《流暢的 Python》讀書筆記
兩個問題
學了 Python 基礎就夠了嗎?
前言的引言給出了答案:
要不這樣吧,如果程式語言裡有個地方你弄不明白,而正好又有個人用了這個功能,那就開槍把他打死。這比學習新特性要容易些,然後過不了多久,那些活下來的程式設計師就會開始用 0.9.6 版的 Python,而且他們只需要使用這個版本中易於理解的那一小部分就好了(眨眼) 。
—— Tim Peters
傳奇的核心開發者, “Python 之禪”作者
這本書的目的是什麼?
第十一章的雜談裡給出了答案:
這正是本書的主要目的:著重講解這門語言的基本慣用法,讓你的程式碼簡潔、高效且可讀,把你打造成熟練的 Python 程式設計師。
另外本書的前言裡也有提及書本的目標讀者和非目標讀者。
如果你才剛剛開始學 Python,本書的內容可能會顯得有些“超綱”。比難懂更糟的是,如果在學習 Python 的過程中過早接觸本書的內容,你可能會誤以為所有的 Python 程式碼都應該利用特殊方法和超程式設計(metaprogramming)技巧。我們知道,不成熟的抽象和過早的優化一樣,都會壞事。
對內容的一些評價
從書目錄結構來看,作者的眼界十分開闊,每章最後有小結、延伸閱讀、和相關的一些雜談。書的前一部分從 Python 特性出發,參考了很多語言的相關做法和實現,來解釋 Python 的設計。
書中時常引用一些參考資料,有些是郵件列表裡的討論、維基百科、一些十分優秀的程式設計師的撰寫的文章和演講視訊。這意味著你可以在某一個概念看到不同的觀點,看到優秀的程式設計師是怎麼思考一個問題的。
作者從1998年成為了 Python 程式設計師,是巴西一家培訓機構的共同所有者,也為巴西的媒體、銀行和政府部門教授 Python 課程,由此可見本書的程式碼會是十分透徹和淺顯易懂的,事實也的確如此。從程式碼示例來看,作者為大部分程式碼提供了 doctest 測試,並且在為某一個知識點提供程式碼示例時,追求的是簡單、直接,同時示例的難度是循序漸進的。加上作者在大部分程式碼行提供了說明,讓讀者能十分流暢地理解概念。(對比:《Go 程式設計語言》講複數語法時用 Mandelbrot 影像作為示例,苦笑)
對翻譯的一些評價
整體翻譯還是不錯的,幾百頁的書的勘誤也才十多個,部分術語可能還要參考書裡的術語翻譯表,個人認為容易弄混的有特性(properties)和屬性(attributes),還有函式(function)和方法(method)。後者的區別可以參考Difference between a method and a function,簡單的說法就是函式(function)定義在類外面,而方法(method)定義在類裡面,是類的一部分。兩者也可以根據是否獨立於物件來判斷。
黃志斌:這本書第2次印刷時已經把“期物”改為“future”了。
P21 前面那種方式顯然能夠節省記憶體。 前者指的是 genexp,即生成器表示式。
章節簡介
這本書的結構十分優秀,每一章節都有前言和小結,因此章節簡介我偏向於寫些零散的知識點和個人感受,會比較亂。大部分章節的章節簡介最後會有個人閱讀時做的筆記,章節簡介沒提及的內容可以看看我的筆記。
全部的筆記還可以在這裡找到:Latias94/fluent-python-notes
第一章
第一章作者就介紹了 Python 中的特殊方法,特殊方法也是貫穿這本書的基礎。
讀這本書之前,自己通常會遇到__init__、__new__、__name__ == '__main__'等等的帶雙下劃線的特殊方法,但是通過零散的知識點很難形成體系,而這本書涵蓋了絕大部分的特殊方法,並且分章節詳細地討論其背後特殊方法的作用,而這一章就是了解特殊方法的第一步。
作者提到了合理的字串表示形式:__repr__ 和 __str__。前者方便我們除錯和記錄日誌,後者則是給終端使用者看的。
作者開篇就提出了兩個問題,第一個問題是:
為什麼說 Python 最好的品質之一是一致性?
並且在第十二頁給出了答案:
不能讓特例特殊到開始破壞既定規則。
第二個問題是:
len(collection)和collection.len()有什麼不同?和“Python 風格” (Pythonic)有什麼關係?
核心開發者 Raymond Hettinger 的答案是:
實用勝於純粹
practicality beats purity
——《The Zen of Python》
作者給出解釋:
len 是特殊方法,是為了讓 Python 自帶的資料結構可以走後門,abs 也是同理。(解釋:因為如果 x 是一個內建型別的例項,
len(x)的背後會用 CPython 直接從 C 結構體中讀取物件的長度,不呼叫任何方法,以至於len(x)會非常快。)
...
這種處理方式在保持內建型別的效率和保證語言的一致性之間找到了一個平衡點,也印證了“Python 之禪”中的另外一句話:"不能讓特例特殊到開始破壞既定規則。"
從這兩個問題就能看出作者想要強調的是:「Python 風格 無處不在」。為了更好地理解 Python 實現,最好了解 Python 的設計風格。
筆記傳送門:特殊方法
第二章
第二三四章主講 Python 資料結構及其背後的實現,而第二章主要講了可變型別與不可變型別的區別。
要想寫出準確、高效和地道的 Python 程式碼,對標準庫裡的序列型別的掌握是不可或缺的。資料結構的產生就是為了滿足各種不同的需求,例如能讓使用者在不復制內容的情況下操作同一個陣列的不同切片的 memoryview,能高效處理矩陣、向量等高階數值運算的 NumPy 和專為線性代數、數值積分和統計學而設計並基於 NumPy 的 SciPy。電腦科學家主要抽象了幾大資料型別:字典、陣列、列表等,這些資料型別都有不同的使用環境,使用好這些工具能讓你事半功倍、節省不必要的消耗。
另外,在讀這本書的前幾天,我剛好在 Segmentfault 裡面看到一個問題 python小白 問關於a+=a 和a=a+a的區別,當時看完答案還有點似懂非懂的感覺,而讀完這章我能完全理解其區別所在了。
擴充套件閱讀:problem-solving-with-algorithms-and-data-structure-using-python 中文版
筆記傳送門:序列構成的陣列
第三章
前一章提到了列表、元組這兩種序列,以及它們的生成器表示式。這一章則介紹了雜湊表的基本概念、其背後的演算法和由雜湊表實現的資料型別:字典和集合。
- 由於字典是由雜湊表實現的,因此字典的鍵必須是可雜湊的。
- set 型別本身不是可雜湊的(因為 set 是可變的),但其元素必須可雜湊。(這也是為什麼 list 不能作為字典鍵的原因)
- frozenset 是可雜湊的。
- 雜湊表的實現導致它實現的資料型別效率很高,但這是以犧牲空間的代價所帶來的。
"優化往往是可維護性的對立面"
由於字典使用了雜湊表,而雜湊表又必須是稀疏的,這導致它在空間上的效率低下。舉例而言,如果你需要存放數量巨大的記錄,那麼放在由元組或是具名元組構成的列表中會是比較好的選擇;最好不要根據 JSON 的風格,用由字典組成的列表來存放這些記錄。用元組取代字典就能節省空間的原因有兩個:其一是避免了雜湊表所耗費的空間,其二是無需把記錄中欄位的名字在每個元素裡都存一遍。
筆記傳送門:字典和集合
第四章
目前沒遇到過編碼問題,不看。
第五章
第五章的主題是:高階函式沒這麼重要了。
先來一段吐槽:
Lundh 提出的 lambda 表示式重構祕笈如果使用 lambda 表示式導致一段程式碼難以理解,Fredrik Lundh 建議像下面這樣重構。
(1) 編寫註釋,說明 lambda 表示式的作用。
(2) 研究一會兒註釋,並找出一個名稱來概括註釋。
(3) 把 lambda 表示式轉換成 def 語句,使用那個名稱來定義函式。
(4) 刪除註釋。
摘自“Functional Programming HOWTO”
現在函數語言程式設計十分流行,但 Python 獨特的語法使得 lambda、map、filter 和 reduce 這些函式沒這麼重要了,因為我們有 sum、all 等歸約函式,還有 sorted、min、max 和 functools 這樣的內建的高階函式。
最後(5.10.2小節)講了一個和函式柯里化(Currying)十分相像的概念——偏函式(Partial Application),這兩者概念其實不一樣。
筆記傳送門:一等函式
第六章
作者從策略模式開始,討論了一等函式在設計模式中的角色,並用一等函式簡化了設計模式的實現方式,以此來展示 Pythonic 的設計模式應該是什麼樣子的。
擴充套件閱讀:設計模式的python實現
筆記傳送門:使用一等函式實現設計模式
第七章
第七章介紹了裝飾器和閉包,作者給閉包下了一個清晰的定義:
閉包指延伸了作用域的函式,其中包含函式定義體中引用、但是不在定義體中定義的非全域性變數。函式是不是匿名的沒有關係,關鍵是它能訪問定義體之外定義的非全域性變數。
作者用一個閉包例項和作用相同的類來比較,引出了自由變數(free variable)的概念,以此指出閉包與普通函式不一樣的地方——閉包會保留定義函式時存在的自由變數的繫結。在此之後,再引出可變型別與不可變型別對自由變數的影響,從而引出可能導致閉包失效的原因(第二章的主題:可變型別與不可變型別的區別),同時給出瞭解決辦法:nonlocal 宣告。
本章結尾的雜談提到了「一般來說,實現“裝飾器”模式時最好使用類表示裝飾器和要包裝的元件。」,也就是通過實現 __call__ 方法的類來實現裝飾器。遺憾的是本書只通過函式來解說裝飾器以助於理解,類裝飾器沒有提及多少。
筆記傳送門:函式裝飾器和閉包
第八章
不可變集合不變的是所含物件的標識。
第八章中,作者從「元組是不可變的,但是其中的值可以改變」引申到淺複製和深複製的區別。

淺複製帶來的影響可以參考 example(點 foward 顯示下一步)
作者還提到了兩個容易忽略的函式引數引用問題:
- 不要使用可變型別作為引數的預設值
- 防禦可變引數
最後一節討論垃圾回收、del 命令,以及如何使用弱引用“記住”物件,而無需物件本身存在。
另外這章有意思的地方在於作者提到了一個常見的說法錯誤:「對引用式變數來說,說把變數分配給物件更合理,反過來說就有問題。畢竟物件在賦值之前就建立了。」
筆記傳送門:物件引用、可變性和垃圾回收
第九章
要構建符合 Python 風格的物件,就要觀察真正的 Python 物件的行為。
——古老的中國諺語
第九章主要講如何編寫 Pythonic 的物件。作者從構建一個 Vector 型別來介紹符合 Python 風格的類需要注意的地方,例如__repr__不要硬編碼類名、類屬性的私有化、格式規範微語言、雜湊化要注意的條件等。
作者還講了構建一個可雜湊的型別所需要實現的條件:
- 正確的實現
__hash__和__eq__方法 - 不一定要實現只讀屬性,但是要保證例項的雜湊值絕不能變化。
類屬性用於為例項屬性提供預設值。Django 的類檢視也大量用到了這個特性。
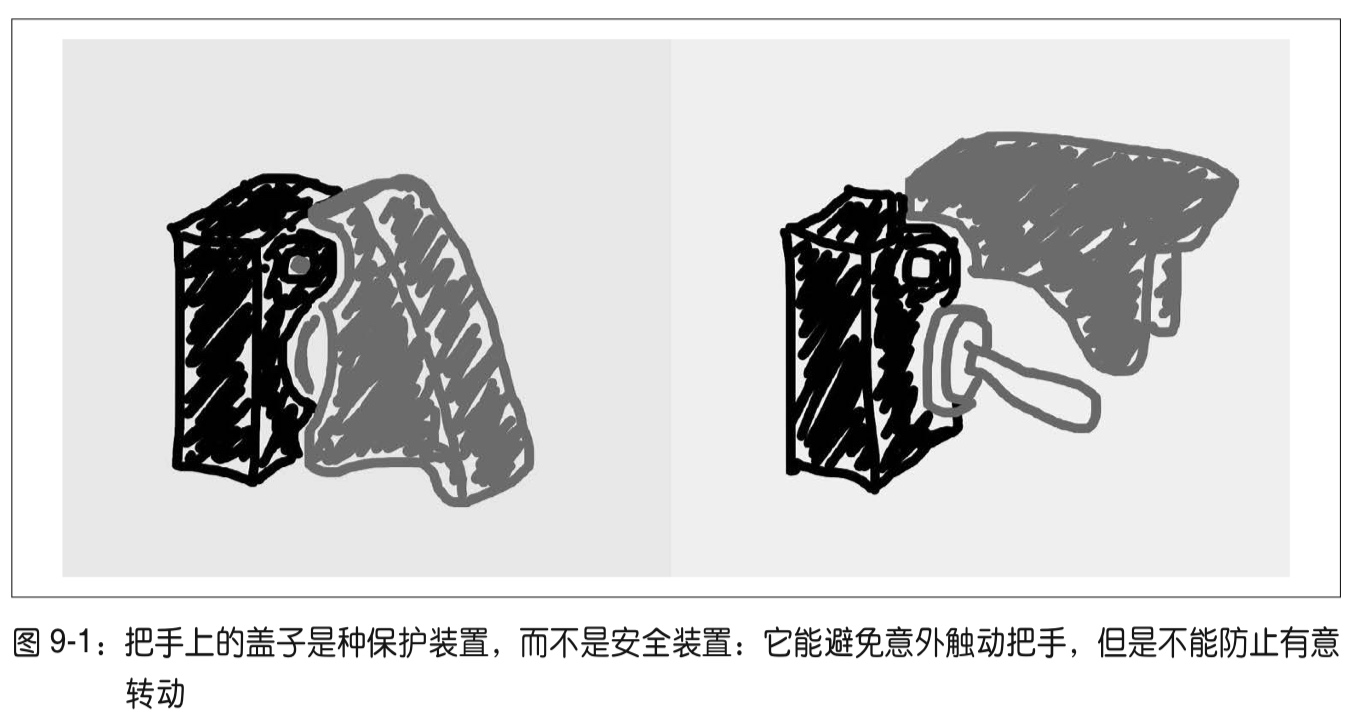
個人十分喜歡名稱改寫(屬性的私有化)中的一張示意圖: 「避免意外訪問,但不能防止故意做錯事。」,以此來提醒名稱改寫所實現的私有化自身的缺陷。
筆記傳送門:符合 Python 風格的物件
第十章
不要檢查它是不是鴨子、它的叫聲像不像鴨子、它的走路姿勢像不像鴨子,等等。具體檢查什麼取決於你想使用語言的哪些行為。 (comp.lang.python,2000 年 7 月 26 日)
——Alex Martelli
其中介紹了鴨子型別,指忽略物件的真正型別,轉而關注物件有沒有實現所需的方法、簽名和語義。在 Python 中指免使用 isinstance 檢查物件的型別。
如果我想實現一個序列,可以實現__init__、__len__、__getitem__等一序列的方法,使其行為像序列,那麼這就是一個序列,這也就是人們所稱的鴨子型別(duck typing)。
自己的理解:要明白自己希望的鴨子有哪些特性,只要我實現出來了,那麼這就是鴨子。
Tips:
- 可以用
dir(slice)來檢視序列的屬性 - 當 Python 庫文件查詢不到方法的文件的時候,可以嘗試用
help(slice.indices)來查詢。( 直接查詢__doc__屬性的資訊 )
第四小節講可切片的序列需要關注的兩個問題:
如果建立的序列內部由陣列(或其他序列)實現,那麼就要考慮切片物件的實現:切片返回的是自建立的序列物件 還是陣列(或其他序列)?如果需要考慮,就是在
__getitem__方法裡修改其實現方式。動態存取屬性,使序列能通過名稱訪問序列的屬性(v.x,v.y代替v[0],v[1])。也提到了實現
__getitem__時可能會產生的問題,和解決方法。
章節末尾的雜談提到了要遵循 KISS 原則(Keep it simple, stupid),不要過度設計協議。
筆記傳送門:序列的修改、雜湊和切片
第十一章
本章討論的話題是介面:從鴨子型別的代表特徵動態協議,到使介面更明確、能驗證實現是否符合規定的抽象基類(Abstract Base Class,ABC)
我們可能不需要寫抽象基類,但是閱讀本章能夠教我們怎麼閱讀標準庫和其他包中的抽象基類原始碼。
其中,作者引用了 Alex Martelli 的一篇文章,用表型系統學(phenetics)和支序系統學(cladistics)用水禽來類比抽象基類。(⊙﹏⊙)b
其中有第十章提到的「鴨子型別」,還有以前沒提過的、描述一種新的 Python 程式設計風格的「白鵝型別」(goose typing)。
白鵝型別指,只要 cls 是抽象基類,即 cls 的元類是
abc.ABCMeta,就可以使用isinstance(obj, cls)。
對此,作者在章節小結裡面提到:
藉助「白鵝型別」,可以使用抽象基類明確宣告介面,而且類可以子類化抽象基類或使用抽象基類註冊(無需在繼承關係中確立靜態的強連結),宣稱它實現了某個介面。
本章最後還介紹了和 Go 語言協議的功能十分類似的 __subclasshook__ 方法。
筆記傳送門:介面:從協議到抽象基類
第十二章
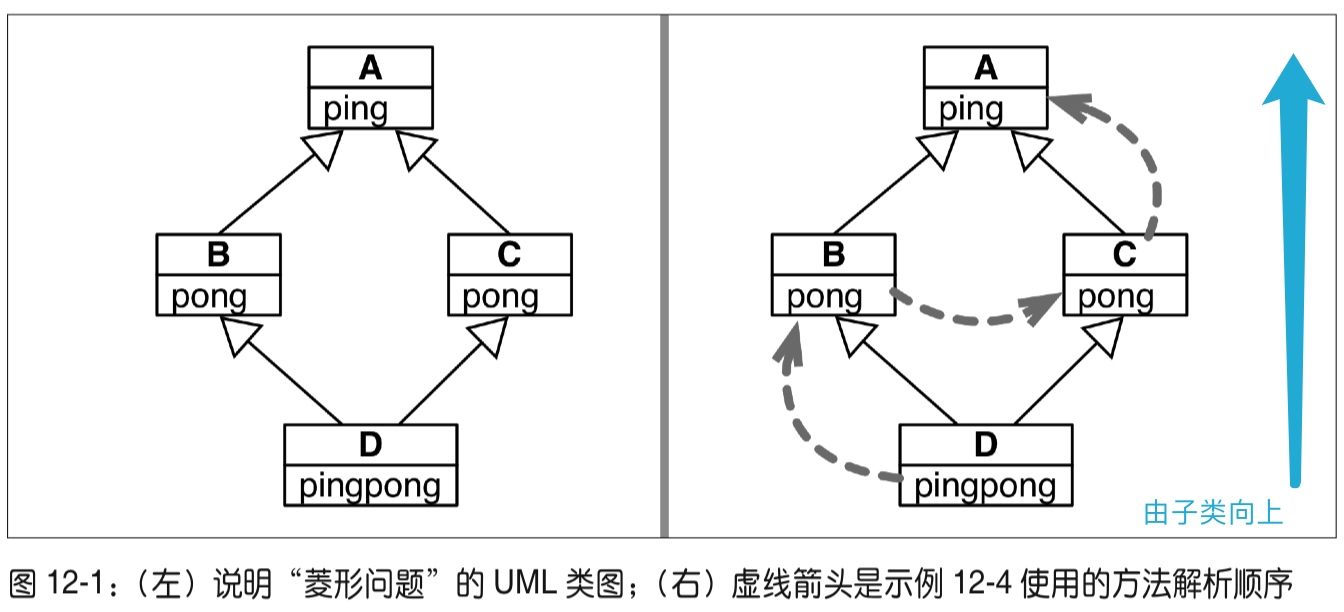
分析 GUI 工具包 Tkhinter 的多重繼承,並且展開分析了多次繼承所帶來的「菱形問題」,以及 Python 對應的解決方案——方法解析順序(Method Resolution Order,MRO),最後作者給了八條關於處理多重繼承的建議。
9.5.1. Multiple Inheritance 裡面提到了繼承順序是深度優先從左至右不重複。
For most purposes, in the simplest cases, you can think of the search for attributes inherited from a parent class as depth-first, left-to-right, not searching twice in the same class where there is an overlap in the hierarchy.
筆記傳送門:繼承的優缺點
第十三章
第十三章介紹了過載運算子的時候要考慮多重情況。
In the face of ambiguity, refuse the temptation to guess.
面對太多的可能,不要嘗試猜測。(ZoomQuiet禪譯)
——《The Zen of Python》
我們要嚴謹地對待可能會出現的運算元。
對於為什麼需要過載運算子,在雜談中作者提到了對於一部分人來說,過載運算子是十分重要的,符合人類直覺的表示法十分重要,例如金融工作會接觸到一些由不同型別的引數(整數、或其他精度的數字)組成的公式。相比於不支援運算子過載的 Go 與 Java 語言,Python 採取了折中的方式,允許過載運算子,也有一些限制,如:不能過載內建型別的運算子、不能新建運算子、一些運算子也不能過載(is、and、or、not)。
筆記傳送門:正確過載運算子
第十四章
作者分別介紹了迭代器、生成器表示式和生成器函式,並詳細地列舉了每個標準庫生成器函式的用法。
前面介紹過 Python 內建的資料型別,如列表和元組,能讓我們高效地訪問資料集,但這些序列只能表示已知且長度有限的資料集。要表示無限長度的資料集,例如斐波拉契數列,就需要用到新的構造方式,這也是本章的話題的由來。
掃描記憶體中放不下的資料集時,我們要找到一種惰性獲取資料項的方式,即按需一次獲取一個資料項。這就是迭代器模式(Iterator pattern) 。
其中作者依然很注意用詞,生成器是 "yields or produces" 生成值,而不是 "returns" 返回值,這樣有助於理解生成器獲取結果的過程,因為生成器不是以「常規」方式返回值的。
筆記傳送門:可迭代的物件、迭代器和生成器
第十五章
介紹了 else 的三種用法與上下文管理器和 with 的作用,作者用__enter__、__exit__等方法手動地實現了一個上下文管理器,還介紹了 @contextmanager 作為另外一種更優雅的實現上下文管理器的方法。其中 @contextmanager 的 yield 語句也引出了第十六章中協程的概念。
筆記傳送門:上下文管理器和else塊
第十六章
建議看第十六、十七、十八章之前先理解五個概念:執行緒、程式、協程、併發和並行。
自己參考了:
在本章中,作者介紹瞭如何構建協程,和協程的一些使用場景,章節末尾,作者舉了一個離散事件模擬示例,說明如何使用生成器代替執行緒和回撥,實現併發。
在前些章節的基礎上,作者在這章提到 yield 可以看做是控制流程的方式,即 yield 能獲取值(.send(foo)),也能產出值(foo = yield),還能不獲取和產出值(yield 後沒有表示式)。因此,我們能用它來構建協程。
不管資料如何流動,yield 都是一種流程控制工具,使用它可以實現協作式多工:協程可以把控制器讓步給中心排程程式,從而啟用其他的協程。
除了呼叫 .send(...) 方法傳送資料,本章還介紹使用 yield from 結構驅動的生成器函式。
擴充套件閱讀:
SICP in Python 有一段關於平行計算的非常精彩的解釋:4.3 平行計算
SICP in Python 中協程的一節裡著重講了將複雜程式解構為小型、模組化元件的技巧:5.3 協程
筆記傳送門:協程
第十七章
併發是電腦科學中最難的概念之一(通常最好別去招惹它) 。
——David Beazley Python 教練和科學狂人
在第十七章,作者用一個下載國旗圖片的例子來介紹網路下載的三種風格:依序下載、concurrent.futures 模組(ThreadPoolExecutor 和 ProcessPoolExecutor 類)實現的併發下載和 asyncio 包實現的併發下載。作者還介紹了阻塞性 I/O 和 GIL,最後介紹瞭如何藉助 concurrent.futures.ProcessPoolExecutor 類使用多程式。
future 指一種物件,表示非同步執行的操作。
早期的計算機從單使用者作業系統(同一時間只能執行一個任務)轉變成多工作業系統(同一時間可以執行多個任務),又由於多工作業系統中程式經常搶奪系統資源而引發死鎖這種缺陷,在 20 世紀 60 年代,電腦科學家就開始探索併發程式設計的道路,併發指交替執行多個任務,解決的就是前面提到的多工作業系統的缺陷。直到現在,很多程式語言都為併發提供了支援,其中包括原生支援併發的 Go 語言,和有相關模組支援的 Python。
併發(concurrency)不是並行(parallelism)。並行是讓不同的程式碼片段同時在不同的物理處理器上執行。並行的關鍵是同時做很多事情,而併發是指同時管理很多事情,這些事情可能只做了一半就被暫停去做別的事情了。在很多情況下,併發的效果比並行好,因為作業系統和硬體的總資源一般很少,但能支援系統同時做很多事情。
——《Go 語言實戰》
筆記傳送門:使用future處理併發
第十八章
併發是指一次處理多件事。
並行是指一次做多件事。
二者不同,但是有聯絡。
一個關於結構,一個關於執行。
併發用於制定方案,用來解決可能(但未必)並行的問題。
——Rob Pike Go 語言的創造者之一
第十八章中,作者主要介紹了新的併發程式設計方式,對比了 asyncio.Task (協程)物件與 threading.Thread (執行緒)物件的區別,包括 Python 包使用方式的區別和中斷時協程與執行緒的區別:鎖的保留。章節尾,作者介紹了 asyncio 包的使用和併發程式設計需要注意的地方。
筆記待補
第十九章
第十九章主要介紹了動態屬性程式設計。
>>> class Foo(object):
... pass
...
>>> foo = Foo()
>>> foo.a = 3
>>> Foo.b = property(lambda self: self.a + 1)
>>> foo.b
4
這就叫做動態屬性(dynamic attribute),不同於屬於靜態語言的 Java 需要依靠 setter 和 getter 方法,Python 能十分方便地設定屬性和讀取屬性。
作者拿 FrozenJSON 類做例子:把巢狀的字典和列表轉換成巢狀的 FrozenJSON 例項和例項列表。FrozenJSON 類的程式碼展示瞭如何使用特殊的 __getattr__ 方法(處理屬性的函式)在讀取屬性時即時轉換資料結構。
作者還介紹了很多處理屬性的屬性和函式以及利用特性(@properties)來修改設定屬性和讀取屬性的方式。
筆記傳送門:動態屬性和特性
第二十章
有時候看書看著就忘了一些名詞是什麼了,因此參考了下【譯】Python描述符指南,描述符類就是實現描述符協議的類。
相比於第十九章中利用特性(@properties)來修改屬性的存取邏輯,第二十章主要介紹了描述符——對多個屬性運用相同存取邏輯的一種方式。兩者的區別是特性有時更合適和簡單,而描述符更靈活。這章還介紹了覆蓋型與非覆蓋型描述符的對比,最後也給出了使用描述符的建議和優缺點。
筆記傳送門:屬性描述符
第二十一章
(元類)是深奧的知識,99% 的使用者都無需關注。如果你想知道是否需要使用元類,我告訴你,不需要(真正需要使用元類的人確信他們需要,無需解釋原因) 。
——Tim Peters
Timsort 演算法的發明者,活躍的 Python 貢獻者
上面是第二十一章的引言,我聽從這位傳奇開發者的建議,沒有看。
總結
整本書都在強調如何最大限度地利用 Python 標準庫以及講述 Python 背後的設計思想。身處眾多動態程式語言中間,Python 無疑是獨行獨立的,這也是為什麼很多 Python 開發者驕傲地宣稱自己是一名 Pythonista。
自己只是不求甚解地通讀了一遍書,學到了很多,但書中仍有太多不熟悉的知識點。因為假期不多了,只能等日後二刷這本書。過一遍這本書最大的收穫莫過於在面對問題的時候,自己的工具箱又多了不少工具,即使這工具還不太「趁手」。其中感受最深的就是現在看一些 Segmentfault 或 StackOverflow 問題的答案的時候不再那麼毫無頭緒,並開始試著從前輩們的角度思考問題。另外書中多次提到 Django 的一些實現方式,對自己日後讀原始碼的時候有幫助。
倉促本身就是最要不得的態度。當你做某件事的時候,一旦想要求快,就表示你再也不關心它,而想去做別的事。
——羅伯特 · M · 波西格 《禪與摩托車維修藝術》
自己的確因為閱讀計劃的期限而讀的倉促了一些,這句話放到文尾,提醒自己在讀下一本書的時候,儘量做到靜下心來。
相關文章
- 《流暢的python》閱讀筆記Python筆記
- 流暢的python讀書筆記-第一章Python 資料模型Python筆記模型
- 《流暢的Python》 讀書筆記 第7章_函式裝飾器和閉包Python筆記函式
- 贈書《流暢的Python》Python
- 讀《流暢的Python》有感Python
- 流暢的python讀書筆記-第六章-使用一等函式實現設計模式Python筆記函式設計模式
- fluent python 讀書筆記 1Python筆記
- 流暢的Python-Fluent Python簡要書評Python
- 流暢的pythonPython
- 讀書筆記...筆記
- 讀書筆記筆記
- 《為ipad而設計 打造暢銷APP》讀書筆記iPadAPP筆記
- 《讀書與做人》讀書筆記筆記
- 4月書訊:流暢的Python,終於等到你!Python
- 《Python資料處理》讀書筆記Python筆記
- Cucumber讀書筆記筆記
- 散文讀書筆記筆記
- HTTP 讀書筆記HTTP筆記
- CoreJava讀書筆記-------Java筆記
- flask讀書筆記Flask筆記
- Vue讀書筆記Vue筆記
- MONGODB 讀書筆記MongoDB筆記
- Qt讀書筆記QT筆記
- Node讀書筆記筆記
- SAP讀書筆記筆記
- YII讀書筆記筆記
- iptables 讀書筆記筆記
- Makefile 讀書筆記筆記
- mysql讀書筆記MySql筆記
- 鎖讀書筆記筆記
- dataguard讀書筆記筆記
- 讀書筆記3筆記
- 讀書筆記2筆記
- postgres 讀書筆記筆記
- 菜鳥的讀書筆記筆記
- fluent python 讀書筆記 2–Python的序列型別2Python筆記型別
- fluent python讀書筆記2—Python的序列型別1Python筆記型別
- 《改善python程式的91個建議》讀書筆記Python筆記