Http請求
參考:
HTTP深入淺出 http請求 - Chance_yin - 部落格園
http://www.cnblogs.com/yin-jingyu/archive/2011/08/01/2123548.html

HTTP(HyperText Transfer Protocol)是一套計算機通過網路進行通訊的規則。計算機專家設計出HTTP,使HTTP客戶(如Web瀏覽器)能夠從HTTP伺服器(Web伺服器)請求資訊和服務,HTTP目前協議的版本是1.1.HTTP是一種無狀態的協議,無狀態是指Web瀏覽器和Web伺服器之間不需要建立持久的連線,這意味著當一個客戶端向伺服器端發出請求,然後Web伺服器返回響應(response),連線就被關閉了,在伺服器端不保留連線的有關資訊.HTTP遵循請求(Request)/應答(Response)模型。Web瀏覽器向Web伺服器傳送請求,Web伺服器處理請求並返回適當的應答。所有HTTP連線都被構造成一套請求和應答。
HTTP使用內容型別,是指Web伺服器向Web瀏覽器返回的檔案都有與之相關的型別。所有這些型別在MIME Internet郵件協議上模型化,即Web伺服器告訴Web瀏覽器該檔案所具有的種類,是HTML文件、GIF格式影象、聲音檔案還是獨立的應用程式。大多數Web瀏覽器都擁有一系列的可配置的輔助應用程式,它們告訴瀏覽器應該如何處理Web伺服器傳送過來的各種內容型別。
HTTP通訊機制是在一次完整的HTTP通訊過程中,Web瀏覽器與Web伺服器之間將完成下列7個步驟:
(1) 建立TCP連線
在HTTP工作開始之前,Web瀏覽器首先要通過網路與Web伺服器建立連線,該連線是通過TCP來完成的,該協議與IP協議共同構建Internet,即著名的TCP/IP協議族,因此Internet又被稱作是TCP/IP網路。HTTP是比TCP更高層次的應用層協議,根據規則,只有低層協議建立之後才能,才能進行更層協議的連線,因此,首先要建立TCP連線,一般TCP連線的埠號是80
(2) Web瀏覽器向Web伺服器傳送請求命令
一旦建立了TCP連線,Web瀏覽器就會向Web伺服器傳送請求命令
例如:GET/sample/hello.jsp HTTP/1.1
(3) Web瀏覽器傳送請求頭資訊
瀏覽器傳送其請求命令之後,還要以頭資訊的形式向Web伺服器傳送一些別的資訊,之後瀏覽器傳送了一空白行來通知伺服器,它已經結束了該頭資訊的傳送。
(4) Web伺服器應答
客戶機向伺服器發出請求後,伺服器會客戶機回送應答,
HTTP/1.1 200 OK
應答的第一部分是協議的版本號和應答狀態碼
(5) Web伺服器傳送應答頭資訊
正如客戶端會隨同請求傳送關於自身的資訊一樣,伺服器也會隨同應答向使用者傳送關於它自己的資料及被請求的文件。
(6) Web伺服器向瀏覽器傳送資料
Web伺服器向瀏覽器傳送頭資訊後,它會傳送一個空白行來表示頭資訊的傳送到此為結束,接著,它就以Content-Type應答頭資訊所描述的格式傳送使用者所請求的實際資料
(7) Web伺服器關閉TCP連線
一般情況下,一旦Web伺服器向瀏覽器傳送了請求資料,它就要關閉TCP連線,然後如果瀏覽器或者伺服器在其頭資訊加入了這行程式碼
Connection:keep-alive
TCP連線在傳送後將仍然保持開啟狀態,於是,瀏覽器可以繼續通過相同的連線傳送請求。保持連線節省了為每個請求建立新連線所需的時間,還節約了網路頻寬。
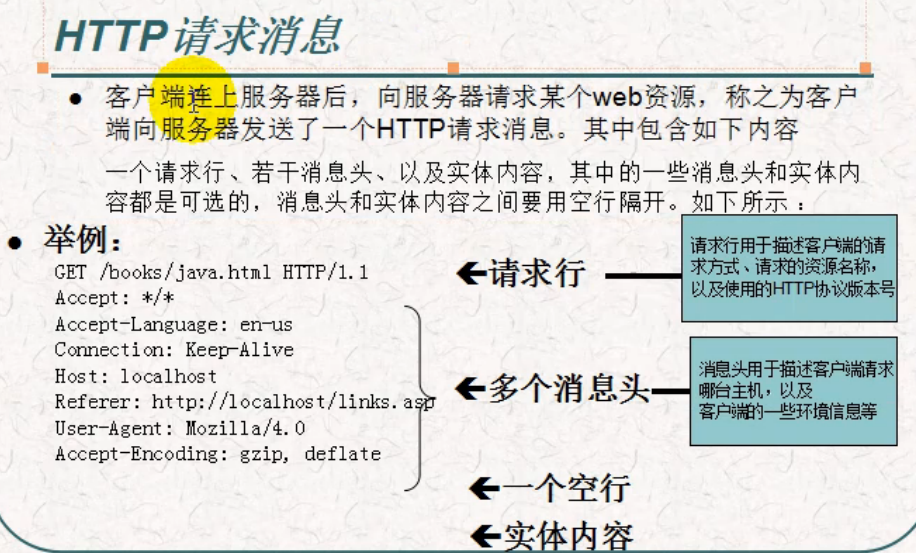
HTTP請求格式
當瀏覽器向Web伺服器發出請求時,它向伺服器傳遞了一個資料塊,也就是請求資訊,HTTP請求資訊由3部分組成:
l 請求方法URI協議/版本
l 請求頭(Request Header)
l 請求正文
下面是一個HTTP請求的例子:
GET/sample.jspHTTP/1.1
Accept:image/gif.image/jpeg,*/*
Accept-Language:zh-cn
Connection:Keep-Alive
Host:localhost
User-Agent:Mozila/4.0(compatible;MSIE5.01;Window NT5.0)
Accept-Encoding:gzip,deflate
username=jinqiao&password=1234
(1) 請求方法URI協議/版本
請求的第一行是“方法URL議/版本”:GET/sample.jsp HTTP/1.1
以上程式碼中“GET”代表請求方法,“/sample.jsp”表示URI,“HTTP/1.1代表協議和協議的版本。
根據HTTP標準,HTTP請求可以使用多種請求方法。例如:HTTP1.1支援7種請求方法:GET、POST、HEAD、OPTIONS、PUT、DELETE和TARCE。在Internet應用中,最常用的方法是GET和POST。
URL完整地指定了要訪問的網路資源,通常只要給出相對於伺服器的根目錄的相對目錄即可,因此總是以“/”開頭,最後,協議版本宣告瞭通訊過程中使用HTTP的版本。
(2) 請求頭(Request Header)
請求頭包含許多有關的客戶端環境和請求正文的有用資訊。例如,請求頭可以宣告瀏覽器所用的語言,請求正文的長度等。
Accept:image/gif.image/jpeg.*/*
Accept-Language:zh-cn
Connection:Keep-Alive
Host:localhost
User-Agent:Mozila/4.0(compatible:MSIE5.01:Windows NT5.0)
Accept-Encoding:gzip,deflate.
(3) 請求正文
請求頭和請求正文之間是一個空行,這個行非常重要,它表示請求頭已經結束,接下來的是請求正文。請求正文中可以包含客戶提交的查詢字串資訊:
username=jinqiao&password=1234
在以上的例子的HTTP請求中,請求的正文只有一行內容。當然,在實際應用中,HTTP請求正文可以包含更多的內容。
HTTP請求方法我這裡只討論GET方法與POST方法
l GET方法
GET方法是預設的HTTP請求方法,我們日常用GET方法來提交表單資料,然而用GET方法提交的表單資料只經過了簡單的編碼,同時它將作為URL的一部分向Web伺服器傳送,因此,如果使用GET方法來提交表單資料就存在著安全隱患上。例如
從上面的URL請求中,很容易就可以辯認出表單提交的內容。(?之後的內容)另外由於GET方法提交的資料是作為URL請求的一部分所以提交的資料量不能太大
l POST方法
POST方法是GET方法的一個替代方法,它主要是向Web伺服器提交表單資料,尤其是大批量的資料。POST方法克服了GET方法的一些缺點。通過POST方法提交表單資料時,資料不是作為URL請求的一部分而是作為標準資料傳送給Web伺服器,這就克服了GET方法中的資訊無法保密和資料量太小的缺點。因此,出於安全的考慮以及對使用者隱私的尊重,通常表單提交時採用POST方法。
從程式設計的角度來講,如果使用者通過GET方法提交資料,則資料存放在QUERY_STRING環境變數中,而POST方法提交的資料則可以從標準輸入流中獲取。
HTTP應答與HTTP請求相似,HTTP響應也由3個部分構成,分別是:
l 協議狀態版本程式碼描述
l 響應頭(Response Header)
l 響應正文
下面是一個HTTP響應的例子:
HTTP/1.1 200 OK
Server:Apache Tomcat/5.0.12
Date:Mon,6Oct2003 13:23:42 GMT
Content-Length:112
<html>
<head>
<head>
<title>HTTP響應示例<title>
</head>
<body>
Hello HTTP!
</body>
</html>
協議狀態程式碼描述HTTP響應的第一行類似於HTTP請求的第一行,它表示通訊所用的協議是HTTP1.1伺服器已經成功的處理了客戶端發出的請求(200表示成功):
協議狀態程式碼描述HTTP響應的第一行類似於HTTP請求的第一行,它表示通訊所用的協議是HTTP1.1伺服器已經成功的處理了客戶端發出的請求(200表示成功):
HTTP/1.1 200 OK
響應頭(Response Header)響應頭也和請求頭一樣包含許多有用的資訊,例如伺服器型別、日期時間、內容型別和長度等:
響應頭(Response Header)響應頭也和請求頭一樣包含許多有用的資訊,例如伺服器型別、日期時間、內容型別和長度等:
Server:Apache Tomcat/5.0.12
Date:Mon,6Oct2003 13:13:33 GMT
Content-Type:text/html
Last-Moified:Mon,6 Oct 2003 13:23:42 GMT
Content-Length:112
響應正文響應正文就是伺服器返回的HTML頁面:
<html>
<head>
<head>
<title>HTTP響應示例<title>
</head>
<body>
Hello HTTP!
</body>
</html>
響應頭和正文之間也必須用空行分隔。
l HTTP應答碼
HTTP應答碼也稱為狀態碼,它反映了Web伺服器處理HTTP請求狀態。HTTP應答碼由3位數字構成,其中首位數字定義了應答碼的型別:
1XX-資訊類(Information),表示收到Web瀏覽器請求,正在進一步的處理中
2XX-成功類(Successful),表示使用者請求被正確接收,理解和處理例如:200 OK
3XX-重定向類(Redirection),表示請求沒有成功,客戶必須採取進一步的動作。
4XX-客戶端錯誤(Client Error),表示客戶端提交的請求有錯誤 例如:404 NOT
Found,意味著請求中所引用的文件不存在。
5XX-伺服器錯誤(Server Error)表示伺服器不能完成對請求的處理:如 500
對於我們Web開發人員來說掌握HTTP應答碼有助於提高Web應用程式除錯的效率和準確性。
安全連線
Web應用最常見的用途之一是電子商務,可以利用Web伺服器端程式使人們能夠網路購物,需要指出一點是,預設情況下,通過Internet傳送資訊是不安全的,如果某人碰巧截獲了你發給朋友的一則訊息,他就能開啟它,假想在裡面有你的信用卡號碼,這會有多麼糟糕,幸運的是,很多Web伺服器以及Web瀏覽器都有創立安全連線的能力,這樣它們就可以安全的通訊了。
通過Internet提供安全連線最常見的標準是安全套接層(Secure Sockets layer,SSl)協議。SSL協議是一個應用層協議(和HTTP一樣),用於安全方式在Web上交換資料,SSL使用公開金鑰編碼系統。從本質講,這意味著業務中每一方都擁有一個公開的和一個私有的金鑰。當一方使用另一方公開金鑰進行編碼時,只有擁有匹配金鑰的人才能對其解碼。簡單來講,公開金鑰編碼提供了一種用於在兩方之間交換資料的安全方法,SSL連線建立之後,客戶和伺服器都交換公開金鑰,並在進行業務聯絡之前進行驗證,一旦雙方的金鑰都通過驗證,就可以安全地交換資料。
- GET
通過請求URI得到資源 - POST,
用於新增新的內容 - PUT
用於修改某個內容 - DELETE,
刪除某個內容 - CONNECT,
用於代理進行傳輸,如使用SSL - OPTIONS
詢問可以執行哪些方法 - PATCH,
部分文件更改 - PROPFIND, (wedav)
檢視屬性 - PROPPATCH, (wedav)
設定屬性 - MKCOL, (wedav)
建立集合(資料夾) - COPY, (wedav)
拷貝 - MOVE, (wedav)
移動 - LOCK, (wedav)
加鎖 - UNLOCK (wedav)
解鎖 - TRACE
用於遠端診斷伺服器 - HEAD
類似於GET, 但是不返回body資訊,用於檢查物件是否存在,以及得到物件的後設資料
apache2中,可使用Limit,LimitExcept進行訪問控制的方法包括:
GET, POST, PUT, DELETE, CONNECT,OPTIONS, PATCH, PROPFIND, PROPPATCH, MKCOL, COPY, MOVE, LOCK, 和 UNLOCK.其中, HEAD GET POST OPTIONS PROPFIND是和讀取相關的方法,MKCOL PUT DELETE LOCK UNLOCK COPY MOVE PROPPATCH是和修改相關的方法
part of Hypertext Transfer Protocol -- HTTP/1.1
RFC 2616 Fielding, et al.
RFC 2616 Fielding, et al.
The set of common methods for HTTP/1.1 is defined below. Although this set can be expanded, additional methods cannot be assumed to share the same semantics for separately extended clients and servers.
The Host request-header field (section 14.23) MUST accompany all HTTP/1.1 requests.
Implementors should be aware that the software represents the user in their interactions over the Internet, and should be careful to allow the user to be aware of any actions they might take which may have an unexpected significance to themselves or others.
In particular, the convention has been established that the GET and HEAD methods SHOULD NOT have the significance of taking an action other than retrieval. These methods ought to be considered "safe". This allows user agents to represent other methods, such as POST, PUT and DELETE, in a special way, so that the user is made aware of the fact that a possibly unsafe action is being requested.
Naturally, it is not possible to ensure that the server does not generate side-effects as a result of performing a GET request; in fact, some dynamic resources consider that a feature. The important distinction here is that the user did not request the side-effects, so therefore cannot be held accountable for them.
Methods can also have the property of "idempotence" in that (aside from error or expiration issues) the side-effects of N > 0 identical requests is the same as for a single request. The methods GET, HEAD, PUT and DELETE share this property. Also, the methods OPTIONS and TRACE SHOULD NOT have side effects, and so are inherently idempotent.
However, it is possible that a sequence of several requests is non- idempotent, even if all of the methods executed in that sequence are idempotent. (A sequence is idempotent if a single execution of the entire sequence always yields a result that is not changed by a reexecution of all, or part, of that sequence.) For example, a sequence is non-idempotent if its result depends on a value that is later modified in the same sequence.
A sequence that never has side effects is idempotent, by definition (provided that no concurrent operations are being executed on the same set of resources).
The OPTIONS method represents a request for information about the communication options available on the request/response chain identified by the Request-URI. This method allows the client to determine the options and/or requirements associated with a resource, or the capabilities of a server, without implying a resource action or initiating a resource retrieval.
Responses to this method are not cacheable.
If the OPTIONS request includes an entity-body (as indicated by the presence of Content-Length or Transfer-Encoding), then the media type MUST be indicated by a Content-Type field. Although this specification does not define any use for such a body, future extensions to HTTP might use the OPTIONS body to make more detailed queries on the server. A server that does not support such an extension MAY discard the request body.
If the Request-URI is an asterisk ("*"), the OPTIONS request is intended to apply to the server in general rather than to a specific resource. Since a server's communication options typically depend on the resource, the "*" request is only useful as a "ping" or "no-op" type of method; it does nothing beyond allowing the client to test the capabilities of the server. For example, this can be used to test a proxy for HTTP/1.1 compliance (or lack thereof).
If the Request-URI is not an asterisk, the OPTIONS request applies only to the options that are available when communicating with that resource.
A 200 response SHOULD include any header fields that indicate optional features implemented by the server and applicable to that resource (e.g., Allow), possibly including extensions not defined by this specification. The response body, if any, SHOULD also include information about the communication options. The format for such a
body is not defined by this specification, but might be defined by future extensions to HTTP. Content negotiation MAY be used to select the appropriate response format. If no response body is included, the response MUST include a Content-Length field with a field-value of "0".
The Max-Forwards request-header field MAY be used to target a specific proxy in the request chain. When a proxy receives an OPTIONS request on an absoluteURI for which request forwarding is permitted, the proxy MUST check for a Max-Forwards field. If the Max-Forwards field-value is zero ("0"), the proxy MUST NOT forward the message; instead, the proxy SHOULD respond with its own communication options. If the Max-Forwards field-value is an integer greater than zero, the proxy MUST decrement the field-value when it forwards the request. If no Max-Forwards field is present in the request, then the forwarded request MUST NOT include a Max-Forwards field.
The GET method means retrieve whatever information (in the form of an entity) is identified by the Request-URI. If the Request-URI refers to a data-producing process, it is the produced data which shall be returned as the entity in the response and not the source text of the process, unless that text happens to be the output of the process.
The semantics of the GET method change to a "conditional GET" if the request message includes an If-Modified-Since, If-Unmodified-Since, If-Match, If-None-Match, or If-Range header field. A conditional GET method requests that the entity be transferred only under the circumstances described by the conditional header field(s). The conditional GET method is intended to reduce unnecessary network usage by allowing cached entities to be refreshed without requiring multiple requests or transferring data already held by the client.
The semantics of the GET method change to a "partial GET" if the request message includes a Range header field. A partial GET requests that only part of the entity be transferred, as described in section 14.35. The partial GET method is intended to reduce unnecessary network usage by allowing partially-retrieved entities to be completed without transferring data already held by the client.
The response to a GET request is cacheable if and only if it meets the requirements for HTTP caching described in section 13.
See section 15.1.3 for security considerations when used for forms.
The HEAD method is identical to GET except that the server MUST NOT return a message-body in the response. The metainformation contained in the HTTP headers in response to a HEAD request SHOULD be identical to the information sent in response to a GET request. This method can be used for obtaining metainformation about the entity implied by the request without transferring the entity-body itself. This method is often used for testing hypertext links for validity, accessibility, and recent modification.
The response to a HEAD request MAY be cacheable in the sense that the information contained in the response MAY be used to update a previously cached entity from that resource. If the new field values indicate that the cached entity differs from the current entity (as would be indicated by a change in Content-Length, Content-MD5, ETag or Last-Modified), then the cache MUST treat the cache entry as stale.
The POST method is used to request that the origin server accept the entity enclosed in the request as a new subordinate of the resource identified by the Request-URI in the Request-Line. POST is designed to allow a uniform method to cover the following functions:
- Annotation of existing resources;
- Posting a message to a bulletin board, newsgroup, mailing list, or similar group of articles;
- Providing a block of data, such as the result of submitting a form, to a data-handling process;
- Extending a database through an append operation.
The actual function performed by the POST method is determined by the server and is usually dependent on the Request-URI. The posted entity is subordinate to that URI in the same way that a file is subordinate to a directory containing it, a news article is subordinate to a newsgroup to which it is posted, or a record is subordinate to a database.
The action performed by the POST method might not result in a resource that can be identified by a URI. In this case, either 200 (OK) or 204 (No Content) is the appropriate response status, depending on whether or not the response includes an entity that describes the result.
If a resource has been created on the origin server, the response SHOULD be 201 (Created) and contain an entity which describes the status of the request and refers to the new resource, and a Location header (see section 14.30).
Responses to this method are not cacheable, unless the response includes appropriate Cache-Control or Expires header fields. However, the 303 (See Other) response can be used to direct the user agent to retrieve a cacheable resource.
POST requests MUST obey the message transmission requirements set out in section 8.2.
See section 15.1.3 for security considerations.
The PUT method requests that the enclosed entity be stored under the supplied Request-URI. If the Request-URI refers to an already existing resource, the enclosed entity SHOULD be considered as a modified version of the one residing on the origin server. If the Request-URI does not point to an existing resource, and that URI is capable of being defined as a new resource by the requesting user agent, the origin server can create the resource with that URI. If a new resource is created, the origin server MUST inform the user agent via the 201 (Created) response. If an existing resource is modified, either the 200 (OK) or 204 (No Content) response codes SHOULD be sent to indicate successful completion of the request. If the resource could not be created or modified with the Request-URI, an appropriate error response SHOULD be given that reflects the nature of the problem. The recipient of the entity MUST NOT ignore any Content-* (e.g. Content-Range) headers that it does not understand or implement and MUST return a 501 (Not Implemented) response in such cases.
If the request passes through a cache and the Request-URI identifies one or more currently cached entities, those entries SHOULD be treated as stale. Responses to this method are not cacheable.
The fundamental difference between the POST and PUT requests is reflected in the different meaning of the Request-URI. The URI in a POST request identifies the resource that will handle the enclosed entity. That resource might be a data-accepting process, a gateway to some other protocol, or a separate entity that accepts annotations. In contrast, the URI in a PUT request identifies the entity enclosed with the request -- the user agent knows what URI is intended and the server MUST NOT attempt to apply the request to some other resource. If the server desires that the request be applied to a different URI,
it MUST send a 301 (Moved Permanently) response; the user agent MAY then make its own decision regarding whether or not to redirect the request.
A single resource MAY be identified by many different URIs. For example, an article might have a URI for identifying "the current version" which is separate from the URI identifying each particular version. In this case, a PUT request on a general URI might result in several other URIs being defined by the origin server.
HTTP/1.1 does not define how a PUT method affects the state of an origin server.
PUT requests MUST obey the message transmission requirements set out in section 8.2.
Unless otherwise specified for a particular entity-header, the entity-headers in the PUT request SHOULD be applied to the resource created or modified by the PUT.
The DELETE method requests that the origin server delete the resource identified by the Request-URI. This method MAY be overridden by human intervention (or other means) on the origin server. The client cannot be guaranteed that the operation has been carried out, even if the status code returned from the origin server indicates that the action has been completed successfully. However, the server SHOULD NOT indicate success unless, at the time the response is given, it intends to delete the resource or move it to an inaccessible location.
A successful response SHOULD be 200 (OK) if the response includes an entity describing the status, 202 (Accepted) if the action has not yet been enacted, or 204 (No Content) if the action has been enacted but the response does not include an entity.
If the request passes through a cache and the Request-URI identifies one or more currently cached entities, those entries SHOULD be treated as stale. Responses to this method are not cacheable.
The TRACE method is used to invoke a remote, application-layer loop- back of the request message. The final recipient of the request SHOULD reflect the message received back to the client as the entity-body of a 200 (OK) response. The final recipient is either the
origin server or the first proxy or gateway to receive a Max-Forwards value of zero (0) in the request (see section 14.31). A TRACE request MUST NOT include an entity.
TRACE allows the client to see what is being received at the other end of the request chain and use that data for testing or diagnostic information. The value of the Via header field (section14.45) is of particular interest, since it acts as a trace of the request chain. Use of the Max-Forwards header field allows the client to limit the length of the request chain, which is useful for testing a chain of proxies forwarding messages in an infinite loop.
If the request is valid, the response SHOULD contain the entire request message in the entity-body, with a Content-Type of "message/http". Responses to this method MUST NOT be cached.
This specification reserves the method name CONNECT for use with a proxy that can dynamically switch to being a tunnel (e.g. SSL tunneling [44]).