[CDAS 2016] 分散式資料庫模式與反模式
>TiDB 是一個 OLTP 的資料庫,我們主要 focus 在大資料的關係型資料庫的儲存和可擴充套件性,還有關係的模型,以及線上交易型資料庫上的應用。所以,今天整個資料庫的模式和反模式,我都會圍繞著如何在一個海量的併發,海量的資料儲存的容量上,去做線上實時的資料庫業務的一些模式來講。並從資料庫的開發者角度,來為大家分享怎樣寫出更加適合資料庫的一些程式。
### 基礎軟體的發展趨勢 先簡單介紹一下,現在我認為的一些基礎軟體上的發展趨勢。 #### 開源 第一點,開源是一個非常大的趨勢。大家可以看到一些比較著名的基礎軟體,基本都是開源的,比如 Docker,比如 k8s。甚至在網際網路公司裡面用的非常多的軟體,像 MySQL、Hadoop 等這種新一代的大資料處理的資料庫等基礎軟體,也大多是開源的。其實這背後的邏輯非常簡單:在未來其實你很難去將你所有的技術軟體都用閉源, 因為開源會慢慢組成一個生態,而並不是被某一個公司繫結住。比如國家經常說去 IOE,為什麼?很大的原因就是基本上你的業務是被基礎軟體綁死的,這個其實是不太好的一個事情。而且現在跟過去二十年前不一樣,無論是開源軟體的質量,還是社群的迭代速度,都已經是今非昔比,所以基本上開源再也不是低質低量的代名詞,在網際網路公司已經被驗證很多次了。 #### 分散式 第二,分散式會漸漸成為主流的趨勢。這是為什麼?這個其實也很好理解,因為隨著資料量越來越大,大家可以看到,隨著現在的硬體發展,我感覺摩爾定律有漸漸失效的趨勢。所以單個節點的計算資源或者計算能力,它的增長速度是遠比資料的增長速度要慢的。在這種情況下,你要完成業務,儲存資料,要應對這麼大的併發,只有一種辦法就是橫向的擴充套件。橫向的擴充套件,分散式基本是唯一的出路。scale-up 和 scale-out 這兩個選擇其實我是堅定的站在 scale-out 這邊。當然傳統的關聯式資料庫都會說我現在用的 Oracle,IBM DB2,他們現在還是在走 scale-up 的路線,但是未來我覺得 scale-out 的方向會漸漸成為主流。 #### 碎片化 第三,就是整個基礎軟體碎片化。現在看上去會越來越嚴重。但是回想在十年前、二十年前,大家在寫程式的時候,我上面一層業務,下面一層資料庫。但是現在你會發現,隨著可以給你選擇的東西越來越多,可以給你在開源社群裡面能用到的元件越來越多,業務越來越複雜,你會發現,像快取有一個單獨的軟體,比如 redis,佇列又有很多可以選擇的,比如說 zeromq,rabbitmq,celery 各種各樣的佇列;資料庫有 NoSQL、HBase,關係型資料庫有 MySQL、PG 等各種各樣的基礎軟體都可以選。但是就沒有一個非常好東西能夠完全解決自己的問題。所以這是一個碎片化的現狀。 #### 微服務 第四,是微服務的模式興起。其實這個也是最近兩年在軟體架構領域非常火的一個概念。這個概念的背後思想,其實也是跟當年的 SOA 是一脈相承的。就是說一個大的軟體專案,其實是非常難去 handle 複雜度的,當你業務變得越來越大以後,維護成本和開發成本會隨著專案的程式碼量呈指數級別上升的。所以現在比較流行的就是,把各個業務之間拆的非常細,然後互相之間儘量做到無狀態,整個系統的複雜度可以控制,是由很多比較簡單的小的元件組合在一起,來對外提供服務的。 這個服務看上去非常美妙,一會兒會說有什麼問題。最典型的問題就是,當你的上層業務都拆成無狀態的小服務以後,你會發現原有的邏輯需要有狀態的儲存服務的時候你是沒法拆的。我所有的業務都分成一小塊,每一小塊都是自己的資料庫或者資料儲存。比如說一個簡單的 case,我每一個小部分都需要依賴同一個使用者資訊服務,這個資訊服務會變成整個系統的一個狀態集中的點,如果這個點沒有辦法做彈性擴充套件或者容量擴充套件的話,就會變成整個系統很致命的單點。
所以現在整個基礎軟體的現狀,特別在網際網路行業是非常典型的幾個大的趨勢。我覺得大概傳統行業跟網際網路行業整合,應該在三到五年,這麼一個時間。所以網際網路行業遇到的今天,可能就是傳統行業,或者其他的行業會遇到的明天。所以,通過現在整個網際網路裡面,在資料儲存、資料架構方面的一些比較新的思想,我們就能知道如何去做這個程式的設計,應對明天資料的量級。
### 現有儲存系統的痛點
其實今天主要的內容是講儲存系統,儲存系統現在有哪些痛點?其實我覺得在座的各位應該也都能切身的體會到。
#### 彈性擴充套件
首先,大資料量級下你如何實現彈性擴充套件?因為我們今天主要討論的是 OLTP ,是線上的儲存服務,並不是離線分析的服務。所以線上的儲存服務,它其實要做到的可用性、一致性,是要比離線的分析業務強得多的。但是在這種情況下,你們怎樣做到業務無感知的彈性擴充套件,你的資料怎麼很好的滿足現有的高併發、大吞吐,還有資料容量的方案。
#### 可用性
第二,在分散式的儲存系統下,你的應用的可用性到底是如何去定義,如何去保證?其實這個也很好理解,因為在大規模的分散式系統裡面,任何一個節點,任何一個資料中心或者支架都有可能出現硬體的故障,軟體的故障,各種各樣的故障,但這個時候你很多業務是並沒有辦法停止,或者並沒有辦法去容忍 down time 的。所以在一個新的環境之下,你如何對你係統的可用性做定義和保證,這是一個新的課題。一會兒我會講到最新的研究方向和成果。
#### 可維護性
第三,對於大規模的分散式資料庫來說它的可維護性,這個怎麼辦?可維護性跟單機的系統是明顯不同的,因為單機的資料庫,或者傳統的單點的資料庫,它其實做到主從,甚至做到一主多從,我去維護 master ,別讓它掛掉,這個維護性主要就是維護單點。在一個大規模的分散式系統上,你去做這個事情是非常麻煩的。可以簡單說一個案例,就是 Google 的 Spanner。Spanner 是 Google 內部的一個大規模分散式系統,整個谷歌內部只部署了一套,在生產環節中只部署了一套。這一套系統上有上萬甚至上數十萬的物理節點。但是整個資料庫的維護團隊,其實只有很小的一組人。想像一下,上十萬臺的物理節點,如果你要真正換一塊盤、做一次資料恢復或者人工運維的話,這是根本不可能做到的事情。但是對於一個分散式系統來說,它的可維護性或者說它的維護應該是轉嫁給資料庫自己。
#### 開發複雜度
還有,就是對於一個分散式資料庫來說,它在開發業務的時候複雜度是怎麼樣的。大家其實可能接觸的比較多的,像 Hbase、Cassandra、Bigtable 等這種開源的實現,像 NoSQL 資料庫它其實並沒有一個很好的 cross-row transaction 的 support。另外,對於很多的 NoSQL 資料庫並沒有一個很好的 SQL 的 interface,這會讓你寫程式變得非常麻煩。比如說對於一些很普通的業務,一個表,我需要去 select from table,然後有一個 fliter 比如一個條件大於 10,小於 100,這麼簡單的邏輯,如果在 HBase 上去做的話,你要寫十行、二十行、三十行;如果你在一個關係的資料庫,或者支援 SQL 的資料庫,其實一行就搞定了。其實這個對於很多網際網路公司來說,在過去的幾年之內基本上已經完成了這種從 RDBMS 到 NoSQL 的改造,但是這個改造的成本和代價是非常非常高的。比如我原來的業務可能在很早以前是用 MySQL 已經寫的穩定執行好久了,但是隨著併發、容量、可擴充套件性的要求,我需要遷移 Bigtable、Hbase、Cassandra、MongoDB 這種 NoSQL 資料庫上,這時基本上就要面臨程式碼的完整重寫。這個要放在網際網路公司還可以,因為它們有這樣的技術能力去保證遷移的過程。反正我花這麼多錢,招這麼牛的工程師,你要幫我搞定這個事情。但是對於傳統的行業,或者傳統的機構來說,這個基本上是不可能的事情。你不可能讓他把原來用 Oracle 用 SQL 的程式碼改成 NoSQL 的 code。 因為 NoSQL 很少有跨行事務,首先你要做一個轉賬,你如果不是一個很強的工程師,你這個程式基本寫不對,這是一個很大的問題。這也是為什麼一直以來像這種 NoSQL 的東西並沒有很好的在傳統行業中去使用的一個最核心的原因,就是代價實在太大。
### 儲存系統的擴充套件模型
所以其實在去講這些具體到底該怎麼解決,或者未來資料庫會是什麼樣的之前,我想簡單講一下擴充套件的模型。對於一個關係型資料庫也好,對於儲存的系統本身也好,它的擴充套件模型有哪些。
####Sharding 模式
第一種模式是 Sharding 模式。如果在座的各位有運維過線上的 MySQL 的話,對這個模型會非常熟悉。最簡單的就是分庫、分表加中介軟體,就是說我不同的業務可能用不同的庫,不同的表。當一個單表太大的時候,我通過一些 Cobar、Mycat 等這樣的資料庫中介軟體來去把它分發到具體的資料庫的例項上。這種模型是目前用的最普遍的模型,它其實也解決了很大部分的問題。為什麼這十年在關係型資料庫上並沒有很好的擴充套件方案,但是大家看上去這種業務還沒有出現死掉的情況,就是因為後面有各種各樣 Sharding 的中介軟體或者分庫分表這種策略在硬扛著。像這種中介軟體 Sharding 第一個優勢就是實現非常簡單。你並不需要對資料庫內做任何的改造,你也並不需要去比如說從你原來的 SQL 程式碼轉到 NoSQL 的程式碼。
但是它也有自己的缺點。首先,對你的業務層有很強的侵入性。這是沒有辦法的,比如你想用一箇中介軟體,你就需要給它指定一個 Sharding key。另外,原來比如你的業務有一些 join ,有一些跨表跨行的事務,像這種事務你必須得改掉,因為很多中介軟體並沒有辦法支援這個跨 shard 的分散式 join。
第二個比較大的缺陷是它的分片基本是固定的,自動化程度、擴充套件性都非常差,你必須得有一個專職的 DBA 團隊給你的 MySQL 或者 PG 的 Sharding 的叢集去做運維。我之前在豌豆莢做過一段時間 MySQL cluster 的分片的維護工作。當時我記得是一個 16 個節點的 MySQL 的叢集,我們需要擴充套件到 32 個節點的規模,整整提前演練了一個月,最後上線了一個禮拜。上線那個禮拜,晚上基本上沒有辦法睡覺,所以非常痛苦。 再說一個 Google 的事情,Google 在剛才我說的 Spanner 和 F1 這兩個資料庫沒有上線之前,Google 的廣告系統的業務是由 100 多個節點的 MySQL 的叢集對外提供服務的。如 Google 這麼牛的公司,在維護一百多個節點的 MySQL Sharding 的資料庫的時候,都已經非常痛苦,寧可重新去寫一個資料庫,也不想去維護這個 datebase cluster。其實大家可以看到,像這種 Sharding 的方案,它比較大的問題就是它的維護代價或者維護叢集的複雜度,並不是隨著節點數呈線性增長,而是隨著節點的增加非線性的增長上去。比如你維護 2 個節點的還好,維護 4 個節點的也還可以,但是你維護 16 個、64 個、128 個基本就是不可能的事情。
第三就是一些複雜的查詢優化,並沒有辦法在中介軟體這一層,去幫你產生一個足夠優化的執行計劃,因此,對於一些複雜查詢來說,Sharding 的方案是沒法做的。所以對你的業務層有很高的要求。
####Region Base 模型
第二種擴充套件模型是 Region Base。這張圖是我專案裡面扒出來的圖。
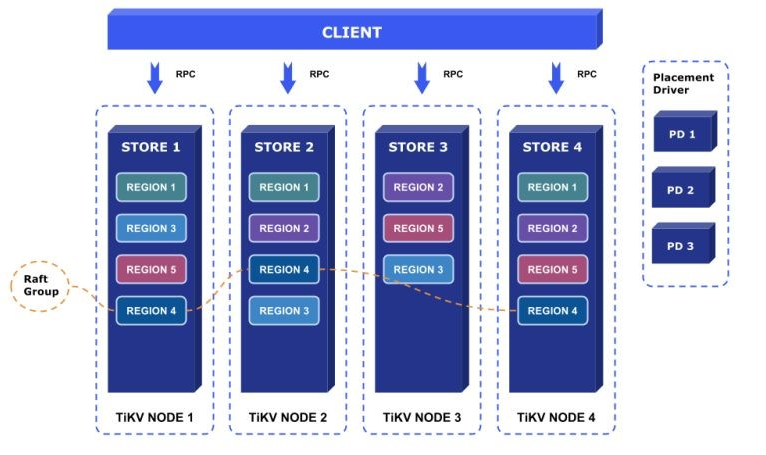 它整個思路有點像 Bigtable,它相當於把底下的儲存層分開,資料在最底層儲存上已經沒有表、行這樣結構的劃分,每一塊資料都由一個固定的 size 比如 64 M、128 M 連續的 Key-value pairs 組成。其實這個模型背後最早的系統應該是谷歌在 06 年發表的 Bigtable 這篇論文裡面去描述的。這個模型有什麼好處呢?一是它能真正實現這種彈性的擴充套件。第二個,它是一個真正高度去中心化。去中心化這個事情,對於一個大的 Cluster 來說是一個非常重要的特性。
還有一個優勢,在 KV 層實現真正具有一定的自動 Failover 的能力。 Failover 指的是什麼呢?比如說在一個叢集比較大的情況下,或者你是一個 cluster,你任何一個節點,任何一個資料損壞,如果能做到業務端的透明,你就真正實現了 Auto-Failover 的能力。其實在一些對一致性要求不那麼高的業務裡面,Auto-Failover 就是指, 比如在最簡單的一個 MySQL 組從的模型裡,當你的組掛掉了以後,我監控的程式自動把 slave 提上來,這也是一種 Failover 的方式。但是這個一致性或者說資料的正確性並不能做到很好的保證。你怎麼做到一致性的 Auto-Failover,其實背後需要做非常非常多的工作。 這是 Region 模型的一些優勢。但是它的劣勢也同樣明顯,這種模型的實現非常複雜。我一會兒會說到背後的關鍵技術和理論,但是它比起寫中介軟體真的複雜太多了。你要寫一個能用的 MySQL 或者 PG 的中介軟體,可能只需要一兩個工程師,花一兩週的時間就能寫出一個能用的資料庫中介軟體;但是你如果按照這個模型做一個彈性擴充套件的資料庫的話,你的工作量就會是數量級的增加。
第二個劣勢就是它業務層的相容性。像 Region Base 的模型,最典型的分散式儲存系統就是 HBase。HBase 它對外的程式設計介面和 SQL 是千差萬別,因為它是一個 Key Value 的資料庫。你的業務層的程式碼相容性都得改,這個對於一些沒有這麼強開發能力的使用者來說,是很難去使用的,或者它說沒有 SQL 對於使用者端這麼友好。
### 可用性級別
我一會兒會講一下,剛才我們由 Region Base 這個模型往上去思考的一些東西,在此之前先說一些可用性。高可用。其實說到高可用這個詞,大多數的架構師都對它非常熟悉。我的系統是高可用的,任何一個節點故障業務層都不受影響,但是真的不受影響嗎?我經過很多的思考得到的一個經驗就是主從的模型是不可能保證同時滿足強一致性和高可用性的。可能這一點很多人覺得,我主從,我主掛了,從再提起來就好,為什麼不能保護這個一致性呢?就是因為在一個叢集的環境下,有一種故障叫腦裂。腦裂是什麼情況?整個叢集是全網路聯通的,但是出現一種情況,就是我只是在叢集內部分成了兩個互不聯通的一個子集。這兩個子集又可以對外提供服務,其實這個並不是非常少見的狀況,經常會發生。像這種情況,你貿然把 slave 提起來,相當於原來的 master 並沒有完全的被 shutdown,這個時候兩邊可能都會有讀寫的情況,造成資料非常嚴重的不一致,當然這個比較極端了。所以你會發現阿里或者說淘寶,年年都在說我們有異地多活。但是去年甚至前幾個月,杭州阿里的資料中心光纖被挖斷,支付寶並沒有直接切到重複層,而是寧可停止服務,完全不動,也不敢把 slave 資料中心提起來。所以其實任何基於主從模型的異地多活方案都是不行的。這個問題有沒有辦法解決呢?其實也是有的。 還是說到 Google,我認為它才是全世界最大的資料庫公司,因為它有全世界最大的資料量。你從來沒有聽說過 Google 哪一個業務因為哪一個資料中心光纖挖斷,哪一個磁碟壞了而對外終止服務的,幾乎完全沒有。因為 Google 的儲存系統大多完全拋棄了基於主從的一致性模型。它的所有資料都不是通過主從做複製的,而是通過類似 Raft 或者 Paxos 這種分散式選舉的演算法做資料的同步。這個演算法的細節不展開了,總體來說是一個解決在資料的一致性跟自動的資料恢復方面的一個演算法。同時,它的 latency 會比多節點強同步的主從平均表現要好的一個分散式選舉的演算法。 在 Google 內部其實一直用的 Paxos,它最新的 Spanner 資料庫是用 Paxos 做的 replication 。在社群裡面,跟 Paxos 等價的一個演算法就是 Raft。Raft 這個演算法的效能以及可靠性都是跟 Paxos 等價的實現。這個演算法就不展開了。我認為這才是新一代的強一致的資料庫應該使用的資料庫複製模型。
### 分散式事務
說到事務。對於一個資料庫來說,我要做傳統的關係型資料庫業務,事務在一個分散式環境下,並不像單機的資料庫有這麼多的方法,這麼多的優化。其實在分散式事務這個領域只有一種方法,並且這麼多年了從分散式事務開始到現在,在這個方法上並沒有什麼突破,基本只有一條出路就是兩階段提交。其實可以看一下 Google 的系統。對於我們做分散式系統的公司來說,Google 就是給大家帶路的角色。Google 最新的資料庫系統上它使用的分散式事務的方法仍然是兩階段提交。其實還有沒有什麼優化的路呢?其實也是有的。兩階段提交最大的問題是什麼呢?一個是延遲。因為第一階段先要把資料發過去,第二階段要收到所有參與的節點的 response 之後你才能去 commit 。這個過程,相當於你走了很多次網路的 roundtrip,latency 也會變得非常高。所以其實優化的方向也是有的,但是你的 latency 沒法優化,只能通過吞吐做優化,就是 throughput 。比如說我在一萬個併發的情況下,每個使用者的 latency 是 100 毫秒,但是一百萬併發,一千萬併發的時候,我每個使用者的 latency 還可以是 100 毫秒,這在傳統的單點關係型資料庫上,是沒有辦法實現的。第二就是去中心化的事務管理器。另外沒有什麼東西是銀彈,是包治百病的,你要根據你的業務的特性去選擇合適的一致性演算法。
###NewSQL
其實剛剛這些 pattern 會發展出一個新的類別,我們能不能把關聯式資料庫上的一些 SQL、Transaction 跟 NoSQL 跟剛才我說到的 Region Base 的可擴充套件的模型融合起來。這個思想應該是在 2013 年左右的時候,學術界提出來比較多的東西,NewSQL。NewSQL 首先要解決 Scalability 的問題, 剛給我們說過 scalability 是一個未來的資料庫必須要有的功能,第二個就是 SQL,SQL 對於業務開發者來說是很好的程式設計的介面。第三,ACID Transaction,我希望我的資料庫實現轉帳和存錢這種強一致性級別的業務。第四,就是整個 cluster 可以支援無窮大的資料規模,同時任何資料節點的當機、損壞都需要叢集自己去做監控,不需要 DBA 的介入。
它整個思路有點像 Bigtable,它相當於把底下的儲存層分開,資料在最底層儲存上已經沒有表、行這樣結構的劃分,每一塊資料都由一個固定的 size 比如 64 M、128 M 連續的 Key-value pairs 組成。其實這個模型背後最早的系統應該是谷歌在 06 年發表的 Bigtable 這篇論文裡面去描述的。這個模型有什麼好處呢?一是它能真正實現這種彈性的擴充套件。第二個,它是一個真正高度去中心化。去中心化這個事情,對於一個大的 Cluster 來說是一個非常重要的特性。
還有一個優勢,在 KV 層實現真正具有一定的自動 Failover 的能力。 Failover 指的是什麼呢?比如說在一個叢集比較大的情況下,或者你是一個 cluster,你任何一個節點,任何一個資料損壞,如果能做到業務端的透明,你就真正實現了 Auto-Failover 的能力。其實在一些對一致性要求不那麼高的業務裡面,Auto-Failover 就是指, 比如在最簡單的一個 MySQL 組從的模型裡,當你的組掛掉了以後,我監控的程式自動把 slave 提上來,這也是一種 Failover 的方式。但是這個一致性或者說資料的正確性並不能做到很好的保證。你怎麼做到一致性的 Auto-Failover,其實背後需要做非常非常多的工作。 這是 Region 模型的一些優勢。但是它的劣勢也同樣明顯,這種模型的實現非常複雜。我一會兒會說到背後的關鍵技術和理論,但是它比起寫中介軟體真的複雜太多了。你要寫一個能用的 MySQL 或者 PG 的中介軟體,可能只需要一兩個工程師,花一兩週的時間就能寫出一個能用的資料庫中介軟體;但是你如果按照這個模型做一個彈性擴充套件的資料庫的話,你的工作量就會是數量級的增加。
第二個劣勢就是它業務層的相容性。像 Region Base 的模型,最典型的分散式儲存系統就是 HBase。HBase 它對外的程式設計介面和 SQL 是千差萬別,因為它是一個 Key Value 的資料庫。你的業務層的程式碼相容性都得改,這個對於一些沒有這麼強開發能力的使用者來說,是很難去使用的,或者它說沒有 SQL 對於使用者端這麼友好。
### 可用性級別
我一會兒會講一下,剛才我們由 Region Base 這個模型往上去思考的一些東西,在此之前先說一些可用性。高可用。其實說到高可用這個詞,大多數的架構師都對它非常熟悉。我的系統是高可用的,任何一個節點故障業務層都不受影響,但是真的不受影響嗎?我經過很多的思考得到的一個經驗就是主從的模型是不可能保證同時滿足強一致性和高可用性的。可能這一點很多人覺得,我主從,我主掛了,從再提起來就好,為什麼不能保護這個一致性呢?就是因為在一個叢集的環境下,有一種故障叫腦裂。腦裂是什麼情況?整個叢集是全網路聯通的,但是出現一種情況,就是我只是在叢集內部分成了兩個互不聯通的一個子集。這兩個子集又可以對外提供服務,其實這個並不是非常少見的狀況,經常會發生。像這種情況,你貿然把 slave 提起來,相當於原來的 master 並沒有完全的被 shutdown,這個時候兩邊可能都會有讀寫的情況,造成資料非常嚴重的不一致,當然這個比較極端了。所以你會發現阿里或者說淘寶,年年都在說我們有異地多活。但是去年甚至前幾個月,杭州阿里的資料中心光纖被挖斷,支付寶並沒有直接切到重複層,而是寧可停止服務,完全不動,也不敢把 slave 資料中心提起來。所以其實任何基於主從模型的異地多活方案都是不行的。這個問題有沒有辦法解決呢?其實也是有的。 還是說到 Google,我認為它才是全世界最大的資料庫公司,因為它有全世界最大的資料量。你從來沒有聽說過 Google 哪一個業務因為哪一個資料中心光纖挖斷,哪一個磁碟壞了而對外終止服務的,幾乎完全沒有。因為 Google 的儲存系統大多完全拋棄了基於主從的一致性模型。它的所有資料都不是通過主從做複製的,而是通過類似 Raft 或者 Paxos 這種分散式選舉的演算法做資料的同步。這個演算法的細節不展開了,總體來說是一個解決在資料的一致性跟自動的資料恢復方面的一個演算法。同時,它的 latency 會比多節點強同步的主從平均表現要好的一個分散式選舉的演算法。 在 Google 內部其實一直用的 Paxos,它最新的 Spanner 資料庫是用 Paxos 做的 replication 。在社群裡面,跟 Paxos 等價的一個演算法就是 Raft。Raft 這個演算法的效能以及可靠性都是跟 Paxos 等價的實現。這個演算法就不展開了。我認為這才是新一代的強一致的資料庫應該使用的資料庫複製模型。
### 分散式事務
說到事務。對於一個資料庫來說,我要做傳統的關係型資料庫業務,事務在一個分散式環境下,並不像單機的資料庫有這麼多的方法,這麼多的優化。其實在分散式事務這個領域只有一種方法,並且這麼多年了從分散式事務開始到現在,在這個方法上並沒有什麼突破,基本只有一條出路就是兩階段提交。其實可以看一下 Google 的系統。對於我們做分散式系統的公司來說,Google 就是給大家帶路的角色。Google 最新的資料庫系統上它使用的分散式事務的方法仍然是兩階段提交。其實還有沒有什麼優化的路呢?其實也是有的。兩階段提交最大的問題是什麼呢?一個是延遲。因為第一階段先要把資料發過去,第二階段要收到所有參與的節點的 response 之後你才能去 commit 。這個過程,相當於你走了很多次網路的 roundtrip,latency 也會變得非常高。所以其實優化的方向也是有的,但是你的 latency 沒法優化,只能通過吞吐做優化,就是 throughput 。比如說我在一萬個併發的情況下,每個使用者的 latency 是 100 毫秒,但是一百萬併發,一千萬併發的時候,我每個使用者的 latency 還可以是 100 毫秒,這在傳統的單點關係型資料庫上,是沒有辦法實現的。第二就是去中心化的事務管理器。另外沒有什麼東西是銀彈,是包治百病的,你要根據你的業務的特性去選擇合適的一致性演算法。
###NewSQL
其實剛剛這些 pattern 會發展出一個新的類別,我們能不能把關聯式資料庫上的一些 SQL、Transaction 跟 NoSQL 跟剛才我說到的 Region Base 的可擴充套件的模型融合起來。這個思想應該是在 2013 年左右的時候,學術界提出來比較多的東西,NewSQL。NewSQL 首先要解決 Scalability 的問題, 剛給我們說過 scalability 是一個未來的資料庫必須要有的功能,第二個就是 SQL,SQL 對於業務開發者來說是很好的程式設計的介面。第三,ACID Transaction,我希望我的資料庫實現轉帳和存錢這種強一致性級別的業務。第四,就是整個 cluster 可以支援無窮大的資料規模,同時任何資料節點的當機、損壞都需要叢集自己去做監控,不需要 DBA 的介入。
案例:Google Spanner / F1
有沒有這樣的系統?其實有的。剛才一直提到 Google 的 Spanner 系統。Spanner 系統是在 2012 年底於 OSDI 的會議上釋出了論文; F1 這篇論文在 2013 年的 VLDB 釋出的,去描述了整個 Google 內部的分散式關係型資料庫的實現。首先,根據 Spanner 的論文 Spanner 和 F1 在生產環境只有一個部署,上萬物理節點遍佈在全球各種資料中心內,通過 Paxos 進行日誌複製。第二,整個架構是無狀態的 SQL 層架在一個 NoSQL 的基礎之上。第三,它對外提供的是一個跨行事務的語義,這個跨行事務是透明的跨行事務,我不需要對我的業務層做修改,它是通過 一個硬體支援的 Truetime API,GPS 時鐘和原子鐘去實現事務的隔離級別。這個系統是最早用來支撐 Google 的線上廣告業務,線上廣告業務大家知道,其實對於扣費、廣告計費、點選記錄,廣告活動等一致性的級別要求非常高。首先這個錢不能多扣,也不能少扣,實時性要求非常高。而且業務邏輯相當複雜,這個時候需要一個 SQL 資料庫,需要一個支援事務的資料庫,需要一個支援 Auto-Failover 的資料庫,所以就有了 Google Spanner/F1 這個系統。 ### 典型業務場景 最典型的業務場景是什麼呢?對於這種高吞吐、大容量的資料量級對於 NoSQL 系統來說,典型的應用的 Pattern 就是高吞吐大容量,還有就是 Workload 相對比較分散的情況。比較典型的反例是秒殺,秒殺這個場景其實非常不適合這種 NewSQL。另外就是一致性、可用性和 latency 之間怎麼做取捨。在這種分散式資料庫上面,第一個要丟棄的就是延遲,在這麼大規模的量級上做強一致性,延遲是首先是不能保證的。你去看谷歌的 F1 和 Spanner 的論文裡面,它提到它們的 latency 基本都是 10 毫秒、20 毫秒、甚至 50 毫秒、100 毫秒的量級,但是它並不會太關心 latency 。因為它必須保證通過 Paxos 去做跨機房、多機房的複製,光速你肯定沒法超越,所以這個時間是省不了的,它整個系統是面向吞吐設計的,而不是面向低延遲設計的,但是它要求非常強的一致性。 ####MySQL Sharding 一個典型的場景就是替換 MySQL Sharding 的業務。它的業務典型的特點,就是高吞吐,海量併發的小事務,並不是特別大的 transection,模型也相對簡單,沒有複雜的 join 的程式。但是痛點剛才提到了非常明顯,首先就是對於 MySQL Sharding 方案 scale 能力很差,對於表結構變更的方案並沒有太多;再者,cross shard transaction,目前 Sharding 的方案並沒有辦法很好支援,但 NewSQL 面向的場景和 MySQL Sharding 面向的場景是非常的像的。 ####Cross datacenter HA 第二種場景是 Cross datacenter HA(跨資料中心多活),這種場景簡直是資料開發者追求的聖盃。因為像 Oracle、DB2 文,它在最關鍵,最核心的業務上,比如說像銀行這種業務,它必須要求實現這種跨資料中心的高可用。但是在一個分散式的資料庫上,或者說是 Open-source solution 裡,有沒有人有辦法實現這個 Cross datacenter HA 呢?完全沒有。目前來說並沒有任何一個資料庫能去解決這個問題。因為剛才提到了主從的模型根本是不可靠的。像這種業務的資料極端的重要,任何一點資料的丟失都不能容忍。另外即使整個資料中心當機也不能影響線上的業務,很典型的像支付寶,這種涉及錢相關的,甚至有些比如你的銀行卡,你肯定不能容忍說你吃完飯,告訴你不好意思資料中心掛了,你的錢我刷不了。但是並沒有開源的資料庫能解決這個問題,如果你真的自己做同步複製的方案的話,特別兩地三中心的情況,你請求的延遲是取決於離你最遠的資料中心,所以大部分業務來說延遲過大。 另外就是這些系統重度依賴人工運維。我認為一旦任何系統有人工的介入一定是會出錯的。因為人是最難自動化的一個因素。 ### 反模式 #### 濫用傳統關係模型 對於這種大規模的分散式 NewSQL 來說,比較大的反模式就是,大量的使用儲存過程 foreign key,檢視等操作。因為首先儲存過程是沒有辦法 scale 的。另外,大表與大表的 JOIN ,線上上的 OLTP 資料庫上最大的開銷並不是優化器的開銷,而是網路通訊的開銷。比如兩個表去做一個笛卡兒積,算起來可能並不是這麼慢,但是要把資料一條一條在網路中傳輸代價是非常大的,這種情況下用 OLAP 的資料庫是比較適合。 #### 沒有利用好併發 剛才我一直強調對於新型的 OLTP 或者分散式關係型資料庫來說,併發或者說吞吐才是應該追求的優化點。在架構設計時,不應該把對延遲非常敏感的業務去使用分散式資料庫來實現。所以其實在延遲跟吞吐之間,資料庫永遠去選擇吞吐。所以寫程式會遇到的一個很典型的問題,就是我的查詢是一行一行,上下之間有這種強依賴關係的模式。其實在這種模式下,對於分散式關係型資料庫來說是非常不合適的。所以你應該用併發的思想去做,比如說我的請求,我可以把吞吐打到整個叢集上,我的 Database,我的 cluster 會自動 balance 一些 workload,如果一行行查詢之間是有依賴的話,那麼每一條查詢之間的 latency 是會疊加起來。所以這個其實並不是一個太好的 pattern 。 #### 不均勻的設計 資料庫其實經常會被大家濫用。比如說我看到很多傳統行業資料庫使用的方法,其實真的是非常痛苦。無論什麼業務我全都直接上 Oracle,不管這個業務是否真的需要 Database 來去支援;比如有人用 MySQL 做計數器,有些有 MySQL 做佇列或者做秒殺,這個並不是太 scale 的東西。特別像秒殺的業務,特別高的併發打到同一個 key 上,workload 沒辦法去分拆到好多個節點來幫你去處理,所以整個分散式的叢集就會退化成一個單點,這是非常不合理的。第二,當你的索引設計的不太好的時候,涉及到的過多全表掃描是非常不划算的。剛剛也說過,在一個分散式叢集裡面,最大的開銷是網路的開銷,你做全表掃描的時候並不是在一臺機器上,而是在好多機器上做全表掃描,同時經過很大的網路傳輸,當你的索引設計不合理的時候會出現這樣的問題。還有是過多的無效索引,會導致整個系統在寫入的時候有延遲也好或者吞吐也好,會變得更慢。主要注意的就是不要存在任何可以把你的系統退化成單點的機會。 #### 錯誤的一致性模型 還有一種最容易犯的問題,就是在沒有好好思考你的業務適合的場景情況下,就去使用很強的一致性模型。因為當你要求一個非常高的強一致性的時候,你的分散式事務的 latency 一定比不這麼強的一致性的業務要高得多的。其實,很多業務並不需要那麼強的一致性,我的資料庫雖然給你了這個能力,但如果你去濫用的話,你會說這個資料庫好慢,或者為什麼我這個請求 100 毫秒才給我返回。但其實很多場景下,你並不是這麼強的依賴強一致性 。這個跟資料庫本身提不提供這個機制是沒有關係的。作為一個 Database 開發者來說,我還是需要給你能實現這個功能的機制,但是不要濫用。 另外根據你業務的衝突的頻繁程度選擇不同的鎖策略。你知道這個業務就是一個很高的衝突的場景,比如說可能像類似發工資,一個集團的賬號發到成千上萬的小賬號。如果你是一個樂觀事務的話,可能涉及到的衝突就會很大。因為所有的事務的發起者都要去修改這個公共賬號,這種情況下一般可以使用悲觀事務,因為你已經預知到你業務的 conflict 級別會很高。但當我知道我的業務的衝突很小,我要追求整個系統的吞吐,我可能會選用樂觀的事務的模型。 ###Q&A 問:對於秒殺這個場景,什麼樣的資料庫設計是合適的? >黃東旭:其實秒殺這個業務是一個比較系統的工程,並不是一個簡單的我用什麼資料庫就可以做的東西。我之前給一些朋友做秒殺的架構設計的時候,從最上層,甚至你可能從 JS 這邊就要去做排隊,一層一層的排隊。比如在快取這邊我可以用 redis,我可以用一些快取的資料庫再去進行二級的排隊,因為每一次排隊你都會丟掉很多,最後到底下的佇列,在資料庫這一層,比如庫存就十個,你只要在前面放十個進來就行了。就是說,你在上層把流量用排隊的方式做更好。最典型的例子就是大家看 12306 賣火車票的時候經常會有排隊。基本沒有什麼資料庫能去應對,像淘寶,像京東這種秒殺的業務,它從上到下是整個系統的過程。謝謝。
問:分散式的 OLTP 資料庫,歷史資料怎麼清理,如果後續還需要分析資料的話。 >黃東旭:其實在谷歌 Spanner 包括像 TiDB 、TiKV 這個系統之上,是通過一種 MVCC 的技術,每一條資料都會有一個版本號。比如說你不停的 update,它可能會產生好多版本。我背後會有一個 GC 的邏輯,去選定一個 safe point,在這個 safe point 之前的所有資料全都刪掉也好,還是挪到冷的儲存上也好,我們是通過這種方式實現的。另外隨著資料量的膨脹,整個系統設計的時候,我們是通過 Raft 演算法,比如說這個資料慢慢長大,我會把它切成兩塊,再慢慢 Auto-balance 到其它的節點上,然後新的那一塊會再長大......這相當於一個細胞一樣,一個細胞分裂成兩個細胞,成千上萬的細胞會均勻的分佈在整個叢集裡面。如果你要刪資料可以直接刪,如果你不想刪的話,你的資料可以全都留下,你自己隨便往叢集裡增加新的節點。這個叢集很大,它會自動幫你把資料均勻的分到這兒。所有的歷史資料是通過 GC 的模組把歷史的版本拿出來,丟到冷的儲存上。 在 Google 幾乎是完全不刪資料的,因為儲存的成本是很低的,但是資料未來說不定什麼時候就用了。大概是這樣,我需要有一個辦法能把它存下來。
問:當前做的交易要使用歷史的參考資料,可能量不是很大,有這樣的例子嗎? >黃東旭:當然有。像 MVCC 在訪問歷史,它其實提供了一個 Lock-free 的 Snapshot Read, 它在讀歷史版本的時候是不會讀線上的正在進行的讀寫事務,所以它是有一個無所讀的機制,這也是為什麼它要去採用每一個資料都要有版本號的機制去實現。它是有這個需求,而且在實現的時候也非常漂亮,不會阻塞其他的請求。
問:TiDB 是怎麼考慮用 MySQL 或者 PG 的?當時是怎麼考慮的? >黃東旭:首先我們沒有用 MySQL 或者 PG,剛才說的 TiDB 這個模型是谷歌的 Spanner 跟 F1 的模型。用傳統的單機資料庫做改造的話,有一個比較大的誤區,整個 SQL 的查詢優化器跟儲存的資料結構,並不知道你底層是分散式的儲存,它還是假設你生成 SQL 的方案都是單機的。比如最簡單的例子,我需要去 count *,如果是一個單機的 MySQL 優化器,沒有建索引的話會一行一行把資料拉過來計一個數,這樣算下去;但是如果對一個分散式系統來說,我只要把 count * 這個邏輯推到所有儲存表的資料節點上,演算法再 reduce 回來就可以,更像一個 Mapreduce 這種分散式框架的 SQL 優化器。如果你沒有從底到上完整的去實現 Database 的話,你很難對分散式的場景或者分散式資料儲存的這些性質來去對資料庫做優化。沒有辦法,這是一條很難的道路,但是我們也得去下走。
![[CDAS 2016] 分散式資料庫模式與反模式](https://gocn.vip/uploads/gopherchina.jpg)
- 加微信實戰群請加微信(註明:實戰群):gocnio
相關文章
- 反DDD模式之關係型資料庫模式資料庫
- Kafka Eagle分散式模式Kafka分散式模式
- 分散式資料庫分散式資料庫
- 資料庫的模式資料庫模式
- 分散式資料庫的需求與場景分散式資料庫
- 集中式資料庫與分散式資料庫的戰場與戰爭資料庫分散式
- 大資料分散式儲存的部署模式:分離式or超融合大資料分散式模式
- 分散式資料庫概述分散式資料庫
- Greenplum資料庫,分散式資料庫,大資料資料庫分散式大資料
- 分散式資料(4)分散式與版本化分散式
- 完全分散式模式hadoop叢集安裝與配置分散式模式Hadoop
- 達夢資料庫使用者與模式管理資料庫模式
- 分散式事務Saga模式分散式模式
- 分散式資料庫系列(三)分散式資料庫
- 分散式資料庫系列(二)分散式資料庫
- 分散式資料庫系列(一)分散式資料庫
- 區塊鏈與分散式資料庫的比較區塊鏈分散式資料庫
- 分析型資料庫:分散式分析型資料庫資料庫分散式
- 更改資料庫的相容模式資料庫模式
- Vim反模式模式
- 資料庫的FLASHBACK 與ARCHIVELOG模式的關係資料庫Hive模式
- 服務設計的原則:服務模式與反模式模式
- 分散式資料庫 ZNBase 的分散式計劃生成分散式資料庫
- 區塊鏈中的分散式模式區塊鏈分散式模式
- 《分散式資料庫HBase案例教程》分散式資料庫
- 分散式資料庫管理系列(一)分散式資料庫
- openGauss 分散式資料庫能力分散式資料庫
- 分散式事務之事務實現模式與技術(四)分散式模式
- 國產分散式資料庫發展趨勢與難點分散式資料庫
- 分散式 SQL 資料庫與表格最佳化技術分散式SQL資料庫
- 原生分散式資料庫與子資料庫子表中介軟體的區別分散式資料庫
- 分散式資料庫如何控制資料重複 ?分散式資料庫
- 架構設計:分散式服務,庫表拆分模式詳解架構分散式模式
- 資料庫啟動歸檔模式資料庫模式
- 開啟資料庫歸檔模式資料庫模式
- 修改資料庫的歸檔模式資料庫模式
- 更改資料庫為歸檔模式資料庫模式
- ORACLE/MySQL資料庫模式設計~~OracleMySql資料庫模式