Google TPU讓“脈動陣列”(systolic array)這項“古老”的技術又回到大家的視野當中。短短几天,各種爭論不絕於耳。其中有一個評論我比較喜歡,“這次google tpu讓像我這樣的年輕後輩又有機會能重新認識systolic,也很有意思”。是啊,還是讓我們靜下心來,重新認識一下“脈動陣列”這位老朋友吧。
Why systolic architectures?
要真正理解脈動陣列,首先要問的就是發明者的初衷。這正好也是1982年H. T. Kung論文的題目[1]。對於為什麼要設計這樣的架構,作者給出了三個理由:
1. Simple and regular design:可以說,簡單和規則是脈動陣列的一個重要原則。而這樣的設計主要是從“成本”的角度來考慮問題的。“Cost-effectiveness has always been a chief concern in designing special-purpose systems; their cost must be low enough to justify their limited applicability.”換言之,由於一個專用系統往往是功能有限的,因此它的成本必須足夠低才能克服這一劣勢。這也是設計專用處理器的一個基本考慮。更進一步,作者把成本分成兩部分:nonrecurring cost(設計 design) 和recurring cost(器件 parts)。器件成本對於專用設計和通用設計基本是一樣的,因此決定性的是設計成本。而設計一個合理的架構(appropriate architectures)是降低設計成本的一個重要方法。Google的TPU可以說很好的證明了這一點。通過採用脈動陣列這個簡單而規則的硬體架構,Google在很短的時間內完成了晶片的設計和實現。從另一個角度來說,硬體設計相對簡單,儘量發揮軟體的能力,也是非常適合Google的一種策略。
2. Concurrency and communication:這一點主要強調並行性和通訊的重要。由於這方面大家應該比較熟悉,這裡不再贅述。
3. Balancing computation with I/O:平衡運算和I/O,應該說是脈動陣列最重要的設計目標。對於這一點,作者用下面這幅圖給出了很好的說明。

首先,圖中上半部分是傳統的計算系統的模型。一個處理單元(PE)從儲存器(memory)讀取資料,進行處理,然後再寫回到儲存器。這個系統的最大問題是:資料存取的速度往往大大低於資料處理的速度。因此,整個系統的處理能力(MOPS,每秒完成的操作)很大程度受限於訪存的能力。這個問題也是多年來計算機體系結構研究的重要課題之一,可以說是推動處理器和儲存器設計的一大動力。而脈動架構用了一個很簡單的方法:讓資料儘量在處理單元中多流動一會兒。
正如上圖的下半部分所描述的,第一個資料首先進入第一個PE,經過處理以後被傳遞到下一個PE,同時第二個資料進入第一個PE。以此類推,當第一個資料到達最後一個PE,它已經被處理了多次。所以,脈動架構實際上是多次重用了輸入資料。因此,它可以在消耗較小的memory頻寬的情況下實現較高的運算吞吐率。當然,脈動架構還有其它一些好處,比如模組化的設計容易擴充套件,簡單和規則的資料和控制流程,使用簡單並且均勻的單元(cell),避免了全域性廣播和扇入(fan-in),以及快速的響應時間(可能?)等等。
總結起來,脈動架構有幾個特徵:1. 由多個同構的PE構成,可以是一維或二維,序列、陣列或樹的結構(現在我們看到的更多的是陣列形式);2. PE功能相對簡單,系統通過實現大量PE並行來提高運算的效率;3. PE只能向相鄰的PE傳送資料(在一些二維結構中,也可能有對角線方向的資料通道)。資料採用流水線的方式向“下游”流動,直到流出最後的PE。
到這裡不難看出,脈動架構是一種很特殊的設計,結構簡單,實現成本低。但它靈活性較差,只適合特定運算。而作者認為,卷積運算是展示脈動架構特點的理想應用,因此在文章中用了很大篇幅介紹了脈動架構實現卷積運算的方法。首先看看作者對卷積運算的定義:

下面是作者給出的一種方法(broadcast inputs, move results, weights stay):

在這個例子中,X值廣播到各個運算單元,W值預先儲存在PE中並保持不動,而部分結果Y採用脈動的方式在PE陣列間向右傳遞(初始值為零)。不難看出,經過三個時刻,最右邊的PE的輸出就是X和W兩個序列的卷積運算的第一個結果,這之後就會不斷輸出Y值。文中還給出了其它幾種實現卷積的方式,如broadcast inputs, move weights, results stay;fan-in results, move inputs, weights stay。這幾種都算作“(Semi-) systolic convolution arrays with global data communication”。另外還有一大類是“(Pure-) systolic convolution arrays without global data communication”,包括results stay, inputs and weights move in opposite directions;results stay, inputs and weights move in the same direction but at different speeds;weights stay, inputs and results move in opposite direction;weights stay, inputs and results move in the same direction but at different speeds。建議大家好好看看,還是挺有啟發的。
那麼二維的脈動陣列如何做矩陣相乘呢?下面這個例子比較清楚。A和B都是3x3矩陣,T表示時刻。

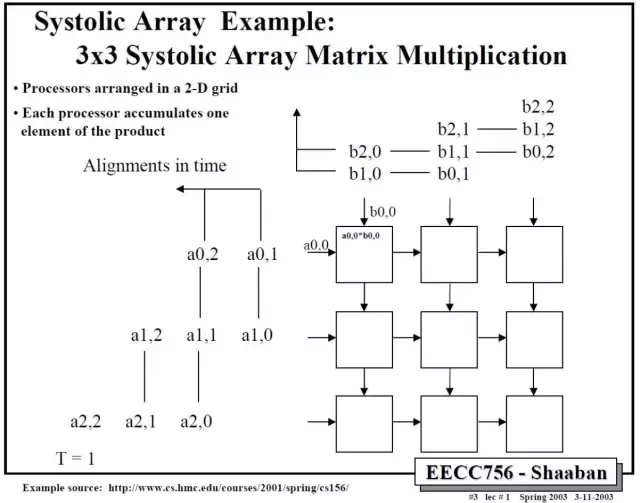


依此類推,中間省略幾步,可以得到最後結果。
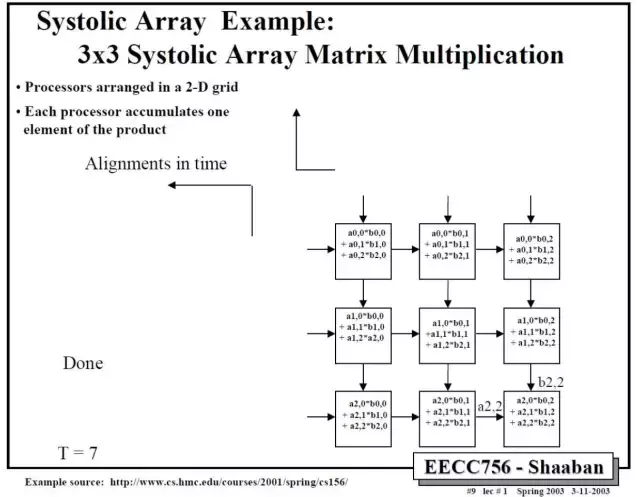
這裡值得注意的是,要實現正確的矩陣運算,資料進入脈動陣列需要調整好形式,並且按照一定的順序。這就需要對原始的矩陣進行一些reformat,這也增加了額外的操作。在後面對Google TPU的討論中,我們可以更清楚的看到這一問題。
除了卷積運算,作者在文章中還說明的脈動架構適合的其它運算,主要包括訊號和影象處理(signal and image processing),矩陣算術(matrix arithmetic)和一些非數值型應用(non-numeric application)。不過,由於脈動架構的靈活性較差,加之當時半導體技術的限制,它在被髮明之後並沒有得到廣泛的應用。
時至今日,在我們設計Deep Learning處理器的時候,面對的一個主要矛盾仍然是I/O和處理不平衡的問題。這種不平衡既體現在速度上,也體現在功耗上。而一種減少I/O操作的思路 “…discuss how dataflows can increase data reuse from low cost memories in the memory hierarchy”[2],和脈動架構的方法是類似的。而另一方面,深度神經網路中大量使用了卷積運算和矩陣運算,這正好也是是脈動架構的優勢。所以,在很多DL處理器中我們都可以看到脈動架構的影子(雖然有或多或少的變化和改進)。而Google TPU的設計更是讓脈動陣列成了大家關注的焦點。
Google TPU Implementation
下面我們看看Google在TPU設計中是怎麼實現脈動陣列的。作為一個強迫症患者,我把Google TPU的框圖重新畫了一下,又結合他們的專利細化了一下Matrix Multiply Unit的結構以及其中的cell的結構,算是小小的福利吧。 當然,很多細節也是我的猜想,可能不準確,如果大家發現什麼問題也請指教。

首先,從整體來看,整個TPU的核心就是Matrix Multiply Unit,它正是一個256X256的脈動陣列。而整個晶片的其它部分,都是圍繞這個脈動陣列來運轉的,目的就是能夠讓脈動陣列儘量高效的運作(不過從TPU論文來看,實際效率並不算很高)。
這裡有兩個值得注意的地方。第一,是確實實現了相對較低的I/O頻寬30GiB/s;第二是64K個MAC(可能是目前公開文獻中看到的最大的MAC數量)。這兩點很大程度上歸功於脈動陣列的特點:平衡I/O和運算,以及相對簡單的PE(cell)。當然,還有另外一個原因,TPU採用8bit定點的MAC(可以支援16bit運算)。這也是Google做出的最重要的設計選擇之一。還是那句話,專用處理器的設計基於對目標應用的理解。在這一點上,估計沒有人比Google更瞭解data center的DNN inference需求了。也正因如此,Google的TPU才會引起這麼多關注。

根據Google的專利,matrix單元就是一個典型的脈動陣列。weight由上向下流動,activation資料從左向右流動。在最下方有一些累加單元,主要用於weight矩陣或者activation矩陣超出matrix單元範圍的時候儲存部分結果。控制單元實際上就是把指令翻譯成控制訊號,控制weight和activation如何傳入脈動陣列以及如何在脈動陣列中進行處理和流動。由於指令比較簡單,相應的控制也是比較簡單的。
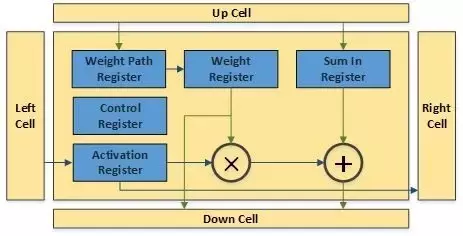
脈動陣列中的一個cell也非常簡單。幾組暫存器分別儲存weight,activation和來自上方cell的部分和。weight從上向下傳播,可以在weight path register中儲存,保持不動或者傳輸給weight register進行運算。weight register可以把資料發到乘法器進行處理,也可以直接傳遞給下方的cell;同樣activation register也可以把資料發到乘法器進行處理,或者直接傳遞給右側的cell。乘法器的輸出和Sum in register的數值求和並傳遞給下方的cell。所有運算和傳遞都由控制暫存器控制(通過指令決定)。That’s it。
那麼,在這樣一個大規模的脈動陣列中怎麼實現卷積操作呢?在Google的專利中有這樣一個例子,可以看出一些端倪。如下圖所示,activation輸入被轉換成一定的向量形式,作為脈動陣列的行輸入。而3x3卷積核(Kernel)經過旋轉,變成9個矩陣分別輸入到脈動陣列的9個列。第一列計算的是卷積核和activation矩陣左上角的9個資料的卷積,得到輸出矩陣的左上角的第一個資料,依此類推。

不難看出,為了要體現脈動陣列的運算效率(“keep the matrix unit busy”),需要對weight和activation進行很多形式上的轉換。從TPU論文來看,似乎這項工作是由software stack中的“User Space driver”來完成,“It sets up and controls TPU execution, reformats data into TPU order, translates API calls into TPU instructions, and turns them into an application binary.”這項工作的運算量也不小,具體是怎麼優化的就不得而知了。
差不多就這些內容了,歡迎大家和我討論。
T.S.
Google TPU論文公開以來,引起各種爭論。相信隨著時間推移,它帶來的影響還會不斷顯現。我甚至還看到這樣的觀點,“ASIC systolic arrays are going to flood the market with likely Chinese government subsidized hardware manufacturers cranking this stuff out. It just takes someone to come up with an open source reference design. Just like what happened in the Bitcoin world. This stuff is ancient design stuff, and I’m sure someone has the old iWarp designs and compilers in their basement somewhere! ”
(“ASIC脈動陣列架構只要有人搞出個開源的參考設計,就會席捲整個市場。就像當年比特幣挖礦機一樣。這個東西有年頭了,而且我非常確定有些人在硬碟的某個角落還保留著當年的iWarp設計和編譯器!”)
即使拋開這些,對我們來說,有機會結合Google的TPU深入瞭解一下脈動架構,確實是一件頗為有趣的事情。
參考:1. H. T. Kung, "Why systolic architectures?", IEEE Computer, Vol. 15, N°1, pp 37-46, 1982.2. Vivienne Sze, Yu-Hsin Chen, Tien-Ju Yang, Joel Emer, "Efficient Processing of Deep Neural Networks: A Tutorial and Survey",arxiv.org/pdf/1703.09039.pdf3. Norman P. Jouppi, et al."In-Datacenter Performance Analysis of a Tensor Processing Unit",accepted by ISCA 2017