Adam Gibson 是美國電腦科學家,人工智慧公司 Skymind、開源框架 Deeplearning4j 的聯合創始人。Deeplearning4j(簡稱DL4J)是為 Java 和 Scala 編寫的首個商業級開源分散式深度學習庫。DL4J與 Hadoop 和 Spark 整合,為商業環境(而非研究工具目的)所設計。Skymind 是 DL4J 的商業支援機構。

分散式深度學習——綜述

神經網路訓練基礎
向量化/不同型別資料
引數——一個完整的神經網路包括一張圖和引數向量
Minibatchers——神經網路資料需要大量的 ram(隨機訪問記憶體)。需要做 minibatch 訓練。

向量化
影像
文字
音訊
視訊
CSV 檔案/有結構的
網站日誌
引數神經網路結構
計算圖——一個神經網路只是 ndarray/tensor 的一個 dag 圖。
一個神經網路的引數可做成一張圖中代表所有連線/權重的一個向量。

Minibatches
資料被區分入子樣本
適合於 GPU
訓練更快速
應該是儘可能均勻的代表性樣本(每一個標籤)

分散式訓練
多臺計算機
多重 GPUs
多重 GPUs 和多臺計算機
不同型別的並行訓練
多種不同的演算法

多臺計算機
分散式系統——在叢集上連線/協調計算機
Hadoop
HPC(MPI 和同類)
Client/server 體系架構

多重 GPUs
單個 box
可能是多個主執行緒
RDMA 互相連線
NVLink 技術
典型應用於一個資料中心架
將問題打碎
在 GPUs 間共享資料

多重 GPUs 和多臺計算機
在叢集上協調問題
使用 GPUs 做計算
可通過 MPI 或者 hadoop 完成(主執行緒協調)
引數伺服器——在主伺服器上同步引數,和處理 GPU 互相連線事件一樣。

型別的並行
資料並行
模型並行
二者兼有?

多種不同的演算法
全域性歸納
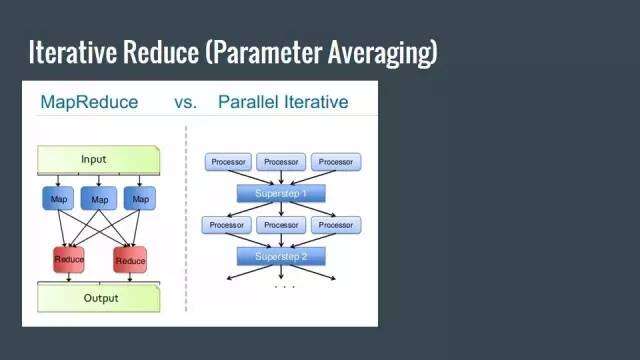
Iterative Reduce
純模型並行
引數平均是關鍵

核心理念
將問題區分進組塊
可以使神經網路
也可以是資料
儘可能使用多的 CUDA 或 CPU 核心

引數平均化如何工作的?
在叢集上覆制模型
使用同樣的模型在不同的資料部分上進行訓練
超引數應該更具侵略性(更高的學習效率)

全域性歸納
PDF 檢視網址:http://cilvr.cs.nyu.edu/diglib/lsml/lecture04-allreduce.pdf
Iterative Reduce(引數平均)
自然梯度演算法(ICLR 2015)
論文檢視地址:https://arxiv.org/pdf/1410.7455v8.pdf——同步每一個 K 資料點

調整分散式訓練
以正則化的方式平均每一步
需要更多侵略性超引數
不需要總是非常快速——因為你擁有的資料點的原因
分散式系統應用到這裡:傳送程式碼到資料,沒其他辦法
為最大效能降低通訊開銷
已經有很多的實驗了

©本文由機器之心編譯