那本書的第八章,寫了一個非常具體的技術問題----如何使用貝葉斯推斷過濾垃圾郵件(英文版)。
我沒完全看懂那一章。當時是硬著頭皮,按照字面意思把它譯出來的。雖然譯文質量還可以,但是心裡很不舒服,下決心一定要搞懂它。
一年過去了,我讀了一些機率論文獻,逐漸發現貝葉斯推斷並不難。原理的部分相當容易理解,不需要用到高等數學。
下面就是我的學習筆記。需要宣告的是,我並不是這方面的專家,數學其實是我的弱項。歡迎大家提出寶貴意見,讓我們共同學習和提高。
=====================================
貝葉斯推斷及其網際網路應用
作者:阮一峰
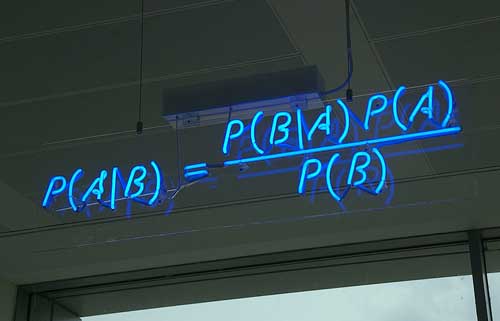
一、什麼是貝葉斯推斷
貝葉斯推斷(Bayesian inference)是一種統計學方法,用來估計統計量的某種性質。
它是貝葉斯定理(Bayes' theorem)的應用。英國數學家托馬斯·貝葉斯(Thomas Bayes)在1763年發表的一篇論文中,首先提出了這個定理。

貝葉斯推斷與其他統計學推斷方法截然不同。它建立在主觀判斷的基礎上,也就是說,你可以不需要客觀證據,先估計一個值,然後根據實際結果不斷修正。正是因為它的主觀性太強,曾經遭到許多統計學家的詬病。
貝葉斯推斷需要大量的計算,因此歷史上很長一段時間,無法得到廣泛應用。只有計算機誕生以後,它才獲得真正的重視。人們發現,許多統計量是無法事先進行客觀判斷的,而網際網路時代出現的大型資料集,再加上高速運算能力,為驗證這些統計量提供了方便,也為應用貝葉斯推斷創造了條件,它的威力正在日益顯現。
二、貝葉斯定理
要理解貝葉斯推斷,必須先理解貝葉斯定理。後者實際上就是計算"條件機率"的公式。
所謂"條件機率"(Conditional probability),就是指在事件B發生的情況下,事件A發生的機率,用P(A|B)來表示。
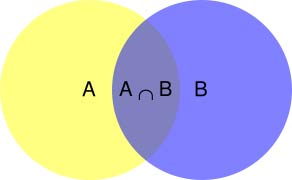
根據文氏圖,可以很清楚地看到在事件B發生的情況下,事件A發生的機率就是P(A∩B)除以P(B)。
因此,
同理可得,
所以,
即
這就是條件機率的計算公式。
三、全機率公式
由於後面要用到,所以除了條件機率以外,這裡還要推導全機率公式。
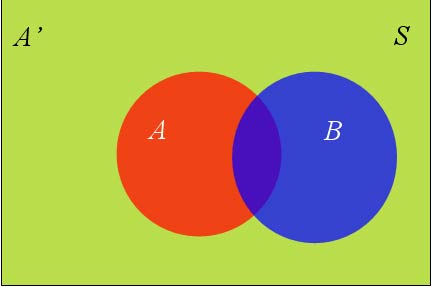
假定樣本空間S,是兩個事件A與A'的和。

上圖中,紅色部分是事件A,綠色部分是事件A',它們共同構成了樣本空間S。
在這種情況下,事件B可以劃分成兩個部分。
即
在上一節的推導當中,我們已知
所以,
這就是全機率公式。它的含義是,如果A和A'構成樣本空間的一個劃分,那麼事件B的機率,就等於A和A'的機率分別乘以B對這兩個事件的條件機率之和。
將這個公式代入上一節的條件機率公式,就得到了條件機率的另一種寫法:
四、貝葉斯推斷的含義
對條件機率公式進行變形,可以得到如下形式:
我們把P(A)稱為"先驗機率"(Prior probability),即在B事件發生之前,我們對A事件機率的一個判斷。P(A|B)稱為"後驗機率"(Posterior probability),即在B事件發生之後,我們對A事件機率的重新評估。P(B|A)/P(B)稱為"可能性函式"(Likelyhood),這是一個調整因子,使得預估機率更接近真實機率。
所以,條件機率可以理解成下面的式子:
這就是貝葉斯推斷的含義。我們先預估一個"先驗機率",然後加入實驗結果,看這個實驗到底是增強還是削弱了"先驗機率",由此得到更接近事實的"後驗機率"。
在這裡,如果"可能性函式"P(B|A)/P(B)>1,意味著"先驗機率"被增強,事件A的發生的可能性變大;如果"可能性函式"=1,意味著B事件無助於判斷事件A的可能性;如果"可能性函式"<,意味著"先驗機率"被削弱,事件A的可能性變小。
五、【例子】水果糖問題
為了加深對貝葉斯推斷的理解,我們看兩個例子。
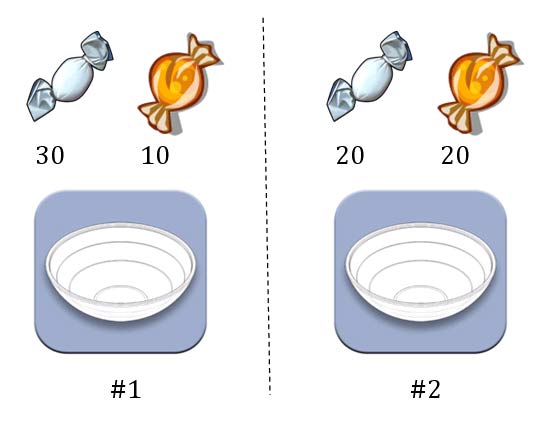
第一個例子。兩個一模一樣的碗,一號碗有30顆水果糖和10顆巧克力糖,二號碗有水果糖和巧克力糖各20顆。現在隨機選擇一個碗,從中摸出一顆糖,發現是水果糖。請問這顆水果糖來自一號碗的機率有多大?
我們假定,H1表示一號碗,H2表示二號碗。由於這兩個碗是一樣的,所以P(H1)=P(H2),也就是說,在取出水果糖之前,這兩個碗被選中的機率相同。因此,P(H1)=0.5,我們把這個機率就叫做"先驗機率",即沒有做實驗之前,來自一號碗的機率是0.5。
再假定,E表示水果糖,所以問題就變成了在已知E的情況下,來自一號碗的機率有多大,即求P(H1|E)。我們把這個機率叫做"後驗機率",即在E事件發生之後,對P(H1)的修正。
根據條件機率公式,得到
已知,P(H1)等於0.5,P(E|H1)為一號碗中取出水果糖的機率,等於0.75,那麼求出P(E)就可以得到答案。根據全機率公式,
所以,
將數字代入原方程,得到
這表明,來自一號碗的機率是0.6。也就是說,取出水果糖之後,H1事件的可能性得到了增強。
六、【例子】假陽性問題
第二個例子是一個醫學的常見問題,與現實生活關係緊密。

已知某種疾病的發病率是0.001,即1000人中會有1個人得病。現有一種試劑可以檢驗患者是否得病,它的準確率是0.99,即在患者確實得病的情況下,它有99%的可能呈現陽性。它的誤報率是5%,即在患者沒有得病的情況下,它有5%的可能呈現陽性。現有一個病人的檢驗結果為陽性,請問他確實得病的可能性有多大?
假定A事件表示得病,那麼P(A)為0.001。這就是"先驗機率",即沒有做試驗之前,我們預計的發病率。再假定B事件表示陽性,那麼要計算的就是P(A|B)。這就是"後驗機率",即做了試驗以後,對發病率的估計。
根據條件機率公式,
用全機率公式改寫分母,
將數字代入,
我們得到了一個驚人的結果,P(A|B)約等於0.019。也就是說,即使檢驗呈現陽性,病人得病的機率,也只是從0.1%增加到了2%左右。這就是所謂的"假陽性",即陽性結果完全不足以說明病人得病。
為什麼會這樣?為什麼這種檢驗的準確率高達99%,但是可信度卻不到2%?答案是與它的誤報率太高有關。(【習題】如果誤報率從5%降為1%,請問病人得病的機率會變成多少?)
有興趣的朋友,還可以算一下"假陰性"問題,即檢驗結果為陰性,但是病人確實得病的機率有多大。然後問自己,"假陽性"和"假陰性",哪一個才是醫學檢驗的主要風險?
===================================
關於貝葉斯推斷的原理部分,今天就講到這裡。下一次,將介紹如何使用貝葉斯推斷過濾垃圾郵件。
(未完待續)