MySQL詳解--鎖,事務
查詢表級鎖爭用情況
MySQL表級鎖的鎖模式
|
請求鎖模式
是否相容
當前鎖模式
|
None | 讀鎖 | 寫鎖 |
| 讀鎖 | 是 | 是 | 否 |
| 寫鎖 | 是 | 否 | 否 |
| session_1 | session_2 |
|
獲得表film_text的WRITE鎖定
mysql> lock table film_text write;
Query OK, 0 rows affected (0.00 sec)
|
|
|
當前session對鎖定表的查詢、更新、插入操作都可以執行:
mysql> select film_id,title from film_text where film_id = 1001;
+---------+-------------+
| film_id | title |
+---------+-------------+
| 1001 | Update Test |
+---------+-------------+
1 row in set (0.00 sec)
mysql> insert into film_text (film_id,title) values(1003,'Test');
Query OK, 1 row affected (0.00 sec)
mysql> update film_text set title = 'Test' where film_id = 1001;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
|
其他session對鎖定表的查詢被阻塞,需要等待鎖被釋放:
mysql> select film_id,title from film_text where film_id = 1001;
等待
|
|
釋放鎖:
mysql> unlock tables;
Query OK, 0 rows affected (0.00 sec)
|
等待 |
|
Session2獲得鎖,查詢返回:
mysql> select film_id,title from film_text where film_id = 1001;
+---------+-------+
| film_id | title |
+---------+-------+
| 1001 | Test |
+---------+-------+
1 row in set (57.59 sec)
|
如何加表鎖
| session_1 | session_2 |
|
獲得表film_text的READ鎖定
mysql> lock table film_text read;
Query OK, 0 rows affected (0.00 sec)
|
|
|
當前session可以查詢該表記錄
mysql> select film_id,title from film_text where film_id = 1001;
+---------+------------------+
| film_id | title |
+---------+------------------+
| 1001 | ACADEMY DINOSAUR |
+---------+------------------+
1 row in set (0.00 sec)
|
其他session也可以查詢該表的記錄
mysql> select film_id,title from film_text where film_id = 1001;
+---------+------------------+
| film_id | title |
+---------+------------------+
| 1001 | ACADEMY DINOSAUR |
+---------+------------------+
1 row in set (0.00 sec)
|
|
當前session不能查詢沒有鎖定的表
mysql> select film_id,title from film where film_id = 1001;
ERROR 1100 (HY000): Table 'film' was not locked with LOCK TABLES
|
其他session可以查詢或者更新未鎖定的表
mysql> select film_id,title from film where film_id = 1001;
+---------+---------------+
| film_id | title |
+---------+---------------+
| 1001 | update record |
+---------+---------------+
1 row in set (0.00 sec)
mysql> update film set title = 'Test' where film_id = 1001;
Query OK, 1 row affected (0.04 sec)
Rows matched: 1 Changed: 1 Warnings: 0
|
|
當前session中插入或者更新鎖定的表都會提示錯誤:
mysql> insert into film_text (film_id,title) values(1002,'Test');
ERROR 1099 (HY000): Table 'film_text' was locked with a READ lock and can't be updated
mysql> update film_text set title = 'Test' where film_id = 1001;
ERROR 1099 (HY000): Table 'film_text' was locked with a READ lock and can't be updated
|
其他session更新鎖定表會等待獲得鎖:
mysql> update film_text set title = 'Test' where film_id = 1001;
等待
|
|
釋放鎖
mysql> unlock tables;
Query OK, 0 rows affected (0.00 sec)
|
等待 |
|
Session獲得鎖,更新操作完成:
mysql> update film_text set title = 'Test' where film_id = 1001;
Query OK, 1 row affected (1 min 0.71 sec)
Rows matched: 1 Changed: 1 Warnings: 0
|
併發插入(Concurrent Inserts)
| session_1 | session_2 |
|
獲得表film_text的READ LOCAL鎖定
mysql> lock table film_text read local;
Query OK, 0 rows affected (0.00 sec)
|
|
|
當前session不能對鎖定表進行更新或者插入操作:
mysql> insert into film_text (film_id,title) values(1002,'Test');
ERROR 1099 (HY000): Table 'film_text' was locked with a READ lock and can't be updated
mysql> update film_text set title = 'Test' where film_id = 1001;
ERROR 1099 (HY000): Table 'film_text' was locked with a READ lock and can't be updated
|
其他session可以進行插入操作,但是更新會等待:
mysql> insert into film_text (film_id,title) values(1002,'Test');
Query OK, 1 row affected (0.00 sec)
mysql> update film_text set title = 'Update Test' where film_id = 1001;
等待
|
|
當前session不能訪問其他session插入的記錄:
mysql> select film_id,title from film_text where film_id = 1002;
Empty set (0.00 sec)
|
|
|
釋放鎖:
mysql> unlock tables;
Query OK, 0 rows affected (0.00 sec)
|
等待 |
|
當前session解鎖後可以獲得其他session插入的記錄:
mysql> select film_id,title from film_text where film_id = 1002;
+---------+-------+
| film_id | title |
+---------+-------+
| 1002 | Test |
+---------+-------+
1 row in set (0.00 sec)
|
Session2獲得鎖,更新操作完成:
mysql> update film_text set title = 'Update Test' where film_id = 1001;
Query OK, 1 row affected (1 min 17.75 sec)
Rows matched: 1 Changed: 1 Warnings: 0
|
MyISAM的鎖排程
背景知識
1.事務(Transaction)及其ACID屬性
2.併發事務處理帶來的問題
3.事務隔離級別
|
讀資料一致性及允許的併發副作用
隔離級別
|
讀資料一致性 | 髒讀 | 不可重複讀 | 幻讀 |
|
未提交讀(Read uncommitted)
|
最低階別,只能保證不讀取物理上損壞的資料 | 是 | 是 | 是 |
|
已提交度(Read committed)
|
語句級 | 否 | 是 | 是 |
|
可重複讀(Repeatable read)
|
事務級 | 否 | 否 | 是 |
|
可序列化(Serializable)
|
最高階別,事務級 | 否 | 否 | 否 |
獲取InnoDB行鎖爭用情況
InnoDB的行鎖模式及加鎖方法
|
請求鎖模式
是否相容
當前鎖模式
|
X | IX | S | IS |
| X | 衝突 | 衝突 | 衝突 | 衝突 |
| IX | 衝突 | 相容 | 衝突 | 相容 |
| S | 衝突 | 衝突 | 相容 | 相容 |
| IS | 衝突 | 相容 | 相容 | 相容 |
| session_1 | session_2 |
|
mysql> set autocommit = 0;
Query OK, 0 rows affected (0.00 sec)
mysql> select actor_id,first_name,last_name from actor where actor_id = 178;
+----------+------------+-----------+
| actor_id | first_name | last_name |
+----------+------------+-----------+
| 178 | LISA | MONROE |
+----------+------------+-----------+
1 row in set (0.00 sec)
|
mysql> set autocommit = 0;
Query OK, 0 rows affected (0.00 sec)
mysql> select actor_id,first_name,last_name from actor where actor_id = 178;
+----------+------------+-----------+
| actor_id | first_name | last_name |
+----------+------------+-----------+
| 178 | LISA | MONROE |
+----------+------------+-----------+
1 row in set (0.00 sec)
|
|
當前session對actor_id=178的記錄加share mode 的共享鎖:
mysql> select actor_id,first_name,last_name from actor where actor_id = 178lock in share mode;
+----------+------------+-----------+
| actor_id | first_name | last_name |
+----------+------------+-----------+
| 178 | LISA | MONROE |
+----------+------------+-----------+
1 row in set (0.01 sec)
|
|
|
其他session仍然可以查詢記錄,並也可以對該記錄加share mode的共享鎖:
mysql> select actor_id,first_name,last_name from actor where actor_id = 178lock in share mode;
+----------+------------+-----------+
| actor_id | first_name | last_name |
+----------+------------+-----------+
| 178 | LISA | MONROE |
+----------+------------+-----------+
1 row in set (0.01 sec)
|
|
|
當前session對鎖定的記錄進行更新操作,等待鎖:
mysql> update actor set last_name = 'MONROE T' where actor_id = 178;
等待
|
|
|
其他session也對該記錄進行更新操作,則會導致死鎖退出:
mysql> update actor set last_name = 'MONROE T' where actor_id = 178;
ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction
|
|
|
獲得鎖後,可以成功更新:
mysql> update actor set last_name = 'MONROE T' where actor_id = 178;
Query OK, 1 row affected (17.67 sec)
Rows matched: 1 Changed: 1 Warnings: 0
|
| session_1 | session_2 |
|
mysql> set autocommit = 0;
Query OK, 0 rows affected (0.00 sec)
mysql> select actor_id,first_name,last_name from actor where actor_id = 178;
+----------+------------+-----------+
| actor_id | first_name | last_name |
+----------+------------+-----------+
| 178 | LISA | MONROE |
+----------+------------+-----------+
1 row in set (0.00 sec)
|
mysql> set autocommit = 0;
Query OK, 0 rows affected (0.00 sec)
mysql> select actor_id,first_name,last_name from actor where actor_id = 178;
+----------+------------+-----------+
| actor_id | first_name | last_name |
+----------+------------+-----------+
| 178 | LISA | MONROE |
+----------+------------+-----------+
1 row in set (0.00 sec)
|
|
當前session對actor_id=178的記錄加for update的排它鎖:
mysql> select actor_id,first_name,last_name from actor where actor_id = 178 for update;
+----------+------------+-----------+
| actor_id | first_name | last_name |
+----------+------------+-----------+
| 178 | LISA | MONROE |
+----------+------------+-----------+
1 row in set (0.00 sec)
|
|
|
其他session可以查詢該記錄,但是不能對該記錄加共享鎖,會等待獲得鎖:
mysql> select actor_id,first_name,last_name from actor where actor_id = 178;
+----------+------------+-----------+
| actor_id | first_name | last_name |
+----------+------------+-----------+
| 178 | LISA | MONROE |
+----------+------------+-----------+
1 row in set (0.00 sec)
mysql> select actor_id,first_name,last_name from actor where actor_id = 178 for update;
等待
|
|
|
當前session可以對鎖定的記錄進行更新操作,更新後釋放鎖:
mysql> update actor set last_name = 'MONROE T' where actor_id = 178;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> commit;
Query OK, 0 rows affected (0.01 sec)
|
|
|
其他session獲得鎖,得到其他session提交的記錄:
mysql> select actor_id,first_name,last_name from actor where actor_id = 178 for update;
+----------+------------+-----------+
| actor_id | first_name | last_name |
+----------+------------+-----------+
| 178 | LISA | MONROE T |
+----------+------------+-----------+
1 row in set (9.59 sec)
|
InnoDB行鎖實現方式
| session_1 | session_2 |
|
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from tab_no_index where id = 1 ;
+------+------+
| id | name |
+------+------+
| 1 | 1 |
+------+------+
1 row in set (0.00 sec)
|
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from tab_no_index where id = 2 ;
+------+------+
| id | name |
+------+------+
| 2 | 2 |
+------+------+
1 row in set (0.00 sec)
|
|
mysql> select * from tab_no_index where id = 1 for update;
+------+------+
| id | name |
+------+------+
| 1 | 1 |
+------+------+
1 row in set (0.00 sec)
|
|
|
mysql> select * from tab_no_index where id = 2 for update;
等待
|
| session_1 | session_2 |
|
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from tab_with_index where id = 1 ;
+------+------+
| id | name |
+------+------+
| 1 | 1 |
+------+------+
1 row in set (0.00 sec)
|
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from tab_with_index where id = 2 ;
+------+------+
| id | name |
+------+------+
| 2 | 2 |
+------+------+
1 row in set (0.00 sec)
|
|
mysql> select * from tab_with_index where id = 1 for update;
+------+------+
| id | name |
+------+------+
| 1 | 1 |
+------+------+
1 row in set (0.00 sec)
|
|
|
mysql> select * from tab_with_index where id = 2 for update;
+------+------+
| id | name |
+------+------+
| 2 | 2 |
+------+------+
1 row in set (0.00 sec)
|
| session_1 | session_2 |
|
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)
|
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)
|
|
mysql> select * from tab_with_index where id = 1 and name = '1' for update;
+------+------+
| id | name |
+------+------+
| 1 | 1 |
+------+------+
1 row in set (0.00 sec)
|
|
|
雖然session_2訪問的是和session_1不同的記錄,但是因為使用了相同的索引,所以需要等待鎖:
mysql> select * from tab_with_index where id = 1 and name = '4' for update;
等待
|
| session_1 | session_2 |
|
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)
|
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)
|
|
mysql> select * from tab_with_index where id = 1 for update;
+------+------+
| id | name |
+------+------+
| 1 | 1 |
| 1 | 4 |
+------+------+
2 rows in set (0.00 sec)
|
|
|
Session_2使用name的索引訪問記錄,因為記錄沒有被索引,所以可以獲得鎖:
mysql> select * from tab_with_index where name = '2' for update;
+------+------+
| id | name |
+------+------+
| 2 | 2 |
+------+------+
1 row in set (0.00 sec)
|
|
|
由於訪問的記錄已經被session_1鎖定,所以等待獲得鎖。:
mysql> select * from tab_with_index where name = '4' for update;
|
間隙鎖(Next-Key鎖)
| session_1 | session_2 |
|
mysql> select @@tx_isolation;
+-----------------+
| @@tx_isolation |
+-----------------+
| REPEATABLE-READ |
+-----------------+
1 row in set (0.00 sec)
mysql> set autocommit = 0;
Query OK, 0 rows affected (0.00 sec)
|
mysql> select @@tx_isolation;
+-----------------+
| @@tx_isolation |
+-----------------+
| REPEATABLE-READ |
+-----------------+
1 row in set (0.00 sec)
mysql> set autocommit = 0;
Query OK, 0 rows affected (0.00 sec)
|
|
當前session對不存在的記錄加for update的鎖:
mysql> select * from emp where empid = 102 for update;
Empty set (0.00 sec)
|
|
|
這時,如果其他session插入empid為102的記錄(注意:這條記錄並不存在),也會出現鎖等待:
mysql>insert into emp(empid,...) values(102,...);
阻塞等待
|
|
|
Session_1 執行rollback:
mysql> rollback;
Query OK, 0 rows affected (13.04 sec)
|
|
|
由於其他session_1回退後釋放了Next-Key鎖,當前session可以獲得鎖併成功插入記錄:
mysql>insert into emp(empid,...) values(102,...);
Query OK, 1 row affected (13.35 sec)
|
恢復和複製的需要,對InnoDB鎖機制的影響
| session_1 | session_2 |
|
mysql> set autocommit = 0;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from target_tab;
Empty set (0.00 sec)
mysql> select * from source_tab where name = '1';
+----+------+----+
| d1 | name | d2 |
+----+------+----+
| 4 | 1 | 1 |
| 5 | 1 | 1 |
| 6 | 1 | 1 |
| 7 | 1 | 1 |
| 8 | 1 | 1 |
+----+------+----+
5 rows in set (0.00 sec)
|
mysql> set autocommit = 0;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from target_tab;
Empty set (0.00 sec)
mysql> select * from source_tab where name = '1';
+----+------+----+
| d1 | name | d2 |
+----+------+----+
| 4 | 1 | 1 |
| 5 | 1 | 1 |
| 6 | 1 | 1 |
| 7 | 1 | 1 |
| 8 | 1 | 1 |
+----+------+----+
5 rows in set (0.00 sec)
|
|
mysql> insert into target_tab select d1,name from source_tab where name = '1';
Query OK, 5 rows affected (0.00 sec)
Records: 5 Duplicates: 0 Warnings: 0
|
|
|
mysql> update source_tab set name = '1' where name = '8';
等待
|
|
| commit; | |
|
返回結果
commit;
|
| session_1 | session_2 |
|
mysql> set autocommit = 0;
Query OK, 0 rows affected (0.00 sec)
mysql>set innodb_locks_unsafe_for_binlog='on'
Query OK, 0 rows affected (0.00 sec)
mysql> select * from target_tab;
Empty set (0.00 sec)
mysql> select * from source_tab where name = '1';
+----+------+----+
| d1 | name | d2 |
+----+------+----+
| 4 | 1 | 1 |
| 5 | 1 | 1 |
| 6 | 1 | 1 |
| 7 | 1 | 1 |
| 8 | 1 | 1 |
+----+------+----+
5 rows in set (0.00 sec)
|
mysql> set autocommit = 0;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from target_tab;
Empty set (0.00 sec)
mysql> select * from source_tab where name = '1';
+----+------+----+
| d1 | name | d2 |
+----+------+----+
| 4 | 1 | 1 |
| 5 | 1 | 1 |
| 6 | 1 | 1 |
| 7 | 1 | 1 |
| 8 | 1 | 1 |
+----+------+----+
5 rows in set (0.00 sec)
|
|
mysql> insert into target_tab select d1,name from source_tab where name = '1';
Query OK, 5 rows affected (0.00 sec)
Records: 5 Duplicates: 0 Warnings: 0
|
|
|
session_1未提交,可以對session_1的select的記錄進行更新操作。
mysql> update source_tab set name = '8' where name = '1';
Query OK, 5 rows affected (0.00 sec)
Rows matched: 5 Changed: 5 Warnings: 0
mysql> select * from source_tab where name = '8';
+----+------+----+
| d1 | name | d2 |
+----+------+----+
| 4 | 8 | 1 |
| 5 | 8 | 1 |
| 6 | 8 | 1 |
| 7 | 8 | 1 |
| 8 | 8 | 1 |
+----+------+----+
5 rows in set (0.00 sec)
|
|
|
更新操作先提交
mysql> commit;
Query OK, 0 rows affected (0.05 sec)
|
|
|
插入操作後提交
mysql> commit;
Query OK, 0 rows affected (0.07 sec)
|
|
|
此時檢視資料,target_tab中可以插入source_tab更新前的結果,這符合應用邏輯:
mysql> select * from source_tab where name = '8';
+----+------+----+
| d1 | name | d2 |
+----+------+----+
| 4 | 8 | 1 |
| 5 | 8 | 1 |
| 6 | 8 | 1 |
| 7 | 8 | 1 |
| 8 | 8 | 1 |
+----+------+----+
5 rows in set (0.00 sec)
mysql> select * from target_tab;
+------+------+
| id | name |
+------+------+
| 4 | 1.00 |
| 5 | 1.00 |
| 6 | 1.00 |
| 7 | 1.00 |
| 8 | 1.00 |
+------+------+
5 rows in set (0.00 sec)
|
mysql> select * from tt1 where name = '1';
Empty set (0.00 sec)
mysql> select * from source_tab where name = '8';
+----+------+----+
| d1 | name | d2 |
+----+------+----+
| 4 | 8 | 1 |
| 5 | 8 | 1 |
| 6 | 8 | 1 |
| 7 | 8 | 1 |
| 8 | 8 | 1 |
+----+------+----+
5 rows in set (0.00 sec)
mysql> select * from target_tab;
+------+------+
| id | name |
+------+------+
| 4 | 1.00 |
| 5 | 1.00 |
| 6 | 1.00 |
| 7 | 1.00 |
| 8 | 1.00 |
+------+------+
5 rows in set (0.00 sec)
|
InnoDB在不同隔離級別下的一致性讀及鎖的差異
|
隔離級別
一致性讀和鎖
SQL
|
Read Uncommited | Read Commited | Repeatable Read | Serializable | |
| SQL | 條件 | ||||
| select | 相等 | None locks | Consisten read/None lock | Consisten read/None lock | Share locks |
| 範圍 | None locks | Consisten read/None lock | Consisten read/None lock | Share Next-Key | |
| update | 相等 | exclusive locks | exclusive locks | exclusive locks | Exclusive locks |
| 範圍 | exclusive next-key | exclusive next-key | exclusive next-key | exclusive next-key | |
| Insert | N/A | exclusive locks | exclusive locks | exclusive locks | exclusive locks |
| replace | 無鍵衝突 | exclusive locks | exclusive locks | exclusive locks | exclusive locks |
| 鍵衝突 | exclusive next-key | exclusive next-key | exclusive next-key | exclusive next-key | |
| delete | 相等 | exclusive locks | exclusive locks | exclusive locks | exclusive locks |
| 範圍 | exclusive next-key | exclusive next-key | exclusive next-key | exclusive next-key | |
| Select ... from ... Lock in share mode | 相等 | Share locks | Share locks | Share locks | Share locks |
| 範圍 | Share locks | Share locks | Share Next-Key | Share Next-Key | |
| Select * from ... For update | 相等 | exclusive locks | exclusive locks | exclusive locks | exclusive locks |
| 範圍 | exclusive locks | Share locks | exclusive next-key | exclusive next-key | |
|
Insert into ... Select ...
(指源表鎖)
|
innodb_locks_unsafe_for_binlog=off | Share Next-Key | Share Next-Key | Share Next-Key | Share Next-Key |
| innodb_locks_unsafe_for_binlog=on | None locks | Consisten read/None lock | Consisten read/None lock | Share Next-Key | |
|
create table ... Select ...
(指源表鎖)
|
innodb_locks_unsafe_for_binlog=off | Share Next-Key | Share Next-Key | Share Next-Key | Share Next-Key |
| innodb_locks_unsafe_for_binlog=on | None locks | Consisten read/None lock | Consisten read/None lock | Share Next-Key |
什麼時候使用表鎖
關於死鎖
| session_1 | session_2 |
|
mysql> set autocommit = 0;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from table_1 where where id=1 for update;
...
做一些其他處理...
|
mysql> set autocommit = 0;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from table_2 where id=1 for update;
...
|
|
select * from table_2 where id =1 for update;
因session_2已取得排他鎖,等待
|
做一些其他處理... |
|
mysql> select * from table_1 where where id=1 for update;
死鎖
|
| session_1 | session_2 |
|
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)
|
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)
|
|
mysql> select first_name,last_name from actor where actor_id = 1 for update;
+------------+-----------+
| first_name | last_name |
+------------+-----------+
| PENELOPE | GUINESS |
+------------+-----------+
1 row in set (0.00 sec)
|
|
|
mysql> insert into country (country_id,country) values(110,'Test');
Query OK, 1 row affected (0.00 sec)
|
|
|
mysql> insert into country (country_id,country) values(110,'Test');
等待
|
|
|
mysql> select first_name,last_name from actor where actor_id = 1 for update;
+------------+-----------+
| first_name | last_name |
+------------+-----------+
| PENELOPE | GUINESS |
+------------+-----------+
1 row in set (0.00 sec)
|
|
|
mysql> insert into country (country_id,country) values(110,'Test');
ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction
|
| session_1 | session_2 |
|
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)
|
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)
|
|
mysql> select first_name,last_name from actor where actor_id = 1 for update;
+------------+-----------+
| first_name | last_name |
+------------+-----------+
| PENELOPE | GUINESS |
+------------+-----------+
1 row in set (0.00 sec)
|
|
|
mysql> select first_name,last_name from actor where actor_id = 3 for update;
+------------+-----------+
| first_name | last_name |
+------------+-----------+
| ED | CHASE |
+------------+-----------+
1 row in set (0.00 sec)
|
|
|
mysql> select first_name,last_name from actor where actor_id = 3 for update;
等待
|
|
|
mysql> select first_name,last_name from actor where actor_id = 1 for update;
ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction
|
|
|
mysql> select first_name,last_name from actor where actor_id = 3 for update;
+------------+-----------+
| first_name | last_name |
+------------+-----------+
| ED | CHASE |
+------------+-----------+
1 row in set (4.71 sec)
|
| session_1 | session_2 |
|
mysql> select @@tx_isolation;
+-----------------+
| @@tx_isolation |
+-----------------+
| REPEATABLE-READ |
+-----------------+
1 row in set (0.00 sec)
mysql> set autocommit = 0;
Query OK, 0 rows affected (0.00 sec)
|
mysql> select @@tx_isolation;
+-----------------+
| @@tx_isolation |
+-----------------+
| REPEATABLE-READ |
+-----------------+
1 row in set (0.00 sec)
mysql> set autocommit = 0;
Query OK, 0 rows affected (0.00 sec)
|
|
當前session對不存在的記錄加for update的鎖:
mysql> select actor_id,first_name,last_name from actor where actor_id = 201 for update;
Empty set (0.00 sec)
|
|
|
其他session也可以對不存在的記錄加for update的鎖:
mysql> select actor_id,first_name,last_name from actor where actor_id = 201 for update;
Empty set (0.00 sec)
|
|
|
因為其他session也對該記錄加了鎖,所以當前的插入會等待:
mysql> insert into actor (actor_id , first_name , last_name) values(201,'Lisa','Tom');
等待
|
|
|
因為其他session已經對記錄進行了更新,這時候再插入記錄就會提示死鎖並退出:
mysql> insert into actor (actor_id, first_name , last_name) values(201,'Lisa','Tom');
ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction
|
|
|
由於其他session已經退出,當前session可以獲得鎖併成功插入記錄:
mysql> insert into actor (actor_id , first_name , last_name) values(201,'Lisa','Tom');
Query OK, 1 row affected (13.35 sec)
|
| session_1 | session_2 | session_3 |
|
mysql> select @@tx_isolation;
+----------------+
| @@tx_isolation |
+----------------+
| READ-COMMITTED |
+----------------+
1 row in set (0.00 sec)
mysql> set autocommit=0;
Query OK, 0 rows affected (0.01 sec)
|
mysql> select @@tx_isolation;
+----------------+
| @@tx_isolation |
+----------------+
| READ-COMMITTED |
+----------------+
1 row in set (0.00 sec)
mysql> set autocommit=0;
Query OK, 0 rows affected (0.01 sec)
|
mysql> select @@tx_isolation;
+----------------+
| @@tx_isolation |
+----------------+
| READ-COMMITTED |
+----------------+
1 row in set (0.00 sec)
mysql> set autocommit=0;
Query OK, 0 rows affected (0.01 sec)
|
|
Session_1獲得for update的共享鎖:
mysql> select actor_id, first_name,last_name from actor where actor_id = 201 for update;
Empty set (0.00 sec)
|
由於記錄不存在,session_2也可以獲得for update的共享鎖:
mysql> select actor_id, first_name,last_name from actor where actor_id = 201 for update;
Empty set (0.00 sec)
|
|
|
Session_1可以成功插入記錄:
mysql> insert into actor (actor_id,first_name,last_name) values(201,'Lisa','Tom');
Query OK, 1 row affected (0.00 sec)
|
||
|
Session_2插入申請等待獲得鎖:
mysql> insert into actor (actor_id,first_name,last_name) values(201,'Lisa','Tom');
等待
|
||
|
Session_1成功提交:
mysql> commit;
Query OK, 0 rows affected (0.04 sec)
|
||
|
Session_2獲得鎖,發現插入記錄主鍵重,這個時候丟擲了異常,但是並沒有釋放共享鎖:
mysql> insert into actor (actor_id,first_name,last_name) values(201,'Lisa','Tom');
ERROR 1062 (23000): Duplicate entry '201' for key 'PRIMARY'
|
||
|
Session_3申請獲得共享鎖,因為session_2已經鎖定該記錄,所以session_3需要等待:
mysql> select actor_id, first_name,last_name from actor where actor_id = 201 for update;
等待
|
||
|
這個時候,如果session_2直接對記錄進行更新操作,則會丟擲死鎖的異常:
mysql> update actor set last_name='Lan' where actor_id = 201;
ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction
|
||
|
Session_2釋放鎖後,session_3獲得鎖:
mysql> select first_name, last_name from actor where actor_id = 201 for update;
+------------+-----------+
| first_name | last_name |
+------------+-----------+
| Lisa | Tom |
+------------+-----------+
1 row in set (31.12 sec)
|
MySQL事務隔離級別詳解
http://xm-king.iteye.com/blog/770721
SQL標準定義了4類隔離級別,包括了一些具體規則,用來限定事務內外的哪些改變是可見的,哪些是不可見的。低階別的隔離級一般支援更高的併發處理,並擁有更低的系統開銷。
Read Uncommitted(讀取未提交內容)
在該隔離級別,所有事務都可以看到其他未提交事務的執行結果。本隔離級別很少用於實際應用,因為它的效能也不比其他級別好多少。讀取未提交的資料,也被稱之為髒讀(Dirty Read)。
Read Committed(讀取提交內容)
這是大多數資料庫系統的預設隔離級別(但不是MySQL預設的)。它滿足了隔離的簡單定義:一個事務只能看見已經提交事務所做的改變。這種隔離級別
也支援所謂的不可重複讀(Nonrepeatable
Read),因為同一事務的其他例項在該例項處理其間可能會有新的commit,所以同一select可能返回不同結果。
Repeatable Read(可重讀)
這是MySQL的預設事務隔離級別,它確保同一事務的多個例項在併發讀取資料時,會看到同樣的資料行。不過理論上,這會導致另一個棘手的問題:幻讀 (Phantom Read)。簡單的說,幻讀指當使用者讀取某一範圍的資料行時,另一個事務又在該範圍內插入了新行,當使用者再讀取該範圍的資料行時,會發現有新的“幻影” 行。InnoDB和Falcon儲存引擎透過多版本併發控制(MVCC,Multiversion Concurrency Control)機制解決了該問題。
Serializable(可序列化)
這是最高的隔離級別,它透過強制事務排序,使之不可能相互衝突,從而解決幻讀問題。簡言之,它是在每個讀的資料行上加上共享鎖。在這個級別,可能導致大量的超時現象和鎖競爭。
這四種隔離級別採取不同的鎖型別來實現,若讀取的是同一個資料的話,就容易發生問題。例如:
髒讀(Drity Read):某個事務已更新一份資料,另一個事務在此時讀取了同一份資料,由於某些原因,前一個RollBack了操作,則後一個事務所讀取的資料就會是不正確的。
不可重複讀(Non-repeatable read):在一個事務的兩次查詢之中資料不一致,這可能是兩次查詢過程中間插入了一個事務更新的原有的資料。
幻讀(Phantom Read):在一個事務的兩次查詢中資料筆數不一致,例如有一個事務查詢了幾列(Row)資料,而另一個事務卻在此時插入了新的幾列資料,先前的事務在接下來的查詢中,就會發現有幾列資料是它先前所沒有的。
在MySQL中,實現了這四種隔離級別,分別有可能產生問題如下所示:
下面,將利用MySQL的客戶端程式,分別測試幾種隔離級別。測試資料庫為test,表為tx;表結構:
| id | int |
|
num |
int |
兩個命令列客戶端分別為A,B;不斷改變A的隔離級別,在B端修改資料。
(一)、將A的隔離級別設定為read uncommitted(未提交讀)
在B未更新資料之前:
客戶端A: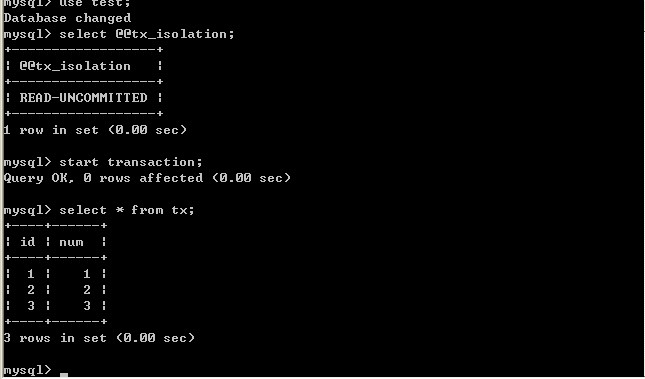
B更新資料:
客戶端B:

客戶端A:

經過上面的實驗可以得出結論,事務B更新了一條記錄,但是沒有提交,此時事務A可以查詢出未提交記錄。造成髒讀現象。未提交讀是最低的隔離級別。
(二)、將客戶端A的事務隔離級別設定為read committed(已提交讀)
在B未更新資料之前:
客戶端A:
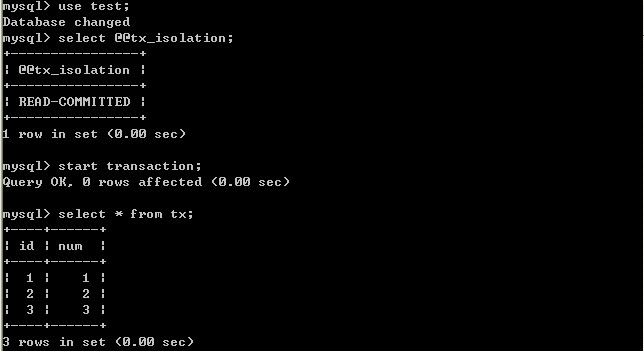
B更新資料:
客戶端B:

客戶端A:

經過上面的實驗可以得出結論,已提交讀隔離級別解決了髒讀的問題,但是出現了不可重複讀的問題,即事務A在兩次查詢的資料不一致,因為在兩次查詢之間事務B更新了一條資料。已提交讀只允許讀取已提交的記錄,但不要求可重複讀。
(三)、將A的隔離級別設定為repeatable read(可重複讀)
在B未更新資料之前:

B更新資料:
客戶端B:

客戶端A:

B插入資料:
客戶端B:

客戶端A:

由以上的實驗可以得出結論,可重複讀隔離級別只允許讀取已提交記錄,而且在一個事務兩次讀取一個記錄期間,其他事務部的更新該記錄。但該事務不要求與其他 事務可序列化。例如,當一個事務可以找到由一個已提交事務更新的記錄,但是可能產生幻讀問題(注意是可能,因為資料庫對隔離級別的實現有所差別)。像以上 的實驗,就沒有出現資料幻讀的問題。
(四)、將A的隔離級別設定為 可序列化 (Serializable)
A端開啟事務,B端插入一條記錄
事務A端:

事務B端:
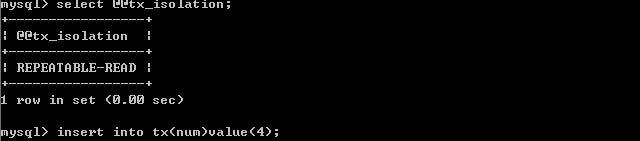
因為此時事務A的隔離級別設定為serializable,開始事務後,並沒有提交,所以事務B只能等待。
事務A提交事務:
事務A端

事務B端

serializable完全鎖定欄位,若一個事務來查詢同一份資料就必須等待,直到前一個事務完成並解除鎖定為止 。是完整的隔離級別,會鎖定對應的資料表格,因而會有效率的問題。
相關文章
- Mysql之鎖、事務絕版詳解---乾貨!2019-08-03MySql
- MySQL 事務最全詳解2019-09-09MySql
- 詳解MySQL事務原理2021-02-05MySql
- MYSQL的事務詳解2018-12-22MySql
- 詳解Mysql事務隔離級別與鎖機制2022-03-31MySql
- MySQL 中的事務詳解2019-05-02MySql
- MySQL 事務和鎖2022-04-29MySql
- MySQL事務與鎖2022-02-06MySql
- MySQL事務和鎖2022-03-16MySql
- MySQL 筆記 - 事務&鎖2018-08-17MySql筆記
- mysql之鎖與事務2018-03-24MySql
- mysql事務和鎖InnoDB2017-05-12MySql
- MySQL – 事務的啟動 / 設定 / 鎖 / 解鎖——入門2019-02-16MySql
- MySQL事務隔離級別詳解2017-10-23MySql
- MySQL鎖詳解2015-12-18MySql
- MySQL入門--事務與鎖2019-06-27MySql
- mysql鎖與事務總結2018-12-28MySql
- 【Mysql】mysql事務處理用法與例項詳解2016-08-30MySql
- Mysql系列第十五講 事務詳解2020-10-09MySql
- 轉:MySQL詳解--鎖2017-01-18MySql
- mysql 事務,鎖,隔離機制2021-06-27MySql
- Mysql事務以及加鎖機制2015-12-20MySql
- MySQL(一):MySQL資料庫事務與鎖2020-12-12MySql資料庫
- Django 事務詳解2017-08-04Django
- MySQL 核心三劍客 —— 索引、鎖、事務2020-01-06MySql索引
- mysql事務隔離級別和鎖2021-06-30MySql
- Mysql鎖與事務隔離級別2020-12-07MySql
- mysql事務處理與鎖機制2020-12-14MySql
- MySQL鎖詳解!(轉載)2018-09-21MySql
- MySQL資料庫詳解(三)MySQL的事務隔離剖析2019-06-25MySql資料庫
- 十、Redis事務、事務鎖2020-12-23Redis
- 【轉】phpmysql事務詳解2017-09-07PHPMySql
- MySql 三大知識點——索引、鎖、事務!2019-03-22MySql索引
- MySQL中的事務原理和鎖機制2020-11-30MySql
- 對線面試官:MySQL 事務、鎖和MVCC2022-05-30面試MySqlMVC
- SqlServer事務詳解(事務隔離性和隔離級別詳解)2021-05-31SQLServer
- MySQL資料庫-鎖詳解2023-02-05MySql資料庫
- Mysql加鎖過程詳解(4)-select for update/lock in share mode 對事務併發性影響2017-09-30MySql