記一次golang的gzip優化
背景
近期使用 Golang 官方的"compress/gzip"包對資料壓縮返回給 App,此場景特性:資料不固定、高併發。在實際過程中發現一個簡單邏輯的 API 服務,幾百 QPS 的情況下 CPU 卻很高達到幾個核負載。
問題追蹤
通過 golang 自帶工具 pprof 抓圖分析 CPU,如下圖 (由於有業務程式碼,所以部分資訊遮蓋了):
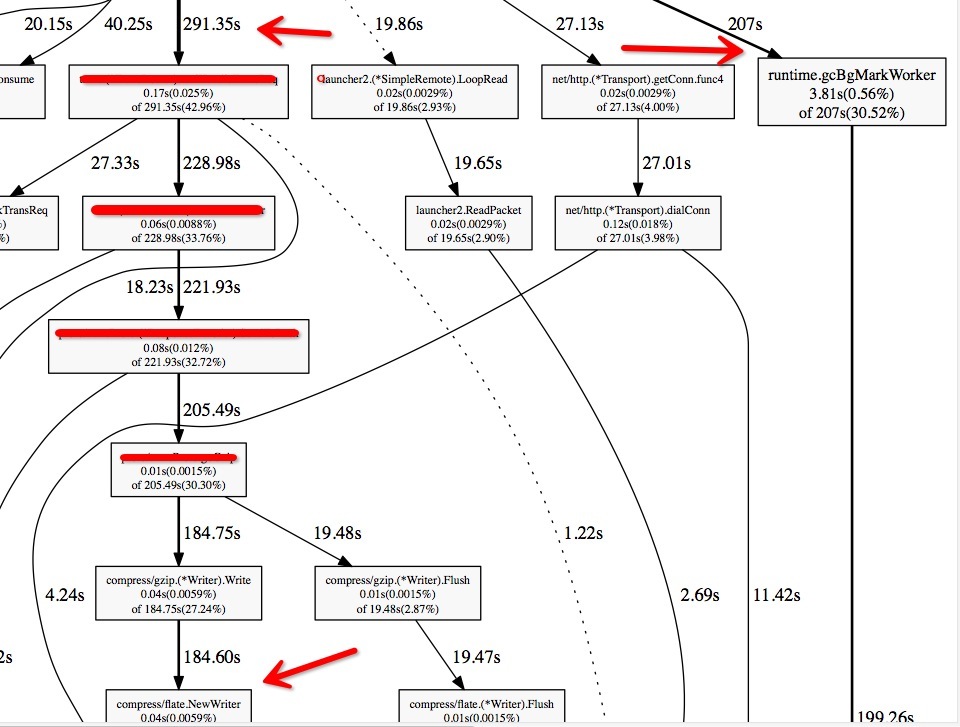
通過此圖可以看出,整個工程裡有兩個 CPU 消耗大頭:1) GC 高 2) 大部分 CPU 耗在 Gzip 上.看方法屬於 New 操作,再加上 GC 高,很容易往一個方向上去想,就是物件建立過多造成。
於是 google 搜了一些資料發現有人嘗試優化 gzip,地址:https://github.com/klauspost/compress/tree/master/gzip20~30%,但是並不相容原生 Gzip,似乎並不是一個很通用的方案。,但經過測試雖然速度提升
分析原始碼
1.首先看下 demo 裡原生的使用方式
demo 地址:https://github.com/thinkboy/gzip-benchmark
func OldGzip(wr http.ResponseWriter, r *http.Request) { buf := new(bytes.Buffer) w := gzip.NewWriter(buf)
leng, err := w.Write(originBuff) if err != nil || leng == 0 { return } err = w.Flush() if err != nil { return } err = w.Close() if err != nil { return } b := buf.Bytes() wr.Write(b)
// 檢視是否相容 go 官方 gzip /gr, _ := gzip.NewReader(buf) defer gr.Close() rBuf, err := ioutil.ReadAll(gr) if err != nil { panic(err) } fmt.Println(string(rBuf))/ }
2.其次看下官方 gzip 的實現,如下圖:
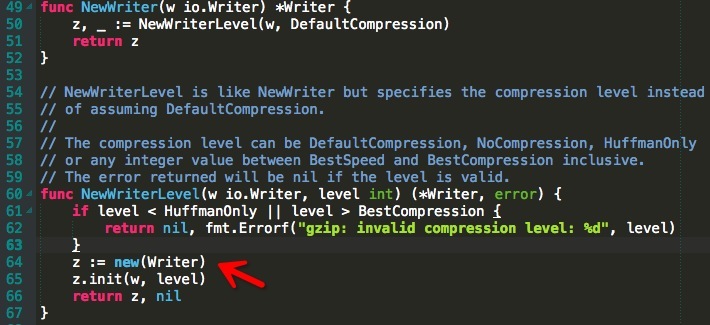
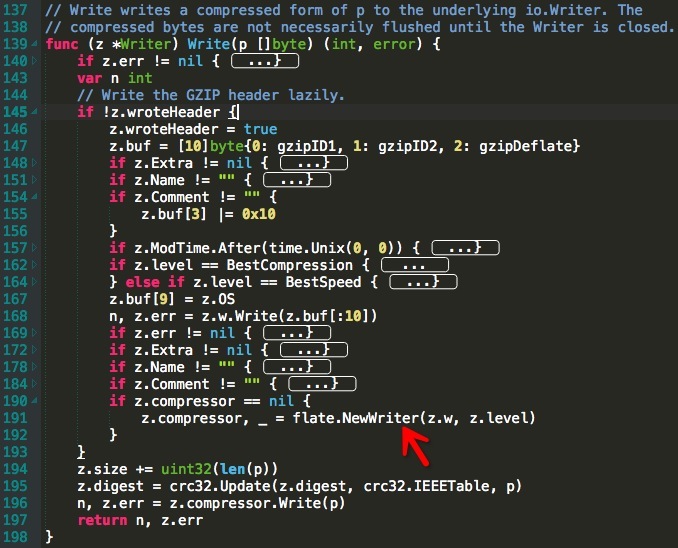
跟蹤程式碼尋找幾處與 Pprof 圖相關的有 New 操作的地方,首先第一張圖每次都會 New 一個 Writer,然後在第二張圖裡的 Write 的時候,每次又都會為新建立的 Writer 分配一個壓縮器。對於物件的反覆建立有一個通用的思路,使用物件池。
3.嘗試使用物件池
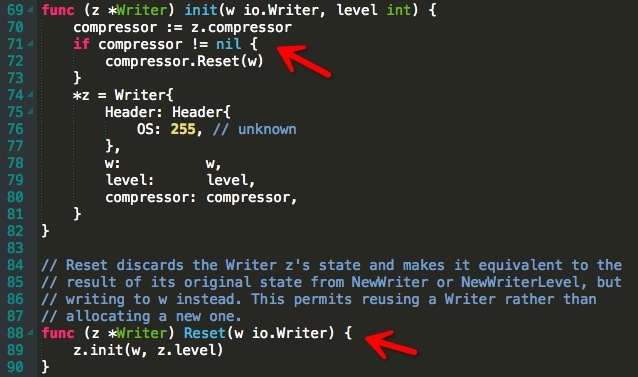
通過上圖我們發現 gzip 的 Writer 有個 Reset() 方法,該方法呼叫的 init() 裡的實現是如果已經存在壓縮器,就複用並且 Reset()。也就是說其實官方已經提供了一種方式讓使用者不再反覆 New Writer。然後我們可以這樣改造下實現程式碼:
func MyGzip(wr http.ResponseWriter, r *http.Request) { buf := spBuffer.Get().(*bytes.Buffer) w := spWriter.Get().(*gzip.Writer) w.Reset(buf) defer func() { // 歸還 buff buf.Reset() spBuffer.Put(buf) // 歸還 Writer spWriter.Put(w) }()
leng, err := w.Write(originBuff) if err != nil || leng == 0 { return } err = w.Flush() if err != nil { return } err = w.Close() if err != nil { return } b := buf.Bytes() wr.Write(b)
// 檢視是否相容 go 官方 gzip /gr, _ := gzip.NewReader(buf) defer gr.Close() rBuf, err := ioutil.ReadAll(gr) if err != nil { panic(err) } fmt.Println(string(rBuf))/ }
我們給壓縮過程中用到的 Buffer 以及 Writer 定義物件池 spBuffer、spWriter,然後每次 api 請求都從物件池裡去取,然後 Reset,從而繞過 New 操作。
這裡容易產生一個疑問:物件池其實本身就是一個 “全域性大鎖”,高併發場景下這把全域性大鎖影響有多大?(其實有一種深度優化的方式就是拆鎖,比如依據某個 ID 進行取餘取不同的物件池。這裡就拿一把大鎖來實驗).
下面看一下此次改造後的壓測結果 (QPS: 3000):
不使用物件池 (CPU 使用 28 個核左右):
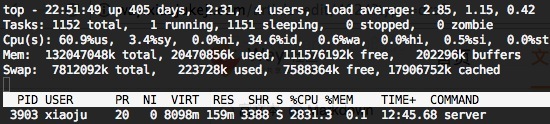
使用物件池 (CPU 使用 22 個核左右):
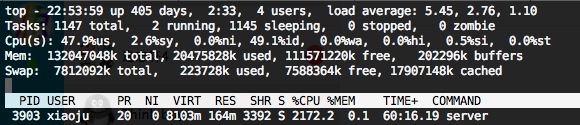
通過 CPU 使用來看有消耗降低 22% 左右,由於 QPS 並不是很高,所以這裡物件池的 “全域性大鎖” 的影響暫且可以忽略。
結論
針對官方 Gzip 的壓縮可以使用物件池來改善。
klauspost 所提供的方案也列舉在 demo 中了,雖然屬於自己改了壓縮演算法不相容 Golang 官方包,但親測對壓縮速度也提升了很大百分比。使用該庫 + 物件池的方式可能會達到更顯著優化效果。
demo 地址:https://github.com/thinkboy/gzip-benchmark

- 加微信實戰群請加微信(註明:實戰群):gocnio
相關文章
- 記一次 Golang 資料庫查詢元件的優化。Golang資料庫元件優化
- 記一次UITableView優化UIView優化
- 記一次sql優化SQL優化
- Vue首頁效能優化之gzipVue優化
- 記一次Node專案的優化優化
- 記MySQL一次關於In的優化MySql優化
- 記一次前端效能優化的案例前端優化
- ? 記一次前端效能優化前端優化
- 記一次分頁優化優化
- 記錄一次打包優化優化
- 一次sql優化小記SQL優化
- 記一次提升18倍的效能優化優化
- 記一次 Webpack 專案優化Web優化
- 記一次Elasticsearch優化總結Elasticsearch優化
- 記一次效能優化經歷優化
- Golang優化-優雅退出Golang優化
- 記一次真實的webpack優化經歷Web優化
- 記一次優化ansible inventory的小例子優化
- 記一次卓有成效的SQL優化SQL優化
- 「簡明效能優化」雙端開啟Gzip優化
- 記一次 spinor flash 讀速度優化優化
- 記一次公司產品「負」優化優化
- 漫漫優化路,總會錯幾步(記一次介面優化)優化
- 「簡明效能優化」雙端開啟Gzip指南優化
- VuePress 部落格優化之開啟 Gzip 壓縮Vue優化
- 記一次 VUE 專案優化實踐Vue優化
- 記一次Prometheus代理效能優化問題Prometheus優化
- NOT IN 一次優化優化
- 一次優化優化
- Golang net/http 效能優化GolangHTTP優化
- Golang效能分析與優化Golang優化
- 記一次線上商城系統高併發的優化優化
- 記一次使用策略模式優化程式碼的經歷模式優化
- 記,一次線上商城系統高併發的優化!優化
- 記錄一次SQL函式和優化的問題SQL函式優化
- 記一次資料庫的分析和優化建議資料庫優化
- 一次成功的優化案例優化
- 記一次bem命名規範使用優化方案優化