取,NPAD=0
但是,如果換成隨機訪問或者不可預測的訪問,情況就大不相同了。圖3.15比較了順序讀取與隨機讀取的耗時情況。
換成隨機之後,處理器無法再有效地預取資料,只有少數情況下靠運氣剛好碰到先後訪問的兩個元素挨在一起的情形。
圖3.15中有兩個需要關注的地方。首先,在大的工作集下需要非常多的週期。這臺機器訪問主存的時間大約為200-300個週期,但圖中的耗時甚至超過了450個週期。我們前面已經觀察到過類似現象(對比圖3.11)。這說明,處理器的自動預取在這裡起到了反效果。
其次,代表隨機訪問的曲線在各個階段不像順序訪問那樣保持平坦,而是不斷攀升。為了解釋這個問題,我們測量了程式在不同工作集下對L2的訪問情況。結果如圖3.16和表3.2。
從圖中可以看出,當工作集大小超過L2時,未命中率(L2未命中次數/L2訪問次數)開始上升。整條曲線的走向與圖3.15有些相似: 先急速爬升,隨後緩緩下滑,最後再度爬升。它與耗時圖有緊密的關聯。L2未命中率會一直爬升到100%為止。只要工作集足夠大(並且記憶體也足夠大),就可以將快取線位於L2內或處於裝載過程中的可能性降到非常低。
快取未命中率的攀升已經可以解釋一部分的開銷。除此以外,還有一個因素。觀察表3.2的L2/#Iter列,可以看到每個迴圈對L2的使用次數在增長。由於工作集每次為上一次的兩倍,如果沒有快取的話,記憶體的訪問次數也將是上一次的兩倍。在按順序訪問時,由於快取的幫助及完美的預見性,對L2使用的增長比較平緩,完全取決於工作集的增長速度。
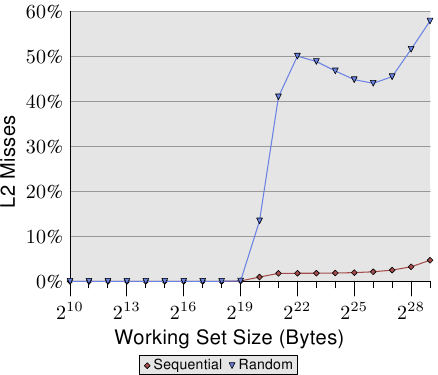
圖3.16: L2d未命中率
而換成隨機訪問後,單位耗時的增長超過了工作集的增長,根源是TLB未命中率的上升。圖3.17描繪的是NPAD=7時隨機訪問的耗時情況。這一次,我們修改了隨機訪問的方式。正常情況下是把整個列表作為一個塊進行隨機(以∞表示),而其它11條線則是在小一些的塊裡進行隨機。例如,標籤為'60'的線表示以60頁(245760位元組)為單位進行隨機。先遍歷完這個塊裡的所有元素,再訪問另一個塊。這樣一來,可以保證任意時刻使用的TLB條目數都是有限的。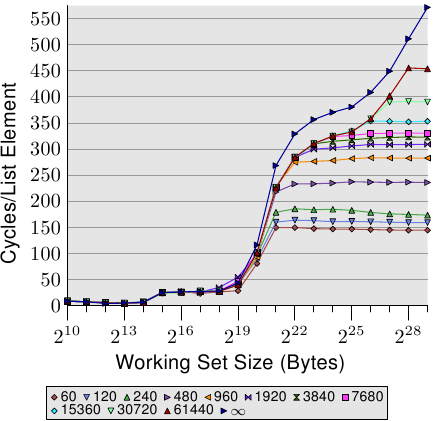
圖3.17: 頁意義上(Page-Wise)的隨機化,NPAD=7
NPAD=7對應於64位元組,正好等於快取線的長度。由於元素順序隨機,硬體預取不可能有任何效果,特別是在元素較多的情況下。這意味著,分塊隨機時的L2未命中率與整個列表隨機時的未命中率沒有本質的差別。隨著塊的增大,曲線逐漸逼近整個列表隨機對應的曲線。這說明,在這個測試裡,效能受到TLB命中率的影響很大,如果我們能提高TLB命中率,就能大幅度地提升效能(在後面的一個例子裡,效能提升了38%之多)。
3.3.3 寫入時的行為
在我們開始研究多個執行緒或程式同時使用相同記憶體之前,先來看一下快取實現的一些細節。我們要求快取是一致的,而且這種一致性必須對使用者級程式碼完全透明。而核心程式碼則有所不同,它有時候需要對快取進行轉儲(flush)。
這意味著,如果對快取線進行了修改,那麼在這個時間點之後,系統的結果應該是與沒有快取的情況下是相同的,即主存的對應位置也已經被修改的狀態。這種要求可以通過兩種方式或策略實現:
- 寫通(write-through)
- 寫回(write-back)
寫通比較簡單。當修改快取線時,處理器立即將它寫入主存。這樣可以保證主存與快取的內容永遠保持一致。當快取線被替代時,只需要簡單地將它丟棄即可。這種策略很簡單,但是速度比較慢。如果某個程式反覆修改一個本地變數,可能導致FSB上產生大量資料流,而不管這個變數是不是有人在用,或者是不是短期變數。
寫回比較複雜。當修改快取線時,處理器不再馬上將它寫入主存,而是打上已弄髒(dirty)的標記。當以後某個時間點快取線被丟棄時,這個已弄髒標記會通知處理器把資料寫回到主存中,而不是簡單地扔掉。
寫回有時候會有非常不錯的效能,因此較好的系統大多采用這種方式。採用寫回時,處理器們甚至可以利用FSB的空閒容量來儲存快取線。這樣一來,當需要快取空間時,處理器只需清除髒標記,丟棄快取線即可。
但寫回也有一個很大的問題。當有多個處理器(或核心、超執行緒)訪問同一塊記憶體時,必須確保它們在任何時候看到的都是相同的內容。如果快取線在其中一個處理器上弄髒了(修改了,但還沒寫回主存),而第二個處理器剛好要讀取同一個記憶體地址,那麼這個讀操作不能去讀主存,而需要讀第一個處理器的快取線。在下一節中,我們將研究如何實現這種需求。
在此之前,還有其它兩種快取策略需要提一下:
- 寫入合併
- 不可快取
這兩種策略用於真實記憶體不支援的特殊地址區,核心為地址區設定這些策略(x86處理器利用記憶體型別範圍暫存器MTRR),餘下的部分自動進行。MTRR還可用於寫通和寫回策略的選擇。
寫入合併是一種有限的快取優化策略,更多地用於顯示卡等裝置之上的記憶體。由於裝置的傳輸開銷比本地記憶體要高的多,因此避免進行過多的傳輸顯得尤為重要。如果僅僅因為修改了快取線上的一個字,就傳輸整條線,而下個操作剛好是修改線上的下一個字,那麼這次傳輸就過於浪費了。而這恰恰對於顯示卡來說是比較常見的情形——螢幕上水平鄰接的畫素往往在記憶體中也是靠在一起的。顧名思義,寫入合併是在寫出快取線前,先將多個寫入訪問合併起來。在理想的情況下,快取線被逐字逐字地修改,只有當寫入最後一個字時,才將整條線寫入記憶體,從而極大地加速記憶體的訪問。
最後來講一下不可快取的記憶體。一般指的是不被RAM支援的記憶體位置,它可以是硬編碼的特殊地址,承擔CPU以外的某些功能。對於商用硬體來說,比較常見的是對映到外部卡或裝置的地址。在嵌入式主機板上,有時也有類似的地址,用來開關LED。對這些地址進行快取顯然沒有什麼意義。比如上述的LED,一般是用來除錯或報告狀態,顯然應該儘快點亮或關閉。而對於那些PCI卡上的記憶體,由於不需要CPU的干涉即可更改,也不該快取。
3.3.4 多處理器支援
在上節中我們已經指出當多處理器開始發揮作用的時候所遇到的問題。甚至對於那些不共享的高速級別的快取(至少在L1d級別)的多核處理器也有問題。
直接提供從一個處理器到另一處理器的高速訪問,這是完全不切實際的。從一開始,連線速度根本就不夠快。實際的選擇是,在其需要的情況下,轉移到其他處理器。需要注意的是,這同樣應用在相同處理器上無需共享的快取記憶體。
現在的問題是,當該快取記憶體線轉移的時候會發生什麼?這個問題回答起來相當容易:當一個處理器需要在另一個處理器的快取記憶體中讀或者寫的髒的快取記憶體線的時候。但怎樣處理器怎樣確定在另一個處理器的快取中的快取記憶體線是髒的?假設它僅僅是因為一個快取記憶體線被另一個處理器載入將是次優的(最好的)。通常情況下,大多數的記憶體訪問是隻讀的訪問和產生快取記憶體線,並不髒。在快取記憶體線上處理器頻繁的操作(當然,否則為什麼我們有這樣的檔案呢?),也就意味著每一次寫訪問後,都要廣播關於快取記憶體線的改變將變得不切實際。
多年來,人們開發除了MESI快取一致性協議(MESI=Modified, Exclusive, Shared, Invalid,變更的、獨佔的、共享的、無效的)。協議的名稱來自協議中快取線可以進入的四種狀態:
- 變更的: 本地處理器修改了快取線。同時暗示,它是所有快取中唯一的拷貝。
- 獨佔的: 快取線沒有被修改,而且沒有被裝入其它處理器快取。
- 共享的: 快取線沒有被修改,但可能已被裝入其它處理器快取。
- 無效的: 快取線無效,即,未被使用。
MESI協議開發了很多年,最初的版本比較簡單,但是效率也比較差。現在的版本通過以上4個狀態可以有效地實現寫回式快取,同時支援不同處理器對只讀資料的併發訪問。
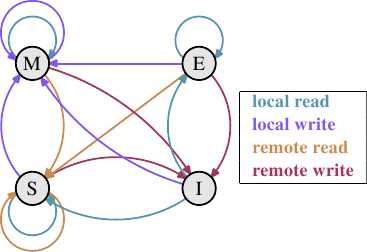
圖3.18: MESI協議的狀態躍遷圖
在協議中,通過處理器監聽其它處理器的活動,不需太多努力即可實現狀態變更。處理器將操作釋出在外部引腳上,使外部可以瞭解到處理過程。目標的快取線地址則可以在地址匯流排上看到。在下文講述狀態時,我們將介紹匯流排參與的時機。
一開始,所有快取線都是空的,快取為無效(Invalid)狀態。當有資料裝進快取供寫入時,快取變為變更(Modified)狀態。如果有資料裝進快取供讀取,那麼新狀態取決於其它處理器是否已經狀態了同一條快取線。如果是,那麼新狀態變成共享(Shared)狀態,否則變成獨佔(Exclusive)狀態。
如果本地處理器對某條Modified快取線進行讀寫,那麼直接使用快取內容,狀態保持不變。如果另一個處理器希望讀它,那麼第一個處理器將內容發給第一個處理器,然後可以將快取狀態置為Shared。而發給第二個處理器的資料由記憶體控制器接收,並放入記憶體中。如果這一步沒有發生,就不能將這條線置為Shared。如果第二個處理器希望的是寫,那麼第一個處理器將內容發給它後,將快取置為Invalid。這就是臭名昭著的"請求所有權(Request For Ownership,RFO)"操作。在末級快取執行RFO操作的代價比較高。如果是寫通式快取,還要加上將內容寫入上一層快取或主存的時間,進一步提升了代價。對於Shared快取線,本地處理器的讀取操作並不需要修改狀態,而且可以直接從快取滿足。而本地處理器的寫入操作則需要將狀態置為Modified,而且需要將快取線在其它處理器的所有拷貝置為Invalid。因此,這個寫入操作需要通過RFO訊息發通知其它處理器。如果第二個處理器請求讀取,無事發生。因為主存已經包含了當前資料,而且狀態已經為Shared。如果第二個處理器需要寫入,則將快取線置為Invalid。不需要匯流排操作。
Exclusive狀態與Shared狀態很像,只有一個不同之處: 在Exclusive狀態時,本地寫入操作不需要在匯流排上宣告,因為本地的快取是系統中唯一的拷貝。這是一個巨大的優勢,所以處理器會盡量將快取線保留在Exclusive狀態,而不是Shared狀態。只有在資訊不可用時,才退而求其次選擇shared。放棄Exclusive不會引起任何功能缺失,但會導致效能下降,因為E→M要遠遠快於S→M。
從以上的說明中應該已經可以看出,在多處理器環境下,哪一步的代價比較大了。填充快取的代價當然還是很高,但我們還需要留意RFO訊息。一旦涉及RFO,操作就快不起來了。
RFO在兩種情況下是必需的:
- 執行緒從一個處理器遷移到另一個處理器,需要將所有快取線移到新處理器。
- 某條快取線確實需要被兩個處理器使用。{對於同一處理器的兩個核心,也有同樣的情況,只是代價稍低。RFO訊息可能會被髮送多次。}
多執行緒或多程式的程式總是需要同步,而這種同步依賴記憶體來實現。因此,有些RFO訊息是合理的,但仍然需要儘量降低傳送頻率。除此以外,還有其它來源的RFO。在第6節中,我們將解釋這些場景。快取一致性協議的訊息必須發給系統中所有處理器。只有當協議確定已經給過所有處理器響應機會之後,才能進行狀態躍遷。也就是說,協議的速度取決於最長響應時間。{這也是現在能看到三插槽AMD Opteron系統的原因。這類系統只有三個超級鏈路(hyperlink),其中一個連線南橋,每個處理器之間都只有一跳的距離。}匯流排上可能會發生衝突,NUMA系統的延時很大,突發的流量會拖慢通訊。這些都是讓我們避免無謂流量的充足理由。
此外,關於多處理器還有一個問題。雖然它的影響與具體機器密切相關,但根源是唯一的——FSB是共享的。在大多數情況下,所有處理器通過唯一的匯流排連線到記憶體控制器(參見圖2.1)。如果一個處理器就能佔滿匯流排(十分常見),那麼共享匯流排的兩個或四個處理器顯然只會得到更有限的頻寬。
即使每個處理器有自己連線記憶體控制器的匯流排,如圖2.2,但還需要通往記憶體模組的匯流排。一般情況下,這種匯流排只有一條。退一步說,即使像圖2.2那樣不止一條,對同一個記憶體模組的併發訪問也會限制它的頻寬。
對於每個處理器擁有本地記憶體的AMD模型來說,也是同樣的問題。的確,所有處理器可以非常快速地同時訪問它們自己的記憶體。但是,多執行緒呢?多程式呢?它們仍然需要通過訪問同一塊記憶體來進行同步。
對同步來說,有限的頻寬嚴重地制約著併發度。程式需要更加謹慎的設計,將不同處理器訪問同一塊記憶體的機會降到最低。以下的測試展示了這一點,還展示了與多執行緒程式碼相關的其它效果。
多執行緒測量
為了幫助大家理解問題的嚴重性,我們來看一些曲線圖,主角也是前文的那個程式。只不過這一次,我們執行多個執行緒,並測量這些執行緒中最快那個的執行時間。也就是說,等它們全部執行完是需要更長時間的。我們用的機器有4個處理器,而測試是做多跑4個執行緒。所有處理器共享同一條通往記憶體控制器的匯流排,另外,通往記憶體模組的匯流排也只有一條。
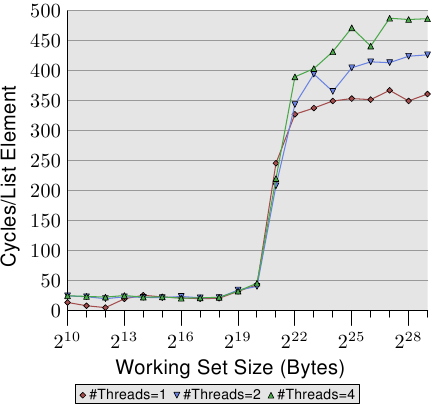
圖3.19: 順序讀操作,多執行緒
圖3.19展示了順序讀訪問時的效能,元素為128位元組長(64位計算機,NPAD=15)。對於單執行緒的曲線,我們預計是與圖3.11相似,只不過是換了一臺機器,所以實際的數字會有些小差別。
更重要的部分當然是多執行緒的環節。由於是隻讀,不會去修改記憶體,不會嘗試同步。但即使不需要RFO,而且所有快取線都可共享,效能仍然分別下降了18%(雙執行緒)和34%(四執行緒)。由於不需要在處理器之間傳輸快取,因此這裡的效能下降完全由以下兩個瓶頸之一或同時引起: 一是從處理器到記憶體控制器的共享匯流排,二是從記憶體控制器到記憶體模組的共享匯流排。當工作集超過L3後,三種情況下都要預取新元素,而即使是雙執行緒,可用的頻寬也無法滿足線性擴充套件(無懲罰)。
當加入修改之後,場面更加難看了。圖3.20展示了順序遞增測試的結果。
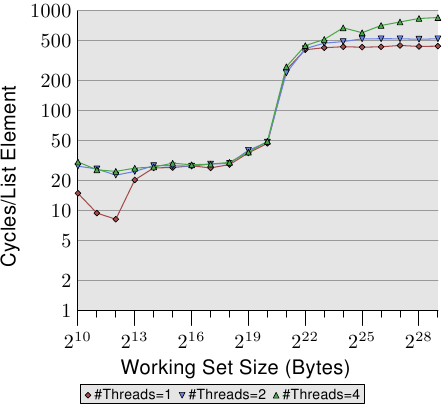
圖3.20: 順序遞增,多執行緒
圖中Y軸採用的是對數刻度,不要被看起來很小的差值欺騙了。現在,雙執行緒的效能懲罰仍然是18%,但四執行緒的懲罰飆升到了93%!原因在於,採用四執行緒時,預取的流量與寫回的流量加在一起,佔滿了整個匯流排。
我們用對數刻度來展示L1d範圍的結果。可以發現,當超過一個執行緒後,L1d就無力了。單執行緒時,僅當工作集超過L1d時訪問時間才會超過20個週期,而多執行緒時,即使在很小的工作集情況下,訪問時間也達到了那個水平。
這裡並沒有揭示問題的另一方面,主要是用這個程式很難進行測量。問題是這樣的,我們的測試程式修改了記憶體,所以本應看到RFO的影響,但在結果中,我們並沒有在L2階段看到更大的開銷。原因在於,要看到RFO的影響,程式必須使用大量記憶體,而且所有執行緒必須同時訪問同一塊記憶體。如果沒有大量的同步,這是很難實現的,而如果加入同步,則會佔滿執行時間。
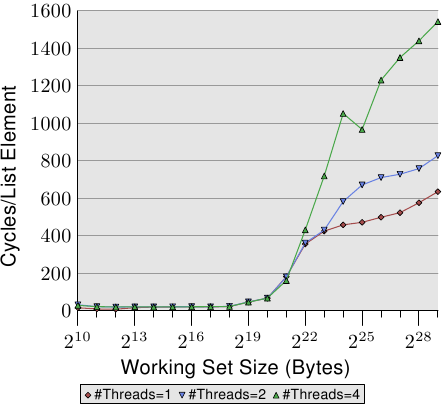
圖3.21: 隨機的Addnextlast,多執行緒
最後,在圖3.21中,我們展示了隨機訪問的Addnextlast測試的結果。這裡主要是為了讓大家感受一下這些巨大到爆的數字。極端情況下,甚至用了1500個週期才處理完一個元素。如果加入更多執行緒,真是不可想象哪。我們把多執行緒的效能總結了一下:
表3.3: 多執行緒的效能
#Threads Seq Read Seq Inc Rand Add 2 1.69 1.69 1.54 4 2.98 2.07 1.65
這個表展示了圖3.21中多執行緒執行大工作集時的效能。表中的數字表示測試程式在使用多執行緒處理大工作集時可能達到的最大加速因子。雙執行緒和四執行緒的理論最大加速因子分別是2和4。從表中資料來看,雙執行緒的結果還能接受,但四執行緒的結果表明,擴充套件到雙執行緒以上是沒有什麼意義的,帶來的收益可以忽略不計。只要我們把圖3.21換個方式呈現,就可以很容易看清這一點。
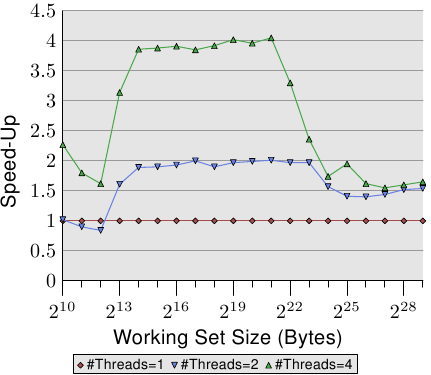
圖3.22: 通過並行化實現的加速因子
圖3.22中的曲線展示了加速因子,即多執行緒相對於單執行緒所能獲取的效能加成值。測量值的精確度有限,因此我們需要忽略比較小的那些數字。可以看到,在L2與L3範圍內,多執行緒基本可以做到線性加速,雙執行緒和四執行緒分別達到了2和4的加速因子。但是,一旦工作集的大小超出L3,曲線就崩塌了,雙執行緒和四執行緒降到了基本相同的數值(參見表3.3中第4列)。也是部分由於這個原因,我們很少看到4CPU以上的主機板共享同一個記憶體控制器。如果需要配置更多處理器,我們只能選擇其它的實現方式(參見第5節)。
可惜,上圖中的資料並不是普遍情況。在某些情況下,即使工作集能夠放入末級快取,也無法實現線性加速。實際上,這反而是正常的,因為普通的執行緒都有一定的耦合關係,不會像我們的測試程式這樣完全獨立。而反過來說,即使是很大的工作集,即使是兩個以上的執行緒,也是可以通過並行化受益的,但是需要程式設計師的聰明才智。我們會在第6節進行一些介紹。
特例: 超執行緒
由CPU實現的超執行緒(有時又叫對稱多執行緒,SMT)是一種比較特殊的情況,每個執行緒並不能真正併發地執行。它們共享著除暫存器外的絕大多數處理資源。每個核心和CPU仍然是並行工作的,但核心上的執行緒則受到這個限制。理論上,每個核心可以有大量執行緒,不過到目前為止,Intel的CPU最多隻有兩個執行緒。CPU負責對各執行緒進行分時多工,但這種複用本身並沒有多少厲害。它真正的優勢在於,CPU可以在當前執行的超執行緒發生延遲時,排程另一個執行緒。這種延遲一般由記憶體訪問引起。
如果兩個執行緒執行在一個超執行緒核心上,那麼只有當兩個執行緒合起來的執行時間少於單執行緒執行時間時,效率才會比較高。我們可以將通常先後發生的記憶體訪問疊合在一起,以實現這個目標。有一個簡單的計算公式,可以幫助我們計算如果需要某個加速因子,最少需要多少的快取命中率。
程式的執行時間可以通過一個只有一級快取的簡單模型來進行估算(參見[htimpact]):
T exe = N[(1-F mem )T proc + F mem (G hit T cache + (1-G hit )T miss )]
各變數的含義如下:
N = 指令數 Fmem = N中訪問記憶體的比例 Ghit = 命中快取的比例 Tproc = 每條指令所用的週期數 Tcache = 快取命中所用的週期數 Tmiss = 緩衝未命中所用的週期數 Texe = 程式的執行時間
為了讓任何判讀使用雙執行緒,兩個執行緒之中任一執行緒的執行時間最多為單執行緒指令的一半。兩者都有一個唯一的變數快取命中數。 如果我們要解決最小快取命中率相等的問題需要使我們獲得的執行緒的執行率不少於50%或更多,如圖 3.23.
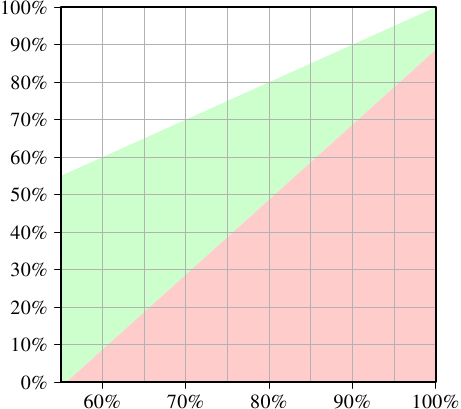
圖 3.23: 最小快取命中率-加速
X軸表示單執行緒指令的快取命中率Ghit,Y軸表示多執行緒指令所需的快取命中率。這個值永遠不能高於單執行緒命中率,否則,單執行緒指令也會使用改良的指令。為了使單執行緒的命中率在低於55%的所有情況下優於使用多執行緒,cup要或多或少的足夠空閒因為快取丟失會執行另外一個超執行緒。
綠色區域是我們的目標。如果執行緒的速度沒有慢過50%,而每個執行緒的工作量只有原來的一半,那麼它們合起來的耗時應該會少於單執行緒的耗時。對我們用的示例系統來說(使用超執行緒的P4機器),如果單執行緒程式碼的命中率為60%,那麼多執行緒程式碼至少要達到10%才能獲得收益。這個要求一般來說還是可以做到的。但是,如果單執行緒程式碼的命中率達到了95%,那麼多執行緒程式碼要做到80%才行。這就很難了。而且,這裡還涉及到超執行緒,在兩個超執行緒的情況下,每個超執行緒只能分到一半的有效快取。因為所有超執行緒是使用同一個快取來裝載資料的,如果兩個超執行緒的工作集沒有重疊,那麼原始的95%也會被打對摺——47%,遠低於80%。
因此,超執行緒只在某些情況下才比較有用。單執行緒程式碼的快取命中率必須低到一定程度,從而使快取容量變小時新的命中率仍能滿足要求。只有在這種情況下,超執行緒才是有意義的。在實踐中,採用超執行緒能否獲得更快的結果,取決於處理器能否有效地將每個程式的等待時間與其它程式的執行時間重疊在一起。並行化也需要一定的開銷,需要加到總的執行時間裡,這個開銷往往是不能忽略的。
在6.3.4節中,我們會介紹一種技術,它將多個執行緒通過公用快取緊密地耦合起來。這種技術適用於許多場合,前提是程式設計師們樂意花費時間和精力擴充套件自己的程式碼。
如果兩個超執行緒執行完全不同的程式碼(兩個執行緒就像被當成兩個處理器,分別執行不同程式),那麼快取容量就真的會降為一半,導致緩衝未命中率大為攀升,這一點應該是很清楚的。這樣的排程機制是很有問題的,除非你的快取足夠大。所以,除非程式的工作集設計得比較合理,能夠確實從超執行緒獲益,否則還是建議在BIOS中把超執行緒功能關掉。{我們可能會因為另一個原因 開啟 超執行緒,那就是除錯,因為SMT在查詢並行程式碼的問題方面真的非常好用。}
3.3.5 其它細節
我們已經介紹了地址的組成,即標籤、集合索引和偏移三個部分。那麼,實際會用到什麼樣的地址呢?目前,處理器一般都向程式提供虛擬地址空間,意味著我們有兩種不同的地址: 虛擬地址和實體地址。
虛擬地址有個問題——並不唯一。隨著時間的變化,虛擬地址可以變化,指向不同的實體地址。同一個地址在不同的程式裡也可以表示不同的實體地址。那麼,是不是用實體地址會比較好呢?
問題是,處理器指令用的虛擬地址,而且需要在記憶體管理單元(MMU)的協助下將它們翻譯成實體地址。這並不是一個很小的操作。在執行指令的管線(pipeline)中,實體地址只能在很後面的階段才能得到。這意味著,快取邏輯需要在很短的時間裡判斷地址是否已被快取過。而如果可以使用虛擬地址,快取查詢操作就可以更早地發生,一旦命中,就可以馬上使用記憶體的內容。結果就是,使用虛擬記憶體後,可以讓管線把更多記憶體訪問的開銷隱藏起來。
處理器的設計人員們現在使用虛擬地址來標記第一級快取。這些快取很小,很容易被清空。在程式頁表樹發生變更的情況下,至少是需要清空部分快取的。如果處理器擁有指定變更地址範圍的指令,那麼可以避免快取的完全重新整理。由於一級快取L1i及L1d的時延都很小(~3週期),基本上必須使用虛擬地址。
對於更大的快取,包括L2和L3等,則需要以實體地址作為標籤。因為這些快取的時延比較大,虛擬到實體地址的對映可以在允許的時間裡完成,而且由於主存時延的存在,重新填充這些快取會消耗比較長的時間,重新整理的代價比較昂貴。
一般來說,我們並不需要了解這些快取處理地址的細節。我們不能更改它們,而那些可能影響效能的因素,要麼是應該避免的,要麼是有很高代價的。填滿快取是不好的行為,快取線都落入同一個集合,也會讓快取早早地出問題。對於後一個問題,可以通過快取虛擬地址來避免,但作為一個使用者級程式,是不可能避免快取實體地址的。我們唯一可以做的,是盡最大努力不要在同一個程式裡用多個虛擬地址對映同一個實體地址。
另一個細節對程式設計師們來說比較乏味,那就是快取的替換策略。大多數快取會優先逐出最近最少使用(Least Recently Used,LRU)的元素。這往往是一個效果比較好的策略。在關聯性很大的情況下(隨著以後核心數的增加,關聯性勢必會變得越來越大),維護LRU列表變得越來越昂貴,於是我們開始看到其它的一些策略。
在快取的替換策略方面,程式設計師可以做的事情不多。如果快取使用實體地址作為標籤,我們是無法找出虛擬地址與快取集之間關聯的。有可能會出現這樣的情形: 所有邏輯頁中的快取線都對映到同一個快取集,而其它大部分快取卻空閒著。即使有這種情況,也只能依靠OS進行合理安排,避免頻繁出現。
虛擬化的出現使得這一切變得更加複雜。現在不僅作業系統可以控制實體記憶體的分配。虛擬機器監視器(VMM,也稱為 hypervisor)也負責分配記憶體。
對程式設計師來說,最好 a) 完全使用邏輯記憶體頁面 b) 在有意義的情況下,使用盡可能大的頁面大小來分散實體地址。更大的頁面大小也有其他好處,不過這是另一個話題(見第4節)。
3.4 指令快取
其實,不光處理器使用的資料被快取,它們執行的指令也是被快取的。只不過,指令快取的問題相對來說要少得多,因為:
- 執行的程式碼量取決於程式碼大小。而程式碼大小通常取決於問題複雜度。問題複雜度則是固定的。
- 程式的資料處理邏輯是程式設計師設計的,而程式的指令卻是編譯器生成的。編譯器的作者知道如何生成優良的程式碼。
- 程式的流向比資料訪問模式更容易預測。現如今的CPU很擅長模式檢測,對預取很有利。
- 程式碼永遠都有良好的時間區域性性和空間區域性性。
有一些準則是需要程式設計師們遵守的,但大都是關於如何使用工具的,我們會在第6節介紹它們。而在這裡我們只介紹一下指令快取的技術細節。
隨著CPU的核心頻率大幅上升,快取與核心的速度差越拉越大,CPU的處理開始管線化。也就是說,指令的執行分成若干階段。首先,對指令進行解碼,隨後,準備引數,最後,執行它。這樣的管線可以很長(例如,Intel的Netburst架構超過了20個階段)。在管線很長的情況下,一旦發生延誤(即指令流中斷),需要很長時間才能恢復速度。管線延誤發生在這樣的情況下: 下一條指令未能正確預測,或者裝載下一條指令耗時過長(例如,需要從記憶體讀取時)。
為了解決這個問題,CPU的設計人員們在分支預測上投入大量時間和晶片資產(chip real estate),以降低管線延誤的出現頻率。
在CISC處理器上,指令的解碼階段也需要一些時間。x86及x86-64處理器尤為嚴重。近年來,這些處理器不再將指令的原始位元組序列存入L1i,而是快取解碼後的版本。這樣的L1i被叫做“追蹤快取(trace cache)”。追蹤快取可以在命中的情況下讓處理器跳過管線最初的幾個階段,在管線發生延誤時尤其有用。
前面說過,L2以上的快取是統一快取,既儲存程式碼,也儲存資料。顯然,這裡儲存的程式碼是原始位元組序列,而不是解碼後的形式。
在提高效能方面,與指令快取相關的只有很少的幾條準則:
- 生成儘量少的程式碼。也有一些例外,如出於管線化的目的需要更多的程式碼,或使用小程式碼會帶來過高的額外開銷。
- 儘量幫助處理器作出良好的預取決策,可以通過程式碼佈局或顯式預取來實現。
這些準則一般會由編譯器的程式碼生成階段強制執行。至於程式設計師可以參與的部分,我們會在第6節介紹。
3.4.1 自修改的程式碼
在計算機的早期歲月裡,記憶體十分昂貴。人們想盡千方百計,只為了儘量壓縮程式容量,給資料多留一些空間。其中,有一種方法是修改程式自身,稱為自修改程式碼(SMC)。現在,有時候我們還能看到它,一般是出於提高效能的目的,也有的是為了攻擊安全漏洞。
一般情況下,應該避免SMC。雖然一般情況下沒有問題,但有時會由於執行錯誤而出現效能問題。顯然,發生改變的程式碼是無法放入追蹤快取(追蹤快取放的是解碼後的指令)的。即使沒有使用追蹤快取(程式碼還沒被執行或有段時間沒執行),處理器也可能會遇到問題。如果某個進入管線的指令發生了變化,處理器只能扔掉目前的成果,重新開始。在某些情況下,甚至需要丟棄處理器的大部分狀態。
最後,由於處理器認為內碼表是不可修改的(這是出於簡單化的考慮,而且在99.9999999%情況下確實是正確的),L1i用到並不是MESI協議,而是一種簡化後的SI協議。這樣一來,如果萬一檢測到修改的情況,就需要作出大量悲觀的假設。
因此,對於SMC,強烈建議能不用就不用。現在記憶體已經不再是一種那麼稀缺的資源了。最好是寫多個函式,而不要根據需要把一個函式改來改去。也許有一天可以把SMC變成可選項,我們就能通過這種方式檢測入侵程式碼。如果一定要用SMC,應該讓寫操作越過快取,以免由於L1i需要L1d裡的資料而產生問題。更多細節,請參見6.1節。
在Linux上,判斷程式是否包含SMC是很容易的。利用正常工具鏈(toolchain)構建的程式程式碼都是防寫(write-protected)的。程式設計師需要在連結時施展某些關鍵的魔術才能生成可寫的內碼表。現代的Intel x86和x86-64處理器都有統計SMC使用情況的專用計數器。通過這些計數器,我們可以很容易判斷程式是否包含SMC,即使它被准許執行。
3.5 快取未命中的因素
我們已經看過記憶體訪問沒有命中快取時,那陡然猛漲的高昂代價。但是有時候,這種情況又是無法避免的,因此我們需要對真正的代價有所認識,並學習如何緩解這種局面。
3.5.1 快取與記憶體頻寬
為了更好地理解處理器的能力,我們測量了各種理想環境下能夠達到的頻寬值。由於不同處理器的版本差別很大,所以這個測試比較有趣,也因為如此,這一節都快被測試資料灌滿了。我們使用了x86和x86-64處理器的SSE指令來裝載和儲存資料,每次16位元組。工作集則與其它測試一樣,從1kB增加到512MB,測量的具體物件是每個週期所處理的位元組數。
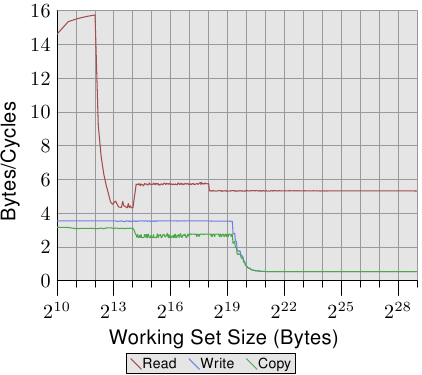
圖3.24: P4的頻寬
圖3.24展示了一顆64位Intel Netburst處理器的效能圖表。當工作集能夠完全放入L1d時,處理器的每個週期可以讀取完整的16位元組資料,即每個週期執行一條裝載指令(moveaps指令,每次移動16位元組的資料)。測試程式並不對資料進行任何處理,只是測試讀取指令本身。當工作集增大,無法再完全放入L1d時,效能開始急劇下降,跌至每週期6位元組。在218工作集處出現的臺階是由於DTLB快取耗盡,因此需要對每個新頁施加額外處理。由於這裡的讀取是按順序的,預取機制可以完美地工作,而FSB能以5.3位元組/週期的速度傳輸內容。但預取的資料並不進入L1d。當然,真實世界的程式永遠無法達到以上的數字,但我們可以將它們看作一系列實際上的極限值。
更令人驚訝的是寫操作和複製操作的效能。即使是在很小的工作集下,寫操作也始終無法達到4位元組/週期的速度。這意味著,Intel為Netburst處理器的L1d選擇了寫通(write-through)模式,所以寫入效能受到L2速度的限制。同時,這也意味著,複製測試的效能不會比寫入測試差太多(複製測試是將某塊記憶體的資料拷貝到另一塊不重疊的記憶體區),因為讀操作很快,可以與寫操作實現部分重疊。最值得關注的地方是,兩個操作在工作集無法完全放入L2後出現了嚴重的效能滑坡,降到了0.5位元組/週期!比讀操作慢了10倍!顯然,如果要提高程式效能,優化這兩個操作更為重要。
再來看圖3.25,它來自同一顆處理器,只是執行雙執行緒,每個執行緒分別執行在處理器的一個超執行緒上。

圖3.25: P4開啟兩個超執行緒時的頻寬表現
圖3.25採用了與圖3.24相同的刻度,以方便比較兩者的差異。圖3.25中的曲線抖動更多,是由於採用雙執行緒的緣故。結果正如我們預期,由於超執行緒共享著幾乎所有資源(僅除暫存器外),所以每個超執行緒只能得到一半的快取和頻寬。所以,即使每個執行緒都要花上許多時間等待記憶體,從而把執行時間讓給另一個執行緒,也是無濟於事——因為另一個執行緒也同樣需要等待。這裡恰恰展示了使用超執行緒時可能出現的最壞情況。
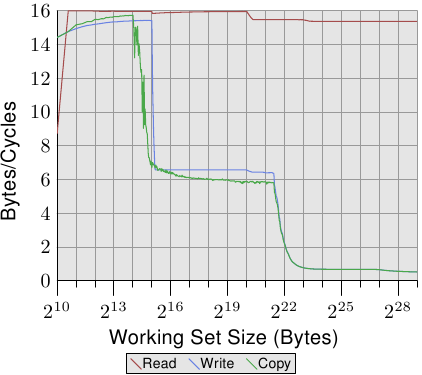
圖3.26: Core 2的頻寬表現
再來看Core 2處理器的情況。看看圖3.26和圖3.27,再對比下P4的圖3.24和3.25,可以看出不小的差異。Core 2是一顆雙核處理器,有著共享的L2,容量是P4 L2的4倍。但更大的L2只能解釋寫操作的效能下降出現較晚的現象。
當然還有更大的不同。可以看到,讀操作的效能在整個工作集範圍內一直穩定在16位元組/週期左右,在220處的下降同樣是由於DTLB的耗盡引起。能夠達到這麼高的數字,不但表明處理器能夠預取資料,並且按時完成傳輸,而且還意味著,預取的資料是被裝入L1d的。
寫/複製操作的效能與P4相比,也有很大差異。處理器沒有采用寫通策略,寫入的資料留在L1d中,只在必要時才逐出。這使得寫操作的速度可以逼近16位元組/週期。一旦工作集超過L1d,效能即飛速下降。由於Core 2讀操作的效能非常好,所以兩者的差值顯得特別大。當工作集超過L2時,兩者的差值甚至超過20倍!但這並不表示Core 2的效能不好,相反,Core 2永遠都比Netburst強。

圖3.27: Core 2執行雙執行緒時的頻寬表現
在圖3.27中,啟動雙執行緒,各自執行在Core 2的一個核心上。它們訪問相同的記憶體,但不需要完美同步。從結果上看,讀操作的效能與單執行緒並無區別,只是多了一些多執行緒情況下常見的抖動。
有趣的地方來了——當工作集小於L1d時,寫操作與複製操作的效能很差,就好像資料需要從記憶體讀取一樣。兩個執行緒彼此競爭著同一個記憶體位置,於是不得不頻頻傳送RFO訊息。問題的根源在於,雖然兩個核心共享著L2,但無法以L2的速度處理RFO請求。而當工作集超過L1d後,效能出現了迅猛提升。這是因為,由於L1d容量不足,於是將被修改的條目重新整理到共享的L2。由於L1d的未命中可以由L2滿足,只有那些尚未重新整理的資料才需要RFO,所以出現了這樣的現象。這也是這些工作集情況下速度下降一半的原因。這種漸進式的行為也與我們期待的一致: 由於每個核心共享著同一條FSB,每個核心只能得到一半的FSB頻寬,因此對於較大的工作集來說,每個執行緒的效能大致相當於單執行緒時的一半。
由於同一個廠商的不同處理器之間都存在著巨大差異,我們沒有理由不去研究一下其它廠商處理器的效能。圖3.28展示了AMD家族10h Opteron處理器的效能。這顆處理器有64kB的L1d、512kB的L2和2MB的L3,其中L3快取由所有核心所共享。

圖3.28: AMD家族10h Opteron的頻寬表現
大家首先應該會注意到,在L1d快取足夠的情況下,這個處理器每個週期能處理兩條指令。讀操作的效能超過了32位元組/週期,寫操作也達到了18.7位元組/週期。但是,不久,讀操作的曲線就急速下降,跌到2.3位元組/週期,非常差。處理器在這個測試中並沒有預取資料,或者說,沒有有效地預取資料。
另一方面,寫操作的曲線隨幾級快取的容量而流轉。在L1d階段達到最高效能,隨後在L2階段下降到6位元組/週期,在L3階段進一步下降到2.8位元組/週期,最後,在工作集超過L3後,降到0.5位元組/週期。它在L1d階段超過了Core 2,在L2階段基本相當(Core 2的L2更大一些),在L3及主存階段比Core 2慢。
複製的效能既無法超越讀操作的效能,也無法超越寫操作的效能。因此,它的曲線先是被讀效能壓制,隨後又被寫效能壓制。
圖3.29顯示的是Opteron處理器在多執行緒時的效能表現。
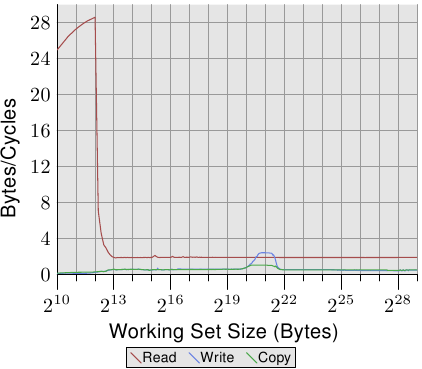
圖3.29: AMD Fam 10h在雙執行緒時的頻寬表現
讀操作的效能沒有受到很大的影響。每個執行緒的L1d和L2表現與單執行緒下相仿,L3的預取也依然表現不佳。兩個執行緒並沒有過渡爭搶L3。問題比較大的是寫操作的效能。兩個執行緒共享的所有資料都需要經過L3,而這種共享看起來卻效率很差。即使是在L3足夠容納整個工作集的情況下,所需要的開銷仍然遠高於L3的訪問時間。再來看圖3.27,可以發現,在一定的工作集範圍內,Core 2處理器能以共享的L2快取的速度進行處理。而Opteron處理器只能在很小的一個範圍內實現相似的效能,而且,它僅僅只能達到L3的速度,無法與Core 2的L2相比。
3.5.2 關鍵字載入
記憶體以比快取線還小的塊從主儲存器向快取傳送。如今64位可一次性傳送,快取線的大小為64或128位元。這意味著每個快取線需要8或16次傳送。
DRAM晶片可以以觸發模式傳送這些64位的塊。這使得不需要記憶體控制器的進一步指令和可能伴隨的延遲,就可以將快取線充滿。如果處理器預取了快取,這有可能是最好的操作方式。
如果程式在訪問資料或指令快取時沒有命中(這可能是強制性未命中或容量性未命中,前者是由於資料第一次被使用,後者是由於容量限制而將快取線逐出),情況就不一樣了。程式需要的並不總是快取線中的第一個字,而資料塊的到達是有先後順序的,即使是在突發模式和雙倍傳輸率下,也會有明顯的時間差,一半在4個CPU週期以上。舉例來說,如果程式需要快取線中的第8個字,那麼在首字抵達後它還需要額外等待30個週期以上。
當然,這樣的等待並不是必需的。事實上,記憶體控制器可以按不同順序去請求快取線中的字。當處理器告訴它,程式需要快取中具體某個字,即「關鍵字(critical word)」時,記憶體控制器就會先請求這個字。一旦請求的字抵達,雖然快取線的剩餘部分還在傳輸中,快取的狀態還沒有達成一致,但程式已經可以繼續執行。這種技術叫做關鍵字優先及較早重啟(Critical Word First & Early Restart)。
現在的處理器都已經實現了這一技術,但有時無法運用。比如,預取操作的時候,並不知道哪個是關鍵字。如果在預取的中途請求某條快取線,處理器只能等待,並不能更改請求的順序。
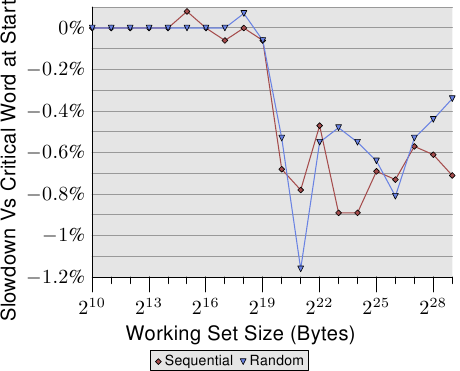
圖3.30: 關鍵字位於快取線尾時的表現
在關鍵字優先技術生效的情況下,關鍵字的位置也會影響結果。圖3.30展示了下一個測試的結果,圖中表示的是關鍵字分別線上首和線尾時的效能對比情況。元素大小為64位元組,等於快取線的長度。圖中的噪聲比較多,但仍然可以看出,當工作集超過L2後,關鍵字處於線尾情況下的效能要比線首情況下低0.7%左右。而順序訪問時受到的影響更大一些。這與我們前面提到的預取下條線時可能遇到的問題是相符的。
3.5.3 快取設定
快取放置的位置與超執行緒,核心和處理器之間的關係,不在程式設計師的控制範圍之內。但是程式設計師可以決定執行緒執行的位置,接著快取記憶體與使用的CPU的關係將變得非常重要。
這裡我們將不會深入(探討)什麼時候選擇什麼樣的核心以執行執行緒的細節。我們僅僅描述了在設定關聯執行緒的時候,程式設計師需要考慮的系統結構的細節。
超執行緒,通過定義,共享除去暫存器集以外的所有資料。包括 L1 快取。這裡沒有什麼可以多說的。多核處理器的獨立核心帶來了一些樂趣。每個核心都至少擁有自己的 L1 快取。除此之外,下面列出了一些不同的特性:
- 早期多核心處理器有獨立的 L2 快取且沒有更高層級的快取。
- 之後英特爾的雙核心處理器模型擁有共享的L2 快取。對四核處理器,則分對擁有獨立的L2 快取,且沒有更高層級的快取。
- AMD 家族的 10h 處理器有獨立的 L2 快取以及一個統一的L3 快取。
關於各種處理器模型的優點,已經在它們各自的宣傳手冊裡寫得夠多了。在每個核心的工作集互不重疊的情況下,獨立的L2擁有一定的優勢,單執行緒的程式可以表現優良。考慮到目前實際環境中仍然存在大量類似的情況,這種方法的表現並不會太差。不過,不管怎樣,我們總會遇到工作集重疊的情況。如果每個快取都儲存著某些通用執行庫的常用部分,那麼很顯然是一種浪費。
如果像Intel的雙核處理器那樣,共享除L1外的所有快取,則會有一個很大的優點。如果兩個核心的工作集重疊的部分較多,那麼綜合起來的可用快取容量會變大,從而允許容納更大的工作集而不導致效能的下降。如果兩者的工作集並不重疊,那麼則是由Intel的高階智慧快取管理(Advanced Smart Cache management)發揮功用,防止其中一個核心壟斷整個快取。
即使每個核心只使用一半的快取,也會有一些摩擦。快取需要不斷衡量每個核心的用量,在進行逐出操作時可能會作出一些比較差的決定。我們來看另一個測試程式的結果。
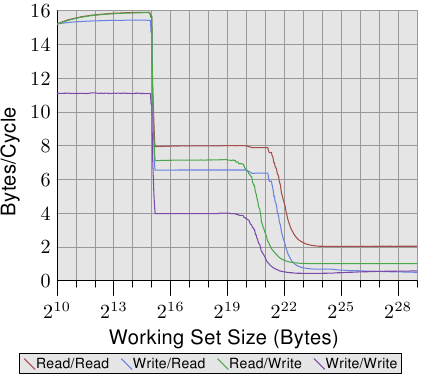
圖3.31: 兩個程式的頻寬表現
這次,測試程式兩個程式,第一個程式不斷用SSE指令讀/寫2MB的記憶體資料塊,選擇2MB,是因為它正好是Core 2處理器L2快取的一半,第二個程式則是讀/寫大小變化的記憶體區域,我們把這兩個程式分別固定在處理器的兩個核心上。圖中顯示的是每個週期讀/寫的位元組數,共有4條曲線,分別表示不同的讀寫搭配情況。例如,標記為讀/寫(read/write)的曲線代表的是後臺程式進行寫操作(固定2MB工作集),而被測量程式進行讀操作(工作集從小到大)。
圖中最有趣的是220到223之間的部分。如果兩個核心的L2是完全獨立的,那麼所有4種情況下的效能下降均應發生在221到222之間,也就是L2快取耗盡的時候。但從圖上來看,實際情況並不是這樣,特別是背景程式進行寫操作時尤為明顯。當工作集達到1MB(220)時,效能即出現惡化,兩個程式並沒有共享記憶體,因此並不會產生RFO訊息。所以,完全是快取逐出操作引起的問題。目前這種智慧的快取處理機制有一個問題,每個核心能實際用到的快取更接近1MB,而不是理論上的2MB。如果未來的處理器仍然保留這種多核共享快取模式的話,我們唯有希望廠商會把這個問題解決掉。
推出擁有雙L2快取的4核處理器僅僅只是一種臨時措施,是開發更高階快取之前的替代方案。與獨立插槽及雙核處理器相比,這種設計並沒有帶來多少效能提升。兩個核心是通過同一條匯流排(被外界看作FSB)進行通訊,並沒有什麼特別快的資料交換通道。
未來,針對多核處理器的快取將會包含更多層次。AMD的10h家族是一個開始,至於會不會有更低階共享快取的出現,還需要我們拭目以待。我們有必要引入更多級別的快取,因為頻繁使用的快取記憶體不可能被許多核心共用,否則會對效能造成很大的影響。我們也需要更大的高關聯性快取,它們的數量、容量和關聯性都應該隨著共享核心數的增長而增長。巨大的L3和適度的L2應該是一種比較合理的選擇。L3雖然速度較慢,但也較少使用。
對於程式設計師來說,不同的快取設計就意味著排程決策時的複雜性。為了達到最高的效能,我們必須掌握工作負載的情況,必須瞭解機器架構的細節。好在我們在判斷機器架構時還是有一些支援力量的,我們會在後面的章節介紹這些介面。
3.5.4 FSB的影響
FSB在效能中扮演了核心角色。快取資料的存取速度受制於記憶體通道的速度。我們做一個測試,在兩臺機器上分別跑同一個程式,這兩臺機器除了記憶體模組的速度有所差異,其它完全相同。圖3.32展示了Addnext0測試(將下一個元素的pad[0]加到當前元素的pad[0]上)在這兩臺機器上的結果(NPAD=7,64位機器)。兩臺機器都採用Core 2處理器,一臺使用667MHz的DDR2記憶體,另一臺使用800MHz的DDR2記憶體(比前一臺增長20%)。
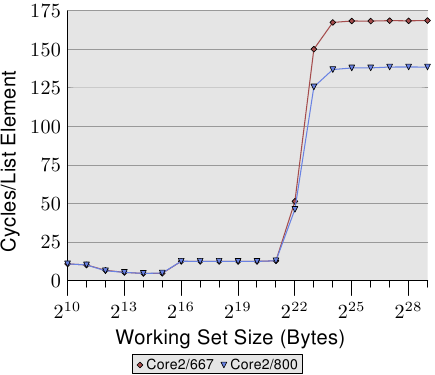
圖3.32: FSB速度的影響
圖上的數字表明,當工作集大到對FSB造成壓力的程度時,高速FSB確實會帶來巨大的優勢。在我們的測試中,效能的提升達到了18.5%,接近理論上的極限。而當工作集比較小,可以完全納入快取時,FSB的作用並不大。當然,這裡我們只測試了一個程式的情況,在實際環境中,系統往往執行多個程式,工作集是很容易超過快取容量的。
如今,一些英特爾的處理器,支援前端匯流排(FSB)的速度高達1,333 MHz,這意味著速度有另外60%的提升。將來還會出現更高的速度。速度是很重要的,工作集會更大,快速的RAM和高FSB速度的記憶體肯定是值得投資的。我們必須小心使用它,因為即使處理器可以支援更高的前端匯流排速度,但是主機板的北橋晶片可能不會。使用時,檢查它的規範是至關重要的。相關文章
- 每個程式設計師都應該瞭解的記憶體知識程式設計師記憶體
- 每個程式設計師都應該瞭解的“虛擬記憶體”知識程式設計師記憶體
- 每個程式設計師都應該瞭解的硬體知識程式設計師
- CPU快取記憶體快取記憶體
- 每個程式設計師都應該瞭解的一件事程式設計師
- 多核cpu、cpu快取記憶體、快取一致性協議、快取行、記憶體快取記憶體協議
- 談談CPU快取記憶體快取記憶體
- CPU快取和記憶體屏障快取記憶體
- 每個程式設計師都應該讀的書程式設計師
- 人人都應該知道的CPU快取執行效率快取
- 每一個程式設計師都應當瞭解的11句話程式設計師
- 關於時間,每個程式設計師都應瞭解的事程式設計師
- CPU、記憶體、快取的關係詳細解釋!記憶體快取
- 每個程式設計師都應該成為架構師程式設計師架構
- 每個程式設計師都應瞭解的關於時間的事程式設計師
- 為SSD程式設計(6):總結—每個程式設計師都應該瞭解的固態硬碟知識程式設計師硬碟
- 每個程式設計師都應該讀《Unix程式設計藝術》程式設計師
- 每個工程師都應該瞭解的:聊聊冪等工程師
- 每個程式設計師都應該知道的 15 個最佳 PHP 庫程式設計師PHP
- 每個程式設計師都應該知道的基礎數論程式設計師
- 每個前端工程師都應該瞭解的HTML5.2前端工程師HTML
- 程式設計師都應該瞭解哪些安全知識程式設計師
- 關於Web開發,每個程式設計師都應瞭解的那些事Web程式設計師
- 每個MySQL開發者都應該瞭解的10個技巧MySql
- 國外程式設計師推薦:每個程式設計師都應該讀的非程式設計書程式設計師
- Rework:每個程式設計師都應該讀的一本書程式設計師
- 每個程式設計師都應該學會分解複雜的方法程式設計師
- 每個前端工程師都應該瞭解的圖片知識前端工程師
- 每個程式設計師都應該參加一次 GDD程式設計師
- 每個程式設計師都應該知道的下一個程式語言——Kotlin程式設計師Kotlin
- 每個程式設計師都應該學習使用Python或Ruby程式設計師Python
- 每個程式設計師都該閱讀的10本書程式設計師
- 每個程式設計師都該知道的編碼準則程式設計師
- 每個程式設計師應該知道的12個API程式設計師API
- 每個Python新手都應該知道的程式設計技巧Python程式設計
- 每個Android開發者都應該瞭解的資源列表Android
- 每個程式設計師應該知道12件事程式設計師
- 為什麼每個程式設計師都應該懂點前端知識?程式設計師前端