文作者 Mikio Braun 是 Zalando 的推薦和搜尋系統的交付帶頭人,Mikio擁有機器學習的博士學位。本文概述了一個能把資料科學引入生產系統的架構的典型模式。想了解更多的大規模複雜資料分析的內容,可以檢視Mikio Braun的培訓視訊《大規模機器學習》。
在過去的幾年間,資料科學這個概念已經被非常多的行業所接受。資料科學(源自於一個科學研究課題)最早是來自於一些試圖去理解人類的智慧並創造人工智慧的科學家,但現在它已經被證明是完全可以帶來真正的商業價值。
例如,我所在的公司:Zalando(歐洲最大的時尚品零售店)。在這裡,資料科學和其他工具一起被用來提供資料驅動的推薦。推薦本身作為後端服務,被提供給很多地方,包括產品頁面、分類目錄頁面、通訊電郵以及重新定位目標客戶等。
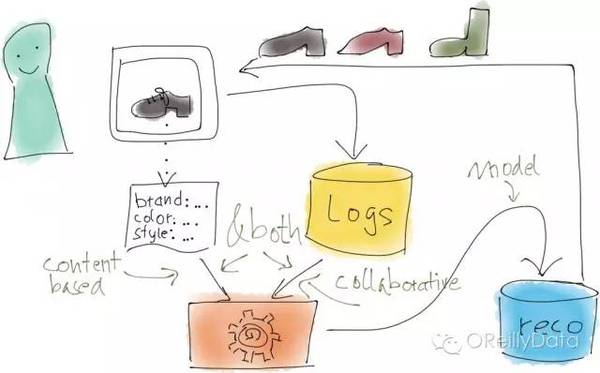
圖1:圖片來自Mikio Braun的演講頁
資料驅動產生推薦
實際上,有非常多的方法可以由資料驅動產生推薦。例如,在所謂的“協同過濾”裡,所有使用者的行為(比如瀏覽商品、對想買商品列表的操作、以及購買行為)都可以被收集起來作為推薦的基礎,然後分析發現哪些商品有相似的使用者行為模式。這種方法的優美之處在於計算機根本不用知道這些商品是什麼。而它的缺點則是商品必須要有足夠多的使用者行為資訊資料才能保證這個方法起作用。
另外一類產生推薦的方法是隻看商品的屬性。例如,推薦具有相同品牌的或者相同顏色的商品。當然,對這些方法還有非常多的擴充套件或者組合。
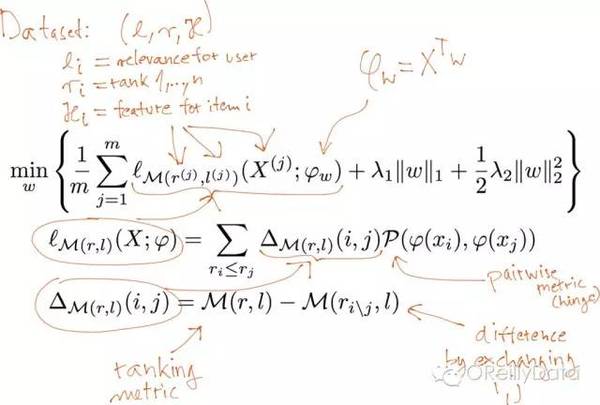
圖2:圖片由Antonio Freno友情提供並授權使用。引用自發表在KDD 2015會議的《One-Pass Ranking Models for Low-Latency Product Recommendations》論文
更簡單一些的方法就是隻通過計數來做推薦。但這種方法在實踐裡會有非常多的複雜的變形。例如,對個性化推薦,我們曾使用過“學習排序”的方法,即對商品集做個性化的排序。上圖裡所顯示的就是這個方法需要最小化的損失函式。
不過,這裡畫出這個圖的主要目的,還是來展示資料科學可能會引入的複雜度。這個函式自身使用了成對的加權指標,並帶有正則化條件。這個函式的數學展現是很簡化的,當然也就很抽象。這個方法不僅對於電商的推薦場景有用,還對當物品有足夠特徵的時候的所有型別的排序問題也有用。
將資料科學方法引入工業界
為了把類似上圖的非常複雜的數學演算法引入到生產系統中,我們需要做什麼?資料科學和軟體工程之間的介面應該是什麼樣?什麼樣的組織架構和隊伍結構才最適合使用這些資料科學的方法?這些都是非常相關和合理的問題。因為這些問題的答案將會決定對於一個資料科學家或者是整個資料科學團隊的投資是否能最終得到回報。
在下文裡,我會根據我作為一個機器學習的研究人員以及在Zalando帶領一個資料科學家和工程師團隊的經驗,來對這些問題做一些探討。
理解資料科學(系統)與生產系統的關係
讓我首先從瞭解資料科學系統與後端生產系統的關係開始,看看如果將兩者進行整合。
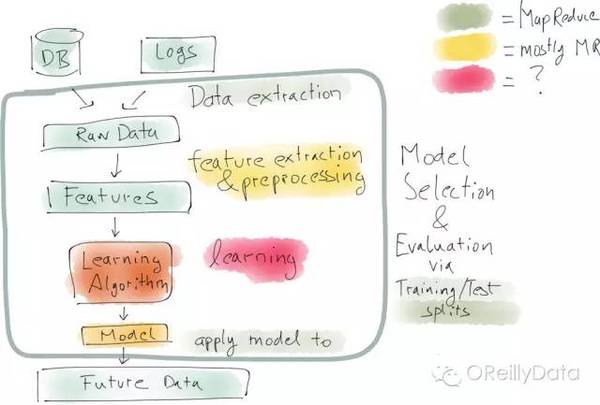
圖3:圖片來自Mikio Braun的演講頁
典型的資料科學工作流程(管道)如上圖裡所示:第一步總是從發現問題和收集一些資料(來自於資料庫或者生產系統的日誌)開始。取決於機構的資料準備好的程度,這一步有可能就是很困難的。首先,你有可能需要搞清楚誰能讓你接觸到所需的資料,並搞清楚誰能給你許可權去使用這個資料。當資料可用後,它們就可能需要被再次處理,以便提取特徵值。你希望這些特徵可以為解決問題提供有用的資訊。接著,這些特徵值被匯入學習的演算法,並用測試資料對產生的結果模型做評估,以決定這個模型是否能較好地對新資料做預測。
上述的這個分析管道通常都是短期一次性的工作。一般是由資料科學家手工完成所有的步驟。資料科學家可能會用到如Python這樣的程式語言,幷包括很多的資料分析和視覺化的庫。取決於資料數量,有時候資料科學家也使用類似Spark和Hadoop這樣的計算框架。但一般他們在一開始都只會使用整個資料集的一小部分來做分析。
為什麼開始只用一小部分資料
開始只用一小部分資料的主要原因是:整個分析管道過程並不是一錘子買賣,而是非常多次反覆迭代的過程。資料科學專案從本質上講是探索性的,甚至在某種程度上是開放式的命題。雖然專案目標很清楚,但什麼資料可用,或可用的資料是否適合分析,這些在專案一開始都不是很清楚。畢竟,選擇機器學習作為方法就已經意味著不能僅僅只是通過寫程式碼來解決問題。而是要訴諸於資料驅動的方法。
這些特點都意味著上述的分析管道是迭代的,並需要有多次改進,嘗試不同的特徵、不同的預處理模式、不同的學習方法,甚至是重回起點並尋找和實驗更多的資料來源。
這整個過程本質上就是反覆的,而且經常是高度探索性的。當做出的模型的整體的表現不錯後,資料科學家就會對真實的資料運用開發的分析管道。到這時,我們就會面臨與生成系統的整合問題。
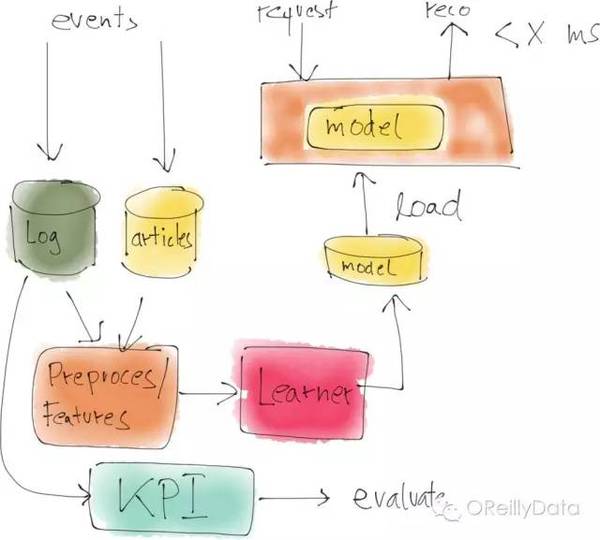
圖4:圖片來自Mikio Braun的演講頁
區分生產系統和資料科學系統
生產系統和一個資料科學系統的最主要區別就是生產系統是一個實時地、在持續執行的系統。資料一定要被處理而模型必須是經常更新的。產生的事件也通常會被用來計算關鍵業務效能指標,比如點選率等。而模型則通常會每隔幾個小時就被用新資料再進行訓練,然後再匯入生產系統中去服務於新來的(例如通過REST介面送入的)資料。
這些生產系統一般都是用如Java這樣的程式語言寫的,可以支援高效能和高可靠性。
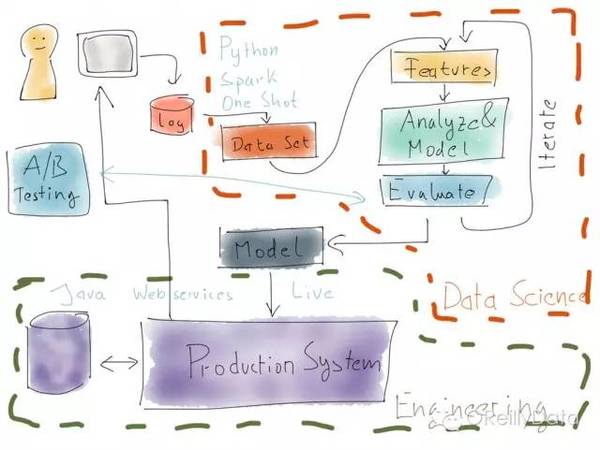
圖5:圖片來自Mikio Braun的演講頁
如果你把生產系統和資料科學系統並排放置,那麼就會得到一個類似上圖的情況。在右上角,是資料科學的部分。其典型特徵是使用類似Python的語音或者是Spark的系統,但一般是一次性的手工觸發的計算任務,並經過迭代來優化整個系統。它的產出就是一個模型,本質上就是一堆學習到的數字。這個模型隨後被匯入進生成系統。而生產系統則是一個典型的企業應用系統,用諸如Java語言寫成的,並持續執行。
當然,上面的這個圖有一些簡化了。現實中,模型都是需要被重新訓練的,所以一些版本的資料處理管道會和生成系統整合在一起,以便不時地更新生產系統裡的模型。
請注意那個在生成系統裡執行的A/B測試。它對應於資料科學一側的評估部分。但這兩部分經常並不完全具有可比性。例如不把離線的推薦結果展示給客戶,就很難去模擬一個推薦的效果,但有這樣做可能會帶來效能的提升。
最後,必須要意識到,這個系統並不是在安裝部署完成後就“萬事大吉了”。就如資料科學側的人需要迭代多次來優化資料分析管道,整個實時系統也必須隨著資料分佈漂移來做迭代演進。由此新的資料分析任務就成為可能。對我而言,能正確做好這個“外部迭代”是對生產系統的最大的挑戰,同時也是最重要的一步。因為這將決定你能否持續地改善生產系統,並確保你在資料科學上的初期投資取得回報。
資料科學家和程式設計師:合作的模式
到目前為止,我們主要關注的是生產環境裡的系統是什麼樣。當然對於如何保證生產系統穩定和高效則有很多種方法。有時候,直接部署Python寫的模型就足夠了,但生產系統和探索分析部分的分離是肯定存在的。
你將會面對的艱鉅挑戰之一,就是如何協調資料科學家與程式設計師的合作。“資料科學家”依然是一個新的角色,但他們所做的工作與典型的程式設計師有著明顯差異。由此導致的誤解和溝通障礙就不可避免了。
資料科學家的工作通常是探索性的。資料科學專案一般始於一個模糊的目標、哪些資料可用的一些想法、以及可能的演算法。但非常常見的情況是,資料科學家必須嘗試多種想法,並從資料裡獲取洞察。資料科學家會寫很多的程式碼,但是大部分都是用於測試想法,並不會被用於最終的解決方案。
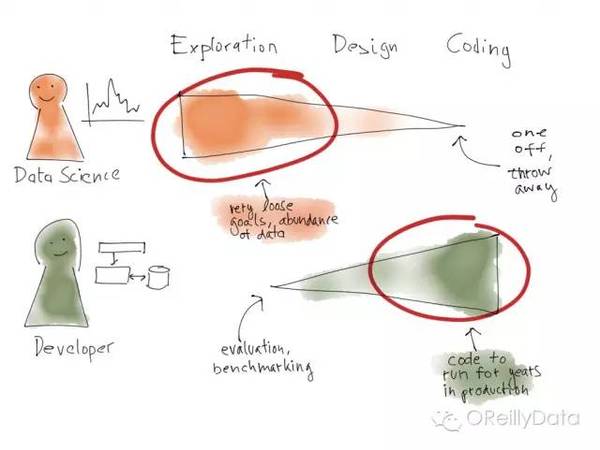
圖6:圖片來自Mikio Braun的演講頁
與資料科學家相反,程式設計師通常非常關注於程式設計。他們的目標是開發一個系統,實現所要求的功能。程式設計師有時會做一些探索性的工作,比如構建原型、驗證概念或是測試效能基準。但他們的工作的主要目標還是寫程式碼。
他們間的不同還明顯地體現在程式碼的變化上。程式設計師通常會堅持一個非常明確定義的程式碼開發流程。一般包括建立自己工作流的分支,在開發完成後做評測檢查,然後把自己的分支合併進主分支。大家可以並行開發,但必須在協商後才能把他們的分支合併進主分支。然後這個過程再重複進行。這整個過程都是確保主分支會以一個有序的方式演進。
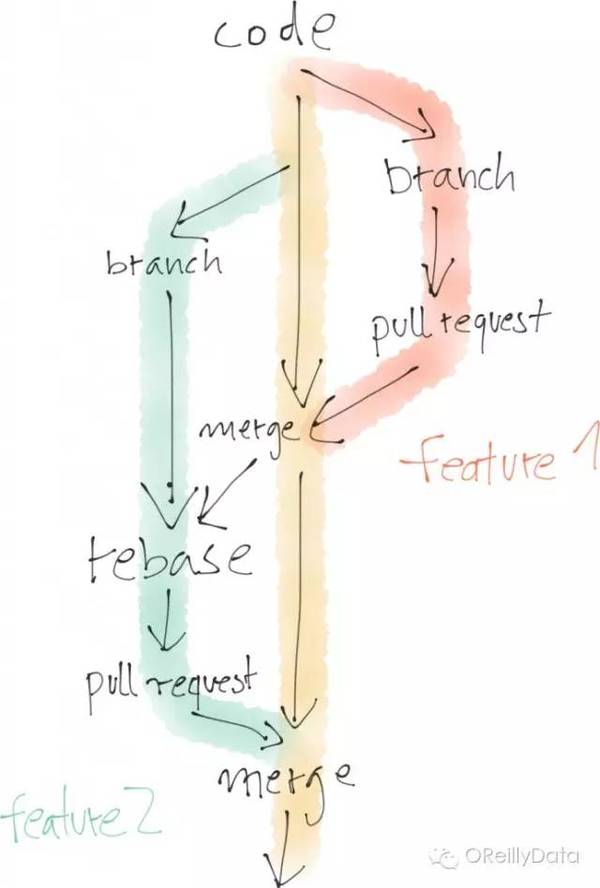
圖7:圖片來自Mikio Braun的演講頁
資料科學家也會寫很多的程式碼。但正如我之前所說的,這些程式碼通常是為了驗證想法。所以資料科學家可能是會寫出一個版本1,但它並沒有實現需求。然後又針對一個新的想法寫了版本2,隨後是2.1和2.2,直到發現還是不能實現需求而停止。再對更新的想法去寫版本3和3.1。也許在這個時候,資料科學家意識到,如果採用2.1版裡的某些方法並結合3.1版裡的某些方法,就能獲得一個更好的解決方案。這就帶來了版本3.3和3.4,並可能由此形成了最終解決方案。
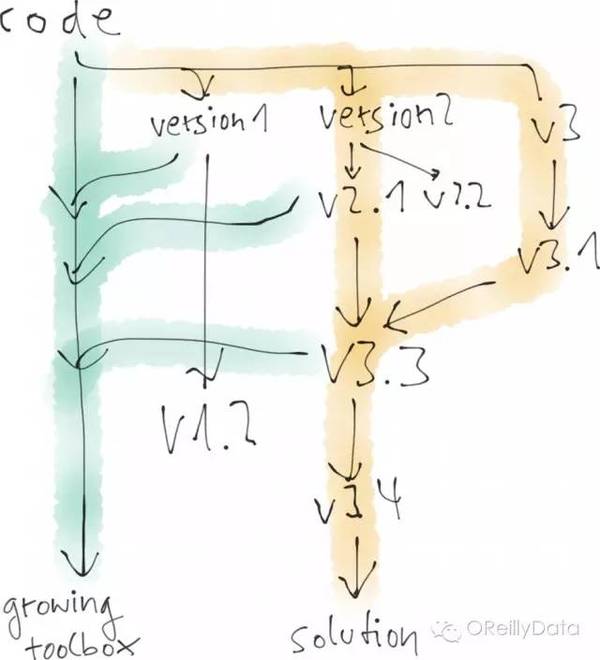
圖8:圖片來自Mikio Braun的演講頁
一個有意思的事情是,資料科學家實際上可能希望保留所有這些沒成功的版本。因為之後的某個時間,也許它們又會被拿來測試新的想法。也許有些部分可以被放入一個“工具箱”裡,逐步形成資料科學家自己的私人機器學習庫。程式設計師更希望去刪除“無用的程式碼”(因為他們知道如何快速地找回這些程式碼),而資料科學家則喜歡保留程式碼以防萬一。
上述的兩大不同意味著,在現實中,直接讓程式設計師和資料科學家共同工作可能會出問題。標準的軟體工程流程對資料科學家的探索性工作模式並不合適,因為他們的目標是不同的。引入程式碼評測檢查和有序的分支管理、評測、合併分支的工作流對資料科學家而言並不合適,還會減慢他們的工作。同樣的,把探索性的模式引入生產系統開發也不會成功。
為此,如何才能構建一個合作模式來保證兩邊都能高產出的工作?可能第一直覺就是讓他們相互分離地工作。例如,完全分開程式碼庫,並讓資料科學家獨立工作,產出需求文件,再由程式設計師團隊實現。這種方法也行得通,但流程通常會非常得慢,且容易出錯。因為重新開發實現一遍就可能會引入錯誤,尤其是在程式設計師並不熟悉資料分析演算法的情況下。同時能否進行外部迭代來改進系統的表現也依賴於程式設計師是否有足夠的能力來實現資料科學家的需求。
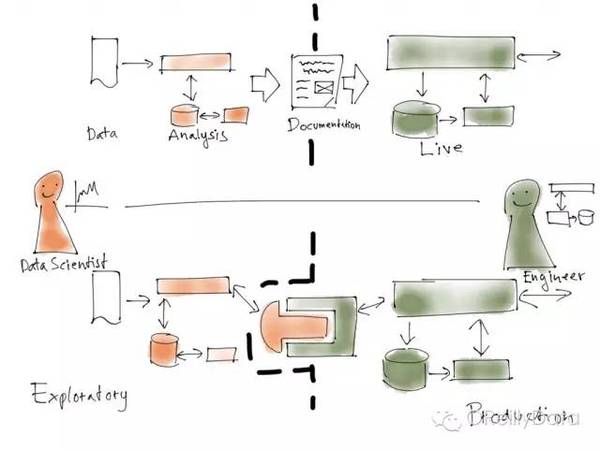
圖9:圖片來自Mikio Braun的演講頁
幸運的是,很多資料科學家實際上是希望能成為好的程式設計師,或是反過來。所以我們已經開始試驗一些更直接和更能幫助加快流程的合作模式。
例如,資料科學家和程式設計師的程式碼庫依然是分離的,但部分生產系統會提供清晰定義的介面來方便資料科學家把他們的方法嵌入進系統。與這些生產系統的介面進行溝通的程式碼必須嚴格地依據軟體開發實踐流程,但這是資料科學家的工作。用這種方式,資料科學團隊可以在自己的程式碼快速地迭代,同時也就是完成了對生產系統的迭代。
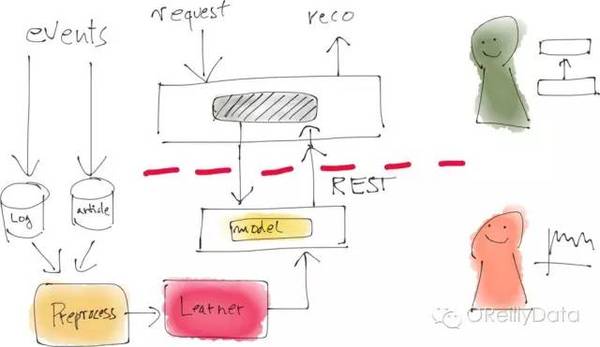
圖10:圖片來自Mikio Braun的演講頁
這種架構模式的一個具體實現是採用“微服務”方法。即讓生產系統去呼叫資料科學家團隊開發的微服務來獲取推薦。用這個方式,整個資料科學家使用的離線分析管道還可以被調整用來做A/B測試,甚至是加入生產系統而不用程式設計師團隊重新開發實現。這種模式會要求資料科學傢俱有更多的軟體工程技能,但我們看到越來越多的資料科學家已經具有這樣的技能集。事實上,後來我們修改了Zalando的資料科學家的職銜為“研究工程師(資料科學)”來反應這種實際情況。
採用類似這樣的方法,資料科學家可以快速實踐,對離線資料做迭代研究,並在生產系統環境裡迭代開發。整個團隊可以持續地把穩定的資料分析方法遷移進生產系統。
持續適應並改進
至此,我概述了一個能把資料科學引入生產系統的架構的典型模式。需要理解的一個關鍵概念就是這樣的系統需要持續地適應並改進(這和幾乎所有的針對實際資料的資料驅動專案類似)。能夠快速迭代,實驗新的方法,使用A/B測試驗證結果,這一切都非常重要。
依據我的經驗,保持資料科學家團隊和程式設計師團隊的分離是不可能達成這些目標的。與此同時,很重要的是,我們也要承認兩個團隊的工作方式確實是不同的,因為他們的目標不一樣(資料科學家的工作更加具有探索性,而程式設計師更關注於開發軟體和系統)。
通過允許各自團隊能工作在更適合他們的目標的方式,並定義一些清晰的介面,是有可能整合兩個團隊,並保證新的方法可以被快速地試錯的。這會要求資料科學家團隊具有更多的軟體工程技能,或是至少能有軟體工程師來橋接起兩個世界。
作者介紹
Mikio Braun是Zalando的推薦和搜尋系統的交付帶頭人。Zalando是歐洲最大的時尚品平臺之一。Mikio擁有機器學習的博士學位,並在投身把研究成果轉化成行業應用前進行了多年的研究工作。