主要介紹了深度學習的訓練方法和技巧、深度學習的挑戰和應對方法等問題。文末,劉博士結合眼下AI的研究進展,對深度學習領域深刻的“吐槽”了一番,妙趣橫生且發人深省。
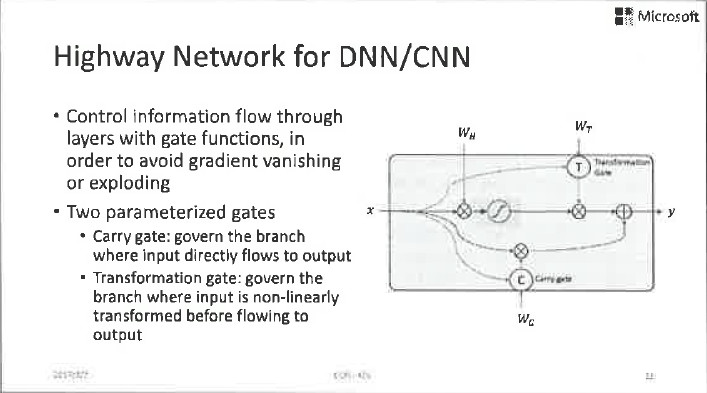
前面提到的BN方法還不能解決所有的問題。 因為即便做了白化,啟用函式的導數的最大值也只有0.25,如果層數成百上千,0.25不斷連乘以後,將很快衰減為0。所以後來又湧現出一些更加直接、更加有效的方法。其基本思路是在各層之間建立更暢通的渠道,讓資訊流繞過非線性的啟用函式。這類工作包含Highway Network、LSTM、ResNet等。
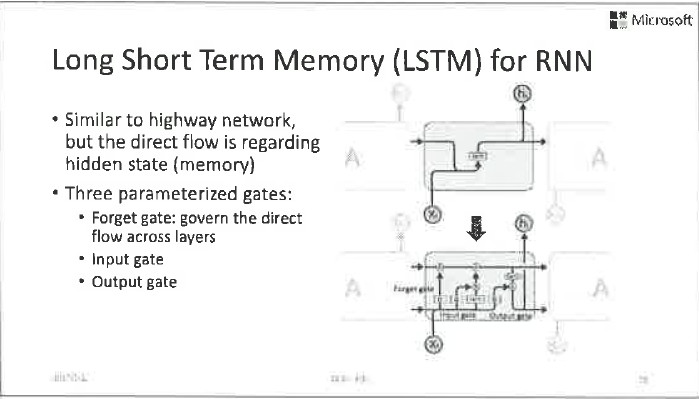
Highway Network和LSTM一脈相承,除了原來的非線性通路以外,增加了一個由閘電路控制的線性通路。兩個通路同時存在,而這兩個通路到底誰開啟或者多大程度開啟,由另外一個小的神經網路進行控制。
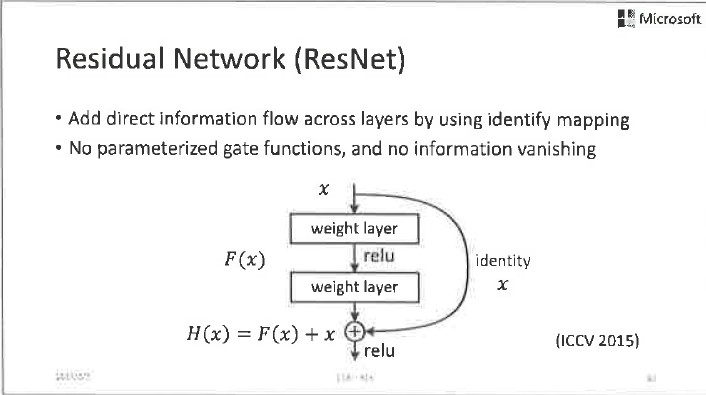
相比之下,ResNet的做法更加直接,它不用閘電路控制,而是直接增加總是開通的線性通路。雖然這些方法的操作方式不同,但是它們的基本出發點是一樣的,就是在一定程度上跳過非線性單元,以線性的方式把殘差傳遞下去,對神經網路模型的引數進行有效的學習。
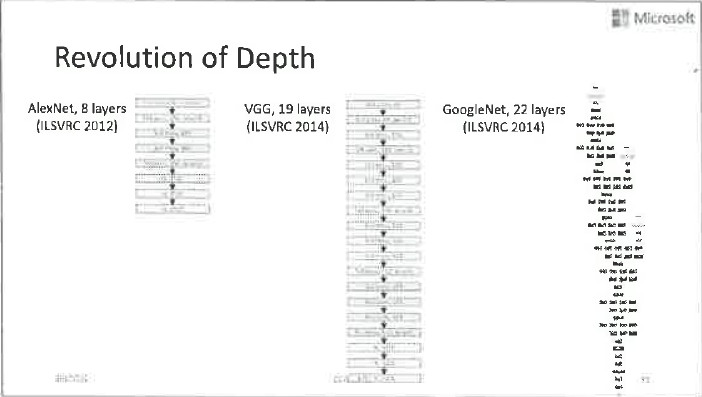
在前面提到的各項技術的幫助下,深層神經網路的訓練效果有了很大的提升。這張圖展示了網路不斷加深、效果不斷變好的歷史演變過程。2012年ImageNet比賽中脫穎而出的AlexNet只有8層,後來變成19層、22層,到2015年,ResNet以152層的複雜姿態出場,贏得了ImageNet比賽的冠軍。
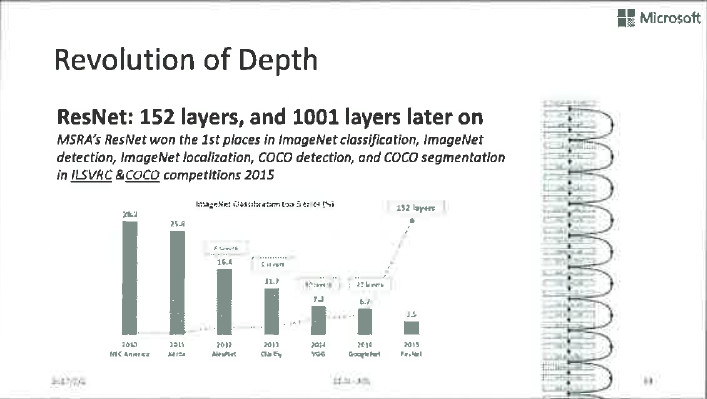
從這張圖上可以看出,隨著層數的不斷變深,影像的識別錯誤率不斷下降,由此看來,網路變深還是很有價值的。
到此為止,我們把深度學習及其訓練方法和技巧給大家做了一個非常簡短的介紹。
深度學習的挑戰
接下來我們進入下一個主題:深度學習的挑戰和機遇。很多人都在討論為什麼深度學習會成功,說起來無外乎來源於機器學習優化過程的三個方面。
基本上所有的有監督機器學習都是在最小化所謂的經驗風險。在這個最小化的式子裡包含以下幾個元素:
一個是資料:X是資料的輸入、Y是資料的標籤;
二是模型,用f表示(L是loss function);
三是針對f的尋優過程。
首先對資料X、Y而言,深度學習通常會利用非常大量的資料進行訓練。舉個例子,機器翻譯的訓練資料通常包含上千萬個雙語句對,語音識別常常使用幾千或者上萬個小時的標註資料,而影像,則會用到幾百萬甚至幾千萬張有標籤的影像進行訓練。前面還提到了下圍棋的AlphaGo,它使用了3千萬個棋局進行訓練。可以這麼說,現在主流的深度學習系統動輒就會用到千萬量級的有標籤訓練資料。這對於十幾年前的機器學習領域是無法想象的。
其次,深度學習通常會使用層次很深、引數眾多的大模型。很多應用級的深層神經網路會包含十億或者更多的引數。使用如此大的模型,其好處是可以具備非常強的逼近能力,因此可以解決以往淺層機器學習無法解決的難題。
當然當我們有那麼大的資料、那麼大的模型,就不得不使用一個計算機叢集來進行優化,所以GPU叢集的出現成為了深度學習成功的第三個推手。
成也蕭何敗也蕭何,深度學習受益於大資料、大模型、和基於計算機叢集的龐大計算能力,但這些方面對於普通的研究人員而言,都蘊含著巨大的挑戰。我們今天要探討的是如何解決這些挑戰。
首先,讓我們來看看大資料。即便在語音、影像、機器翻譯等領域我們可以收集到足夠的訓練資料,在其他的一些領域,想要收集到千萬量級的訓練資料卻可能是mission impossible。比如在醫療行業,有些疑難雜症本身的樣例就很少,想要獲取大資料也無從下手。在其他一些領域,雖然有可能獲取大資料,但是代價昂貴,可能要花上億的成本。那麼對於這些領域,在沒有大的標註資料的情況下,我們還能使用深度學習嗎?
其次,在很多情況下,模型如果太大會超出計算資源的容量。比如,簡單計算一下要在10億量級的網頁上訓練一個基於迴圈神經網路的語言模型,其模型尺寸會在100GB的量級。這會遠遠超過主流GPU卡的容量。這時候可能就必須使用多卡的模型並行,這會帶了很多額外的通訊代價,無法實現預期的加速比。(GPU很有意思,如果模型能塞進一張卡,它的運算並行度很高,訓練很快。可一旦模型放不進一張卡,需要通過PCI-E去訪問遠端的模型,則GPU的吞吐量會被拖垮,訓練速度大打折扣。)
最後,即便有一些公司擁有強大的計算資源,同時排程幾千塊GPU來進行計算不成問題,也並表示這樣可以取得預期的加速比。如果這些GPU卡之間互相等待、內耗,則可能被最慢的GPU拖住,只達到了很小的加速比,得不償失。如何保證取得線性或者準線性加速比,並且還不損失模型訓練的精度,這是一個重要且困難的研究問題。
深度學習“大”挑戰的應對策略

接下來我會介紹我們研究組是如何解決前面提到的有關大資料、大模型、大規模訓練的技術挑戰的。為此,我會簡要介紹我們最近從事的三項研究工作:
一個對偶學習Dual Learning;
二是輕量級演算法LightRNN;
三是Delay-Compensated ASGD。
對偶學習Dual Learning

對偶學習是我們去年年底發表在NIPS(NIPS是機器學習領域最頂級的學術會議)上的一篇論文,發表之後收到了很大的反響。這個論文提出了一個聽起來很簡單的思路,有效地解決了缺乏有標籤訓練資料的問題。那我們是如何做到這一點的呢?

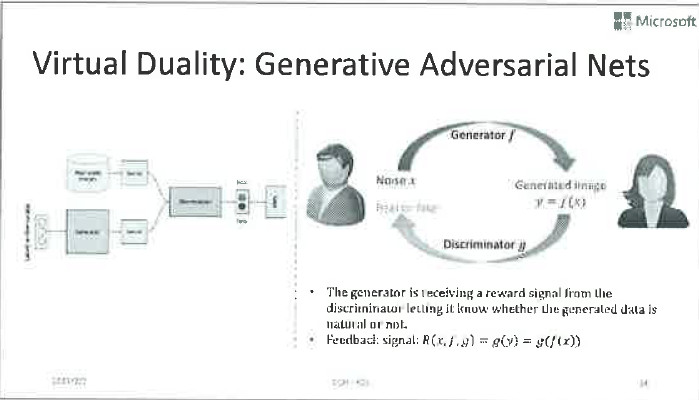
我們的基本思路是在沒有人工標註資料的情況下,利用其它的結構資訊,建立一個閉環系統,利用該系統中的反饋訊號,實現有效的模型訓練。這裡提到的結構資訊,其實是人工智慧任務的對偶性。
什麼是人工智慧任務的對偶性呢?讓我們來看幾個例子。比如機器翻譯,我們關心中文到英文的翻譯,同時也關心從英文到中文的翻譯。比如語音方面,我們關心語音識別,同時也關心語音合成。同樣,我們關心影像分類,也關心影像生成。如此這般,我們發現,很多人工智慧任務都存在一個有意義的相反的任務。能不能利用這種對偶性,讓兩個任務之間互相提供反饋訊號,把深度學習模型訓練出來呢?
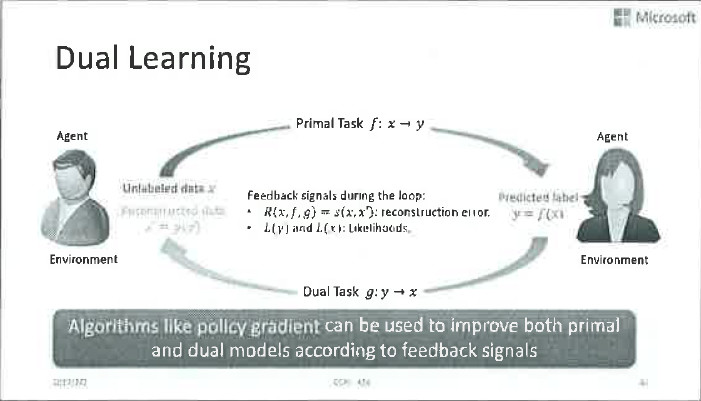
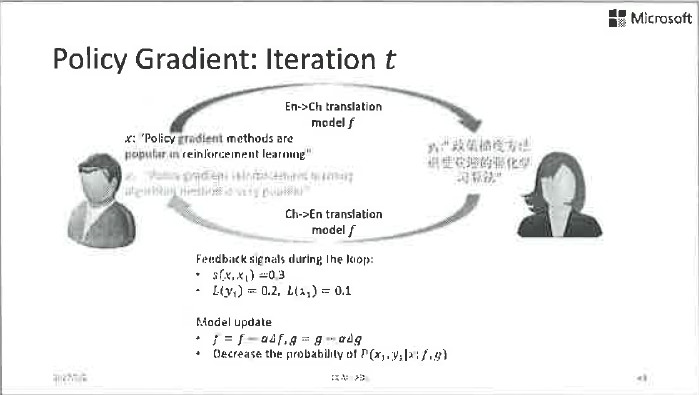
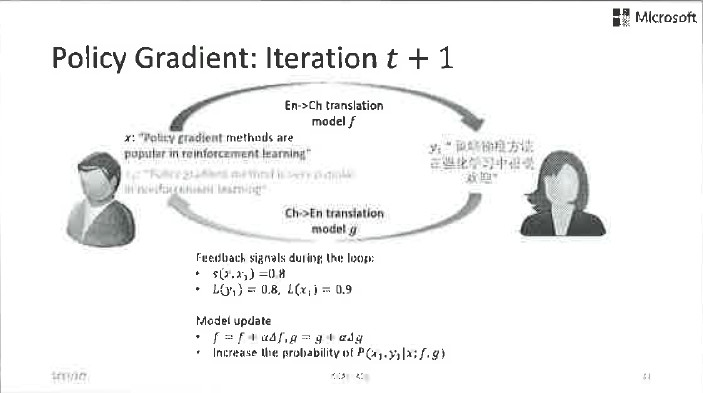
這是完全可行的。舉一個簡單的例子,比如左邊的Agent很懂中文,並且想把中文翻譯成英文,他有一點關於英文的基礎知識,換句話說他擁有一箇中到英翻譯的弱模型。右邊這個agent則相反,他精通英文並想把英文翻譯成中文,但只擁有一個英到中翻譯的弱模型。
現在左邊的agent拿到了一箇中文句子,用他的弱模型將其翻譯成了英文,丟給右邊的agent。右邊的agent做的第一判斷是她收到的句子是否是個合理的英文句子?如果從英文語法的角度看,這個句子亂七八糟的看不懂,她就會給出一個負反饋訊號:之前的中到英的翻譯肯定出錯了。如果這個句子從語法上來看沒啥問題,她就會用自己的弱翻譯模型將其翻譯回中文,並且傳給左邊的agent。同樣,左邊的agent可以通過語法判斷這個翻譯是否靠譜,也可以通過這個翻譯回來的句子和原本的中文句子的比較來給出進一步的反饋訊號。雙方可以通過這些反饋訊號來更新模型引數。這就是對偶學習,是不是特別簡單?
這個過程聽起來簡單,但真正做起來不那麼容易。因為這個閉環中很多的反饋訊號都是離散的,不容易通過求導的方式加以利用,我們需要用到類似強化學習中Policy Gradient這樣的方法實現模型引數的優化。我們把對偶學習應用在機器翻譯中,在標準的測試資料上取得了非常好的效果。我們從一個只用10%的雙語資料訓練出的弱模型出發,通過無標籤的單語資料和對偶學習技術,最終超過了利用100%雙語資料訓練出的強模型。


除了前面提到的機器翻譯的例子,還有很多對偶學習的例子:比如說語音訊號處理、影像訊號處理、對話等等,都可以做對偶學習。這幾張PPT分別展示了在這些應用裡如何定義反饋訊號,實現有效的引數優化。
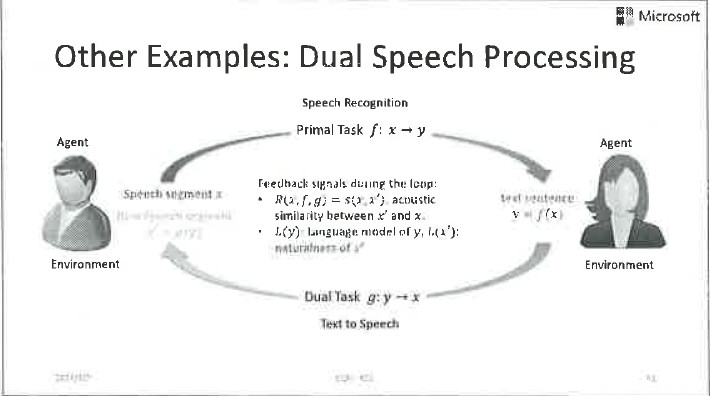
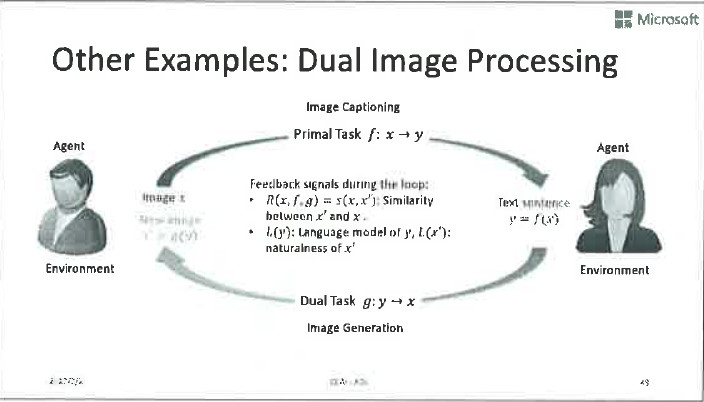
其實人工智慧任務的對偶性是非常本質的,用好了在很多地方都會取得意想不到的結果。它不僅可以幫助我們把無標籤資料用起來,還可以顯著地提高有標籤資料的學習效果。接下來我們將會展示對偶學習的各種擴充套件應用。
首先,有人可能會問,你舉的這些例子裡確實存在天然的對偶性,可以也有些任務並沒有這種天然的對偶性,那能不能使用對偶學習技術來改善它們呢?答案是肯定的。如果沒有天然的對偶性,我們可以通過類似“畫輔助線”的方法,構建一個虛擬的對偶任務。只不過在完成對偶學習之後,我們僅僅使用主任務的模型罷了。大家可能也聽過這幾年很火的GAN(Generative Adversarial Nets),它就可以看做一種虛擬的對偶學習。
其次,還有人可能會問,對偶學習主要是解決無標籤資料的學習問題,那我如果只關心有監督的學習問題,這個結構對偶性還有幫助嗎?答案也是肯定的。
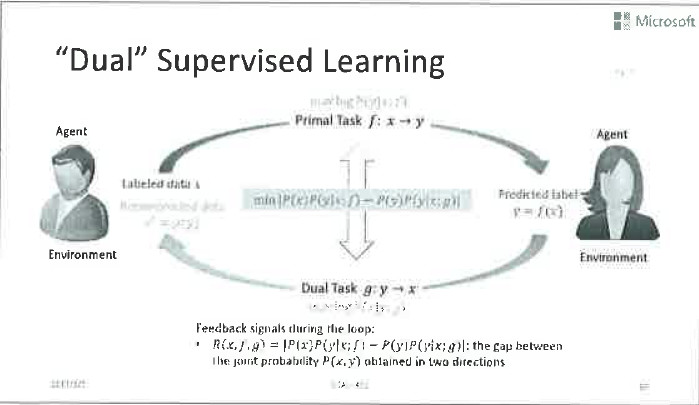
以前人們在訓練一對對偶任務的時候,通常是獨立進行的,也就是各自利用自己的訓練資料來訓練,沒有在訓練過程考慮到還存在另一個有結構關係的訓練任務存在。其實,這兩個訓練任務是存在深層次內在聯絡的。大家學過機器學習原理的話,就知道我們訓練的分類模型其實是去逼近條件概率P(Y X)。那麼一對對偶任務的模型分別逼近的是P(Y X)和P(X Y)。他們之間是有數學聯絡的:P(X)P(Y X)=P(Y)P(X Y)。其中的先驗分佈P(X)和P(Y)可以很容易通過無標籤資料獲得。
因此,我們在訓練兩個模型的時候,如果由他們算出的聯合概率不相等的話,就說明模型訓練還不充分。換言之,前面的等式可以作為兩個對偶任務訓練的正則項使用,提高演算法的泛化能力,在未知的測試集上取得更好的分類效果。
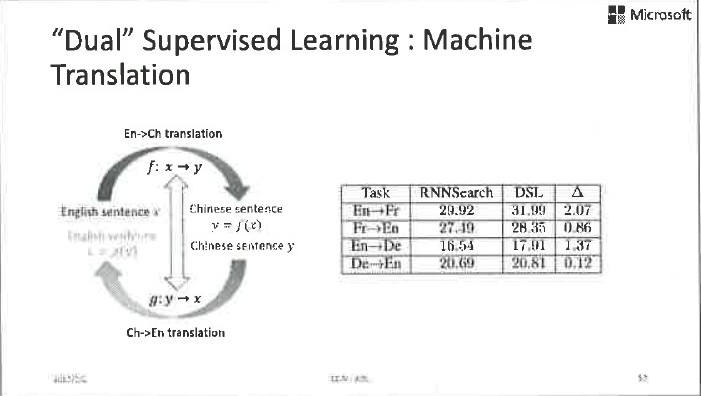
我們把這個正則項應用到機器翻譯中,再次取得了明顯的提升,從英法互譯的資料上看,BLEU score提高了2個點。
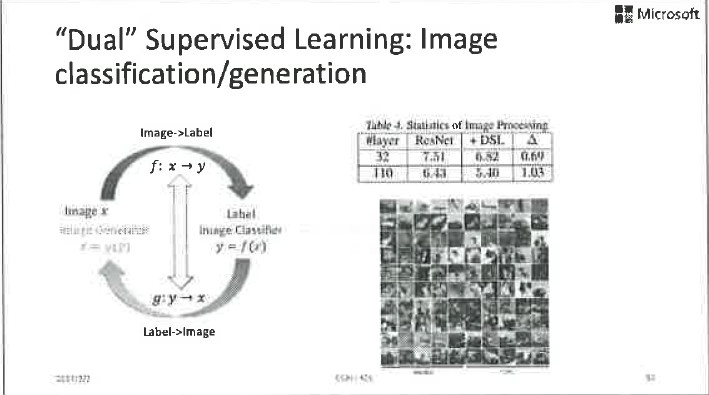
同樣,加入這個正則項,在影像分類、影像生成、情感分類、情感生成等方面都取得了很好的效果。我們舉個例子,傳統技術在做情感生成的時候,出來的語句是似然比較大的句子,通常是訓練資料裡最多出現的詞語和句式。而引入了情感分類的對偶正則項,生成的句子就會更多地包含那些明顯攜帶感情色彩的詞語。這樣生成的句子就會既有內容、又有情感,效果更好。

第三,或許有人還可能會問:如果我無法改變模型訓練的過程,別人已經幫我訓練好了兩個模型,對偶性還能幫我改善推斷的過程嗎?答案還是肯定的。假設我們之前已經獨立地訓練了兩個模型,一個叫f,一個叫g(比如f是做語音識別的,g是做語音合成的),現在要用他們來做inference。這個時候,其實前面說的概率約束還在。我們可以通過貝葉斯公式,把兩個對偶任務的模型聯絡起來,實現共同的推斷。具體細節如圖所示。我們做了大量實驗,效果非常好。比如在機器翻譯方面,聯合推斷又會帶來幾個點的BLEU score的提升。
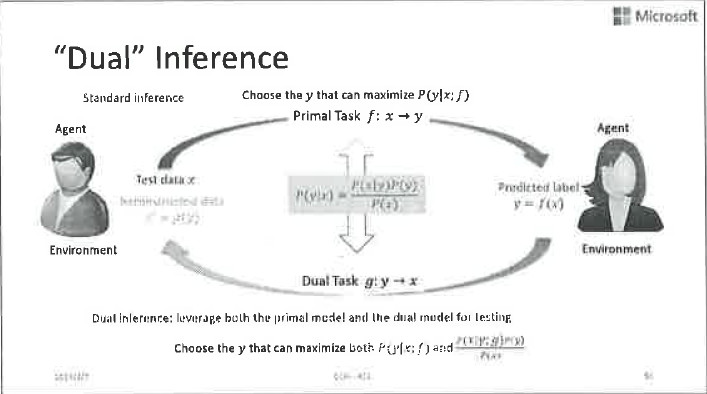

總結一下,我們認為對偶學習是一個新的學習正規化,它和co-training、Transfer learning等既有聯絡又有區別。它開啟了看待人工智慧任務的新視角,應用價值遠遠不止前面的具體介紹,如果大家有興趣可以跟我們一起挖掘。
輕量級演算法LightRNN
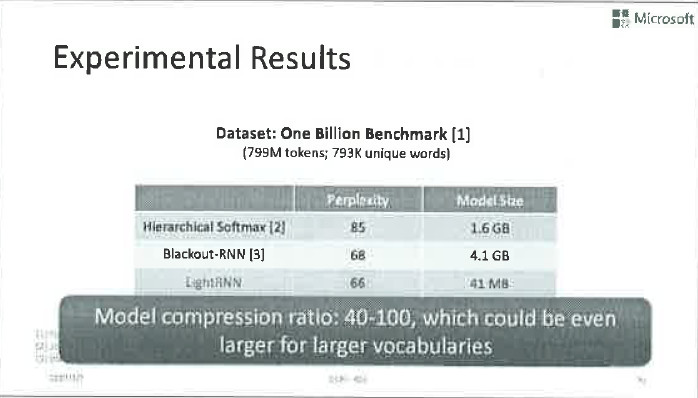
接下來,我們來討論一下如何處理大模型的挑戰。舉個例子,假設我們要利用clueweb這樣的網際網路資料集來訓練語言模型。這種大資料集通常有千萬量級的詞表,其中包含很多生僻的人名、地名、公司名,新詞、衍生詞、甚至是使用者輸入的錯詞。如果使用前面提到的迴圈神經網路來訓練語言模型,經過非常簡單的運算就可以得出,其模型規模大約80G,也就是說你需要有80G的記憶體才能放下這個RNN模型,這對於CPU不是什麼問題,但是對GPU而言就是非常大的挑戰了,主流的GPU只有十幾二十G的記憶體,根本放不下這麼大的模型。 就算真的可以,以目前主流GPU的運算速度,也要將近200年才能完成訓練。

那這個問題怎麼解決呢?接下來我們要介紹的LightRNN演算法是一種解決的辦法,我相信還有很多別的方法,但是這個方法很有啟發意義。它的具體思路是什麼呢?首先,讓我們來看看為什麼模型會那麼大,其主要原因是我們假設每個詞都是相互獨立的,因而如果有1千萬個詞,就會訓練出1千萬個向量引數來。顯然這種假設是不正確的,怎麼可能這1千萬個詞之間沒有關係呢?如果我們打破這個假設,試圖在學習過程中發現詞彙之間的相關性,就可能極大地壓縮模型規模。特別地,我們用2個向量來表達每個詞彙,但是強制某些詞共享其中的一個分量,這樣雖然還是有那麼多詞彙,我們卻不需要那麼多的向量來進行表達,因此可以縮小模型尺寸。

具體而言,我們建立了一張對映表,在這張表裡面每一個詞對應兩個引數向量(x和y),表裡所有同一行的詞共享x,所有同一列的詞共享y。相應地,我們需要把RNN的結構做一些調整,如下圖所示。
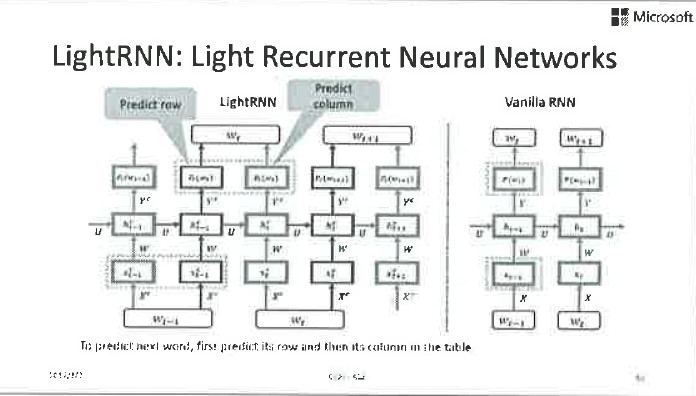
這樣我們就可以把一個80G的模型,壓縮到只有50M那麼大。這麼小的模型,不僅訓練起來很快,還可以隨便塞到移動終端裡,實現高效的inference。
那麼有人會問了,前面的LightRNN演算法嚴重依賴於這個二維對映表,可是怎麼才能構建出一個合理的表格,使得有聯絡的詞共享引數,沒有聯絡的詞就不共享引數呢?其實這是一個經典的問題。假設我給每個詞都已經有一個參數列達,x、y已經有了,就可以通過求解一個最優二分圖匹配的問題實現二維對映表的構造。而一旦有了對映表,我們又可以通過RNN的訓練更新參數列達。這是一個迴圈往復的過程,最終收斂的時候,我們不但有了好的對映表,也有了好的引數模型。

我們在標準資料集上測試了LightRNN演算法。神奇的是,雖然模型變小了,語言模型的Perplexity竟然變好了。這個效果其實有點出乎我們的預期,但是卻也在情理之中。因為LightRNN打破了傳統RNN關於每個詞都是獨立的假設,主動挖掘了詞彙之間的語義相似性,因此會學到更加有意義的模型引數。這對inference是很有幫助的。
其實LightRNN的思想遠遠超過語音模型本身,機器翻譯裡、文字分類裡難道就沒有這個問題嗎?這個技術可以推廣到幾乎所有文字上的應用問題。甚至,除了文字以外,它還可以用來解決大規模影像分類的問題。只要模型的輸出層特別大,而且這些輸出類別存在某些內在的聯絡,都可以採用LightRNN的技術對模型進行簡化,對訓練過程進行加速。


除此之外,模型變小了,對分散式訓練也很有意義。分散式運算的時候,各個worker machine之間通常要傳遞模型或者模型梯度。當模型比較小的時候,這種傳輸的通訊代價就比較小,分散式訓練就 比較容易取得較高的加速比。
Delay-Compensated ASGD

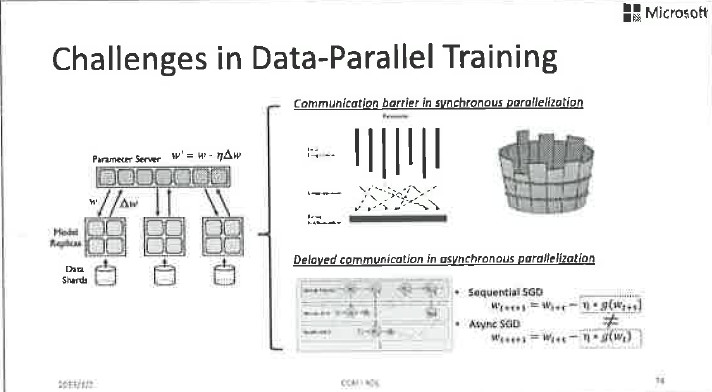
說到分散式訓練,我們順便就講講第三個挑戰。我們這裡討論的主要是資料並行,也就是資料太多了,一臺機器或者放不下、或者訓練速度太慢。假設我們把這些資料分成N份,每份放在一臺機器上,然後各自在本地計算,一段時間以後把本地的運算結果和引數伺服器同步一下,然後再繼續本地的運算,這就是最基本的資料並行的模式。
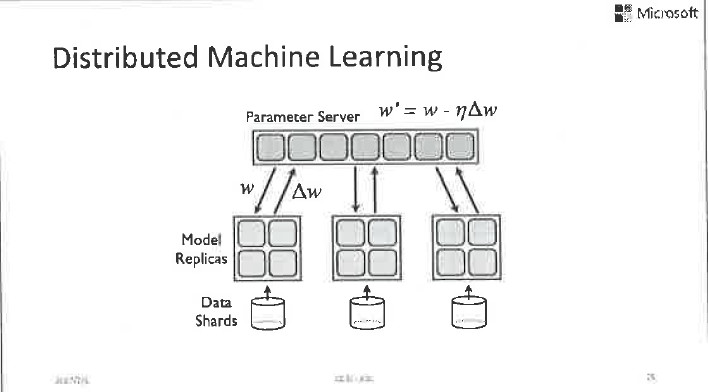
資料並行模式有兩個常用的做法:
一是同步;
二是非同步。
同步並行指的是本地將模型更新後發給引數伺服器,然後進入等待狀態。直到所有模型更新都發到引數伺服器以後,引數伺服器將模型進行平均和回傳,大家再各自以平均模型為起點,進行下一輪的本地訓練。這個過程是完全可控的,而且在數學上是可以清晰描述的。但是,它的問題是由於互相等待,整個系統的速度會被最慢的機器拖垮。雖然使用了很多機器一起進行並行運算,但通常無法達到很高的加速比。為了解決這個問題,非同步並行被大量使用。
所謂非同步並行指的是,本地機器各自進行自己的訓練工作,一段時間以後將模型更新推送到引數伺服器上,然後並不等待其他機器,而是把當前引數伺服器上的全域性模型拿下來,以此為起點馬上進行下一輪的本地訓練。這個過程的好處就是快,因為各個機器之間不需要互相等待,但是訓練過程在數學上的描述是不清晰的,因為包含很多亂序更新,它和單機序列訓練的過程相去甚遠,所以訓練的結果沒有很好的理論保證,會受到各個機器之間速度差的影響。我們用延遲來描述這種速度差。具體來說,假設我們一共有10臺機器參與運算,對於其中的一臺機器,當我從引數伺服器上取得一個模型,並且根據本地資料求出模型梯度以後,在我打算將這個梯度回傳給引數伺服器之前,可能其他的機器已經把他們的模型梯度推送給了引數伺服器,也就是說引數伺服器上的全域性模型可能已經發生了多次版本變化。那麼我推送上去的模型梯度就不再適用了,因為它對應於一箇舊模型,我們稱之為延遲的梯度。當延遲的梯度被加到全域性模型以後,可能毀掉全域性模型,因為它已經違背了梯度下降的基本數學定義,因此收斂性沒法得到很好的保障。

為了解決這個問題,人們使用了很多手段,包括SSP、AdaDelay等等。他們或者強制要求跑的快的機器停下來等待比較慢的機器,或者給延遲的梯度一個較小的學習率。


也有人證明其實這個延遲和Momentum有某種關係,只需要調整momentum的係數就可以平衡這個延遲。這些工作都很有意義,但是他們並沒有非常正面地分析延遲的來源,並且針對性地解決延遲的問題。

我們研究組對這麼問題進行了正面的回答。其實這個事說起來也很簡單。

大家想想,我們本來應該加上這個梯度才是標準的梯度下降法,可是因為延遲的存在,我們加卻把t時刻的梯度加到了t+τ時刻的模型上去。正確梯度和延遲梯度的關係可以用泰勒展開來進行刻畫:它們之間的差別就是這些一階、二階、和高階項。如果我們能把這些項有效地利用起來,就可以把延遲補償掉。這事看起來好像簡單,做起來卻不容易。
首先,泰勒展開在什麼時候有意義呢?Wt和Wt+τ距離不能太遠,如果相差太遠,那些高階項就不是小量,有限泰勒展開就不準了。這決定了在訓練的哪個階段使用這項技術:在訓練的後半程,當模型快要收斂,學習率較小的時候,可以保證每次模型變化不太大,從而安全地使用泰勒展開。
其次,即便是多加上一個一階項,運算量也是很大的。因為梯度函式的一階導數對應於原目標函式的二階導數,也就是對應於海森陣。我們知道海森陣計算和儲存的複雜度都很高,在模型很大的時候,實操性不強。
那麼怎麼解決這個挑戰呢?我們證明了一個定理,在特定情況下,Hessen陣可以幾乎0代價地計算出來,而且近似損失非常之小。具體而言,我們證明了對於一些特定的損失函式(負對數似然的形式),二階導可以被一階導的外積進行無偏估計。無偏估計雖然均值相同,方差可能仍然很大,為了進一步提升近似效果,我們通過最小化MSE來控制方差。做完之後我們就得到了一個新的公式,這個公式除了以前的非同步的梯度下降以外還多引入一項,其中包含一個神奇的Φ函式和λ因子,只要通過調節他們就可以有效的補償延遲。
在此基礎上,我們進一步證明,使用延遲補償的非同步並行演算法可以取得更好的收斂性質,其對延遲的敏感性大大降低。

這一點被我們所做的大量實驗驗證。實驗表明,我們不僅可以取得線性加速比,還能達到幾乎和單機序列演算法一樣的精度。

到這兒為止我們針對大資料、大模型、大計算的挑戰,分別討論了相應的技術解決方案。

如果大家對這些研究工作感興趣,可以看一下我們的論文,也歡迎大家使用微軟的開源工具包CNTK和DMTK,其中已經包含了我們很多的研究工作。


在報告的最後,和大家聊點開腦洞的話題。這幾張PPT是中文的,其實是我之前在一次報告中和大家分享的關於AI的觀點時使用的。其中前三個觀點已經在今天的講座中提到了。我們再來看看後面幾條:
首先是關於深度學習的調參問題。現在深度學習技術非常依賴於調參黑科技。即便是公開的演算法,甚至開源的程式碼,也很難實現完美復現,因為其背後的調參方法通常不會公開。那麼,是否可以用更牛的黑科技來解決這個調參黑科技的問題呢?這幾年炒的很火的Learning to Learn技術,正是為了實現這個目的。大家可以關注一下這個方向。

其次,深度學習是個黑箱方法。很多人都在吐槽,雖然效果很好,就是不知道為什麼,這使得很多敏感行業不敢用,比如醫療、軍工等等。怎樣才能讓這個黑盒子變灰甚至變白呢?我們組目前在從事一項研究,試圖把符號邏輯和深度學習進行深度整合,為此開發了一個新系統叫graph machine,今年晚些時候可能會開源,到時候大家就可以進一步瞭解我們的具體做法。

最後,我來吐槽一下整個深度學習領域吧 :).
我覺得現在所謂的AI其實不配叫做 Artificial Intelligence,更像是animal Intelligence。因為它不夠智慧,它解決的絕大部分問題都是動物智慧做的事情。關鍵原因是,它沒有抓到人和動物的關鍵差別。人和動物的差別是腦容量的大小嗎?是大資料、大計算、大模型能解決的嗎?我個人並不這樣認為。我覺得人和動物主要的差別是在於人是社會動物,人有一套非常有效的機制,使人變得越來越聰明。
我給大家舉個簡單的例子,雖然動物也會通過強化學習適應世界,學得一身本事。但是,一旦成年動物死掉,他們積累的技能就隨之消失,幼崽需要從頭再來,他們的智慧進化就被複位了。而人則完全不同,我們人會總結知識,通過文字記錄知識、傳承知識;人有學校,有教育體系(teaching system),可以在短短十幾年的時間裡教會自己的孩子上下五千年人類積累的知識。所以說,我們的智慧進化過程從未復位,而是站在前人的肩膀上繼續增長。這一點秒殺一切動物,並且使得人類的智慧越來越強大,從而成為了萬物之靈。
可是現在的人工智慧研究並沒有對這些關鍵的機制進行分析和模擬。我們有deep learning,但是沒有人研究deep teaching。所以我才說現在的人工智慧技術是南轅北轍,做來做去還是動物智慧,只有意識到人和動物的差別才能有所突破。或許,Deep Teaching才是人工智慧的下一個春天。
前面這些思考引導我在微軟亞洲研究院組織研究專案的時候進行合理的佈局,比如我們正在從事著對偶學習,Light machine learning,符號學習,分散式學習、群體學習等研究工作。我們拒絕跟風,而是追隨內心對人工智慧的認識不斷前行。今天的講座目的不僅是教會大家瞭解什麼是深度學習,更重要的是啟發大家一起努力,把人工智慧這個領域、深度學習這個領域推向新的高度,為人工智慧的發展做出我們中國人獨特的貢獻!
【 摘自:AI科技評論