這個標題看上去好像很複雜,其實我要談的是一個很簡單的問題。
有一篇很長的文章,我要用計算機提取它的關鍵詞(Automatic Keyphrase extraction),完全不加以人工干預,請問怎樣才能正確做到?

這個問題涉及到資料探勘、文字處理、資訊檢索等很多計算機前沿領域,但是出乎意料的是,有一個非常簡單的經典演算法,可以給出令人相當滿意的結果。它簡單到都不需要高等數學,普通人只用10分鐘就可以理解,這就是我今天想要介紹的TF-IDF演算法。
讓我們從一個例項開始講起。假定現在有一篇長文《中國的蜜蜂養殖》,我們準備用計算機提取它的關鍵詞。

一個容易想到的思路,就是找到出現次數最多的詞。如果某個詞很重要,它應該在這篇文章中多次出現。於是,我們進行"詞頻"(Term Frequency,縮寫為TF)統計。
結果你肯定猜到了,出現次數最多的詞是----"的"、"是"、"在"----這一類最常用的詞。它們叫做"停用詞"(stop words),表示對找到結果毫無幫助、必須過濾掉的詞。
假設我們把它們都過濾掉了,只考慮剩下的有實際意義的詞。這樣又會遇到了另一個問題,我們可能發現"中國"、"蜜蜂"、"養殖"這三個詞的出現次數一樣多。這是不是意味著,作為關鍵詞,它們的重要性是一樣的?
顯然不是這樣。因為"中國"是很常見的詞,相對而言,"蜜蜂"和"養殖"不那麼常見。如果這三個詞在一篇文章的出現次數一樣多,有理由認為,"蜜蜂"和"養殖"的重要程度要大於"中國",也就是說,在關鍵詞排序上面,"蜜蜂"和"養殖"應該排在"中國"的前面。
所以,我們需要一個重要性調整係數,衡量一個詞是不是常見詞。如果某個詞比較少見,但是它在這篇文章中多次出現,那麼它很可能就反映了這篇文章的特性,正是我們所需要的關鍵詞。
用統計學語言表達,就是在詞頻的基礎上,要對每個詞分配一個"重要性"權重。最常見的詞("的"、"是"、"在")給予最小的權重,較常見的詞("中國")給予較小的權重,較少見的詞("蜜蜂"、"養殖")給予較大的權重。這個權重叫做"逆文件頻率"(Inverse Document Frequency,縮寫為IDF),它的大小與一個詞的常見程度成反比。
知道了"詞頻"(TF)和"逆文件頻率"(IDF)以後,將這兩個值相乘,就得到了一個詞的TF-IDF值。某個詞對文章的重要性越高,它的TF-IDF值就越大。所以,排在最前面的幾個詞,就是這篇文章的關鍵詞。
下面就是這個演算法的細節。
第一步,計算詞頻。

考慮到文章有長短之分,為了便於不同文章的比較,進行"詞頻"標準化。

或者

第二步,計算逆文件頻率。
這時,需要一個語料庫(corpus),用來模擬語言的使用環境。
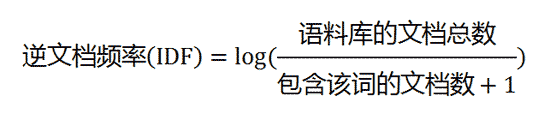
如果一個詞越常見,那麼分母就越大,逆文件頻率就越小越接近0。分母之所以要加1,是為了避免分母為0(即所有文件都不包含該詞)。log表示對得到的值取對數。
第三步,計算TF-IDF。
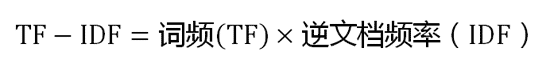
可以看到,TF-IDF與一個詞在文件中的出現次數成正比,與該詞在整個語言中的出現次數成反比。所以,自動提取關鍵詞的演算法就很清楚了,就是計算出文件的每個詞的TF-IDF值,然後按降序排列,取排在最前面的幾個詞。
還是以《中國的蜜蜂養殖》為例,假定該文長度為1000個詞,"中國"、"蜜蜂"、"養殖"各出現20次,則這三個詞的"詞頻"(TF)都為0.02。然後,搜尋Google發現,包含"的"字的網頁共有250億張,假定這就是中文網頁總數。包含"中國"的網頁共有62.3億張,包含"蜜蜂"的網頁為0.484億張,包含"養殖"的網頁為0.973億張。則它們的逆文件頻率(IDF)和TF-IDF如下:
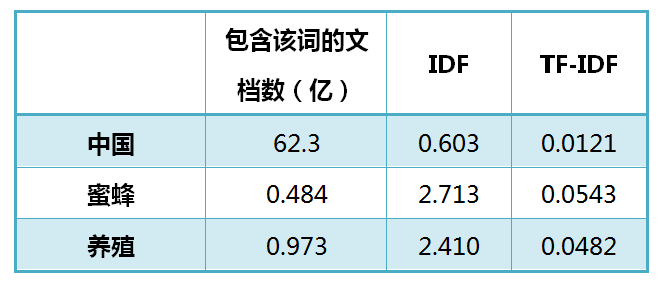
從上表可見,"蜜蜂"的TF-IDF值最高,"養殖"其次,"中國"最低。(如果還計算"的"字的TF-IDF,那將是一個極其接近0的值。)所以,如果只選擇一個詞,"蜜蜂"就是這篇文章的關鍵詞。
除了自動提取關鍵詞,TF-IDF演算法還可以用於許多別的地方。比如,資訊檢索時,對於每個文件,都可以分別計算一組搜尋詞("中國"、"蜜蜂"、"養殖")的TF-IDF,將它們相加,就可以得到整個文件的TF-IDF。這個值最高的文件就是與搜尋詞最相關的文件。
TF-IDF演算法的優點是簡單快速,結果比較符合實際情況。缺點是,單純以"詞頻"衡量一個詞的重要性,不夠全面,有時重要的詞可能出現次數並不多。而且,這種演算法無法體現詞的位置資訊,出現位置靠前的詞與出現位置靠後的詞,都被視為重要性相同,這是不正確的。(一種解決方法是,對全文的第一段和每一段的第一句話,給予較大的權重。)
下一次,我將用TF-IDF結合餘弦相似性,衡量文件之間的相似程度。
(完)