
科技公司的資料科學、關聯性分析以及機器學習等方面的活動大多圍繞著”大資料”,這些大型資料集包含文件、 使用者、 檔案、 查詢、 歌曲、 圖片等資訊,規模數以千計,數十萬、 數百萬、 甚至數十億。過去十年裡,處理這型別資料集的基礎設施、 工具和演算法發展得非常迅速,並且得到了不斷改善。大多數資料科學家和機器學習從業人員就是在這樣的情況下積累了經驗,逐漸習慣於那些用著順手的演算法,而且在那些常見的需要權衡的問題上面擁有良好的直覺(經常需要權衡的問題包括:偏差和方差,靈活性和穩定性,手工特性提取和特徵學習等等)。但小的資料集仍然時不時的出現,而且伴隨的問題往往難以處理,需要一組不同的演算法和不同的技能。小資料集出現在以下幾種情況:
- 企業解決方案: 當您嘗試為一個人員數量相對有限的企業提供解決方案,而不是為成千上萬的使用者提供單一的解決方案。
- 時間序列: 時間供不應求!尤其是和使用者、查詢指令、會話、檔案等相比較。這顯然取決於時間單位或取樣率,但是想每次都能有效地增加取樣率沒那麼容易,比如你得到的標定資料是日期的話,那麼你每天只有一個資料點。
- 關於以下樣本的聚類模型:州市、國家、運動隊或任何總體本身是有限的情況(或者取樣真的很貴)。【備註:比如對美國50個州做聚類】
- 多變數 A/B 測試: 實驗方法或者它們的組合會成為資料點。如果你正在考慮3個維度,每個維度設定4個配置項,那麼將擁有12個點。【備註:比如在網頁測試中,選擇字型顏色、字型大小、字型型別三個維度,然後有四種顏色、四個字號、四個字型】
- 任何罕見現象的模型,例如地震、洪水。
二、小資料問題
小資料問題很多,但主要圍繞高方差:
- 很難避免過度擬合
- 你不只過度擬合訓練資料,有時還過度擬合驗證資料。
- 離群值(異常點)變得更危險。
- 通常,噪聲是個現實問題,存在於目標變數中或在一些特徵中。
三、如何處理以下情況
1-僱一個統計學家
我不是在開玩笑!統計學家是原始的資料科學家。當資料更難獲取時統計學誕生了,因而統計學家非常清楚如何處理小樣本問題。統計檢驗、引數模型、自舉法(Bootstrapping,一種重複抽樣技術),和其他有用的數學工具屬於經典統計的範疇,而不是現代機器學習。如果沒有好的專業統計員,您可以僱一個海洋生物學家、動物學家、心理學家或任何一個接受過小樣本處理訓練的人。當然,他們的專業履歷越接近您的領域越好。如果您不想僱一個全職統計員,那麼可以請臨時顧問。但僱一個科班出身的統計學家可能是非常好的投資。
2-堅持簡單模型
更確切地說: 堅持一組有限的假設。預測建模可以看成一個搜尋問題。從初始的一批可能模型中,選出那個最適合我們資料的模型。在某種程度上,每一個我們用來擬合的點會投票,給不傾向於產生這個點的模型投反對票,給傾向於產生這個點的模型投贊成票。當你有一大堆資料時,你能有效地在一大堆模型/假設中搜尋,最終找到適合的那個。當你一開始沒有那麼多的資料點時,你需要從一套相當小的可能的假設開始 (例如,含有 3個非零權重的線性模型,深度小於4的決策樹模型,含有十個等間隔容器的直方圖)。這意味著你排除複雜的設想,比如說那些非線性或特徵之間相互作用的問題。這也意味著,你不能用太多自由度 (太多的權重或引數)擬合模型。適當時,請使用強假設 (例如,非負權重,沒有互動作用的特徵,特定分佈等等) 來縮小可能的假設的範圍。
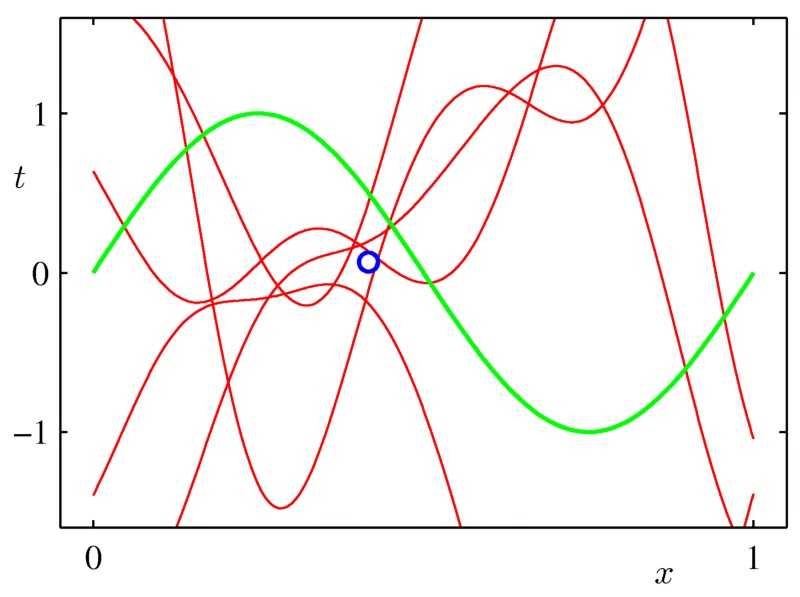

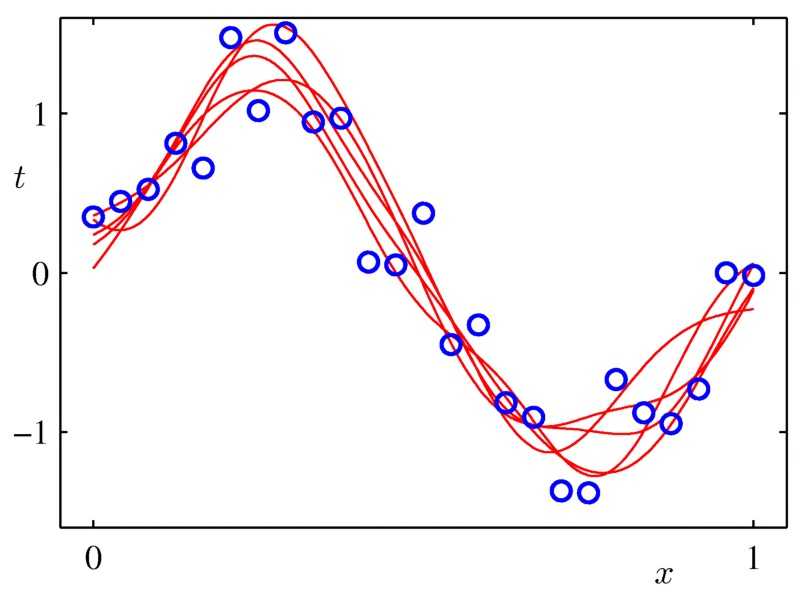
3-儘可能使用更多的資料
您想構建一個個性化的垃圾郵件過濾器嗎?嘗試構建在一個通用模型,併為所有使用者訓練這個模型。你正在為某一個國家的GDP建模嗎?嘗試用你的模型去擬合所有能得到資料的國家,或許可以用重要性抽樣來強調你感興趣的國家。你試圖預測特定的火山爆發嗎?……你應該知道如何做了。
4-做試驗要剋制
不要過分使用驗證集。如果你嘗試過許多不同的技術,並使用一個保留資料集來對比它們,那麼你應該清楚這些結果的統計效力如何,而且要意識到對於樣本以外的資料它可能不是一個好的模型。
5-清洗您的資料
處理小資料集時,噪聲和異常點都特別煩人。為了得到更好的模型,清洗您的資料可能是至關重要的。或者您可以使用魯棒性更好的模型,尤其針對異常點。(例如分位數迴歸)
6-進行特徵選擇
我不是顯式特徵選擇的超級粉絲。我通常選擇用正則化和模型平均 (下面會展開講述)來防止過度擬合。但是,如果資料真的很少,有時顯式特徵選擇至關重要。可以的話,最好藉助某一領域的專業知識來做特徵選擇或刪減,因為窮舉法 (例如所有子集或貪婪前向選擇) 一樣容易造成過度擬合。
7-使用正則化
對於防止模型過擬合,且在不降低模型中引數實際數目的前提下減少有效自由度,正則化幾乎是神奇的解決辦法。L1正則化用較少的非零引數構建模型,有效地執行隱式特徵選擇。而 L2 正則化用更保守 (接近零) 的引數,相當於有效的得到了強零中心的先驗引數 (貝葉斯理論)。通常,L2 擁有比L1更好的預測精度。【備註:L2正則化的效果使權重衰減,人們普遍認為:更小的權值從某種意義上說,表示網路的複雜度更低,對資料的擬合剛剛好,這個法則也叫做奧卡姆剃刀。】
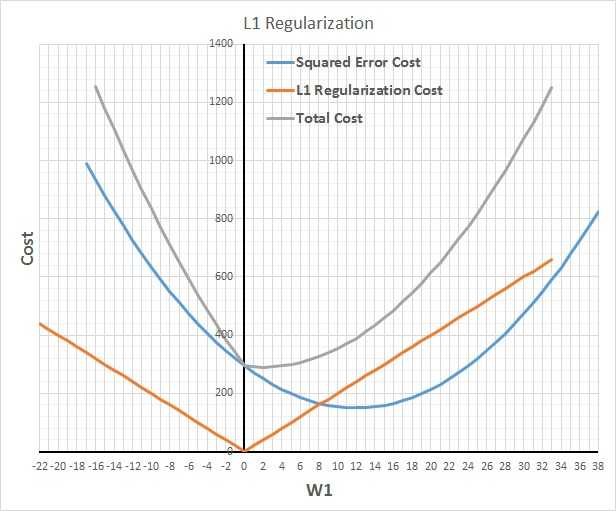
8 使用模型平均
模型平均擁有類似正則化的效果,它減少方差,提高泛化,但它是一個通用的技術,可以在任何型別的模型上甚至在異構模型的集合上使用。缺點是,為了做模型平均,結果要處理一堆模型,模型的評估變得很慢。bagging和貝葉斯模型平均是兩個好用的模型平均方法。
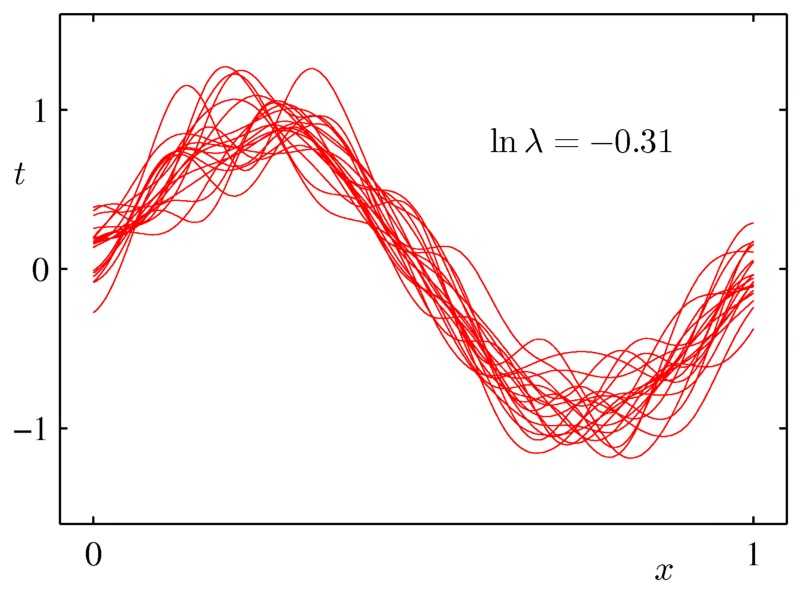
9-嘗試貝葉斯建模和模型平均
這個依然不是我喜歡的技術,但貝葉斯推理可能適合於處理較小的資料集,尤其是當你能夠使用專業知識構造好的先驗引數時。
10-喜歡用置信區間
通常,除了構建一個預測模型之外,估計這個模型的置信是個好主意。對於迴歸分析,它通常是一個以點估計值為中心的取值範圍,真實值以95%的置信水平落在這個區間裡。如果是分類模型的話,那麼涉及的將是分類的概率。這種估計對於小資料集更加重要,因為很有可能模型的某些特徵相比其它特徵沒有更好的表達出來。如上所述的模型平均允許我們很容易得到在迴歸、 分類和密度估計中做置信的一般方法。當評估您的模型時它也很有用。使用置信區間評估模型效能將助於你避免得出很多錯誤的結論。

四、總結
上面講的有點多,但他們都圍繞著三個主題:約束建模,平滑和量化不確定性。這篇文章中所使用的圖片來自Christopher Bishop的書《模式識別和機器學習》
以上內容翻譯自What to do with “small” data?
附錄:翻譯筆記:
一、用語
1、every now and then和now and then 有什麼區別?
根據<<美國傳統詞典[雙解]>>的解釋:
1。every now and then 或 every now and again:
(1)From time to time; occasionally.
不時地,時常地;偶爾地
(2) every once in a while
From time to time; occasionally.
不時地;偶爾地
2。now and then 或 now and again
(1)Occasionally. 偶爾地
這二個片語基本上是相等的,也可以認為,now and then。事件發生的頻率要低一些。every now and then 。事件發生的頻率要稍高一些。
2、Document和file
document是文件,file是檔案。file涵蓋的範圍更大,影像、音訊、視訊之類都可以叫file,而document主要指文字文件。
3、trade-off
權衡,文中提到幾個變數對,偏方和方差,靈活性和穩定性,手工特徵提取和自動化特徵提取。需要在兩方面之間取得平衡,不能只偏向一方。
4、country, nation, state
三者都可譯為“國家”,但含義不同。
country 指國家時,側重疆土或人口, 又作“鄉下”講。
如: China is a socialist country. 中國是一個社會主義國家。
nation指國家時,側重民族。
如: The whole nation is /are rejoicing. 舉國歡騰。
state 指國家時,側重政體、政府,也可指組成國家的“州”。
如: France is one of the member states of the ELL. 法國是歐洲聯盟成員國之一。
5、 population
Aggregate modeling of states, countries, sports teams, or any situation where the population itself is limited (or sampling is really expensive).這裡是總體,而不是人口。
6、 general-purpose
多用途,多功能,通用的
7、 in a way in the way on the way on a way by the way
in a way 在某種程度上,在某種意義上 in the way 擋路,擋道,礙事 eg.get in the way of妨礙某人做某事 on the way 在途中,即將到達 有點類似於around the corner on a way 不存在 by the way 順便說一下,做插入語 而by the way of 藉由某種方式做
二、Bias和Variance:
1、概念理解
在A Few Useful Things to Know about Machine Learning中提到,可以將泛化誤差(generalization error)分解成bias和variance理解。
Bias: a learner’s tendency to consistently learn the same wrong thing,即度量了某種學習演算法的平均估計結果所能逼近學習目標(目標輸出)的程度。
Variance:the tendency to learn random things irrespective of the real signal,即度量了在面對同樣規模的不同訓練集時,學習演算法的估計結果發生變動的程度。比如在同一現象所產生的不同訓練資料上學習的決策樹往往差異巨大,而實際上它們應當是相同的。
從影像角度


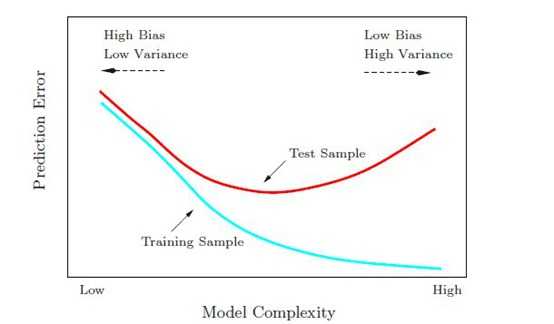
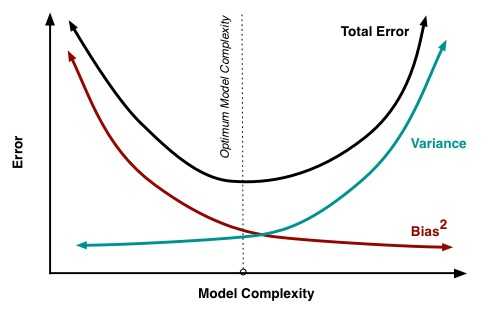
以個性化推薦系統中的特徵工程進行簡單說明:
特徵工程:用目標問題所在的特定領域知識或者自動化的方法來生成、提取、刪減或者組合變化得到特徵。這些特徵可能是顯而易見比如說商品的品牌,也有可能需要複雜的模型計算,比如Facebook上使用者A和使用者B之間關係的緊密程度(FB使用了一個決策樹來生成一個描述這個程度的向量,這個向量決定了他們News Feed推薦內容。)
1、利用領域知識生成和提取特徵
這幾乎是特徵工程裡佔大半時間的工作了:如何描述個性化並且用變數表示成特徵。一般方法就是,想想你就是該商品的目標使用者,你會想要什麼樣的個性化。
2、直接特徵和間接特徵
直接特徵 Extacted Feature 就是比如商品的品牌,間接特徵 Derived Feature 可以是從直接特徵或者各種資料組合裡計算推匯出來的。
3、特徵選擇
這部分的工作就看起來比較高階一些,比較貼近機器學習的研究工作。一般來說是兩個方法:基於領域知識的手工選擇以及自動選擇方法。
對於關聯規則和統計規則的模型來說,手工選擇的比重要大一些。比如我們已有了baseline的特徵向量,現在加進去品牌偏好,給一定的權值,看評價函式輸出的結果是否增強了推薦效果。
對於學習的模型來說,可以通過模型自動選擇每個特徵的權值,按照和效果的關聯來調整模型的引數。
四、多變數測試和AB測試
1、A / B 測試:
A/B測試本質上是個分離式組間實驗,以前進行A/B測試的技術成本和資源成本相對較高,但現在一系列專業的視覺化實驗工具的出現,A/B測試已越來越成為網站優化常用的方法。
使用A/B 測試首先需要建立一個測試頁面(variation page),這個頁面可能在標題字型,背景顏色,措辭等方面與原有頁面(control page)有所不同,然後將這兩個頁面以隨機的方式同時推送給所有瀏覽使用者。接下來分別統計兩個頁面的使用者轉化率,即可清晰的瞭解到兩種設計的優劣。
2、多變數測試
多變數(Multivariate)測試,是從A/B測試延伸出來的概念。A/B測試中,你需要建立多個頁面來進行轉化率測試,而多變數測試則是利用“模組化”的思維方法——你的頁面(被劃分成多個模組)在測試時不需要額外做多個版本,而是直接動態地分配頁面的這些模組,讓不同的頁面模組組合顯示給不同的訪問者。這樣,就能通過一些相對複雜的數學工具來研究頁面各部分之間的關係和相互作用,而不僅僅只是哪個頁面的版本更有用。
五、bootstrap-自舉法
所謂的Bootstrapping法就是利用有限的樣本資料經由多次重複抽樣,重新建立起足以代表母體樣本分佈之新樣本。
對於一個取樣,我們只能計算出某個統計量(例如均值)的一個取值,無法知道均值統計量的分佈情況。但是通過自助法(自舉法)我們可以模擬出均值統計量的近似分佈。有了分佈很多事情就可以做了(比如說有你推出的結果來進而推測實際總體的情況)。
bootstrapping方法的實現很簡單,假設你抽取的樣本大小為n:
在原樣本中有放回的抽樣,抽取n次。每抽一次形成一個新的樣本,重複操作,形成很多新樣本,通過這些樣本就可以計算出樣本的一個分佈。新樣本的數量多少合適呢?大概1000就差不多行了,如果計算成本很小,或者對精度要求比較高,就增加新樣本的數量。
最後這種方法的準確性和什麼有關呢?這個我還不是清楚,猜測是和原樣本的大小n,和Bootstrapping產生的新樣本的數量有關係,越大的話越是精確,更詳細的就不清楚了,想知道話做個搞幾個已知的分佈做做實驗應該就清楚了。
六、直方圖的bin
“hist” is short for “Histogram(直方圖、柱狀圖)”。
1.N = hist(Y)
bins the elements of Y into 10 equally spaced containers and returns the number of elements in each container. If Y is a matrix, hist works down the columns.
(將向量Y的元素平均分到十個等間隔的容器中,並且返回每個容器的元素個數。如果Y是一個矩陣,hist指令逐列元素操作。Y為向量的情形見例1和2,為矩陣的情形見例3.)
例1.執行指令
>> Y = [1:10];
>> hist(Y)
得到
例2.執行指令
>> Y = [1, 2, 2, 5, 6, 6, 8, 11];
>> hist(Y)
得到

七、正則化方法:L1和L2 regularization、資料集擴增、dropout
時間:2015-03-14 18:32:59
標籤:機器學習 正則化 過擬合
本文是《Neural networks and deep learning》概覽 中第三章的一部分,講機器學習/深度學習演算法中常用的正則化方法。
1、正則化方法:防止過擬合,提高泛化能力
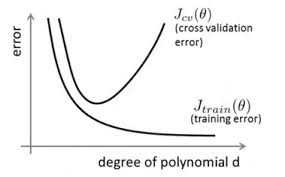
在訓練資料不夠多時,或者overtraining時,常常會導致overfitting(過擬合)。其直觀的表現如下圖所示,隨著訓練過程,網路在training data上的error漸漸減小,但是在驗證集上的error卻反而漸漸增大——因為訓練出來的網路過擬合了訓練集,對訓練集外的資料卻不work。
避免過擬合的方法有很多:early stopping、資料集擴增(Data augmentation)、正則化(Regularization)包括L1、L2(L2 regularization也叫weight decay),dropout。
2、L2 regularization(權重衰減)
L2正則化就是在代價函式後面再加上一個正則化項:
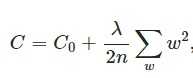
L2正則化項是怎麼避免overfitting的呢?我們推導一下看看,先求導:
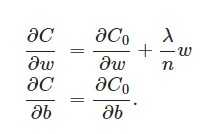
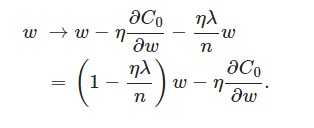
另外,需要提一下,對於基於mini-batch的隨機梯度下降,w和b更新的公式跟上面給出的有點不同:
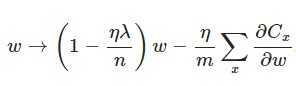
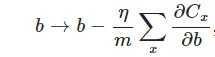
到目前為止,我們只是解釋了L2正則化項有讓w“變小”的效果,但是還沒解釋為什麼w“變小”可以防止overfitting?人們普遍認為:更小的權值w,從某種意義上說,表示網路的複雜度更低,對資料的擬合剛剛好(這個法則也叫做奧卡姆剃刀)。而在實際應用中,也驗證了這一點,L2正則化的效果往往好於未經正則化的效果。
3、L1 regularization
在原始的代價函式後面加上一個L1正則化項,即所有權重w的絕對值的和,乘以λ/n(這裡不像L2正則化項那樣,需要再乘以1/2,具體原因上面已經說過。)
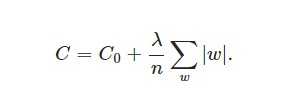
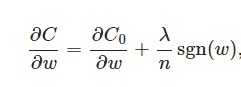
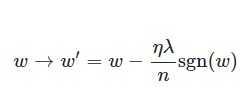
另外,上面沒有提到一個問題,當w為0時怎麼辦?當w等於0時,|W|是不可導的,所以我們只能按照原始的未經正則化的方法去更新w,這就相當於去掉η*λ*sgn(w)/n這一項,所以我們可以規定sgn(0)=0,這樣就把w=0的情況也統一進來了。(在程式設計的時候,令sgn(0)=0,sgn(w>0)=1,sgn(w<0)=-1)
4、Dropout
L1、L2正則化是通過修改代價函式來實現的,而Dropout則是通過修改神經網路本身來實現的,它是在訓練網路時用的一種技巧(trike)。它的流程如下:
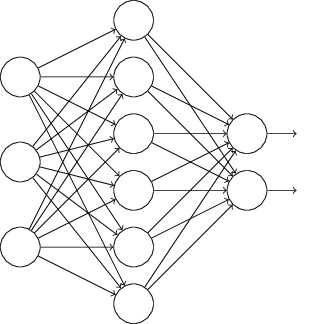
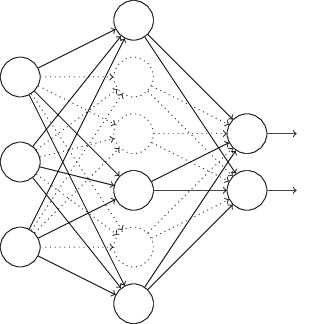
以上就是一次迭代的過程,在第二次迭代中,也用同樣的方法,只不過這次刪除的那一半隱層單元,跟上一次刪除掉的肯定是不一樣的,因為我們每一次迭代都是“隨機”地去刪掉一半。第三次、第四次……都是這樣,直至訓練結束。
以上就是Dropout,它為什麼有助於防止過擬合呢?可以簡單地這樣解釋,運用了dropout的訓練過程,相當於訓練了很多個只有半數隱層單元的神經網路(後面簡稱為“半數網路”),每一個這樣的半數網路,都可以給出一個分類結果,這些結果有的是正確的,有的是錯誤的。隨著訓練的進行,大部分半數網路都可以給出正確的分類結果,那麼少數的錯誤分類結果就不會對最終結果造成大的影響。
更加深入地理解,可以看看Hinton和Alex兩牛2012的論文《ImageNet Classification with Deep Convolutional Neural Networks》
5、資料集擴增(data augmentation)
“有時候不是因為演算法好贏了,而是因為擁有更多的資料才贏了。”
不記得原話是哪位大牛說的了,hinton?從中可見訓練資料有多麼重要,特別是在深度學習方法中,更多的訓練資料,意味著可以用更深的網路,訓練出更好的模型。
既然這樣,收集更多的資料不就行啦?如果能夠收集更多可以用的資料,當然好。但是很多時候,收集更多的資料意味著需要耗費更多的人力物力,有弄過人工標註的同學就知道,效率特別低,簡直是粗活。
所以,可以在原始資料上做些改動,得到更多的資料,以圖片資料集舉例,可以做各種變換,如:
將原始圖片旋轉一個小角度
新增隨機噪聲
一些有彈性的畸變(elastic distortions),論文《Best practices for convolutional neural networks applied to visual document analysis》對MNIST做了各種變種擴增。
擷取(crop)原始圖片的一部分。比如DeepID中,從一副人臉圖中,擷取出了100個小patch作為訓練資料,極大地增加了資料集。感興趣的可以看《Deep learning face representation from predicting 10,000 classes》.
更多資料意味著什麼?
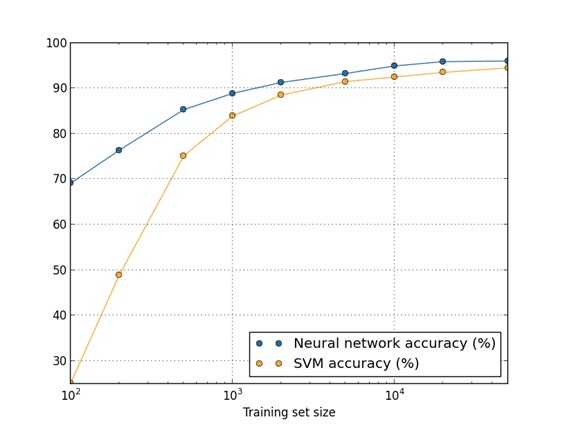
用50000個MNIST的樣本訓練SVM得出的accuracy94.48%,用5000個MNIST的樣本訓練NN得出accuracy為93.24%,所以更多的資料可以使演算法表現得更好。在機器學習中,演算法本身並不能決出勝負,不能武斷地說這些演算法誰優誰劣,因為資料對演算法效能的影響很大。
Bagging 和 Boosting 都是一種將幾個弱分類器(可以理解為分類或者回歸能力不好的分類器)按照一定規則組合在一起從而變成一個強分類器。但二者的組合方式有所區別。
一、Bagging
Bagging的思想很簡單,我選取一堆弱分類器用於分類,然後最終結果投票決定,哪個票數多就屬於哪一類。不過Bagging的一個重要步驟就是在訓練每一個弱分類器的時候不是用整個樣本來做分類,而是在樣本中隨機抽取一系列的樣本集,可以重複也可以數目少於原樣本,這就是Bootstraping。Bagging的思想簡單,應用很廣泛,最出名的應用就是Random Forest。
二、Boosting
Booting的思想與Bagging有所不同。第一個不同,在輸入樣本的選取上,Bagging是隨機抽取樣本,而Boosting則是按照前一個分類器的錯誤率來抽取樣本。好比前一個分類器在樣本A,B,F上出錯了,那麼我們會提升抽取這三個樣本的概率來幫助我們訓練分類器。第二個不同,在弱分類器組合上,Bagging就是投票就好啦,但是Boosting確實不是這樣,Boosting主要是將分類器線性組合起來,以為著分類器前面帶著個權重,錯誤率高的分類器的權重會低一些,正確率高的則高一些,這樣線性組合起來就是最終的結果。當然也有非線性組合的權重,但在這裡就不贅述了。Boosting最出名的應用就是Gradient Boosting Decision Tree,我們會在一篇文章中介紹。


參考內容:http://blog.csdn.net/u012162613/article/details/44261657