用於大規模資料集並行運算的MapReduce誕生之後,谷歌工程師對其進行了大規模隨機資料的排序測試。最近,他們向外界披露了過去幾年的測試資料和經驗總結,特別是50PB海量資料的排序,對於關注資料處理的技術人員來說很有借鑑意義。
為什麼谷歌工程師喜歡測試排序?因為很容易產生任意規模的資料,也很容易驗證排序的輸出是否正確。
最初的MapReduce論文就報導了一個TeraSort排序的結果。工程師在一定的規則基礎上對1TB或10TB的資料進行排序測試,因為細小的錯誤更容易在大規模資料執行的時候被發現。
GraySort是大型排序基準的選擇。在GraySort基準下,你必須按照儘快對至少100TB的資料(每100B資料用最前面的10B資料作為鍵)進行字典序排序。Storbenchmark.org這個網站追蹤報導了這個基準的官方優勝者。而谷歌從未正式參加過比賽。
MapReduce是解決這個問題的不錯選擇,因為它實現reduce的方法是通過對鍵進行排序。結合適當的(字典)分割槽功能,MapReduce的輸出是一組包含了最終排序資料的檔案序列。
有時,當一個新的cluster在一個資料中心出現時(通常被搜尋索引團隊所使用),谷歌MapReduce團隊就得到一個機會在真正的工作到來之前執行若干星期。這時他們有機會去“燃燒”這個cluster,延伸硬體的限制,放棄一些硬碟,而使用一些真正昂貴的裝置,瞭解系統的效能,並贏得(非正式)排序基準測試。
{kind=link}
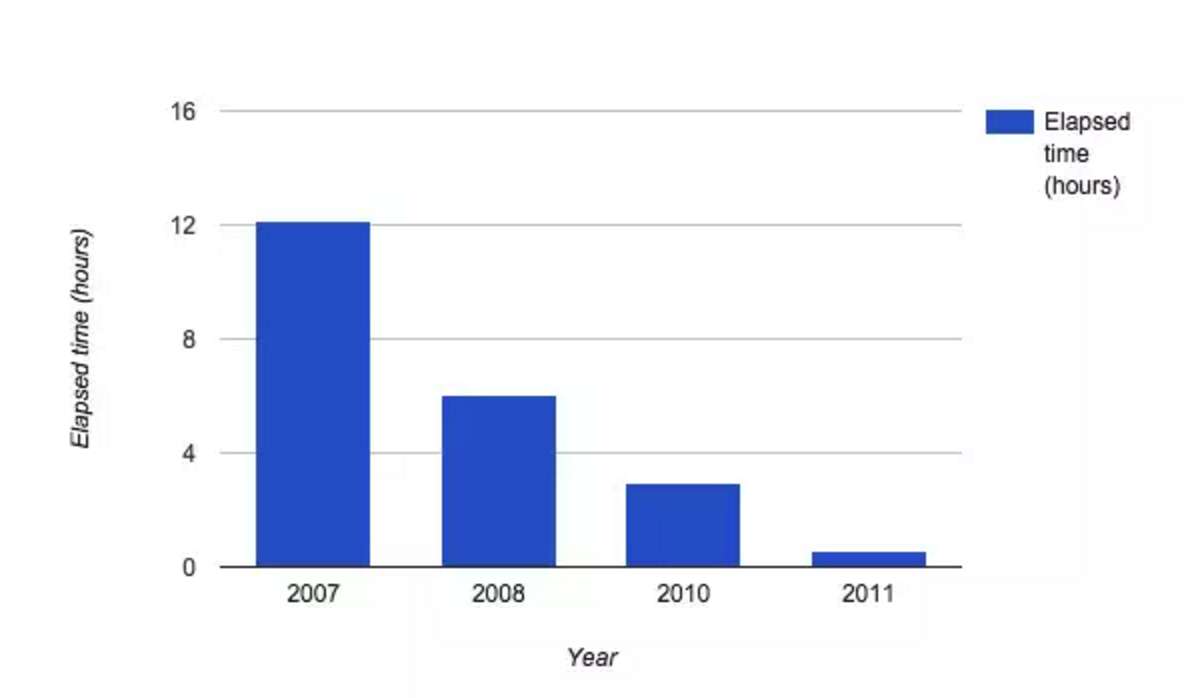
2007年執行了第一個Petasort。在那個時候,測試者最高興的是這個程式最終完成了排序,儘管對排序的結果有一些疑問(當時沒有驗證排序結果的正確性)。如果不是測試者取消了一定要某一個輸出分割槽與備份完全相同的驗證機制,這個排序便不會結束。
測試者懷疑這是因為用來儲存輸入和輸出的檔案是GFS格式(谷歌檔案系統)的緣故。GFS檔案沒有足夠校驗和保護,有時會返回被汙染的資料。不幸的是,這個基準所使用的檔案格式沒有嵌入任何校驗供MapReduce使用(谷歌使用的典型MapReduce的檔案是有嵌入校驗的)。
2008年測試者第一次把注意力集中於調優。花費幾天的時間來調整分割槽數量、緩衝區大小、預讀/預寫策略、頁面快取使用等。最終的瓶頸是寫三路複製的GFS輸出檔案,這是當時在谷歌使用的標準。任何事情的缺失都會造成資料丟失的高風險。
在這個測試中,工程師使用了一種新的不可壓縮資料的GraySort基準版本。在前幾年,當我們讀/寫1PB GFS檔案時,實際上混排的資料只有300TB,因為前幾年的資料是用ASCII格式壓縮好的。
這也是谷歌使用Colossus的一年,新一代的分散式儲存方式取代了GFS。不再有之前遇到過的GFS檔案汙染的問題。還使用了Reed-Solomon編碼(Colossus新特徵)作為輸出,這種編碼允許測試者減少資料的總量,三路複製資料從3位元組減少到了大約1.6位元組。這也是第一次,谷歌驗證了輸出的結果是正確的。
為了減少straggler的影響,測試者採用了一種叫做減少殘餘碎片的動態分割槽技術。這也是資料流採用全動態分割槽的先兆。
這一年,有了更快的網路,並開始更加註重每臺機器的效率,特別是I/O的效率。測試者確保所有的I/O操作都在大於2MB的空間內進行,而以前有時候會小到64kB。
對於部分資料,工程師使用固態硬碟。這是第一個在一小時之內完成Petasort。真的非常接近(兩倍) 給定MapReduce’s體系結構的硬體極限:輸入/輸出分散式儲存,為容錯保留中間資料(容錯是非常重要的,因為這個試驗中一些磁碟甚至整個機器都可能會失敗)。
他們還執行了更大的資料,10PB資料在6小時27分鐘(26TB/min)。
對於這個測試,工程師將注意力轉移到更大規模的資料。在測試團隊控制的最大cluster之下,執行了其認為是最大MapReduce工作。不幸的是,這個cluster沒有足夠的磁碟空間來排序100PB的資料,因而限制測試的排序“只有”50PB。
這個測試只執行了一次,並沒有進行專門的調整,只是使用了之前10PB實驗時候的設定。這次實驗在23小時5分鐘之後執行結束。
需要注意的是,這次排序的規模是GraySort大規模的要求的500倍,計算速率是2015年GraySort官方優勝者的兩倍。
這些實驗教會了谷歌工程師很多關於執行超過10000臺機器的挑戰,以及如何調整使得執行速度接近於硬體的極限。
雖然這些排序實驗很有趣,但還是有幾個缺點:
- 沒有人真的想要一個巨大的全域性範圍內的排序輸出,測試者還沒有找到這個問題的需求用例。
- 這些實驗顯示這個系統是可以良好執行的,但是需要強調的是谷歌花費了很多努力。
- MapReduce需要大量的除錯確保它順利執行。如果看到很多MapReduce執行很差,其原因可能是設定不當。
最近,谷歌工程師已經把注意力集中在構建系統上,目的是使得大部分調優都不再必要。例如,採用資料流自動計算出分割槽的數量(必要時採用動態再分割槽),而不是人為的經驗性分割槽。