[QingCloud Insight 2016] How do we build TiDB
首先我們聊聊 Database 的歷史,在已經有這麼多種資料庫的背景下我們為什麼要建立另外一個資料庫;以及說一下現在方案遇到的困境,說一下 Google Spanner 和 F1,TiKV 和 TiDB,說一下架構的事情,在這裡我們會重點聊一下 TiKV。因為我們產品的很多特性是 TiKV 提供的,比如說跨資料中心的複製,Transaction,auto-scale。
再聊一下為什麼 TiKV 用 Raft 能實現所有這些重要的特性,以及 scale,MVCC 和事務模型。東西非常多,我今天不太可能把裡面的技術細節都描述得特別細,因為幾乎每一個話題都可以找到一篇或者是多篇論文。但講完之後我還在這邊,所以詳細的技術問題大家可以單獨來找我聊。
後面再說一下我們現在遇到的窘境,就是大家常規遇到的分散式方案有哪些問題,比如 MySQL Sharding。我們建立了無數 MySQL Proxy,比如官方的 MySQL proxy,Youtube 的 Vitess,淘寶的 Cobar、TDDL,以及基於 Cobar 的 MyCAT,金山的 Kingshard,360 的 Atlas,京東的 JProxy,我在豌豆莢也寫了一個。可以說,隨便一個大公司都會造一個 MySQL Sharding 的方案。
### 為什麼我們要建立另外一個資料庫?
昨天晚上我還跟一個同學聊到,基於 MySQL 的方案它的天花板在哪裡,它的天花板特別明顯。有一個思路是能不能通過 MySQL 的 server 把 InnoDB 變成一個分散式資料庫,聽起來這個方案很完美,但是很快就會遇到天花板。因為 MySQL 生成的執行計劃是個單機的,它認為整個計劃的 cost 也是單機的,我讀取一行和讀取下一行之間的開銷是很小的,比如迭代 next row 可以立刻拿到下一行。實際上在一個分散式系統裡面,這是不一定的。
另外,你把資料都拿回來計算這個太慢了,很多時候我們需要把我們的 expression 或者計算過程等等運算推下去,向上返回一個最終的計算結果,這個一定要用分散式的 plan,前面控制執行計劃的節點,它必須要理解下面是分散式的東西,才能生成最好的 plan,這樣才能實現最高的執行效率。
比如說你做一個 sum,你是一條條拿回來加,還是讓一堆機器一起算,最後給我一個結果。 例如我有 100 億條資料分佈在 10 臺機器上,並行在這 10 臺 機器我可能只拿到 10 個結果,如果把所有的資料每一條都拿回來,這就太慢了,完全喪失了分散式的價值。聊到 MySQL 想實現分散式,另外一個實現分散式的方案是什麼,就是 Proxy。但是 Proxy 本身的天花板在那裡,就是它不支援分散式的 transaction,它不支援跨節點的 join,它無法理解複雜的 plan,一個複雜的 plan 打到 Proxy 上面,Proxy 就傻了,我到底應該往哪一個節點上轉發呢,如果我涉及到 subquery sql 怎麼辦?所以這個天花板是瞬間會到,在傳統模型下面的修改,很快會達不到我們的要求。
另外一個很重要的是,MySQL 支援的複製方式是半同步或者是非同步,但是半同步可以降級成非同步,也就是說任何時候資料出了問題你不敢切換,因為有可能是非同步複製,有一部分資料還沒有同步過來,這時候切換資料就不一致了。前一陣子出現過某公司突然不能支付了這種事件,今年有很多這種類似的 case,所以微博上大家都在說 “說好的異地多活呢?”……
為什麼傳統的方案在這上面解決起來特別的困難,天花板馬上到了,基本上不可能解決這個問題。另外是多資料中心的複製和資料中心的容災,MySQL 在這上面是做不好的。
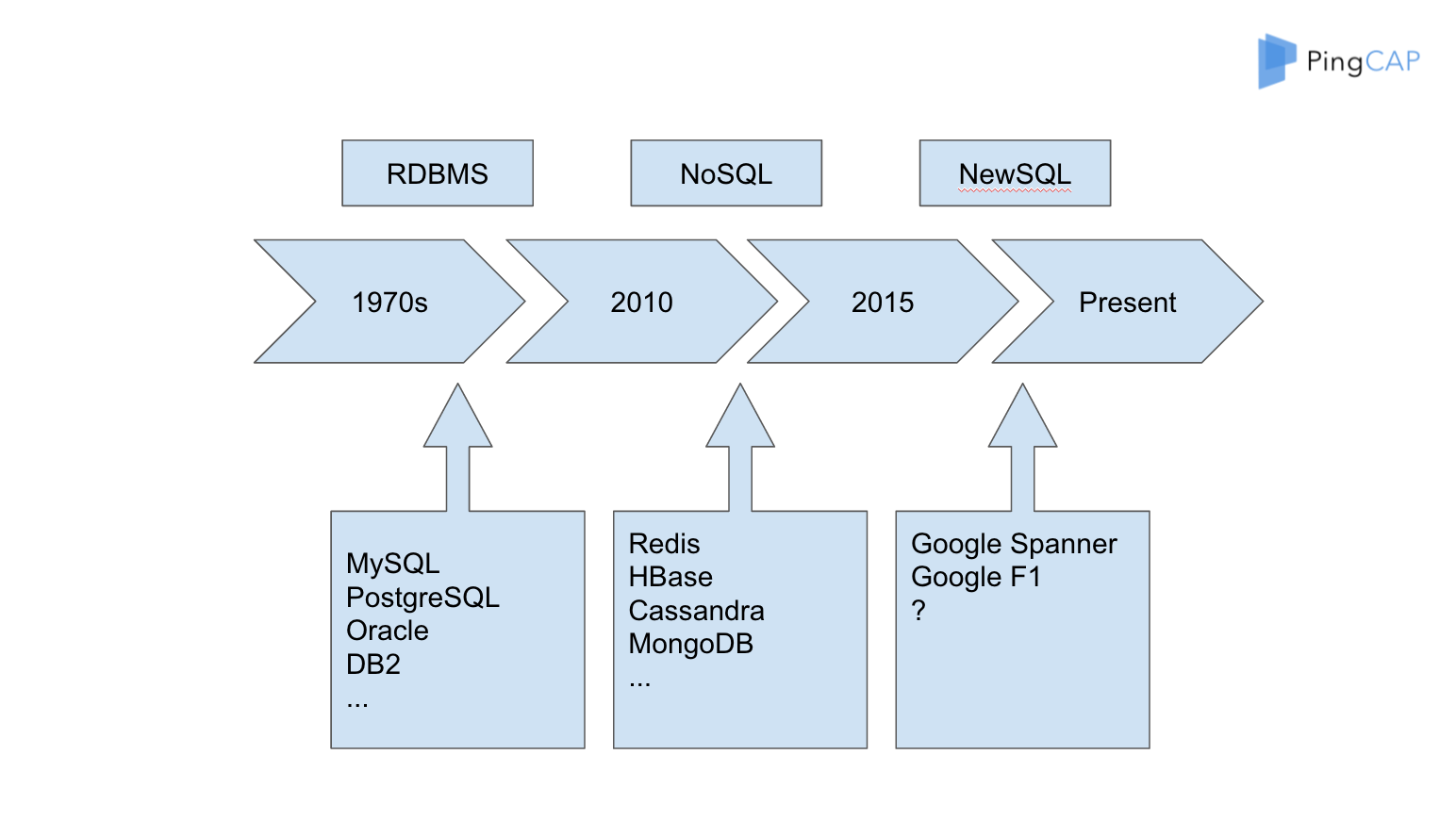 在前面三十年基本上是關聯式資料庫的時代,那個時代建立了很多偉大的公司,比如說 IBM、Oracle、微軟也有自己的資料庫,早期還有一個公司叫 Sybase,有一部分特別老的程式設計師同學在當年的教程裡面還可以找到這些東西,但是現在基本上看不到了。 另外是 NoSQL。NoSQL 也是一度非常火,像 Cassandra,MongoDB 等等,這些都屬於在網際網路快速發展的時候建立這些能夠 scale 的方案,但 Redis scale 出來比較晚,所以很多時候大家把 Redis 當成一個 Cache,現在慢慢大家把它當成儲存不那麼重要的資料的資料庫。因為它有了 scale 支援以後,大家會把更多的資料放在裡面。 然後到了 2015,嚴格來講是到 2014 年到 2015 年之間,Raft 論文發表以後,真正的 NewSQL 的理論基礎終於完成了。我覺得 NewSQL 這個理論基礎,最重要的劃時代的幾篇論文,一個是谷歌的 Spanner,是在 2013 年初發布的,再就是 Raft 是在 2014 年上半年釋出的。這幾篇相當於打下了分散式資料庫 NewSQL 的理論基礎,這個模型是非常重要的,如果沒有模型在上面是堆不起來東西的。說到現在,大家可能對於模型還是可以理解的,但是對於它的實現難度很難想象。
在前面三十年基本上是關聯式資料庫的時代,那個時代建立了很多偉大的公司,比如說 IBM、Oracle、微軟也有自己的資料庫,早期還有一個公司叫 Sybase,有一部分特別老的程式設計師同學在當年的教程裡面還可以找到這些東西,但是現在基本上看不到了。 另外是 NoSQL。NoSQL 也是一度非常火,像 Cassandra,MongoDB 等等,這些都屬於在網際網路快速發展的時候建立這些能夠 scale 的方案,但 Redis scale 出來比較晚,所以很多時候大家把 Redis 當成一個 Cache,現在慢慢大家把它當成儲存不那麼重要的資料的資料庫。因為它有了 scale 支援以後,大家會把更多的資料放在裡面。 然後到了 2015,嚴格來講是到 2014 年到 2015 年之間,Raft 論文發表以後,真正的 NewSQL 的理論基礎終於完成了。我覺得 NewSQL 這個理論基礎,最重要的劃時代的幾篇論文,一個是谷歌的 Spanner,是在 2013 年初發布的,再就是 Raft 是在 2014 年上半年釋出的。這幾篇相當於打下了分散式資料庫 NewSQL 的理論基礎,這個模型是非常重要的,如果沒有模型在上面是堆不起來東西的。說到現在,大家可能對於模型還是可以理解的,但是對於它的實現難度很難想象。
前面我大概提到了我們為什麼需要另外一個資料庫,說到 Scalability 資料的伸縮,然後我們講到需要 SQL,比如你給我一個純粹的 key-velue 系統的 API,比如我要查詢年齡在 10 歲到 20 歲之間的 email 要滿足一個什麼要求的。如果只有 KV 的 API 這是會寫死人的,要寫很多程式碼,但是實際上用 SQL 寫一句話就可以了,而且 SQL 的優化器對整個資料的分佈是知道的,它可以很快理解你這個 SQL,然後會得到一個最優的 plan,他得到這個最優的 plan 基本上等價於一個真正理解 KV 每一步操作的人寫出來的程式。通常情況下,SQL 的優化器是為了更加了解或者做出更好的選擇。
另外一個就是 ACID 的事務,這是傳統資料庫必須要提供的基礎。以前你不提供 ACID 就不能叫資料庫,但是近些年大家寫一個記憶體的 map 也可以叫自己是資料庫。大家寫一個 append-only 檔案,我們也可以叫只讀資料庫,資料庫的概念比以前極大的泛化了。
另外就是高可用和自動恢復,他們的概念是什麼呢?有些人會有一些誤解,因為今天還有朋友在現場問到,出了故障,比如說一個機房掛掉以後我應該怎麼做切換,怎麼操作。這個實際上相當於還是上一代的概念,還需要人去幹預,這種不算是高可用。
未來的高可用一定是系統出了問題馬上可以自動恢復,馬上可以變成可用。比如說一個機房掛掉了,十秒鐘不能支付,十秒鐘之後系統自動恢復了變得可以支付,即使這個資料中心再也不起來我整個系統仍然是可以支付的。Auto-Failover 的重要性就在這裡。大家不希望在睡覺的時候被一個報警給拉起來,我相信大家以後具備這樣一個能力,5 分鐘以內的報警不用理會,掛掉一個機房,又掛掉一個機房,這種連續報警才會理。我們內部開玩笑說,希望大家都能睡個好覺,很重要的事情就是這個。
說完應用層的事情,現在很有很多業務,在應用層自己去分片,比如說我按照 user ID 在程式碼裡面分片,還有一部分是更高階一點我會用到一致性雜湊。問題在於它的複雜度,到一定程度之後我自動的分庫,自動的分表,我覺得下一代資料庫是不需要理解這些東西的,不需要了解什麼叫做分庫,不需要了解什麼叫做分表,因為系統是全部自動搞定的。同時複雜度,如果一個應用不支援事務,那麼在應用層去做,通常的做法是引入一個外部佇列,引入大量的程式機制和狀態轉換,A 狀態的時候允許轉換到 B 狀態,B 狀態允許轉換到 C 狀態。
舉一個簡單的例子,比如說在京東上買東西,先下訂單,支付狀態之後這個商品才能出庫,如果不是支付狀態一定不能出庫,每一步都有嚴格的流程。 ###Google Spanner / F1 說一下 Google 的 Spanner 和 F1,這是我非常喜歡的論文,也是我最近幾年看過很多遍的論文。Google Spanner 已經強大到什麼程度呢?Google Spanner 是全球分佈的資料庫,在國內目前普遍做法叫做同城兩地三中心,它們的差別是什麼呢?以 Google 的資料來講,谷歌比較高的級別是他們有 7 個副本,通常是美國儲存 3 個副本,再在另外 2 個國家可以儲存 2 個副本,這樣的好處是萬一美國兩個資料中心出了問題,那整個系統還能繼續可用,這個概念就是比如美國 3 個副本全掛了,整個資料都還在,這個資料安全級別比很多國家的安全級別還要高,這是 Google 目前做到的,這是全球分佈的好處。
現在國內主流的做法是兩地三中心,但現在基本上都不能自動切換。大家可以看到很多號稱實現了兩地三中心或者異地多活,但是一出現問題都說不好意思這段時間我不能提供服務了。大家無數次的見到這種 case,我就不列舉了。
Spanner 現在也提供一部分 SQL 特性。在以前,大部分 SQL 特性是在 F1 裡面提供的,現在 Spanner 也在逐步豐富它的功能,Google 是全球第一個做到這個規模或者是做到這個級別的資料庫。事務支援裡面 Google 有點黑科技(其實也沒有那麼黑),就是它有 GPS 時鐘和原子鐘。大家知道在分散式系統裡面,比如說數千臺機器,兩個事務啟動先後順序,這個順序怎麼界定 (事務外部一致性)。這個時候 Google 內部使用了 GPS 時鐘和原子鐘,正常情況下它會使用一個 GPS 時鐘的一個叢集,就是說我拿的一個時間戳,並不是從一個 GPS 上來拿的時間戳,因為大家知道所有的硬體都會有誤差。如果這時候我從一個上拿到的 GPS 本身有點問題,那麼你拿到的這個時鐘是不精確的。而 Google 它實際上是在一批 GPS 時鐘上去拿了能夠滿足 majority 的精度,再用時間的演算法,得到一個比較精確的時間。同時大家知道 GPS 也不太安全,因為它是美國軍方的,對於 Google 來講要實現比國家安全級別更高的資料庫,而 GPS 是可能受到干擾的,因為 GPS 訊號是可以調整的,這在軍事用途上面很典型的,大家知道導彈的制導需要依賴 GPS,如果調整了 GPS 精度,那麼導彈精度就廢了。所以他們還用原子鐘去校正 GPS,如果 GPS 突然跳躍了,原子鐘上是可以檢測到 GPS 跳躍的,這部分相對有一點黑科技,但是從原理上來講還是比較簡單,比較好理解的。
最開始它 Spanner 最大的使用者就是 Google 的 Adwords,這是 Google 最賺錢的業務,Google 就是靠廣告生存的,我們一直覺得 Google 是科技公司,但是他的錢是從廣告那來的,所以一定程度來講 Google 是一個廣告公司。Google 內部的方向先有了 Big table ,然後有了 MegaStore ,MegaStore 的下一代是 Spanner ,F1 是在 Spanner 上面構建的。
###TiDB and TiKV
TiKV 和 TiDB 基本上對應 Google Spanner 和 Google F1,用 Open Source 方式重建。目前這兩個專案都開放在 GitHub 上面,兩個專案都比較火爆,TiDB 是更早一點開源的, 目前 TiDB 在 GitHub 上 有 4300 多個 Star,每天都在增長。 另外,對於現在的社會來講,我們覺得 Infrastructure 領域閉源的東西是沒有任何生存機會的。沒有任何一家公司,願意把自己的身家性命壓在一個閉源的專案上。舉一個很典型的例子,在美國有一個資料庫叫 FoundationDB,去年被蘋果收購了。 FoundationDB 之前和使用者籤的合約都是一年的合約。比如說,我給你服務週期是一年,現在我被另外一個公司收購了,我今年服務到期之後,我是滿足合約的。但是其他公司再也不能找它服務了,因為它現在不叫 FoundationDB 了,它叫 Apple 了,你不能找 Apple 給你提供一個 enterprise service。
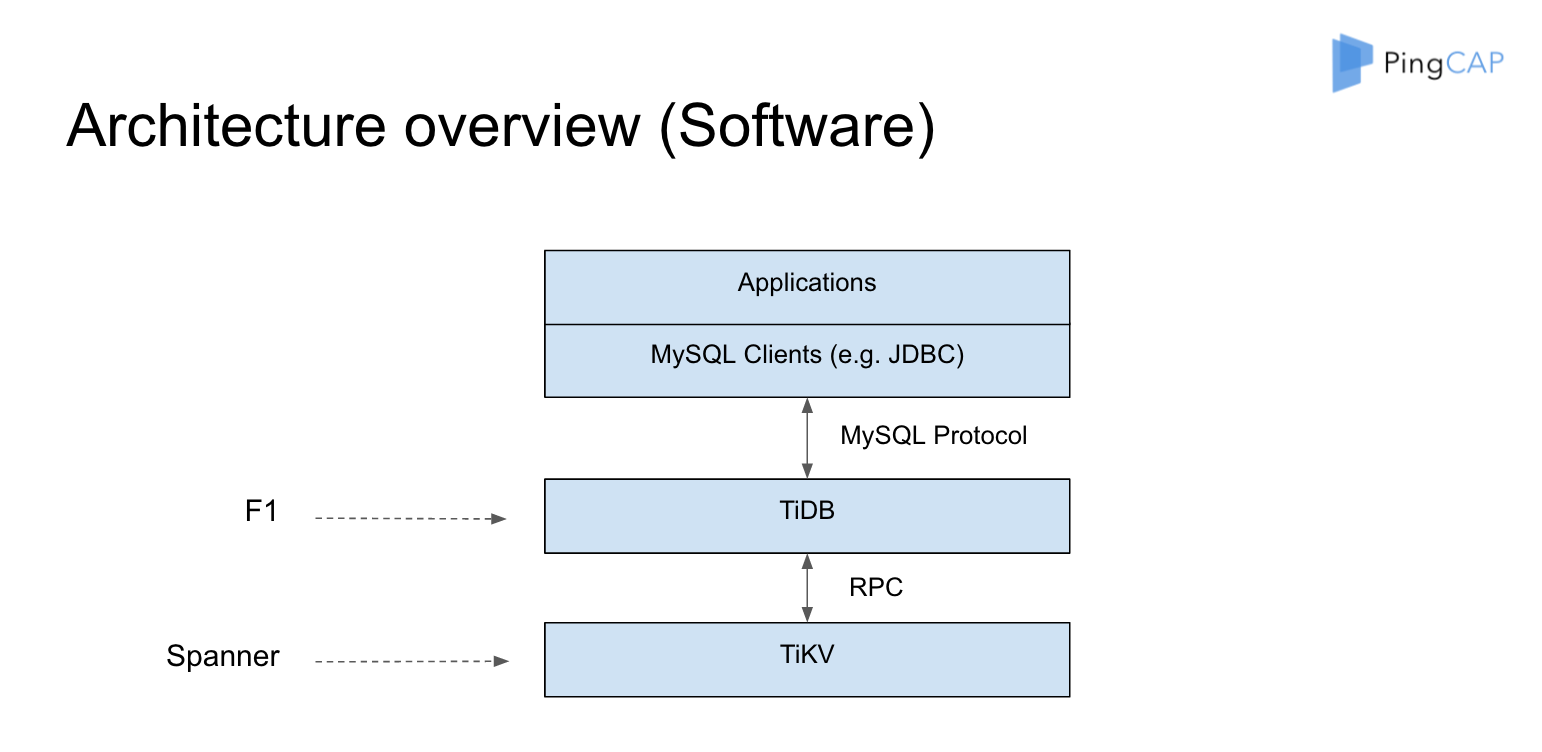 TiDB 和 TiKV 為什麼是兩個專案,因為它和 Google 的內部架構對比差不多是這樣的:TiKV 對應的是 Spanner,TiDB 對應的是 F1 。F1 裡面更強調上層的分散式的 SQL 層到底怎麼做,分散式的 Plan 應該怎麼做,分散式的 Plan 應該怎麼去做優化。同時 TiDB 有一點做的比較好的是,它相容了 MySQL 協議,當你出現了一個新型的資料庫的時候,使用者使用它是有成本的。大家都知道作為開發很討厭的一個事情就是,我要每個語言都寫一個 Driver,比如說你要支援 C++,你要支援 Java,你要支援 Go 等等,這個太累了,而且使用者還得改他的程式,所以我們選擇了一個更加好的東西相容 MySQL 協議,讓使用者可以不用改。一會我會用一個視訊來演示一下,為什麼一行程式碼不改就可以用,使用者就能體會到 TiDB 帶來的所有的好處。
TiDB 和 TiKV 為什麼是兩個專案,因為它和 Google 的內部架構對比差不多是這樣的:TiKV 對應的是 Spanner,TiDB 對應的是 F1 。F1 裡面更強調上層的分散式的 SQL 層到底怎麼做,分散式的 Plan 應該怎麼做,分散式的 Plan 應該怎麼去做優化。同時 TiDB 有一點做的比較好的是,它相容了 MySQL 協議,當你出現了一個新型的資料庫的時候,使用者使用它是有成本的。大家都知道作為開發很討厭的一個事情就是,我要每個語言都寫一個 Driver,比如說你要支援 C++,你要支援 Java,你要支援 Go 等等,這個太累了,而且使用者還得改他的程式,所以我們選擇了一個更加好的東西相容 MySQL 協議,讓使用者可以不用改。一會我會用一個視訊來演示一下,為什麼一行程式碼不改就可以用,使用者就能體會到 TiDB 帶來的所有的好處。
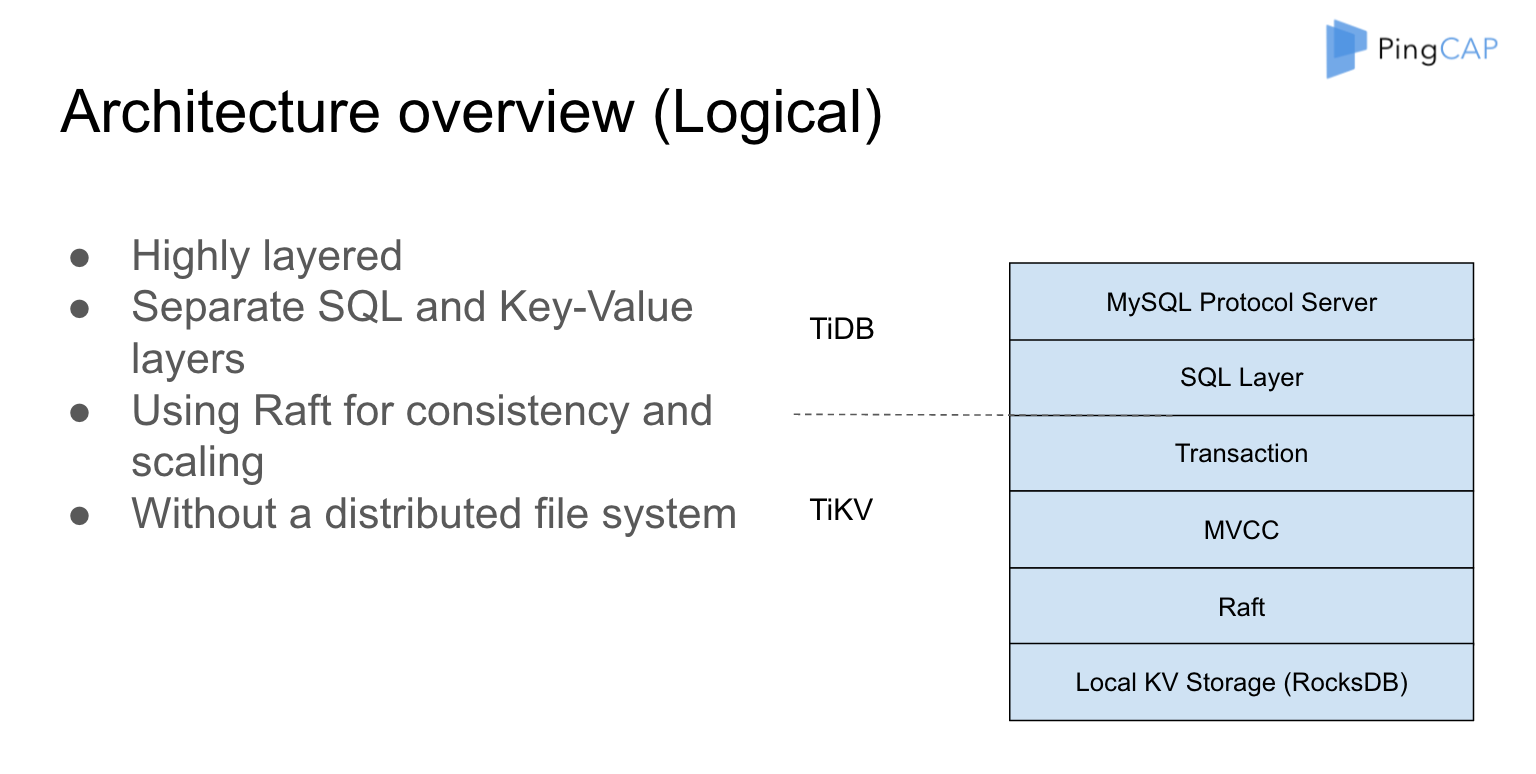 這個圖實際上是整個協議棧或者是整個軟體棧的實現。大家可以看到整個系統是高度分層的,從最底下開始是 RocksDB ,然後再上面用 Raft 構建一層可以被複制的 RocksDB,在這一層的時候它還沒有 Transaction,但是整個系統現在的狀態是所有寫入的資料一定要保證它複製到了足夠多的副本。也就是說只要我寫進來的資料一定有足夠多的副本去 cover 它,這樣才比較安全,在一個比較安全的 Key-value store 上面, 再去構建它的多版本,再去構建它的分散式事務,然後在分散式事務構建完成之後,就可以輕鬆的加上 SQL 層,再輕鬆的加上 MySQL 協議的支援。然後,這兩天我比較好奇,自己寫了 MongoDB 協議的支援,然後我們可以用 MongoDB 的客戶端來玩,就是說協議這一層是高度可插拔的。TiDB 上可以在上面構建一個 MongoDB 的協議,相當於這個是構建一個 SQL 的協議,可以構建一個 NoSQL 的協議。這一點主要是用來驗證 TiKV 在模型上面的支援能力。
這個圖實際上是整個協議棧或者是整個軟體棧的實現。大家可以看到整個系統是高度分層的,從最底下開始是 RocksDB ,然後再上面用 Raft 構建一層可以被複制的 RocksDB,在這一層的時候它還沒有 Transaction,但是整個系統現在的狀態是所有寫入的資料一定要保證它複製到了足夠多的副本。也就是說只要我寫進來的資料一定有足夠多的副本去 cover 它,這樣才比較安全,在一個比較安全的 Key-value store 上面, 再去構建它的多版本,再去構建它的分散式事務,然後在分散式事務構建完成之後,就可以輕鬆的加上 SQL 層,再輕鬆的加上 MySQL 協議的支援。然後,這兩天我比較好奇,自己寫了 MongoDB 協議的支援,然後我們可以用 MongoDB 的客戶端來玩,就是說協議這一層是高度可插拔的。TiDB 上可以在上面構建一個 MongoDB 的協議,相當於這個是構建一個 SQL 的協議,可以構建一個 NoSQL 的協議。這一點主要是用來驗證 TiKV 在模型上面的支援能力。
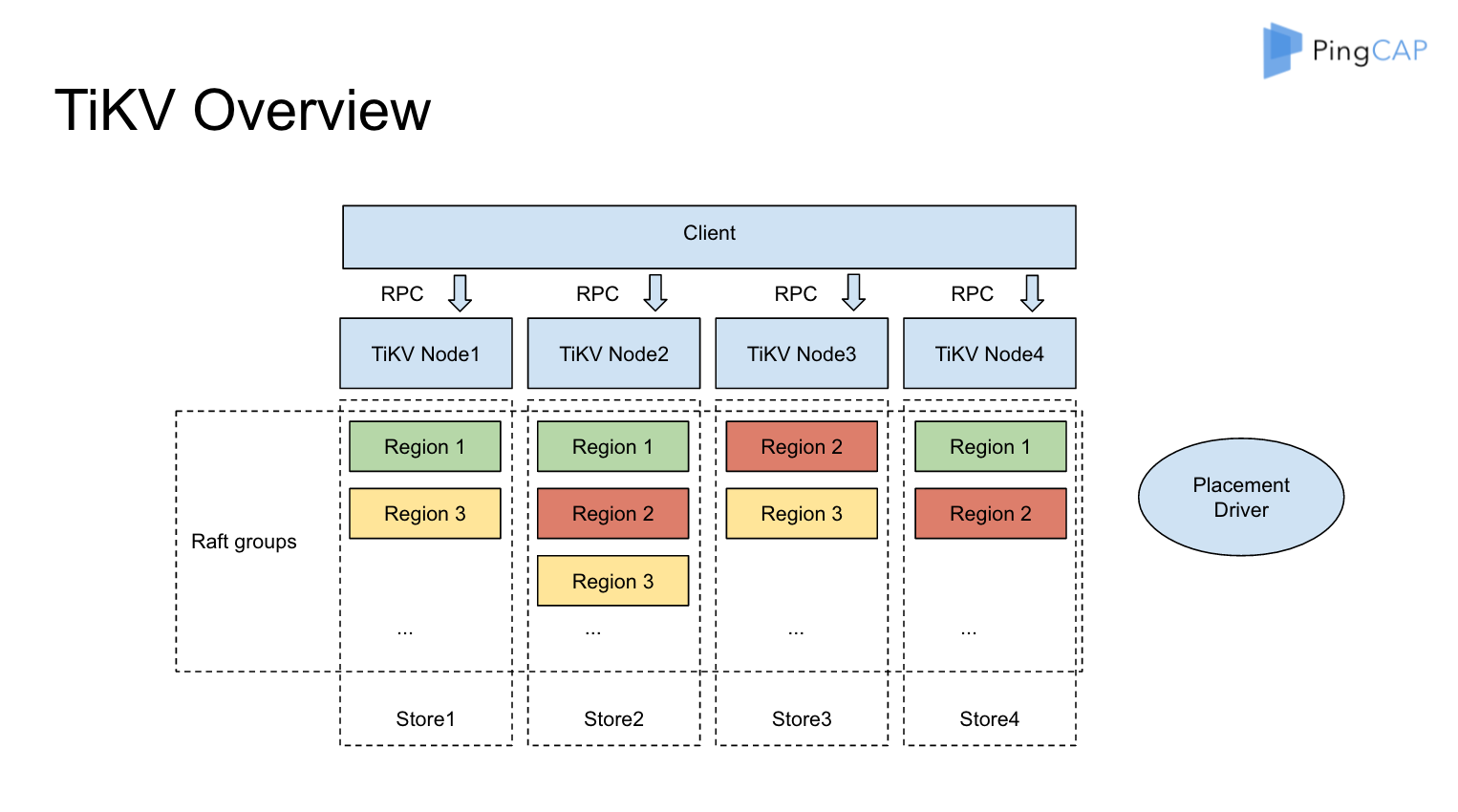 這是整個 TiKV 的架構圖,從這個看來,整個叢集裡面有很多 Node,比如這裡畫了四個 Node,分別對應了四個機器。每一個 Node 上可以有多個 Store,每個 Store 裡面又會有很多小的 Region,就是說一小片資料,就是一個 Region 。從全域性來看所有的資料被劃分成很多小片,每個小片預設配置是 64M,它已經足夠小,可以很輕鬆的從一個節點移到另外一個節點,Region 1 有三個副本,它分別在 Node1、Node 2 和 Node4 上面, 類似的 Region 2,Region 3 也是有三個副本。每個 Region 的所有副本組成一個 Raft Group, 整個系統可以看到很多這樣的 Raft groups。
這是整個 TiKV 的架構圖,從這個看來,整個叢集裡面有很多 Node,比如這裡畫了四個 Node,分別對應了四個機器。每一個 Node 上可以有多個 Store,每個 Store 裡面又會有很多小的 Region,就是說一小片資料,就是一個 Region 。從全域性來看所有的資料被劃分成很多小片,每個小片預設配置是 64M,它已經足夠小,可以很輕鬆的從一個節點移到另外一個節點,Region 1 有三個副本,它分別在 Node1、Node 2 和 Node4 上面, 類似的 Region 2,Region 3 也是有三個副本。每個 Region 的所有副本組成一個 Raft Group, 整個系統可以看到很多這樣的 Raft groups。
Raft 細節我不展開了,大家有興趣可以找我私聊或者看一下相應的資料。
因為整個系統裡面我們可以看到上一張圖裡面有很多 Raft group 給我們,不同 Raft group 之間的通訊都是有開銷的。所以我們有一個類似於 MySQL 的 group commit 機制 ,你發訊息的時候實際上可以 share 同一個 connection , 然後 pipeline + batch 傳送, 很大程度上可以省掉大量 syscall 的開銷。
另外,其實在一定程度上後面我們在支援壓縮的時候,也有非常大的幫助,就是可以減少資料的傳輸。對於整個系統而言,可能有數百萬的 Region,它的大小可以調整,比如說 64M、128M、256M,這個實際上依賴於整個系統裡面當前的狀況。
比如說我們曾經在有一個使用者的機房裡面做過測試,這個測試有一個香港機房和新加坡的機房。結果我們在做複製的時候,新加坡的機房大於 256M 就複製不過去,因為機房很不穩定,必須要保證資料切的足夠小,這樣才能複製過去。
如果一個 Region 太大以後我們會自動做 SPLIT,這是非常好玩的過程,有點像細胞的分裂。
然後 TiKV 的 Raft 實現,是從 etcd 裡面 port 過來的,為什麼要從 etcd 裡面 port 過來呢?首先 TiKV 的 Raft 實現是用 Rust 寫的。作為第一個做到生產級別的 Raft 實現,所以我們從 etcd 裡面把它用 Go 語言寫的 port 到這邊。
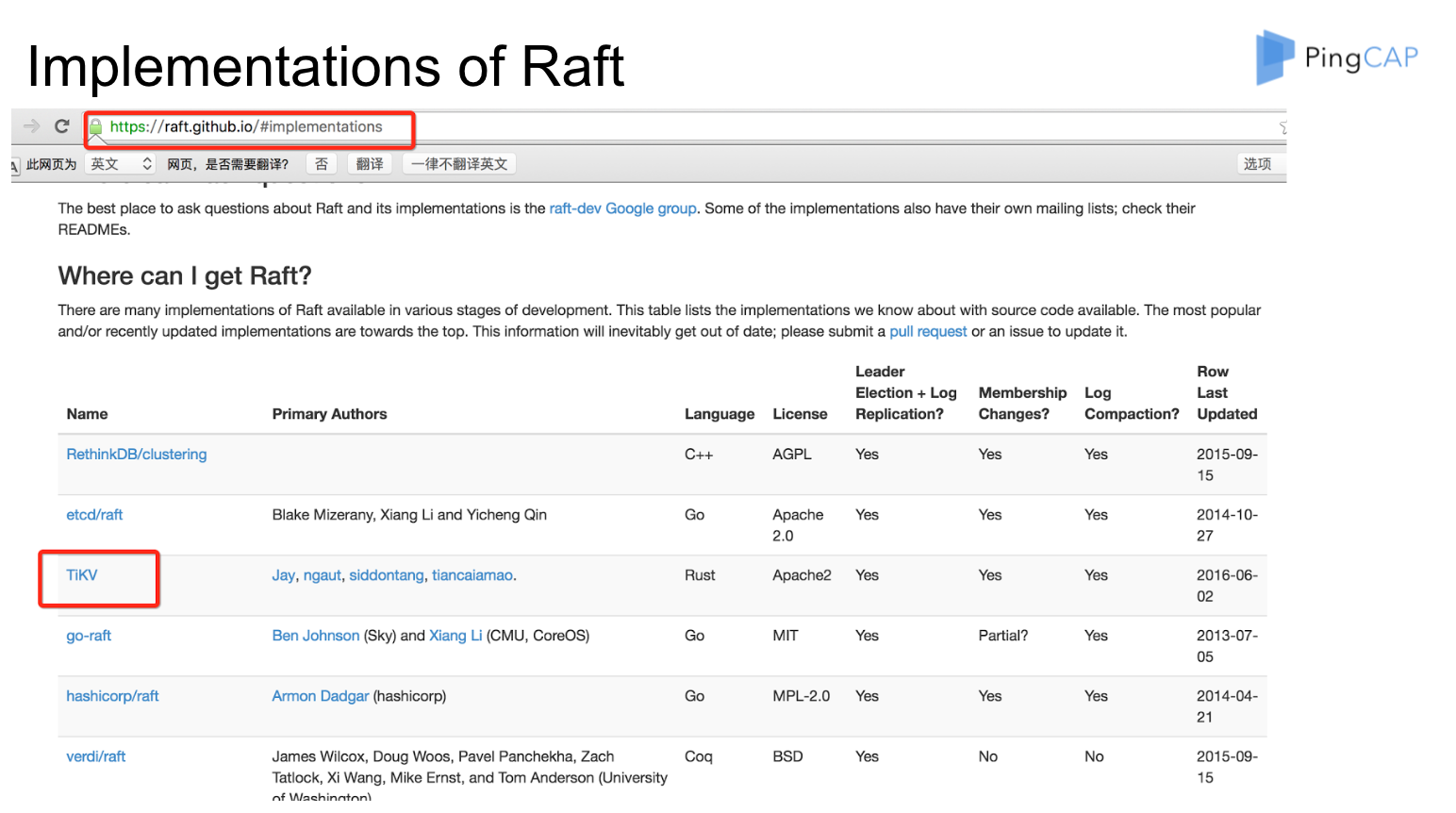 這個是 Raft 官網上面列出來的 TiKV 在裡面的狀態,大家可以看到 TiKV 把所有 Raft 的 feature 都實現了。 比如說 Leader Election、Membership Changes,這個是非常重要的,整個系統的 scale 過程高度依賴 Membership Changes,後面我用一個圖來講這個過程。後面這個是 Log Compaction,這個使用者不太關心。
這個是 Raft 官網上面列出來的 TiKV 在裡面的狀態,大家可以看到 TiKV 把所有 Raft 的 feature 都實現了。 比如說 Leader Election、Membership Changes,這個是非常重要的,整個系統的 scale 過程高度依賴 Membership Changes,後面我用一個圖來講這個過程。後面這個是 Log Compaction,這個使用者不太關心。
 這是很典型的細胞分裂的圖,實際上 Region 的分裂過程和這個是類似的。
這是很典型的細胞分裂的圖,實際上 Region 的分裂過程和這個是類似的。
我們看一下擴容是怎麼做的。
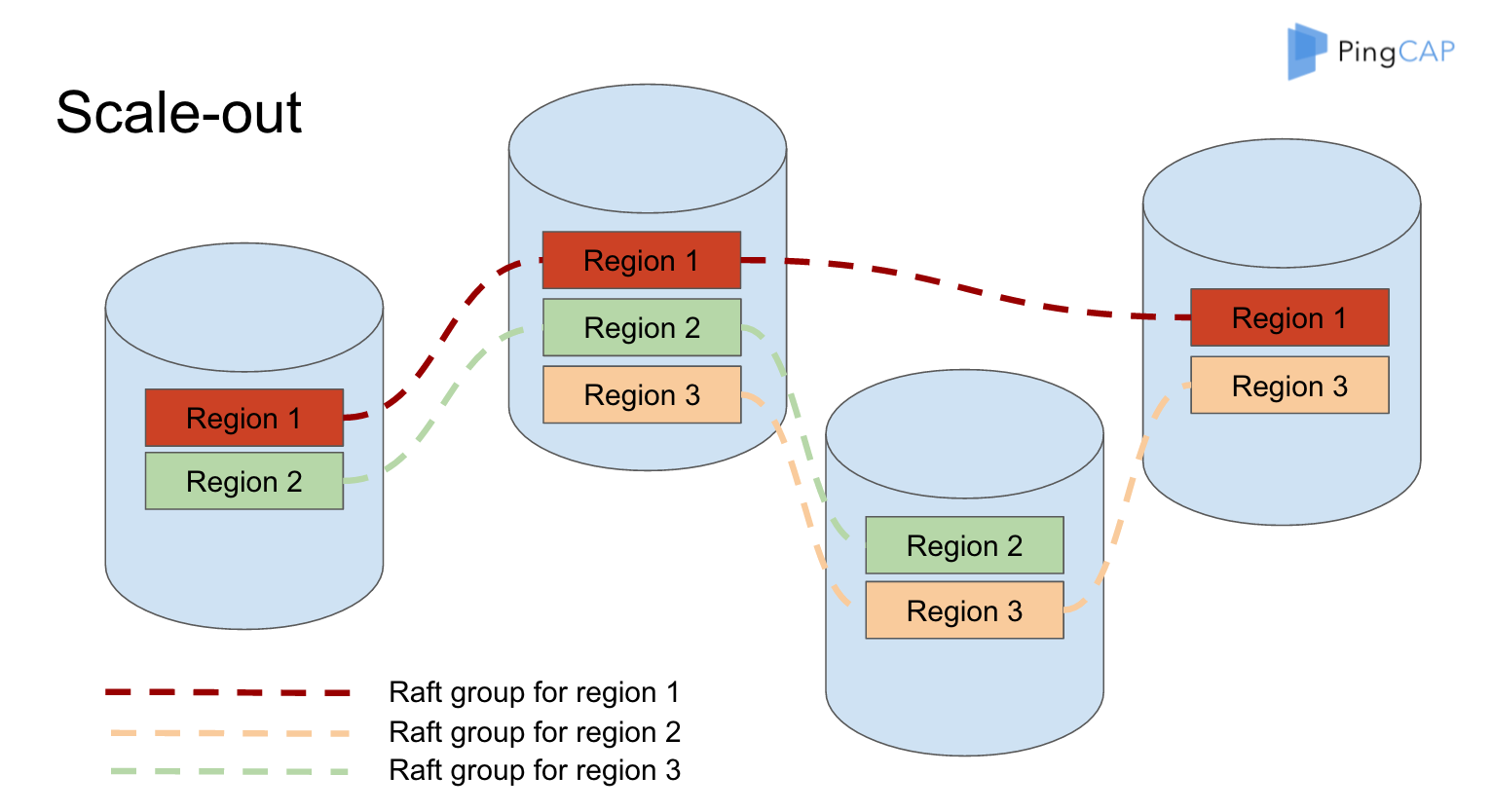 比如說以現在的系統假設,我們剛開始說只有三個節點,有 Region1 分別是在 1 、2、4,我用虛線連線起來代表它是 一個 Raft group ,大家可以看到整個系統裡面有三個 Raft group,在每一個 Node 上面資料的分佈是比較均勻的,在這個假設每一個 Region 是 64M ,相當於只有一個 Node 上面負載比其他的稍微大一點點。
比如說以現在的系統假設,我們剛開始說只有三個節點,有 Region1 分別是在 1 、2、4,我用虛線連線起來代表它是 一個 Raft group ,大家可以看到整個系統裡面有三個 Raft group,在每一個 Node 上面資料的分佈是比較均勻的,在這個假設每一個 Region 是 64M ,相當於只有一個 Node 上面負載比其他的稍微大一點點。
這是一個線上的視訊。預設的時候,我們都是推薦 3 個副本或者 5 個副本的配置。Raft 本身有一個特點,如果一個 leader down 掉之後,其它的節點會選一個新的 leader,那麼這個新的 leader 會把它還沒有 commit 但已經 reply 過去的 log 做一個 commit ,然後會再做 apply,這個有點偏 Raft 協議,細節我不講了。
複製資料的小的 Region,它實際上是跨多個資料中心做的複製。這裡面最重要的一點是永遠不丟失資料,無論如何我保證我的複製一定是複製到 majority,任何時候我只要對外提供服務,允許外面寫入資料一定要複製到 majority。很重要的一點就是恢復的過程一定要是自動化的,我前面已經強調過,如果不能自動化恢復,那麼中間的當機時間或者對外不可服務的時間,便不是由整個系統決定的,這是相對回到了幾十年前的狀態。
###MVCC
MVCC 我稍微仔細講一下這一塊。MVCC 的好處,它很好支援 Lock-free 的 snapshot read ,一會兒我有一個圖會展示 MVCC 是怎麼做的。isolation level 就不講了,MySQL 裡面的級別是可以調的,我們的 TiKV 有 SI,還有 SI+lock,預設是支援 SI 的這種隔離級別,然後你寫一個 select for update 語句,這個會自動的調整到 SI 加上 lock 這個隔離級別。這個隔離級別基本上和 SSI 是一致的。還有一個就是 GC 的問題,如果你的系統裡面的資料產生了很多版本,你需要把這個比較老的資料給 GC 掉,比如說正常情況下我們是不刪除資料的, 你寫入一行,然後再寫入一行,不斷去 update 同一行的時候,每一次 update 會產生新的版本,新的版本就會在系統裡存在,所以我們需要一個 GC 的模組把比較老的資料給 GC 掉,實際上這個 GC 不是 Go 裡面的 GC,不是 Java 的 GC,而是資料的 GC。
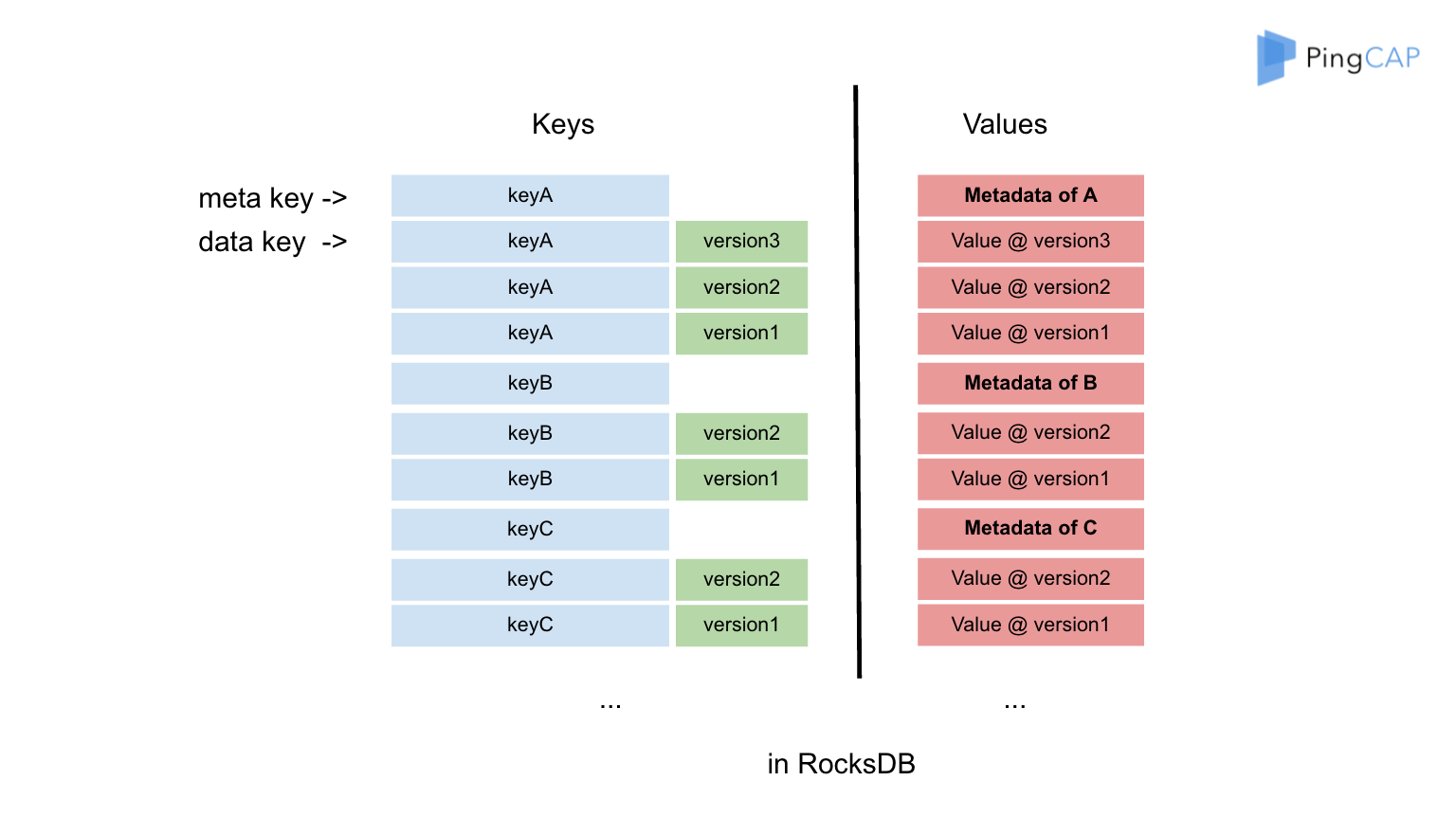 這是一個資料版本,大家可以看到我們的資料分成兩塊,一個是 meta,一個是 data。meta 相對於描述我的資料當前有多少個版本。大家可以看到綠色的部分,比如說我們的 meta key 是 A,keyA 有三個版本,是 A1、A2、A3,我們把 key 自己和 version 拼到一起。那我們用 A1、A2、A3 分別描述 A 的三個版本,那麼就是 version 1/2/3。meta 裡面描述,就是我的整個 key 相對應哪個版本,我想找到那個版本。比如說我現在要讀取 key A 的版本 10,但顯然現在版本 10 是沒有的,那麼小於版本 10 最大的版本是 3,所以這時我就能讀取到 3,這是它的隔離級別決定的。關於 data,我剛才已經講過了。
### 分散式事務模型
接下來是分散式事務模型,其實是基於 Google Percolator,這是 Google 在 2006 發表的一篇論文,是 Google 在做內部增量處理的時候發現了這個方法,本質上還是二階段提交的。這使用的是一個樂觀鎖,比如說我提供一個 transaction ,我去改一個東西,改的時候是釋出在本地的,並沒有馬上 commit 到資料儲存那一端,這個模型就是說,我修改的東西我馬上去 Lock 住,這個基本就是一個悲觀鎖。但如果到最後一刻我才提交出去,那麼鎖住的這一小段的時間,這個時候實現的是樂觀鎖。樂觀鎖的好處就是當你衝突很小的時候可以得到非常好的效能,因為衝突特別小,所以我本地修改通常都是有效的,所以我不需要去 Lock ,不需要去 roll back 。本質上分散式事務就是 2PC 或者是 2+xPC,基本上沒有 1PC,除非你在別人的級別上做弱化。比如說我允許你讀到當前最新的版本,也允許你讀到前面的版本,書裡面把這個叫做幻讀。如果你調到這個程度是比較容易做 1PC 的,這個實際上還是依賴使用者設定的隔離級別的,如果使用者需要更高的隔離級別,這個 1PC 就不太好做了。 這是一個路由,正常來講,大家可能會好奇一個 SQL 語句怎麼最後會落到儲存層,然後能很好的執行,最後怎麼能對映到 KV 上面,又怎麼能路由到正確的節點,因為整個系統可能有上千個節點,你怎麼能正確路由到那一個的節點。我們在 TiDB 有一個 TiKV driver , 另外 TiKV 對外使用的是 Google Protocol Buffer 來作為通訊的編碼格式。
###Placement Driver
來說一下 Placement Driver 。Placement Driver 是什麼呢?整個系統裡面有一個節點,它會時刻知道現在整個系統的狀態。比如說每個機器的負載,每個機器的容量,是否有新加的機器,新加機器的容量到底是怎麼樣的,是不是可以把一部分資料挪過去,是不是也是一樣下線, 如果一個節點在十分鐘之內無法被其他節點探測到,我認為它已經掛了,不管它實際上是不是真的掛了,但是我也認為它掛了。因為這個時候是有風險的,如果這個機器萬一真的掛了,意味著你現在機器的副本數只有兩個,有一部分資料的副本數只有兩個。那麼現在你必須馬上要在系統裡面重新選一臺機器出來,它上面有足夠的空間,讓我現在只有兩個副本的資料重新再做一份新的複製,系統始終維持在三個副本。整個系統裡面如果機器掛掉了,副本數少了,這個時候應該會被自動發現,馬上補充新的副本,這樣會維持整個系統的副本數。這是很重要的 ,為了避免資料丟失,必須維持足夠的副本數,因為副本數每少一個,你的風險就會再增加。這就是 Placement Driver 做的事情。 同時,Placement Driver 還會根據效能負載,不斷去 move 這個 data 。比如說你這邊負載已經很高了,一個磁碟假設有 100G,現在已經用了 80G,另外一個機器上也是 100G,但是他只用了 20G,所以這上面還可以有幾十 G 的資料,比如 40G 的資料,你可以 move 過去,這樣可以保證系統有很好的負載,不會出現一個磁碟巨忙無比,資料已經多的裝不下了,另外一個上面還沒有東西,這是 Placement Driver 要做的東西。
這是一個資料版本,大家可以看到我們的資料分成兩塊,一個是 meta,一個是 data。meta 相對於描述我的資料當前有多少個版本。大家可以看到綠色的部分,比如說我們的 meta key 是 A,keyA 有三個版本,是 A1、A2、A3,我們把 key 自己和 version 拼到一起。那我們用 A1、A2、A3 分別描述 A 的三個版本,那麼就是 version 1/2/3。meta 裡面描述,就是我的整個 key 相對應哪個版本,我想找到那個版本。比如說我現在要讀取 key A 的版本 10,但顯然現在版本 10 是沒有的,那麼小於版本 10 最大的版本是 3,所以這時我就能讀取到 3,這是它的隔離級別決定的。關於 data,我剛才已經講過了。
### 分散式事務模型
接下來是分散式事務模型,其實是基於 Google Percolator,這是 Google 在 2006 發表的一篇論文,是 Google 在做內部增量處理的時候發現了這個方法,本質上還是二階段提交的。這使用的是一個樂觀鎖,比如說我提供一個 transaction ,我去改一個東西,改的時候是釋出在本地的,並沒有馬上 commit 到資料儲存那一端,這個模型就是說,我修改的東西我馬上去 Lock 住,這個基本就是一個悲觀鎖。但如果到最後一刻我才提交出去,那麼鎖住的這一小段的時間,這個時候實現的是樂觀鎖。樂觀鎖的好處就是當你衝突很小的時候可以得到非常好的效能,因為衝突特別小,所以我本地修改通常都是有效的,所以我不需要去 Lock ,不需要去 roll back 。本質上分散式事務就是 2PC 或者是 2+xPC,基本上沒有 1PC,除非你在別人的級別上做弱化。比如說我允許你讀到當前最新的版本,也允許你讀到前面的版本,書裡面把這個叫做幻讀。如果你調到這個程度是比較容易做 1PC 的,這個實際上還是依賴使用者設定的隔離級別的,如果使用者需要更高的隔離級別,這個 1PC 就不太好做了。 這是一個路由,正常來講,大家可能會好奇一個 SQL 語句怎麼最後會落到儲存層,然後能很好的執行,最後怎麼能對映到 KV 上面,又怎麼能路由到正確的節點,因為整個系統可能有上千個節點,你怎麼能正確路由到那一個的節點。我們在 TiDB 有一個 TiKV driver , 另外 TiKV 對外使用的是 Google Protocol Buffer 來作為通訊的編碼格式。
###Placement Driver
來說一下 Placement Driver 。Placement Driver 是什麼呢?整個系統裡面有一個節點,它會時刻知道現在整個系統的狀態。比如說每個機器的負載,每個機器的容量,是否有新加的機器,新加機器的容量到底是怎麼樣的,是不是可以把一部分資料挪過去,是不是也是一樣下線, 如果一個節點在十分鐘之內無法被其他節點探測到,我認為它已經掛了,不管它實際上是不是真的掛了,但是我也認為它掛了。因為這個時候是有風險的,如果這個機器萬一真的掛了,意味著你現在機器的副本數只有兩個,有一部分資料的副本數只有兩個。那麼現在你必須馬上要在系統裡面重新選一臺機器出來,它上面有足夠的空間,讓我現在只有兩個副本的資料重新再做一份新的複製,系統始終維持在三個副本。整個系統裡面如果機器掛掉了,副本數少了,這個時候應該會被自動發現,馬上補充新的副本,這樣會維持整個系統的副本數。這是很重要的 ,為了避免資料丟失,必須維持足夠的副本數,因為副本數每少一個,你的風險就會再增加。這就是 Placement Driver 做的事情。 同時,Placement Driver 還會根據效能負載,不斷去 move 這個 data 。比如說你這邊負載已經很高了,一個磁碟假設有 100G,現在已經用了 80G,另外一個機器上也是 100G,但是他只用了 20G,所以這上面還可以有幾十 G 的資料,比如 40G 的資料,你可以 move 過去,這樣可以保證系統有很好的負載,不會出現一個磁碟巨忙無比,資料已經多的裝不下了,另外一個上面還沒有東西,這是 Placement Driver 要做的東西。
Raft 協議還提供一個很高階的特性叫 leader transfer。leader transfer 就是說在我不移動資料的時候,我把我的 leadership 給你,相當於從這個角度來講,我把流量分給你,因為我是 leader,所以資料會到我這來,但我現在把 leader 給你,我讓你來當 leader,原來打給我的請求會被打給你,這樣我的負載就降下來。這就可以很好的動態調整整個系統的負載,同時又不搬移資料。不搬移資料的好處就是,不會形成一個抖動。 ###MySQL Sharding MySQL Sharding 我前面已經提到了它的各種天花板,MySQL Sharding 的方案很典型的就是解決基本問題以後,業務稍微複雜一點,你在 sharding 這一層根本搞不定。它永遠需要一個 sharding key,你必須要告訴我的 proxy,我的資料要到哪裡找,對使用者來說是極不友好的,比如我現在是一個單機的,現在我要切入到一個分散式的環境,這時我必須要改我的程式碼,我必須要知道我這個 key ,我的 row 應該往哪裡 Sharding。如果是用 ORM ,這個基本上就沒法做這個事情了。有很多 ORM 它本身假設我後面只有一個 MySQL。但 TiDB 就可以很好的支援,因為我所有的角色都是對的,我不需要關注 Sharding、分庫、分表這類的事情。
這裡面有一個很重要的問題沒有提,我怎麼做 DDL。如果這個表非常大的話,比如說我們有一百億吧,橫跨了四臺機器,這個時候你要給它做一個新的 Index,就是我要新增一個新的索引,這個時候你必須要不影響任何現有的業務,實際上這是多階段提交的演算法,這個是 Google 和 F1 一起發出來那篇論文。
簡單來講是這樣的,先把狀態標記成 delete only ,delete only 是什麼意思呢?因為在分散式系統裡面,所有的系統對於 schema 的視野不是一致的,比如說我現在改了一個值,有一部分人發現這個值被改了,但是還有一部分人還沒有開始訪問這個,所以根本不知道它被改了。然後在一個分佈系統裡,你也不可能實時通知到所有人在同一時刻發現它改變了。比如說從有索引到沒有索引,你不能一步切過去,因為有的人認為它有索引,所以他給它建了一個索引,但是另外一個機器他認為它沒有索引,所以他就把資料給刪了,索引就留在裡面了。這樣遇到一個問題,我通過索引找的時候告訴我有, 實際資料卻沒有了,這個時候一致性出了問題。比如說我 count 一個 email 等於多少的,我通過 email 建了一個索引,我認為它是在,但是 UID 再轉過去的時候可能已經不存在了。
比如說我先標記成 delete only,我刪除它的時候不管它現在有沒有索引,我都會嘗試刪除索引,所以我的資料是乾淨的。如果我刪除掉的話,我不管結果是什麼樣的,我嘗試去刪一下,可能這個索引還沒 build 出來,但是我仍然刪除,如果資料沒有了,索引一定沒有了,所以這可以很好的保持它的一致性。後面再類似於前面,先標記成 write only 這種方式, 連續再迭代這個狀態,就可以迭代到一個最終可以對外公開的狀態。比如說當我迭代到一定程度的時候,我可以從後臺 build index ,比如說我一百億,正在操作的 index 會馬上 build,但是還有很多沒有 build index ,這個時候後臺不斷的跑 map-reduce 去 build index ,直到整個都 build 完成之後,再對外 public ,就是說我這個索引已經可用了,你可以直接拿索引來找,這個是非常經典的。在這個 Online, Asynchronous Schema Change in F1 paper 之前,大家都不知道這事該怎麼做。
Proxy Sharding 的方案不支援分散式事務,更不用說跨資料中心的一致性事務了。 TiKV 很好的支援 transaction,剛才提到的 Raft 除了增加副本之外,還有 leader transfer,這是一個傳統的方案都無法提供的特性。以及它帶來的好處,當我瞬間平衡整個系統負載的時候,對外是透明的, 做 leader transfer 的時候並不需要移動資料, 只是個簡單的 leader transfer 訊息。
然後說一下如果大家想參與我們專案的話是怎樣的過程,因為整個系統是完全開源的,如果大家想參與其中任何一部分都可以,比如說我想參與到分散式 KV,可以直接貢獻到 TiKV。TiKV 需要寫 Rust,如果大家對這塊特別有激情可以體驗寫 Rust 的感覺 。
TiDB 是用 Go 寫的,Go 在中國的群眾基礎是非常多的,目前也有很多人在貢獻。整個 TiDB 和 TiKV 是高度協作的專案,因為 TiDB 目前還用到了 etcd,我們在和 CoreOS 在密切的合作,也特別感謝 CoreOS 幫我們做了很多的支援,我們也為 CoreOS 的 etcd 提了一些 patch。同時,TiKV 使用 RocksDB ,所以我們也為 RocksDB 提了一些 patch 和 test,我們也非常感謝 Facebook RocksDB team 對我們專案的支援。
另外一個是 PD,就是我們前面提的 Placement Driver,它負責監控整個系統。這部分的演算法比較好玩,大家如果有興趣的話,可以去自己控制整個叢集的排程,它和 k8s 或者是 Mesos 的排程演算法是不一樣的,因為它排程的維度實際上比那個要更多。比如說磁碟的容量,你的 leader 的數量,你的網路當前的使用情況,你的 IO 的負載和 CPU 的負載都可以放進去。同時你還可以讓它排程不要跨一個機房裡面建多個副本。
![[QingCloud Insight 2016] How do we build TiDB](https://gocn.vip/uploads/gopherchina.jpg)
- 加微信實戰群請加微信(註明:實戰群):gocnio
相關文章
- Scrum series | How we do product backlogs薦Scrum
- Do we need HACMP?ACM
- QingCloud Insight 2016:詮釋雲端計算未來圖景GCCloud
- 青雲QingCloud Insight 2016:揭示雲技術4大方向GCCloud
- How do you pronounce IT?
- How to Build a Cybersecurity CareerUI
- Useless SAP PA certificate, do we still need to get it?
- how to build a website like apkmirrorUIWebAPK
- How to build a jar file by mavenUIJARMaven
- How do you think the GHD hair straightenersAI
- How do you find that an operation mode switch occurred?
- How to Build ffmpeg with NDK r9UI
- 2016新年福利!CoreThink×青雲Qingcloud合作GCCloud
- How we redesign the NSQ-NSQ重塑之客戶端客戶端
- Checkout conflict with files. How do I proceed?
- How do I disable the iptables firewall in Fedora Core Linux?Linux
- How to Build Office Developer Tools Projects with TFS Team Build 2012UIDeveloperProject
- How to build your custom release bazel version?UI
- how-to-build-c-static-libraries-boostUI
- How we redesigned the NSQ- 其他特性及未來計劃
- How Can We Maintain Decanter Centrifuge for Mud Solids Control?AISolid
- How do I initialize Log4J in a web application?WebAPP
- How do I reverse selected lines order in Vim?
- [Encoding]How to do proper encoding output redirection on cmd.exe?Encoding
- How to build a Startup? 首先你缺個合夥人!UI
- Flutter Cupertino Tutorial: How to Build an iOS App That Looks and Feels NativeFlutterUIiOSAPP
- POJ 2831 Can We Build This One:次小生成樹【N^2預處理】UI
- Tutor8?How to crack LockDown 2000 3.0 Build 3.0.1.28UI
- Tutor 9 How to crack Second Copy 97 version 5.31 build 96UI
- Build 2016:細數給開發者的福利UI
- 【譯】如何用人類的方式進行Code Review(How to Do Code Reviews Like a Human)View
- Just Do IT
- Insight Windows AzureWindows
- 擁抱極限程式設計(Do do XP)程式設計
- How Do Vision Transformers Work?[2202.06709] - 論文研讀系列(2) 個人筆記ORM筆記
- Do more, fasterAST
- Source Insight:使用Source Insight檢視C/C++原始碼C++原始碼
- E. We Need More Bosses