基於 Raft 構建彈性伸縮的儲存系統的一些實踐
最近幾年來,越來越多的文章介紹了 Raft 或者 Paxos 這樣的分散式一致性演算法,且主要集中在演算法細節和日誌同步方面的應用。但是呢,這些演算法的潛力並不僅限於此,基於這樣的分散式一致性演算法構建一個完整的可彈性伸縮的高可用的大規模儲存系統,是一個很新的課題,我結合我們這一年多以來在 TiKV 這樣一個大規模分散式資料庫上的實踐,談談其中的一些設計和挑戰。
本次分享的主要內容是如何使用 Raft 來構建一個可以「彈性伸縮」儲存。其實最近這兩年也有很多的文章開始關注類似 Paxos 或者 Raft 這類的分散式一致性演算法,但是主要內容還是在介紹演算法本身和日誌複製,但是對於如何基於這樣的分散式一致性演算法構建一個大規模的儲存系統介紹得並不多,我們目前在以 Raft 為基礎去構建一個大規模的分散式資料庫 TiKV ,在這方面積累了一些第一手的經驗,今天和大家聊聊類似系統的設計,本次分享的內容不會涉及很多 Raft 演算法的細節,大家有個 Paxos 或者 Raft 的概念,知道它們是幹什麼的就好。
先聊聊 Scale
其實一個分散式儲存的核心無非兩點,一個是 Sharding 策略,一個是元資訊儲存,如何在 Sharding 的過程中保持業務的透明及一致性是一個擁有「彈性伸縮」能力的儲存系統的關鍵。如果一個儲存系統,只有靜態的資料 Sharding 策略是很難進行業務透明的彈性擴充套件的,比如各種 MySQL 的靜態路由中介軟體(如 Cobar)或者 Twemproxy 這樣的 Redis 中介軟體等,這些系統都很難無縫地進行 Scale。
Sharding 的幾種策略
在叢集中的每一個物理節點都儲存若干個 Sharding 單元,資料移動和均衡的單位都是 Sharding 單元。策略主要分兩種,一種是 Range 另外一種是 Hash。針對不同型別的系統可以選擇不同的策略,比如 HDFS 的Datanode 的資料分佈就是一個很典型的例子:
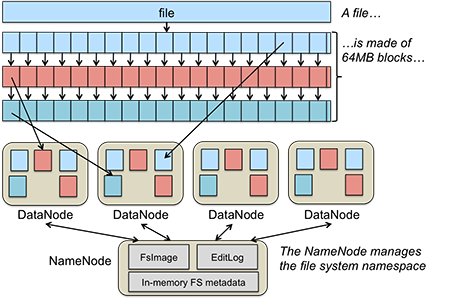
首先是 Range
Range 的想法比較簡單粗暴,首先假設整個資料庫系統的 key 都是可排序的,這點其實還是蠻普遍的,比如 HBase 中 key 是按照位元組序排序,MySQL 可以按照自增 ID 排序,其實對於一些儲存引擎來說,排序其實是天然的,比如 LSM-Tree 或者 BTree 都是天然有序的。Range 的策略就是一段連續的 key 作為一個 Sharding 單元:
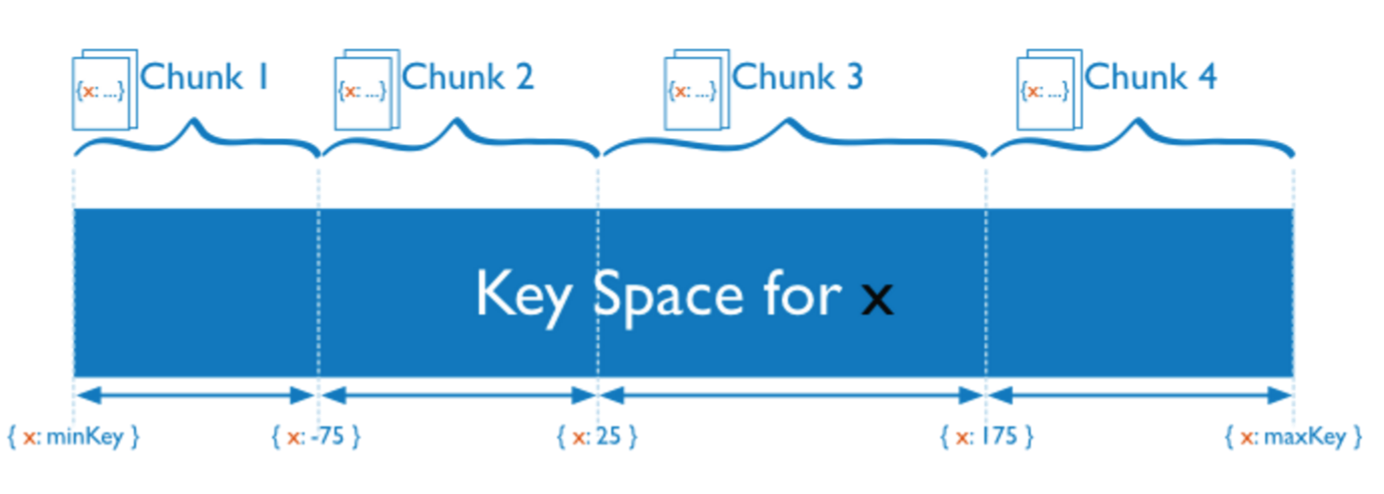
例如上圖中,整個 key 的空間被劃分成 (minKey, maxKey),每一個 Sharding 單元(Chunk)是一段連續的 key。按照 Range 的 Sharding 策略的好處是臨近的資料大概率在一起(例如共同字首),可以很好的支援 range scan 這樣的操作,比如 HBase 的 Region 就是典型的 Range 策略。
但是這種策略對於壓力比較大的順序寫是不太友好的,比如日誌型別的寫入 load,寫入熱點永遠在於最後一個 Region,因為一般來說日誌的 key 基本都和時間戳有關,而時間顯然是單調遞增的。但是對於關係型資料庫來說,經常性的需要表掃描(或者索引掃描),基本上都會選用 Range 的 Sharding 策略。
另外一種策略是 Hash
與 Range 相對的,Sharding 的策略是將 key 經過一個 Hash 函式,用得到的值來決定 Sharding ID,這樣的好處是,每一個 key 的分佈幾乎是隨機的,所以分佈是均勻的分佈,所以對於寫壓力比較大、同時讀基本上是隨機讀的系統來說更加友好,因為寫的壓力可以均勻的分散到叢集中,但是顯然的,對於 range scan 這樣的操作幾乎沒法做。
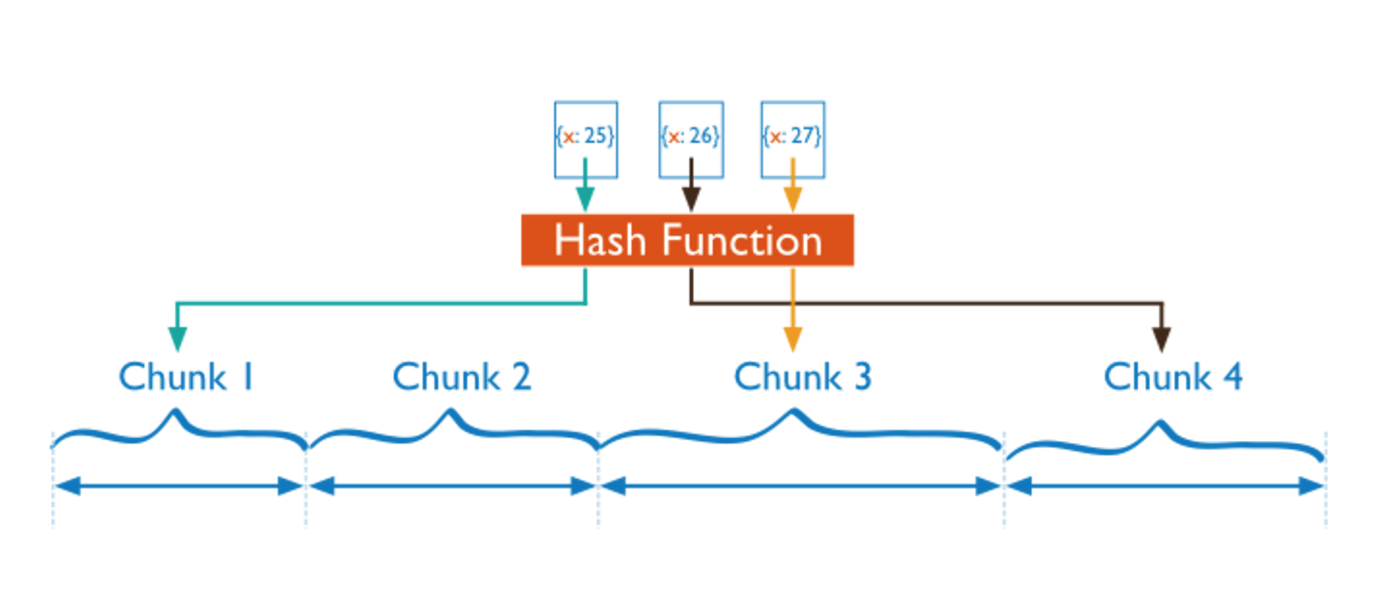
比較典型的 Hash Sharding 策略的系統如:Cassandra 的一致性 Hash,Redis Cluster 和 Codis 的 Pre-sharding 策略,Twemproxy 有采用一致性 Hash 的配置。
當然這兩種策略並不是孤立的,可以靈活組合,比如可以建立多級的 Sharding 策略,最上層用 Hash ,每一個 Hash Sharding 中,資料有序的儲存。
在做動態擴充套件的時候,對於 Range 模型的系統會稍微好做一些,簡單來說是採用分裂,比如原本我有一個 [1, 100) 的 Range Region,現在我要分裂,邏輯上我只需要簡單的將這個 region 選取某個分裂點,如分裂成 [1,50), [50, 100) 即可,然後將這兩個 Region 移動到不同的機器上,負載就可以均攤開。
但是對於 Hash 的方案來說,做一次 re-hash 的代價是挺高的,原因也是顯而易見,比如現在的系統有三個節點,現在我新增一個新的物理節點,此時我的 hash 模的 n 就會從 3 變成 4,對於已有系統的抖動是很大,儘管可以通過 ketama hash 這樣的一致性 hash 演算法儘量的降低對已有系統的抖動,但是很難徹底的避免。
Sharding 與高可用方案結合
選擇好了 sharding 的策略,那剩下的就是和高可用方案結合,不同的複製方案達到的可用性及一致性級別是不同的。很多中介軟體只是簡單的做了 sharding 的策略,但是並沒有規定每個分片上的資料的複製方案,比如 redis 中介軟體 twemproxy 和 codis,MySQL 中介軟體 cobar 等,只是在中間層進行路由,並未假設底層各個儲存節點上的複製方案。但是,在一個大規模儲存系統上,這是一個很重要的事情,由於支援彈性伸縮的系統一般來說整個系統的分片數量,資料分片的具體分佈都是不固定的,系統會根據負載和容量進行自動均衡和擴充套件,人工手動維護主從關係,資料故障恢復等操作在資料量及分片數量巨大的情況下幾乎是不可能完成的任務。選擇一個高度自動化的高可用方案是非常重要的。
在 TiKV 中,我們選擇了按 range 的 sharding 策略,每一個 range 分片我們稱之為 region,因為我們需要對 scan 的支援,而且儲存的資料基本是有關係表結構的,我們希望同一個表的資料儘量的在一起。另外在 TiKV 中每一個 region 採用 Raft 演算法在多個物理節點上保證資料的一致性和高可用。
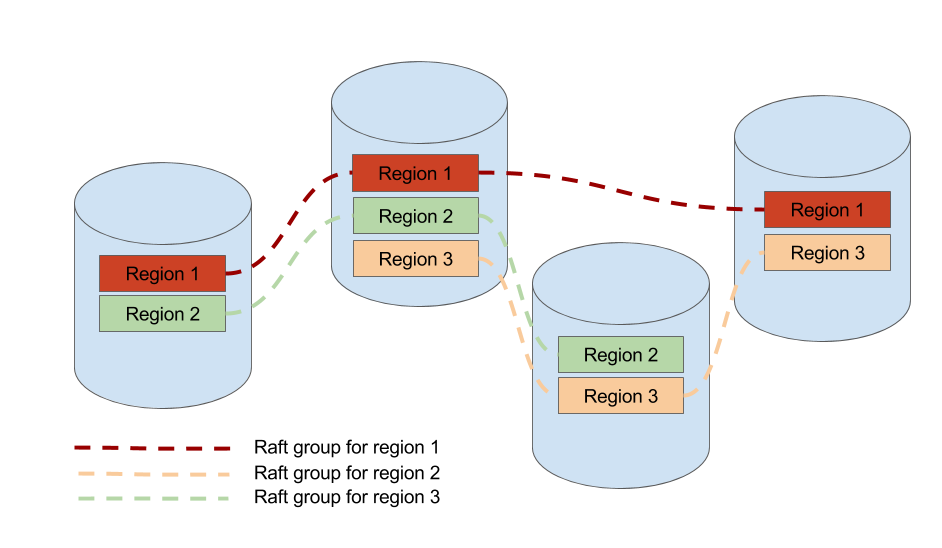
從社群的多個 Raft 實現來看,比如 Etcd / LogCabin / Consul 基本都是單一 raft group 的實現,並不能用於儲存海量的資料,所以他們主要的應用場景是配置管理,很難直接用來儲存大量的資料,畢竟單個 raft group 的參與節點越多,效能越差,但是如果不能橫向的新增物理節點的話,整個系統沒有辦法 scale。
scale 的辦法說來也很簡單,採用多 raft group,這就很自然的和上面所說的 sharding 策略結合起來了,也就是每一個分片作為一個 raft group,這是 TiKV 能夠儲存海量資料的基礎。但是管理動態分裂的多 raft group 的複雜程度比單 group 要複雜得多,目前 TiKV 是我已知的開源專案中實現 multiple raft group 的僅有的兩個專案之一。
正如之前提到過的我們採用的是按照 key range 劃分的 region,當某一個 region 變得過大的時候(目前是 64M),這個 region 就會分裂成兩個新的 region,這裡的分裂會發生在這個 region 所處的所有物理節點上,新產生的 region 會組成新的 raft group。
總結
構建一個健壯的分散式系統是一個很複雜的工程,上面提到了在 TiKV 在實踐中的一些關鍵的設計和思想,希望能拋磚引玉。因為 TiKV 也是一個開源的實現,作為 TiDB 的核心儲存元件,最近也剛釋出了 Beta 版本,程式碼面前沒有祕密,有興趣深入瞭解的同學也可以直接閱讀原始碼和我們的文件,謝謝大家。
Q&A
Q1:如何在這個 region 的各個副本上保證分裂這個操作安全的被執行?
其實這個問題比較簡單,就是將 split region 這個操作作為一個 raft log,走一遍 raft 狀態機,當這個 log 成功 apply 的時候,即可以認為這個操作被安全的複製了(因為 raft 演算法幹得就是這個事情)。確保 split log 操作被 accept 後,對新的 region 在走一次 raft 的選舉流程(也可以沿用原來的 leader,新 region 的其他節點直接發心跳)。split 的過程是加上網路隔離,可能會產生很複雜的 case,比如一個複雜的例子:
a, b 兩個節點,a 是 leader, 發起一個分裂 region 1 [a, d) -> region 1 [a, b) + region 2 [b, d), region 2的 heartbeart 先發到 b,但這時候 region 2 分裂成了 region 2 [b, c) + region 3 [c, d),給 b 傳送的 snapshot 是最新的 region 2 的 snapshot [b, c),region 1的 split log 到了 b,b 的老 region 1 也分裂成了 region 1 [a, b) + region 2 [b,d), 這之後 a 給 b 傳送的最新的 region 2 的 snapshot [b, c) 到了,region 2 被 apply 之後,b 節點的 region 2 必須沒有 [c, d) 區間的資料。
Q2:如何做到透明?
在這方面,raft 做得比 paxos 好,raft 很清晰的提供了 configuration change 的流程,configuration change 流程用於應對 raft gourp 安全的動態新增節點和移除節點,有了這個演算法,在資料庫中 rebalance 的流程其實能很好的總結為:
對一個 region: add replica / transfer leadership / remove local replica
這三個流程都是標準的 raft 的 configuration change 的流程,TiKV 的實現和 raft 的 paper 的實現有點不一樣的是:
config change 的 log 被 apply 後,才會發起 config change 操作,一次一個 group 只能處理一個 config change 操作,避免 disjoint majority,不過這點在 diego 的論文裡提到過。
主要是出於正確性沒問題的情況下,工程實現比較簡單的考慮。 另外這幾個過程要做到業務層透明,也需要客戶端及元資訊管理模組的配合。畢竟當一個 region 的 leader 被轉移走後,客戶端對這個 region 的讀寫請求要發到新的 leader 節點上。
客戶端這裡指的是 TiKV 的 client sdk,下面簡稱 client , client 對資料的讀寫流程是這樣的:首先 client 會本地快取一份資料的路由表,這個路由表形如:
{startKey1, endKey1} -> {Region1, NodeA}
{startKey2, endKey2} -> {Region2, NodeB}
{startKey3, endKey3} -> {Region3, NodeC}
…client 根據使用者訪問的 key,查到這個 key 屬於哪個區間,這個區間是哪個 region,leader 現在在哪個物理節點上,然後客戶端查到後直接將這個請求發到這個具體的 node 上,剛才說過了,此時 leader 可能已經被 transfer 到了其他節點,此時客戶端會收到一個 region stale 的錯誤,客戶端會向元資訊管理服務請求然後更新自己的路由表快取。
這裡可以看到,路由表是一個很重要的模組,它需要儲存所有的 region 分佈的資訊,同時還必須準確,另外這個模組需要高可用。另一方面,剛才提到的資料 rebalance 工作,需要有一個擁有全域性視角的排程器,這個排程器需要知道哪個 node 容量不夠了,哪個 node 的壓力比較大,哪個 node region leader 比較多?以動態的調整 regions 在各個 node 中的分佈,因為每個 node 是幾乎無狀態的,它們無法自主的完成資料遷移工作,需要依靠這個排程器發起資料遷移的操作(raft config change)。
大家應該也注意到了,這個排程器的角色很自然的能和路由表融合成一個模組,在 Google Spanner 的論文中,這個模組的名字叫 Placement Driver, 我們在 TiKV 中沿用了這個名稱,簡稱 pd,pd 主要的工作就是上面提到的兩項:1. 路由表 2. 排程器。 Spanner 的論文中並沒有過多的介紹 pd 的設計,但是設計一個大規模的分散式儲存系統的一個核心思想是一定要假設任何模組都是會 crash 的,模組之間互相持有狀態是一件很危險的事情,因為一旦 crash,standby 要立刻啟動起來,但是這個新例項狀態不一定和之前 crash 的例項一致,這時候就要小心會不會引發問題. 比如一個簡單的 case :因為 pd 的路由表是儲存在 etcd 上的,但是 region 的分裂是由 node 自行決定的 ( node 才能第一時間知道自己的某個 region 大小是不是超過閾值),這個 split 事件如果主動的從 node push 到 pd ,如果 pd 接收到這個事件,但是在持久化到 etcd 前當機,新啟動的 pd 並不知道這個 event 的存在,路由表的資訊就可能錯誤。
我們的做法是將 pd 設計成徹底無狀態的,只有徹底無狀態才能避免各種因為無法持久化狀態引發的問題。
每個 node 會定期的將自己機器上的 region 資訊通過心跳傳送給 pd, pd 通過各個 node 通過心跳傳上來的 region 資訊建立一個全域性的路由表。這樣即使 pd 掛掉,新的 pd 啟動起來後,只需要等待幾個心跳時間,就又可以擁有全域性的路由資訊,另外 etcd 可以作為快取加速這一過程,也就是新的 pd 啟動後,先從 etcd 上拉取一遍路由資訊,然後等待幾個心跳,就可以對外提供服務。
但是這裡有一個問題,細心的朋友也可能注意到了,如果叢集出現區域性分割槽,可能某些 node 的資訊是錯誤的,比如一些 region 在分割槽之後重新發起了選舉和分裂,但是被隔離的另外一批 node 還將老的資訊通過心跳傳遞給 pd,可能對於某個 region 兩個 node 都說自己是 leader 到底該信誰的?
在這裡,TiKV 使用了一個 epoch 的機制,用兩個邏輯時鐘來標記,一個是 raft 的 config change version,另一個是 region version,每次 config change 都會自增 config version,每次 region change(比如split、merge)都會更新 region version. pd 比較的 epoch 的策略是取這兩個的最大值,先比較 region version, 如果 region version 相等則比較 config version 擁有更大 version 的節點,一定擁有更新的資訊。
相關文章
- Serverless:基於個性化服務畫像的彈性伸縮實踐Server
- 基於Ceph物件儲存構建實踐物件
- 儲存系統實現-構建自己的儲存系統(一)
- 基於 Kubernetes 實踐彈性的 CI/CD 系統
- 基於Raft的分散式MySQL Binlog儲存系統開源Raft分散式MySql
- 一個社交App是如何構建高伸縮性的互動式系統APP
- 基於 HBase 構建可伸縮的分散式事務佇列分散式佇列
- 如何基於容器網路流量指標進行彈性伸縮指標
- SpringCloud 應用在 Kubernetes 上的最佳實踐 —— 高可用(彈性伸縮)SpringGCCloud
- 彈性佈局(伸縮佈局)
- 可伸縮性和重/輕量,誰是實用系統的架構主選?架構
- 如何使用 Kubernetes 實現應用程式的彈性伸縮
- 滴滴基於Clickhouse構建新一代日誌儲存系統
- 網站架構的伸縮性設計網站架構
- 彈性伸縮:高可用架構利器(架構+演算法+思維)架構演算法
- Knative Autoscaler 自定義彈性伸縮
- EMQX Operator 如何快速建立彈性伸縮的 MQTT 叢集MQQT
- CSS-彈性佈局3-伸縮屬性CSS
- Fluid 給資料彈性一雙隱形的翅膀 -- 自定義彈性伸縮UI
- js滑鼠懸浮水平彈性伸縮的導航選單JS
- 實踐:GNU構建系統
- 彈性伸縮服務實戰:我是如何節省80%的機器成本的
- 實戰:構建可伸縮Hadoop叢集的方法步驟Hadoop
- 在騰訊雲容器服務 TKE 中利用 HPA 實現業務的彈性伸縮
- 構建高效且可伸縮的結果快取快取
- 基於 react, redux 最佳實踐構建的 2048ReactRedux
- 雲端乾貨|降本必備—彈性伸縮的基本原理
- 基於開源軟體構建儲存解決方案的思考
- Grafana監控系統的構建與實踐Grafana
- 雲原生的彈性 AI 訓練系列之一:基於 AllReduce 的彈性分散式訓練實踐AI分散式
- 分散式儲存系統的最佳實踐:系統發展路徑分散式
- 基於 Prometheus 的監控系統實踐Prometheus
- 分散式系統中的資料儲存方案實踐分散式
- Node.js的可伸縮性Node.js
- 大型系統儲存層遷移實踐
- eBay 基於 Apache Kyuubi 構建統一 Serverless Spark 閘道器的實踐ApacheServerSpark
- Knativa 基於流量的灰度釋出和自動彈性實踐
- 大型網站的可伸縮性架構如何設計?網站架構