#include <stdio.h>int main(void){
fputs("Hello, world!\n", stdout);
return 0;}要先用編譯器處理一下,才能執行。
[ ubbcodeplace_2 ]nbsp;gcc test.c [ ubbcodeplace_2 ]nbsp;./a.out Hello, world!
對於複雜的專案,編譯過程還必須分成三步。
[ ubbcodeplace_3 ]nbsp;./configure [ ubbcodeplace_3 ]nbsp;make [ ubbcodeplace_3 ]nbsp;make install
這些命令到底在幹什麼?大多數的書籍和資料,都語焉不詳,只說這樣就可以編譯了,沒有進一步的解釋。
本文將介紹編譯器的工作過程,也就是上面這三個命令各自的任務。我主要參考了Alex Smith的文章《Building C Projects》。需要宣告的是,本文主要針對gcc編譯器,也就是針對C和C++,不一定適用於其他語言的編譯。
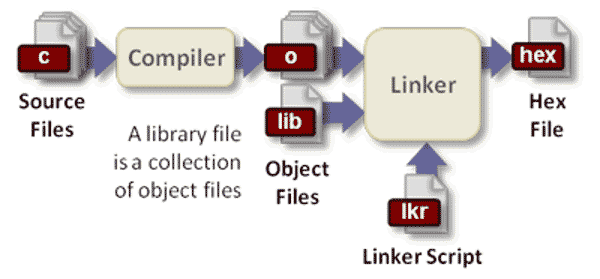
第一步 配置(configure)
編譯器在開始工作之前,需要知道當前的系統環境,比如標準庫在哪裡、軟體的安裝位置在哪裡、需要安裝哪些元件等等。這是因為不同計算機的系統環境不一樣,通過指定編譯引數,編譯器就可以靈活適應環境,編譯出各種環境都能執行的機器碼。這個確定編譯引數的步驟,就叫做"配置"(configure)。
這些配置資訊儲存在一個配置檔案之中,約定俗成是一個叫做configure的指令碼檔案。通常它是由autoconf工具生成的。編譯器通過執行這個指令碼,獲知編譯引數。
configure指令碼已經儘量考慮到不同系統的差異,並且對各種編譯引數給出了預設值。如果使用者的系統環境比較特別,或者有一些特定的需求,就需要手動向configure指令碼提供編譯引數。
上面程式碼是php原始碼的一種編譯配置,使用者指定安裝後的檔案儲存在www目錄,並且編譯時加入mysql模組的支援。[ ubbcodeplace_4 ]nbsp;./configure --prefix=/www --with-mysql
第二步 確定標準庫和標頭檔案的位置
原始碼肯定會用到標準庫函式(standard library)和標頭檔案(header)。它們可以存放在系統的任意目錄中,編譯器實際上沒辦法自動檢測它們的位置,只有通過配置檔案才能知道。
編譯的第二步,就是從配置檔案中知道標準庫和標頭檔案的位置。一般來說,配置檔案會給出一個清單,列出幾個具體的目錄。等到編譯時,編譯器就按順序到這幾個目錄中,尋找目標。
第三步 確定依賴關係
對於大型專案來說,原始碼檔案之間往往存在依賴關係,編譯器需要確定編譯的先後順序。假定A檔案依賴於B檔案,編譯器應該保證做到下面兩點。
(1)只有在B檔案編譯完成後,才開始編譯A檔案。編譯順序儲存在一個叫做makefile的檔案中,裡面列出哪個檔案先編譯,哪個檔案後編譯。而makefile檔案由configure指令碼執行生成,這就是為什麼編譯時configure必須首先執行的原因。
(2)當B檔案發生變化時,A檔案會被重新編譯。
在確定依賴關係的同時,編譯器也確定了,編譯時會用到哪些標頭檔案。
第四步 標頭檔案的預編譯(precompilation)
不同的原始碼檔案,可能引用同一個標頭檔案(比如stdio.h)。編譯的時候,標頭檔案也必須一起編譯。為了節省時間,編譯器會在編譯原始碼之前,先編譯標頭檔案。這保證了標頭檔案只需編譯一次,不必每次用到的時候,都重新編譯了。
不過,並不是標頭檔案的所有內容,都會被預編譯。用來宣告巨集的#define命令,就不會被預編譯。
第五步 預處理(Preprocessing)
預編譯完成後,編譯器就開始替換掉原始碼中bash的標頭檔案和巨集。以本文開頭的那段原始碼為例,它包含標頭檔案stdio.h,替換後的樣子如下。
extern int fputs(const char *, FILE *);extern FILE *stdout;int main(void){
fputs("Hello, world!\n", stdout);
return 0;}這一步稱為"預處理"(Preprocessing),因為完成之後,就要開始真正的處理了。
第六步 編譯(Compilation)
預處理之後,編譯器就開始生成機器碼。對於某些編譯器來說,還存在一箇中間步驟,會先把原始碼轉為彙編碼(assembly),然後再把彙編碼轉為機器碼。
下面是本文開頭的那段原始碼轉成的彙編碼。
.file "test.c"
.section .rodata.LC0:
.string "Hello, world!\n"
.text .globl main .type main, @functionmain:.LFB0:
.cfi_startproc
pushq %rbp .cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp .cfi_def_cfa_register 6
movq stdout(%rip), %rax
movq %rax, %rcx
movl $14, %edx
movl $1, %esi
movl $.LC0, %edi
call fwrite
movl $0, %eax
popq %rbp .cfi_def_cfa 7, 8
ret .cfi_endproc.LFE0:
.size main, .-main .ident "GCC: (Debian 4.9.1-19) 4.9.1"
.section .note.GNU-stack,"",@progbits第七步 連線(Linking)
物件檔案還不能執行,必須進一步轉成可執行檔案。如果你仔細看上一步的轉碼結果,會發現其中引用了stdout函式和fwrite函式。也就是說,程式要正常執行,除了上面的程式碼以外,還必須有stdout和fwrite這兩個函式的程式碼,它們是由C語言的標準庫提供的。
編譯器的下一步工作,就是把外部函式的程式碼(通常是字尾名為.lib和.a的檔案),新增到可執行檔案中。這就叫做連線(linking)。這種通過拷貝,將外部函式庫新增到可執行檔案的方式,叫做靜態連線(static linking),後文會提到還有動態連線(dynamic linking)。
make命令的作用,就是從第四步標頭檔案預編譯開始,一直到做完這一步。
第八步 安裝(Installation)
上一步的連線是在記憶體中進行的,即編譯器在記憶體中生成了可執行檔案。下一步,必須將可執行檔案儲存到使用者事先指定的安裝目錄。
表面上,這一步很簡單,就是將可執行檔案(連帶相關的資料檔案)拷貝過去就行了。但是實際上,這一步還必須完成建立目錄、儲存檔案、設定許可權等步驟。這整個的儲存過程就稱為"安裝"(Installation)。
第九步 作業系統連線
可執行檔案安裝後,必須以某種方式通知作業系統,讓其知道可以使用這個程式了。比如,我們安裝了一個文字閱讀程式,往往希望雙擊txt檔案,該程式就會自動執行。
這就要求在作業系統中,登記這個程式的後設資料:檔名、檔案描述、關聯字尾名等等。Linux系統中,這些資訊通常儲存在/usr/share/applications目錄下的.desktop檔案中。另外,在Windows作業系統中,還需要在Start啟動選單中,建立一個快捷方式。
這些事情就叫做"作業系統連線"。make install命令,就用來完成"安裝"和"作業系統連線"這兩步。
第十步 生成安裝包
寫到這裡,原始碼編譯的整個過程就基本完成了。但是隻有很少一部分使用者,願意耐著性子,從頭到尾做一遍這個過程。事實上,如果你只有原始碼可以交給使用者,他們會認定你是一個不友好的傢伙。大部分使用者要的是一個二進位制的可執行程式,立刻就能執行。這就要求開發者,將上一步生成的可執行檔案,做成可以分發的安裝包。
所以,編譯器還必須有生成安裝包的功能。通常是將可執行檔案(連帶相關的資料檔案),以某種目錄結構,儲存成壓縮檔案包,交給使用者。
第十一步 動態連線(Dynamic linking)
正常情況下,到這一步,程式已經可以執行了。至於執行期間(runtime)發生的事情,與編譯器一概無關。但是,開發者可以在編譯階段選擇可執行檔案連線外部函式庫的方式,到底是靜態連線(編譯時連線),還是動態連線(執行時連線)。所以,最後還要提一下,什麼叫做動態連線。
前面已經說過,靜態連線就是把外部函式庫,拷貝到可執行檔案中。這樣做的好處是,適用範圍比較廣,不用擔心使用者機器缺少某個庫檔案;缺點是安裝包會比較大,而且多個應用程式之間,無法共享庫檔案。動態連線的做法正好相反,外部函式庫不進入安裝包,只在執行時動態引用。好處是安裝包會比較小,多個應用程式可以共享庫檔案;缺點是使用者必須事先安裝好庫檔案,而且版本和安裝位置都必須符合要求,否則就不能正常執行。
現實中,大部分軟體採用動態連線,共享庫檔案。這種動態共享的庫檔案,Linux平臺是字尾名為.so的檔案,Windows平臺是.dll檔案,Mac平臺是.dylib檔案。
來自:PHP100
評論(1)