
圖片來源:PCM
編者按:谷歌在今年的I/O大會推出了一個大驚喜:由機器學習支援的Allo智慧聊天應用。為何Allo能夠如此討使用者的歡心?谷歌研究的Pranav Khaitan在谷歌部落格上為我們解讀了Allo背後的人工智慧演算法。Khaitan具有史丹佛大學電腦科學碩士學位,曾在史丹佛大學擔任研究助理工作,並在微軟、Facebook等公司實習。他2011年加入谷歌,目前帶領團隊進行機器學習、神經網路和個人化科技的工作,並幫助打造谷歌搜尋等產品所需的知識圖表,在谷歌搜尋的幾乎每個領域——排名、指數和基礎建設——都能看到由他打造、釋出的功能。
谷歌一直在打造由機器學習支援的產品,讓使用者的生活更加簡單、美好。今天,本文將介紹一個全新智慧聊天應用Allo背後的技術,該應用使用神經網路和谷歌搜尋,讓文字聊天更加簡單、高效。
正如Inbox的智慧回覆一樣,Allo能夠理解對話記錄,提供使用者會想採用的回覆建議。除了理解對話的語境之外,Allo還能理解你的個人聊天風格,因此可以實現個人定製的聊天回覆。
圖片來源:Google Research Blog
如何做到的?
一年多以前,團隊開始研究如何讓對話可以更加簡便、更加好玩。Allo智慧回覆的想法來源於團隊中的Sushant Prakash和Ori Gershony,他們帶領團隊打造了這項技術。我們最初使用了一個神經網路進行試驗,其模型架構之前已經成功應用在序列預測中,包括Inbox智慧回覆中使用的編碼-解碼模型。
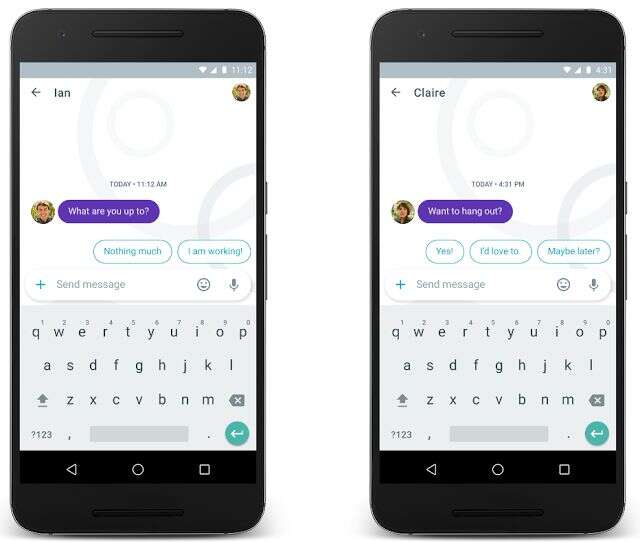
我們面臨的挑戰之一,是線上聊天在回覆時間上有很嚴格的要求。為了解決這個問題,Pavel Sountsov和Sushant想出了一個非常創新的兩階段模型。首先,一個遞迴神經網路一個字一個字地檢視聊天語境,然後用長短時記憶(LSTM)的隱藏狀態將其編碼。下圖展示的就是一個例子,語境是“你在哪?”語境有三個標記,每一個標記都嵌入到一個連續空間中,然後輸入到LSTM裡。然後,LSTM狀態將語境編碼為一個連續向量。這個向量用來生成作為離散語義類別的回覆。
上圖的例子中,最下方是輸入的語境(“你在哪?“),黃色層為”文字嵌入“,藍色層為”LSTM“,綠色層為”softmax函式“,最後輸出”地點短語“,作為預測的回覆語義。圖片來源:Google Research Blog。
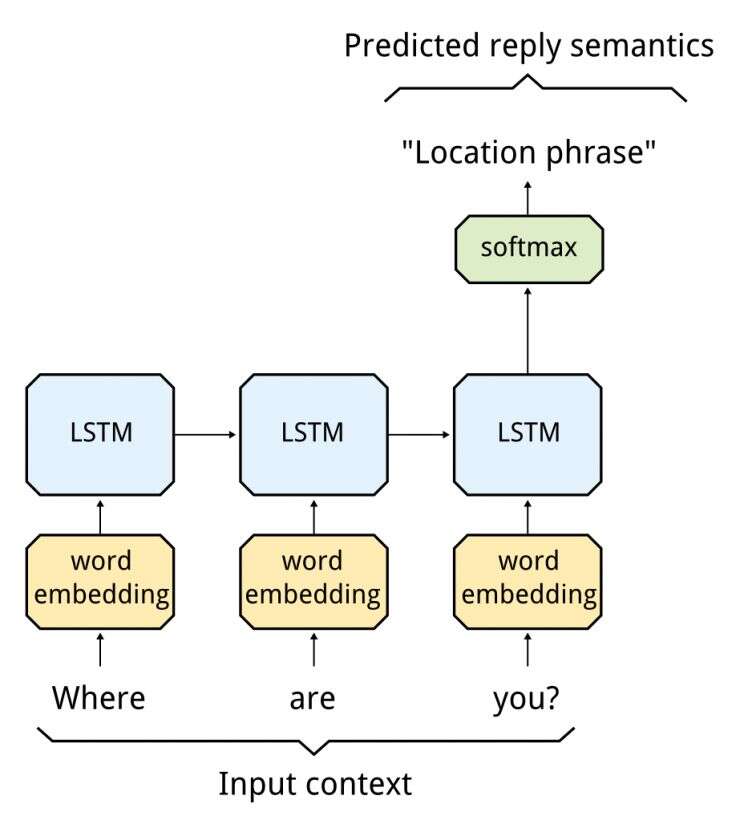
每一個語義類別都與它可能的回覆庫關聯起來。我們使用了第二個遞迴神經網路來從這個回覆庫中,生成一個具體的回覆資訊。這個神經網路還將語境轉換為一個隱藏的LSTM狀態,但是這一次,這個隱藏狀態是用來生成回覆的完整資訊,一次生成一個標記。我們回到上面的例子,LSTM看到了“你在哪?”的語境後,生成了回覆:“我在上班。”
上圖中,最下方是語境輸入(”你在哪?”),最上層softmax函式生成”我在上班。”來源:Google Research Blog。
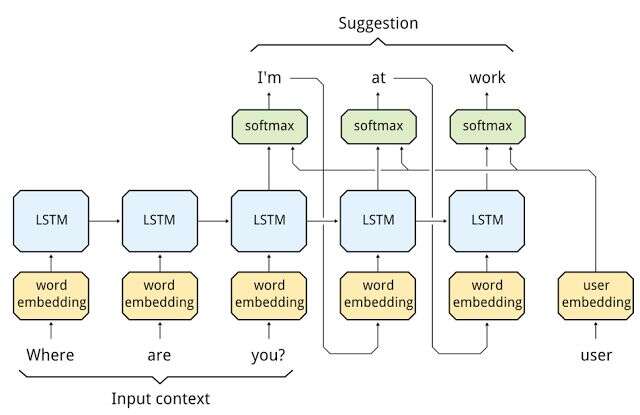
從LSTM生成的大量可能回覆庫中,beam搜尋能有效選擇出頂層得分最高的回覆。下圖展示的是一個搜尋空間的小片段,我們可以從中一窺beam搜尋技術。
圖片來源:Google Research Blog
正如任何大規模產品一樣,我們面臨了多個工程方面的挑戰,高效生成高質量的回覆庫並非易事。舉一個例子,雖然我們使用了這個兩階段的架構,我們最初的幾個神經網路執行都非常慢,生成一個回覆需要大約半秒鐘。半秒鐘聽起來很短,但是針對實時聊天應用來說,這完全是沒法接受的。因此,我們必須讓我們的神經網路架構進一步進化,將回復時間再減少至少200毫秒。我們改變了softmax層,轉而使用一個層級性的softmax層,可以遍歷一個詞彙樹,比之前遍歷一個詞彙列表更加高效。
在生成預測時我們遇到的另一個挑戰比較有趣,那就是控制資訊的長度。有時候,所有可能的回覆長度都不合適——如果模型預測的資訊太短,可能對於讀者來說就沒有用;而如果我們預測的資訊太長,可能就不適合手機螢幕的顯示大小。我們的辦法是,讓beam搜尋更偏向於跟進能夠通向更高反應用途的路徑,而不是傾向於選擇最有可能的回覆。這樣,我們可以高效生成長度適合的回覆預測,對使用者來說會非常有用。
個人定製
這項智慧聊天建議最棒的地方在於,隨著時間,軟體會為使用者進行個人定製,這樣你的個人風格會在聊天對話中體現出來。例如,假設當別人和你說“你好嗎?”(“How are you?”)的時候,你通常的回覆方式是“蠻好。”而不是“不錯。”(英文中某個使用者可能更習慣回覆“Fine.”而不是“I am good.”),軟體就會了解到你的偏好,在未來的回覆建議中就會考慮到這一點。要實現這一點,就要在神經網路中加入使用者的個人”風格“,將這個神經網路用於預測回覆中下一個詞語是什麼,這樣回覆建議就會根據你的個性和偏好進行定製化。使用者的風格是在一系列數字中獲取的,我們稱之為使用者嵌入。這些嵌入可以作為常規模型訓練的一部分,但是這種方法需要等上很多天訓練才能結束,而且如果使用者超過了幾百萬人,這種方法就有可能搞不定。為了解決這個問題,Alon Shafrir打造了一項基於L-BFGS的技術,讓Allo能夠快速、大量地生成使用者嵌入。現在,Allo的使用者只需要很短的一段時間,就能獲得個人定製化的回覆建議。
不只會說英語
我們之前說到的這個神經網路模型是不針對某種語言的,因此我們可以對每一種語言分別建立預測模型。Sujith Ravi為了確保每一種語言的回覆可以從我們對其他語言的語音理解中獲益,他提出了一種基於圖表的機器學習技術,可以將不同語言的可能回覆聯絡起來。Dana Movshovits-Attias和Peter Young將這項技術應用在一個圖表中,對收到資訊的回覆,可以與其他有相似詞彙嵌入和語法關係的回覆聯絡起來。基於谷歌翻譯團隊開發的機器翻譯模型,這個圖表還能將不同語言中具有相似語義的回覆聯絡起來。
利用這個圖表,我們使用了半監督學習(點選連結,可以通過這篇Sujith Ravi發表在第19屆人工智慧與資料國際大會(AISTATS)的論文中瞭解更多關於半監督學習的資訊)來了解回覆的語義含義,判斷哪一個可能的回覆組群是最有用的。每一個可能的回覆語義中都有多個可能的變種,現在我們可以讓LSTM對每個變種進行打分,讓個人化常規來為使用者在聊天情景中選擇最好的回覆。這還能幫助實現多元化,因為我們現在可以從不同的語義組群中選擇最終的回覆庫。
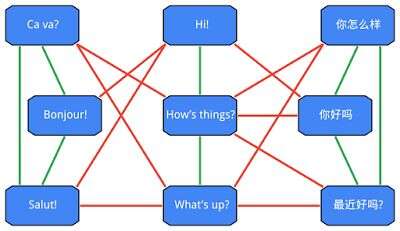
一個打招呼的資訊圖表可能會是這個樣子的。左:法語,中:英語,右:中文。圖片來源:Google Research Blog。
不止於智慧回覆
我非常期待Allo中的谷歌個人助理,你可以與它聊天,獲得谷歌搜尋上可以瞭解到的任何資訊。它可以直接通過對話理解你的句子,幫助你完成日常任務。舉個例子,你和朋友聊天的時候,谷歌助理可以在Allow應用內幫你發現有什麼好吃的餐廳並預定座位。正是因為我們在谷歌進行了最尖端的自然語言理解研究,我們才能實現這項功能。更多細節資訊將在未來發布。這些智慧功能將於今年夏天晚些時候出現在Allo的安卓和IOS應用中。
Via Google Research Blog