相信有過開發經驗的朋友都曾碰到過這樣一個需求。假設你正在為一個新聞網站開發一個評論功能,讀者可以評論原文甚至相互回覆。
這個需求並不簡單,相互回覆會導致無限多的分支,無限多的祖先-後代關係。這是一種典型的遞迴關係資料。
對於這個問題,以下給出幾個解決方案,各位客觀可斟酌後選擇。
一、鄰接表:依賴父節點
鄰接表的方案如下(僅僅說明問題):
CREATE TABLE Comments( CommentId int PK, ParentId int, --記錄父節點 ArticleId int, CommentBody nvarchar(500), FOREIGN KEY (ParentId) REFERENCES Comments(CommentId) --自連線,主鍵外來鍵都在自己表內 FOREIGN KEY (ArticleId) REFERENCES Articles(ArticleId) )
由於偷懶,所以採用了書本中的圖了,Bugs就是Articles:

這種設計方式就叫做鄰接表。這可能是儲存分層結構資料中最普通的方案了。
下面給出一些資料來顯示一下評論表中的分層結構資料。示例表:

圖片說明儲存結構:

鄰接表的優缺分析
對於以上鄰接表,很多程式設計師已經將其當成預設的解決方案了,但即便是這樣,但它在從前還是有存在的問題的。
分析1:查詢一個節點的所有後代(求子樹)怎麼查呢?
我們先看看以前查詢兩層的資料的SQL語句:
SELECT c1.*,c2.* FROM Comments c1 LEFT OUTER JOIN Comments2 c2 ON c2.ParentId = c1.CommentId
顯然,每需要查多一層,就需要聯結多一次表。SQL查詢的聯結次數是有限的,因此不能無限深的獲取所有的後代。而且,這種這樣聯結,執行Count()這樣的聚合函式也相當困難。
說了是以前了,現在什麼時代了,在SQLServer 2005之後,一個公用表表示式就搞定了,順帶解決的還有聚合函式的問題(聚合函式如Count()也能夠簡單實用),例如查詢評論4的所有子節點:
WITH COMMENT_CTE(CommentId,ParentId,CommentBody,tLevel) AS ( --基本語句 SELECT CommentId,ParentId,CommentBody,0 AS tLevel FROM Comment WHERE ParentId = 4 UNION ALL --遞迴語句 SELECT c.CommentId,c.ParentId,c.CommentBody,ce.tLevel + 1 FROM Comment AS c INNER JOIN COMMENT_CTE AS ce --遞迴查詢 ON c.ParentId = ce.CommentId ) SELECT * FROM COMMENT_CTE
顯示結果如下:

那麼查詢祖先節點樹又如何查呢?例如查節點6的所有祖先節點:
WITH COMMENT_CTE(CommentId,ParentId,CommentBody,tLevel) AS ( --基本語句 SELECT CommentId,ParentId,CommentBody,0 AS tLevel FROM Comment WHERE CommentId = 6 UNION ALL SELECT c.CommentId,c.ParentId,c.CommentBody,ce.tLevel - 1 FROM Comment AS c INNER JOIN COMMENT_CTE AS ce --遞迴查詢 ON ce.ParentId = c.CommentId where ce.CommentId <> ce.ParentId ) SELECT * FROM COMMENT_CTE ORDER BY CommentId ASC
結果如下:

再者,由於公用表表示式能夠控制遞迴的深度,因此,你可以簡單獲得任意層級的子樹。
OPTION(MAXRECURSION 2)
看來哥是為鄰接表平反來的。
分析2:當然,鄰接表也有其優點的,例如要新增一條記錄是非常方便的。
INSERT INTO Comment(ArticleId,ParentId)... --僅僅需要提供父節點Id就能夠新增了。
分析3:修改一個節點位置或一個子樹的位置也是很簡單.
UPDATE Comment SET ParentId = 10 WHERE CommentId = 6 --僅僅修改一個節點的ParentId,其後面的子代節點自動合理。
分析4:刪除子樹
想象一下,如果你刪除了一箇中間節點,那麼該節點的子節點怎麼辦(它們的父節點是誰),因此如果你要刪除一箇中間節點,那麼不得不查詢到所有的後代,先將其刪除,然後才能刪除該中間節點。
當然這也能通過一個ON DELETE CASCADE級聯刪除的外來鍵約束來自動完成這個過程。
分析5:刪除中間節點,並提升子節點
面對提升子節點,我們要先修改該中間節點的直接子節點的ParentId,然後才能刪除該節點:
SELECT ParentId FROM Comments WHERE CommentId = 6; --搜尋要刪除節點的父節點,假設返回4 UPDATE Comments SET ParentId = 4 WHERE ParentId = 6; --修改該中間節點的子節點的ParentId為要刪除中間節點的ParentId DELETE FROM Comments WHERE CommentId = 6; --終於可以刪除該中間節點了
由上面的分析可以看到,鄰接表基本上已經是很強大的了。
二、路徑列舉
路徑列舉的設計是指通過將所有祖先的資訊聯合成一個字串,並儲存為每個節點的一個屬性。
路徑列舉是一個由連續的直接層級關係組成的完整路徑。如"/home/account/login",其中home是account的直接父親,這也就意味著home是login的祖先。
還是有剛才新聞評論的例子,我們用路徑列舉的方式來代替鄰接表的設計:
CREATE TABLE Comments( CommentId int PK, Path varchar(100), --僅僅改變了該欄位和刪除了外來鍵 ArticleId int, CommentBody nvarchar(500), FOREIGN KEY (ArticleId) REFERENCES Articles(ArticleId) )
簡略說明問題的資料表如下:
CommentId Path CommentBody
1 1/ 這個Bug的成因是什麼
2 1/2/ 我覺得是一個空指標
3 1/2/3 不是,我查過了
4 1/4/ 我們需要查無效的輸入
5 1/4/5/ 是的,那是個問題
6 1/4/6/ 好,查一下吧。
7 1/4/6/7/ 解決了
路徑列舉的優點:
對於以上表,假設我們需要查詢某個節點的全部祖先,SQL語句可以這樣寫(假設查詢7的所有祖先節點):
SELECT * FROM Comment AS c WHERE '1/4/6/7/' LIKE c.path + '%'
結果如下:

假設我們要查詢某個節點的全部後代,假設為4的後代:
SELECT * FROM Comment AS c WHERE c.Path LIKE '1/4/%'
結果如下:

一旦我們可以很簡單地獲取一個子樹或者從子孫節點到祖先節點的路徑,就可以很簡單地實現更多查詢,比如計算一個字數所有節點的數量(COUNT聚合函式)

插入一個節點也可以像和使用鄰接表一樣地簡單。可以插入一個葉子節點而不用修改任何其他的行。你所需要做的只是複製一份要插入節點的邏輯上的父親節點路徑,並將這個新節點的Id追加到路徑末尾就可以了。如果這個Id是插入時由資料庫生成的,你可能需要先插入這條記錄,然後獲取這條記錄的Id,並更新它的路徑。
路徑列舉的缺點:
1、資料庫不能確保路徑的格式總是正確或者路徑中的節點確實存在(中間節點被刪除的情況,沒外來鍵約束)。
2、要依賴高階程式來維護路徑中的字串,並且驗證字串的正確性的開銷很大。
3、VARCHAR的長度很難確定。無論VARCHAR的長度設為多大,都存在不能夠無限擴充套件的情況。
路徑列舉的設計方式能夠很方便地根據節點的層級排序,因為路徑中分隔兩邊的節點間的距離永遠是1,因此通過比較字串長度就能知道層級的深淺。
三、巢狀集
巢狀集解決方案是儲存子孫節點的資訊,而不是節點的直接祖先。我們使用兩個數字來編碼每個節點,表示這個資訊。可以將這兩個數字稱為nsleft和nsright。
還是以上面的新聞-評論作為例子,對於巢狀集的方式表可以設計為:
CREATE TABLE Comments( CommentId int PK, nsleft int, --之前的一個父節點 nsright int, --變成了兩個 ArticleId int, CommentBody nvarchar(500), FOREIGN KEY (ArticleId) REFERENCES Articles(ArticleId) )
nsleft值的確定:nsleft的數值小於該節點所有後代的Id。
nsright值的確定:nsright的值大於該節點所有後代的Id。
當然,以上兩個數字和CommentId的值並沒有任何關聯,確定值的方式是對樹進行一次深度優先遍歷,在逐層入神的過程中依次遞增地分配nsleft的值,並在返回時依次遞增地分配nsright的值。
採用書中的圖來說明一下情況:

一旦你為每個節點分配了這些數字,就可以使用它們來找到給定節點的祖先和後代。
巢狀集的優點:
我覺得是唯一的優點了,查詢祖先樹和子樹方便。
例如,通過搜尋那些節點的ConmentId在評論4的nsleft與nsright之間就可以獲得其及其所有後代:
SELECT c2.* FROM Comments AS c1 JOIN Comments AS c2 ON cs.neleft BETWEEN c1.nsleft AND c1.nsright WHERE c1.CommentId = 1;
結果如下:

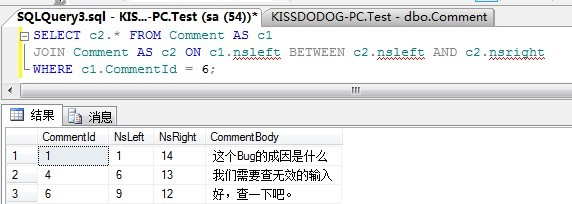
通過搜尋評論6的Id在哪些節點的nsleft和nsright範圍之間,就可以獲取評論6及其所有祖先:
SELECT c2.* FROM Comment AS c1 JOIN Comment AS c2 ON c1.nsleft BETWEEN c2.nsleft AND c2.nsright WHERE c1.CommentId = 6;
這種巢狀集的設計還有一個優點,就是當你想要刪除一個非葉子節點時,它的後代會自動地代替被刪除的節點,稱為其直接祖先節點的直接後代。
巢狀集設計並不必須儲存分層關係。因此當刪除一個節點造成數值不連續時,並不會對樹的結構產生任何影響。
巢狀集缺點:
1、查詢直接父親。
在巢狀集的設計中,這個需求的實現的思路是,給定節點c1的直接父親是這個節點的一個祖先,且這兩個節點之間不應該有任何其他的節點,因此,你可以用一個遞迴的外聯結來查詢一個節點,它就是c1的祖先,也同時是另一個節點Y的後代,隨後我們使y=x就查詢,直到查詢返回空,即不存在這樣的節點,此時y便是c1的直接父親節點。
比如,要找到評論6的直接父節點:老實說,SQL語句又長又臭,行肯定是行,但我真的寫不動了。
2、對樹進行操作,比如插入和移動節點。
當插入一個節點時,你需要重新計算新插入節點的相鄰兄弟節點、祖先節點和它祖先節點的兄弟,來確保它們的左右值都比這個新節點的左值大。同時,如果這個新節點是一個非葉子節點,你還要檢查它的子孫節點。
夠了,夠了。就憑查直接父節點都困難,這個東西就很冷門了。我確定我不會使用這種設計了。
四、閉包表
閉包表是解決分層儲存一個簡單而又優雅的解決方案,它記錄了表中所有的節點關係,並不僅僅是直接的父子關係。
在閉包表的設計中,額外建立了一張TreePaths的表(空間換取時間),它包含兩列,每一列都是一個指向Comments中的CommentId的外來鍵。
CREATE TABLE Comments( CommentId int PK, ArticleId int, CommentBody int, FOREIGN KEY(ArticleId) REFERENCES Articles(Id) )
父子關係表:
CREATE TABLE TreePaths( ancestor int, descendant int, PRIMARY KEY(ancestor,descendant), --複合主鍵 FOREIGN KEY (ancestor) REFERENCES Comments(CommentId), FOREIGN KEY (descendant) REFERENCES Comments(CommentId) )
在這種設計中,Comments表將不再儲存樹結構,而是將書中的祖先-後代關係儲存為TreePaths的一行,即使這兩個節點之間不是直接的父子關係;同時還增加一行指向節點自己,理解不了?就是TreePaths表儲存了所有祖先-後代的關係的記錄。如下圖:

Comment表:

TreePaths表:

優點:
1、查詢所有後代節點(查子樹):
SELECT c.* FROM Comment AS c INNER JOIN TreePaths t on c.CommentId = t.descendant WHERE t.ancestor = 4
結果如下:

2、查詢評論6的所有祖先(查祖先樹):
SELECT c.* FROM Comment AS c INNER JOIN TreePaths t on c.CommentId = t.ancestor WHERE t.descendant = 6
顯示結果如下:

3、插入新節點:
要插入一個新的葉子節點,應首先插入一條自己到自己的關係,然後搜尋TreePaths表中後代是評論5的節點,增加該節點與要插入的新節點的"祖先-後代"關係。
比如下面為插入評論5的一個子節點的TreePaths表語句:
INSERT INTO TreePaths(ancestor,descendant) SELECT t.ancestor,8 FROM TreePaths AS t WHERE t.descendant = 5 UNION ALL SELECT 8,8
執行以後:

至於Comment表那就簡單得不說了。
4、刪除葉子節點:
比如刪除葉子節點7,應刪除所有TreePaths表中後代為7的行:
DELETE FROM TreePaths WHERE descendant = 7
5、刪除子樹:
要刪除一顆完整的子樹,比如評論4和它的所有後代,可刪除所有在TreePaths表中的後代為4的行,以及那些以評論4的後代為後代的行:
DELETE FROM TreePaths WHERE descendant IN(SELECT descendant FROM TreePaths WHERE ancestor = 4)
另外,移動節點,先斷開與原祖先的關係,然後與新節點建立關係的SQL語句都不難寫。
另外,閉包表還可以優化,如增加一個path_length欄位,自我引用為0,直接子節點為1,再一下層為2,一次類推,查詢直接自子節點就變得很簡單。
總結
其實,在以往的工作中,曾見過不同型別的設計,鄰接表,路徑列舉,鄰接表路徑列舉一起來的都見過。
每種設計都各有優劣,如果選擇設計依賴於應用程式中哪種操作最需要效能上的優化。
下面給出一個表格,來展示各種設計的難易程度:
| 設計 | 表數量 | 查詢子 | 查詢樹 | 插入 | 刪除 | 引用完整性 |
| 鄰接表 | 1 | 簡單 | 簡單 | 簡單 | 簡單 | 是 |
| 列舉路徑 | 1 | 簡單 | 簡單 | 簡單 | 簡單 | 否 |
| 巢狀集 | 1 | 困難 | 簡單 | 困難 | 困難 | 否 |
| 閉包表 | 2 | 簡單 | 簡單 | 簡單 | 簡單 | 是 |
1、鄰接表是最方便的設計,並且很多軟體開發者都瞭解它。並且在遞迴查詢的幫助下,使得鄰接表的查詢更加高效。
2、列舉路徑能夠很直觀地展示出祖先到後代之間的路徑,但由於不能確保引用完整性,使得這個設計比較脆弱。列舉路徑也使得資料的儲存變得冗餘。
3、巢狀集是一個聰明的解決方案,但不能確保引用完整性,並且只能使用於查詢效能要求較高,而其他要求一般的場合使用它。
4、閉包表是最通用的設計,並且最靈活,易擴充套件,並且一個節點能屬於多棵樹,能減少冗餘的計算時間。但它要求一張額外的表來儲存關係,是一個空間換取時間的方案。