這是一篇總結文,總結我看過的幾篇用GAN做影象翻譯的文章的“套路”。
首先,什麼是影象翻譯?
為了說清楚這個問題,下面我給出一個不嚴謹的形式化定義。我們先來看兩個概念。第一個概念是影象內容(content) 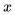 ,它是影象的固有內容,是區分不同影象的依據。第二個概念是影象域(domain),域內的影象可以認為是影象內容被賦予了某些相同的屬性。舉個例子,我們看到一張貓的圖片,影象內容就是那隻特定的喵,如果我們給影象賦予彩色,就得到了現實中看到的喵;如果給那張影象賦予鉛筆畫屬性,就得到了一隻“鉛筆喵”。喵~
,它是影象的固有內容,是區分不同影象的依據。第二個概念是影象域(domain),域內的影象可以認為是影象內容被賦予了某些相同的屬性。舉個例子,我們看到一張貓的圖片,影象內容就是那隻特定的喵,如果我們給影象賦予彩色,就得到了現實中看到的喵;如果給那張影象賦予鉛筆畫屬性,就得到了一隻“鉛筆喵”。喵~

影象翻譯是指影象內容從一個域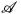 遷移到另一個域
遷移到另一個域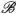 ,可以看成是影象移除一個域的屬性
,可以看成是影象移除一個域的屬性 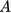 ,然後賦予另一個域的屬性
,然後賦予另一個域的屬性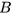 。我們用
。我們用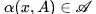 和
和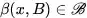 來表示域
來表示域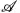 和域
和域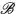 的影象,影象翻譯任務即可以定義為,尋找一個合適的變換
的影象,影象翻譯任務即可以定義為,尋找一個合適的變換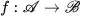 使得
使得
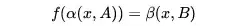
當然,還有一種影象翻譯,在翻譯的時候會把影象內容也換掉,下面介紹的方法也適用於這種翻譯,這種翻譯除了研究影象屬性的變化,還可以研究影象內容的變化,在這裡就不做討論了。
常見的GAN影象翻譯方法
下面簡單總結幾種GAN的影象翻譯方法。
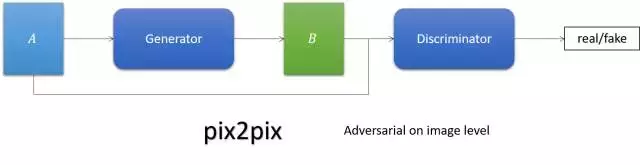
- pix2pix
簡單來說,它就是跟cGAN。Generator的輸入不再是noise,而是影象。
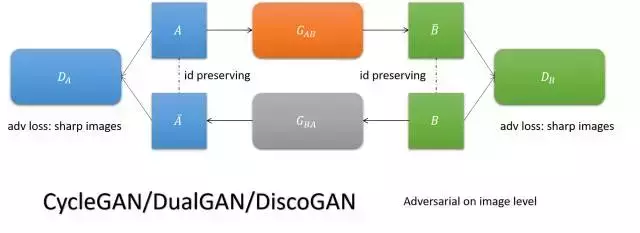
- CycleGAN/DualGAN/DiscoGAN
要求影象翻譯以後翻回來還是它自己,實現兩個域影象的互轉。
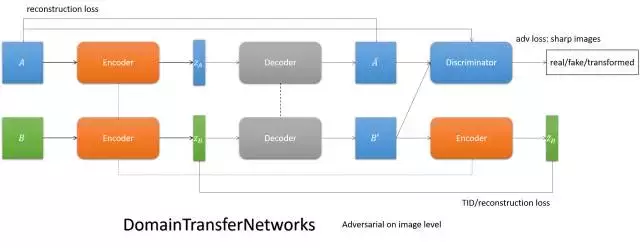
- DTN
用一個encoder實現兩個域的共性編碼,通過特定域的decoder解碼,實現影象翻譯。
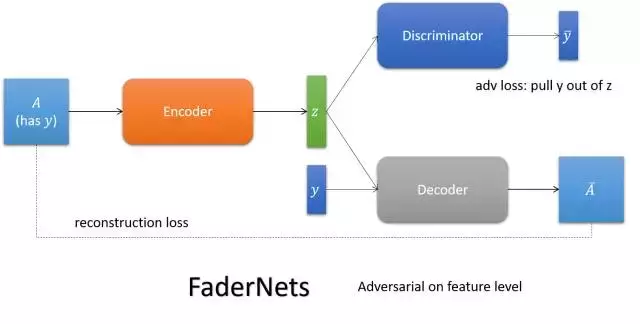
- FaderNets
用encoder編碼影象的內容,通過餵給它不同的屬性,得到內容的不同表達。
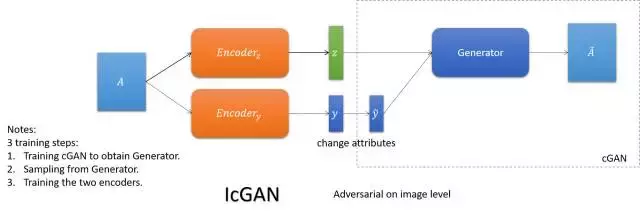
- IcGAN
依靠cGAN餵給它不同屬性得到不同表達的能力,學一個可逆的cGAN以實現圖想到影象的翻譯(傳統的cGAN是編碼+屬性到影象的翻譯)。
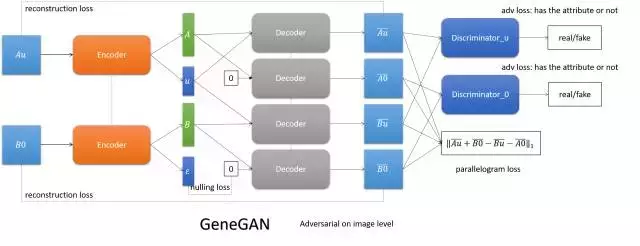
- GeneGAN
將影象編碼成內容和屬性,通過交換兩張圖的屬性,實現屬性的互轉。
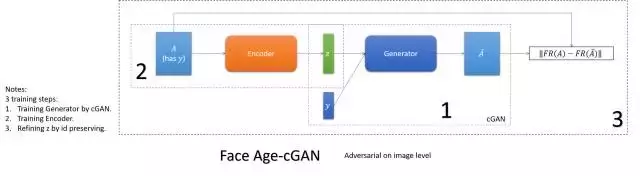
- Face Age-cGAN
這篇是做同個人不同年齡的翻譯。依靠cGAN餵給它不同屬性(年齡)得到不同年齡的影象的能力,學cGAN的逆變換以得到影象內容的編碼,再通過人臉識別系統糾正編碼,實現保id。
影象翻譯方法的完備性
我認為一個影象翻譯方法要取得成功,需要能夠保證下面兩個一致性(必要性):
- Content consistency(內容一致性)
- Domain consistency(論域一致性)
此外,我們也似乎也可以認為,滿足這兩點的影象翻譯方法是能work的(充分性)。
我把上述兩點稱為影象翻譯方法的完備性,換句話說,只要一個方法具備了上述兩個要求,它就應該能work。關於這個完備性的詳細論述,我會在以後給出。
下面,我們來看一下上述幾種方法是如何達成這兩個一致性的。
內容一致性
我把它們實現內容一致性的手段列在下面的表格裡了。

這裡有兩點需要指出。
其一,有兩個方法(IcGAN和Face Age-cGAN)依靠cGAN的能力,學cGAN的逆對映來實現影象換屬性,它們會有多個訓練階段,不是端到端訓練的方法。而cGAN訓練的好壞,以及逆對映的好壞對實驗結果影響會比較大,經過幾個階段的訓練,影象的內容損失會比較嚴重,實際中我們也可以觀察到 IcGAN 的實驗效果比較差。Face Age-cGAN通過引入人臉識別系統識別結果相同的約束,能夠對內容的編碼進行優化,可以起到一些緩解作用。
其二,DTN主要依靠TID loss來實現內容的一致性,而編碼一般來說是有損的,編碼相同只能在較大程度上保證內容相同。從DTN的emoji和人臉互轉的實驗我們也可以看出,emoji保id問題堪憂,參看下圖。

論域一致性
論域一致性是指,翻譯後的影象得是論域內的影象,也就是說,得有目標論域的共有屬性。用GAN實現的方法,很自然的一個實現論域一致性的方法就是,通過discriminator判斷影象是否屬於目標論域。
上述幾種影象翻譯的方法,它們實現論域一致性的手段可以分為兩種,參見下表。

此外,可以看到,FaderNets實現兩個一致性的方法都是剝離屬性和內容,而實現剝離手段則是對抗訓練。編碼層面的對抗訓練我認為博弈雙方不是勢均力敵,一方太容易贏得博弈,不難預料到它的訓練會比較tricky,訓練有效果應該不難達成,要想得到好的結果是比較難的。目前還沒有看到能夠完美復現的程式碼。文章的效果太好,好得甚至讓人懷疑。
最後的最後,放一個歌單,聽說聽這個歌單煉丹會更快哦。
參考文獻
1. Isola P, Zhu J Y, Zhou T, et al. Image-to-image translation with conditional adversarial networks[J]. arXiv preprint arXiv:1611.07004, 2016.
2. Zhu J Y, Park T, Isola P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks[J]. arXiv preprint arXiv:1703.10593, 2017.
3. Yi Z, Zhang H, Gong P T. DualGAN: Unsupervised Dual Learning for Image-to-Image Translation[J]. arXiv preprint arXiv:1704.02510, 2017.
4. Kim T, Cha M, Kim H, et al. Learning to discover cross-domain relations with generative adversarial networks[J]. arXiv preprint arXiv:1703.05192, 2017.
5. Taigman Y, Polyak A, Wolf L. Unsupervised cross-domain image generation[J]. arXiv preprint arXiv:1611.02200, 2016.
6. Zhou S, Xiao T, Yang Y, et al. GeneGAN: Learning Object Transfiguration and Attribute Subspace from Unpaired Data[J]. arXiv preprint arXiv:1705.04932, 2017.
7. Lample G, Zeghidour N, Usunier N, et al. Fader Networks: Manipulating Images by Sliding Attributes[J]. arXiv preprint arXiv:1706.00409, 2017.
8. Brock A, Lim T, Ritchie J M, et al. Neural photo editing with introspective adversarial networks[J]. arXiv preprint arXiv:1609.07093, 2016.
9. Antipov G, Baccouche M, Dugelay J L. Face Aging With Conditional Generative Adversarial Networks[J]. arXiv preprint arXiv:1702.01983, 2017.
10. Perarnau G, van de Weijer J, Raducanu B, et al. Invertible Conditional GANs for image editing[J]. arXiv preprint arXiv:1611.06355, 2016.