這個系列的前兩部分就是很好的例子。僅僅依靠統計詞頻,就能找出關鍵詞和相似文章。雖然它們算不上效果最好的方法,但肯定是最簡便易行的方法。
今天,依然繼續這個主題。討論如何透過詞頻,對文章進行自動摘要(Automatic summarization)。

如果能從3000字的文章,提煉出150字的摘要,就可以為讀者節省大量閱讀時間。由人完成的摘要叫"人工摘要",由機器完成的就叫"自動摘要"。許多網站都需要它,比如論文網站、新聞網站、搜尋引擎等等。2007年,美國學者的論文《A Survey on Automatic Text Summarization》(Dipanjan Das, Andre F.T. Martins, 2007)總結了目前的自動摘要演算法。其中,很重要的一種就是詞頻統計。
這種方法最早出自1958年的IBM公司科學家H.P. Luhn的論文《The Automatic Creation of Literature Abstracts》。
Luhn博士認為,文章的資訊都包含在句子中,有些句子包含的資訊多,有些句子包含的資訊少。"自動摘要"就是要找出那些包含資訊最多的句子。
句子的資訊量用"關鍵詞"來衡量。如果包含的關鍵詞越多,就說明這個句子越重要。Luhn提出用"簇"(cluster)表示關鍵詞的聚集。所謂"簇"就是包含多個關鍵詞的句子片段。
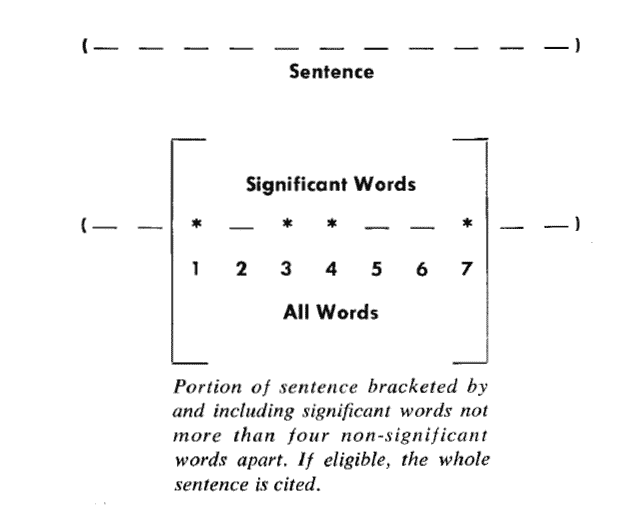
上圖就是Luhn原始論文的插圖,被框起來的部分就是一個"簇"。只要關鍵詞之間的距離小於"門檻值",它們就被認為處於同一個簇之中。Luhn建議的門檻值是4或5。也就是說,如果兩個關鍵詞之間有5個以上的其他詞,就可以把這兩個關鍵詞分在兩個簇。
下一步,對於每個簇,都計算它的重要性分值。

以前圖為例,其中的簇一共有7個詞,其中4個是關鍵詞。因此,它的重要性分值等於 ( 4 x 4 ) / 7 = 2.3。
然後,找出包含分值最高的簇的句子(比如5句),把它們合在一起,就構成了這篇文章的自動摘要。具體實現可以參見《Mining the Social Web: Analyzing Data from Facebook, Twitter, LinkedIn, and Other Social Media Sites》(O'Reilly, 2011)一書的第8章,python程式碼見github。
Luhn的這種演算法後來被簡化,不再區分"簇",只考慮句子包含的關鍵詞。下面就是一個例子(採用偽碼錶示),只考慮關鍵詞首先出現的句子。
// 計算原始文字的詞頻,生成一個陣列,比如[(10,'the'), (3,'language'), (8,'code')...]
wordFrequences = getWordCounts(originalText)// 過濾掉停用詞,陣列變成[(3, 'language'), (8, 'code')...]
contentWordFrequences = filtStopWords(wordFrequences)// 按照詞頻進行排序,陣列變成['code', 'language'...]
contentWordsSortbyFreq = sortByFreqThenDropFreq(contentWordFrequences)// 將文章分成句子
sentences = getSentences(originalText)// 選擇關鍵詞首先出現的句子
setSummarySentences = {}
foreach word in contentWordsSortbyFreq:
firstMatchingSentence = search(sentences, word)
setSummarySentences.add(firstMatchingSentence)
if setSummarySentences.size() = maxSummarySize:
break// 將選中的句子按照出現順序,組成摘要
summary = ""
foreach sentence in sentences:
if sentence in setSummarySentences:
summary = summary + " " + sentencereturn summary
類似的演算法已經被寫成了工具,比如基於Java的Classifier4J庫的SimpleSummariser模組、基於C語言的OTS庫、以及基於classifier4J的C#實現和python實現。
(完)