現代程式語言系列1:靜態型別趨勢
靜態型別是現代語言的發展趨勢之一。近年來,不僅有很多靜態型別的現代語言興起,還有不少動態型別語言也在引入靜態型別支援。
下面我們就來看下為何靜態型別會如此受到現代語言的青睞。
靜態型別的優勢
與動態型別相比,靜態型別有如下優勢:
更佳的效能
靜態型別有利於編譯器優化,生成效率更高的程式碼。型別資訊不僅有助於編譯型靜態型別語言編譯,對於一些具有 JIT 的動態型別語言同樣有積極意義,如減少 JIT 開銷、提供更多優化資訊等。
及早發現錯誤
在動態型別程式碼中,型別不匹配的錯誤需要在執行期才能發現。而在在靜態型別程式碼中,可將這類錯誤的發現提前至編譯期,甚至在 IDE 的輔助下還可以更進一步提前至編碼期。
讓我們先看一個靜態型別語言的例子,這是一段 Kotlin 程式碼:
val hello = "Hello world"
val result = hello / 2
fun main(args: Array<String>) {
println(result)
}
如果把上面程式碼貼上在普通文字編輯器中並儲存,然後編譯會得到以下錯誤:

即上述程式碼中的型別不匹配錯誤可在編譯期發現。 而如果在 IntelliJ IDEA 中手動輸入這些程式碼的話,當輸入完第二行的時候,就會得到以下錯誤提示:
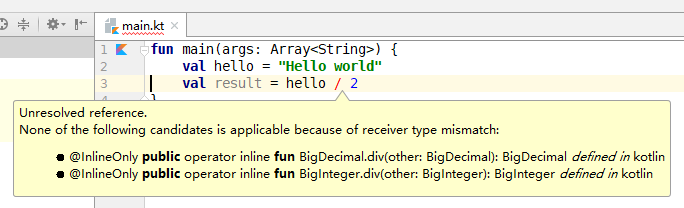
也就是說,通過 IDEA 的輔助,可以在編碼期捕獲到型別不匹配的錯誤。
接下來我們再看一個動態型別語言的例子,以 Python 3 為例對比下引入靜態型別支援前後的差異:
def plus_five(num):
return num + 5
plus_five("Hello")
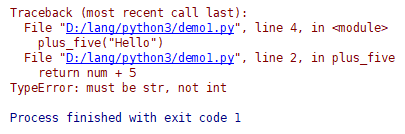
在 PyCharm 中,這段程式碼可以正常鍵入沒有任何錯誤提示,只是執行時會出現以下報錯:
現在,我們加上型別標註再試一次:
def plus_five(num: int) -> int:
return num + 5
plus_five("Hello")
當輸入完 plus_five("Hello") 就能在 PyCharm 中得到以下錯誤提示:
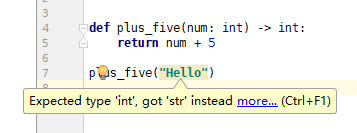
可以看出,即使在 Python 3 這樣的動態型別語言中,也能通過靜態型別(型別標註)與 IDE 輔助成功地將原本要在執行時才能發現的型別不匹配的錯誤,提前到編碼階段發現。
更好的工具支援
靜態型別能為 IDE 智慧補全、重構以及其他靜態分析提供良好支援。我們看個 Python 3 程式碼智慧補全的例子:
hello = "Hello world"
def to_constant_name(s):
return s.upper().replace(' ', '_')
print(to_constant_name(hello))
如果順序鍵入程式碼,當寫到 return s. 時,即便是 PyCharm 這樣智慧的 IDE 也無法自動列出型別 str 的成員。但如果加上型別標註,情形就完全不同了:
hello = "Hello world"
def to_constant_name(s: str) -> str:
return s.upper().replace(' ', '_')
print(to_constant_name(hello))
當鍵入到 s.u 的時候 PyCharm 就會彈出下圖的選單,按 Tab 即可完成補全:
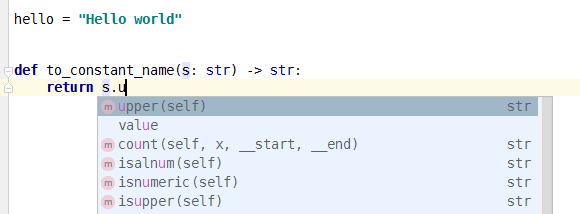
之後的 .replace() 與之類似。
易於理解
程式碼中有函式引數型別、返回值型別、變數型別以及泛型約束這些型別資訊作為輔助,能讓生疏的程式碼更易於理解。這在接手新專案、閱讀開原始碼以及程式碼評審實踐中都能帶來很多便利。
小結
靜態型別能夠提升程式的效能、健壯性、程式碼質量與可維護性。因此,很多現代的動態型別語言都引入了對靜態型別的支援。
動態型別語言中的靜態型別支援
Python 的型別提示
Python 的型別標註稱為型別提示(Type hint)。在上文中我們已經看到,藉助 IDE,它能夠獲得靜態型別的幾點優勢。但是這些資訊只用於工具檢查,Python 執行時自身並不會對型別提示做校驗,是名副其實的“提示”。例如下述程式碼能夠正常執行:
def print_int(i: int) -> None:
print(i)
print_int("Hello")
這段程式碼中宣告瞭一個輸出整數的函式 print_int,函式型別提示指出該函式只接受整數,但當我們傳給它一個字串的時候,它一樣能夠正常輸出。
Julia 的型別標註
Julia 是定位於科學計算、資料統計等數值計算領域的現代語言,旨在取代 Matlab、R、Python、Fortran 等在該領域的地位。 與 Python 3 不同,Julia 會針對型別標註做執行時校驗,同樣以一個只輸出整數的函式為例:
function print_int(i::Int)::Void
print(i)
end
如果給該函式傳一個整型引數,它能夠正常輸出。而如果傳入其他型別的引數,它會報錯:
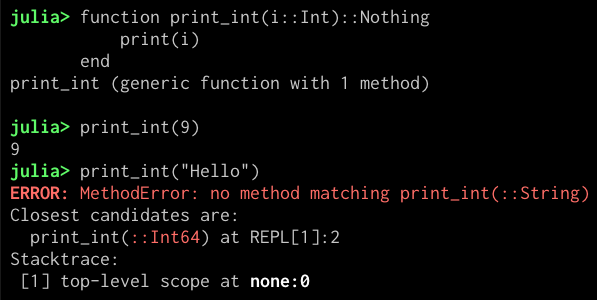
對於解釋執行也會得到類似的錯誤資訊。除此之外 Julia 還會(在 JIT 中)利用型別資訊進行效能優化以及函式過載,作為專業的數值計算語言,這兩點對 Julia 尤為重要。
Hack 的嚴格模式
Hack 是 Facebook 開源的一門動態語言,保留了對 PHP 的良好相容性的同時,引入了對靜態型別的支援。與 Python 3、Julia 類似,Hack 同樣支援型別標註。不同的是 Hack 的執行時 HHVM 對於以 <?hh 開頭 Hack 語言檔案(HHVM 也支援以 <?php 開頭的 PHP 語言檔案)會要求首先執行型別檢查工具,以便在執行前發現問題。繼續以輸出整數的程式碼為例,Hack 程式碼需要用嚴格模式才能檢測出問題。
Hack 語言的嚴格模式不允許呼叫傳統 PHP 程式碼或非嚴格 Hack 程式碼,要求所有程式碼進行型別標註,並且除了 require 語句、函式與類宣告之外不允許有其他頂層程式碼。因此輸出整數的 Hack 程式碼需要分成兩個檔案來寫:
a.hh —— 嚴格模式程式碼,以 <?hh // strict 開頭
<?hh // strict
function print_int(int $i): void {
echo $i;
}
function main(): void {
print_int(5);
print_int("hello");
}
b.hh —— 非嚴格模式,可以在頂層呼叫嚴格模式程式碼,用於執行 main 函式。
<?hh
main();
上述程式碼,在執行型別檢查工具時,會報以下錯誤:

當然,檢查過後就可以執行相應程式碼了。雖然檢查到了錯誤,仍然可以忽略之繼續任性執行。執行同樣會報執行時錯誤:
sh-4.2$ hhvm b.hh
Catchable fatal error: Hack type error: Invalid argument at /tmp/a.hh line 9
Hack 的檢查工具還能做型別檢查之外一些其他靜態分析。與 Julia 類似,HHVM 也會在 JIT 中利用型別資訊來改善效能。
Groovy 的混合型別
Groovy 是同時支援動態型別與靜態型別的動態語言。如果說 Hack 相當於在動態型別語言 PHP 的基礎上引入了靜態型別,那麼 Groovy 正好相反,它相當於在靜態型別語言 Java 的基礎上引入了動態型別。
雖然 Groovy 支援動態型別、在實踐中廣泛應用並且也帶來了很多便利,不過仍然有很多場景它推薦使用靜態型別,比如類成員宣告等。另外 Groovy 程式也可以編譯後執行,並且可以在編譯期做型別檢查。同樣以輸出整數的函式為例:
import groovy.transform.TypeChecked
def print_int(int i) {
print i
}
@TypeChecked
def main() {
print_int(5)
print_int("hello")
}
main()
無論編譯或者直接執行都會報這個錯:
org.codehaus.groovy.control.MultipleCompilationErrorsException: startup failed:
demo1.groovy: 10: [Static type checking] - Cannot find matching method demo1#print_int(java.lang.String). Please check if the declared type is right and if the method exists.
@ line 10, column 5.
print_int("hello")
^
1 error
其他
除此之外,混合型別語言還有 Dart、Perl 6 等;在動態型別語言裡基礎上引入靜態型別的還有著名的 TypeScript 語言,以及一堆帶有 Typed 字首的語言,如 Typed Racket、Typed Clojure、Type Scheme、Typed Lua 等等。可見靜態型別對於動態型別語言也是一個重要補充。
動態型別的出發點主要是省卻型別宣告讓程式碼更簡潔、編碼更便利,另外還能讓同樣的程式碼可適用於多種不同型別(鴨子型別)。相比之下傳統的 C、Java 以及傳統 C++ 等靜態型別語言卻很麻煩,需要寫不少樣板程式碼。而這些問題在現代靜態型別語言中已經有明顯改善,它們能夠提供近乎動態型別語言的簡潔便利性的同時,還能確保效能、型別安全以及良好的工具支援。接下來我們就看下靜態語言的改善之處吧。
靜態型別的便利性改善
REPL
通常靜態型別語言都是編譯型語言,編譯構建是靜態型別語言相對動態型別語言比較麻煩的問題之一,尤其是需要只寫幾行程式碼試驗效果的時候。現代靜態型別語言為這一場景提供了互動式程式設計環境,即 REPL(Read-Eval-Print Loop),這在小段程式碼測試或者實驗驅動開發中非常有用。下表列舉了一些現代靜態型別語言的 REPL,其中粗體表示官方提供。
1: 現代 C++,即 C++ 11 及其後版本(如 C++14、C++17 等)的 C++。
型別推斷
與 C 語言以及傳統的 C++/Java 不同,(包括現代 C++ 在內的)現代的靜態型別語言可以在很多地方省卻顯式型別標註,編譯器能夠從相應的上下文來推斷出變數/表示式的型別,這一機制稱為型別推斷(type inference)。靜態型別語言的這一機制讓變數宣告像動態型別語言一樣簡潔,例如:
// Kotlin 或 Scala 程式碼
val pi = 3.14159 // 推斷為 Double
val hello = "Hello" // 推斷為 String
val one = 1L // 推斷為 Long
val half = 0.5f // 推斷為 Float
在 Scala REPL 中執行的截圖如下:
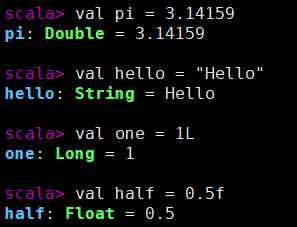
上述變數都是直接以字面值為初值,因此字面值的型別即是變數型別。當然變數的初值還可以是表示式:
// Kotlin 或 Scala 程式碼
val a = "Hello".length + 1.5 // 推斷為 Double
當型別推斷結果與預期不符時可以顯式標註:
// Kotlin 或 Scala 程式碼
val a = 97 // 推斷為 Int
val b: Byte = 97
val c: Short = 97
上述簡單字面值以及表示式的型別推斷結果在 Kotlin、Scala、Swift、Rust、F# 以及現代 C++ 中都是具體型別。不過在 Haskell 中會與它們有所不同,我們在 GHCi 中看兩個示例:
GHCi, version 8.0.2: http://www.haskell.org/ghc/ :? for help
Prelude> :set +t
Prelude> one = 1
one :: Num t => t
Prelude> half = 0.5
half :: Fractional t => t
上述 one 的型別為 Num t => t,這不是一個具體型別,而是泛型。在 Haskell 中 Num 不是具體型別,而是型別類。Haskell 型別類相當於 Rust 的 Trait 或者 Swift 的協議,也可以近似理解為 Scala 的特質或者 Java 的介面。one 的型別如果要在 Java 中表示,大約是這樣的 <t: Num>。在 Haskell 中整數和小數都是 Num 的例項(繼續與 Java 類比,可以理解為實現了 Num 介面),而數字字面值 1 在 Haskell 中既可以做整數也可以做小數,因此推斷為泛型的數字型別實際上更準確、更智慧。
half 與 one 類似,它被推斷為一個泛型型別 t,t 是 Fractional 的一個例項。即它被推斷為一個小數,在 Haskell 中有理數和浮點數都是小數的例項,而 0.5 即可以作為有理數也可以作為浮點數。
Haskell 不僅對字面值的推斷會更智慧,對複雜表示式的推斷也能更智慧一些。例如以下這個除以 5 的函式定義:
Prelude> divBy5 x = x / 5
divBy5 :: Fractional a => a -> a
Haskell 能夠根據運算子 / 將引數 x 和 divBy5 的返回值都推斷為小數,因為 / 接受的引數和返回值都是小數。
Scala 對一些表示式的型別推斷也能夠更智慧一些,例如:
trait I
class A extends I
class B extends I
val a = true
val v = if (a) new A else new B
上面的變數 v 會被推斷為型別 I,這是因為 if 表示式兩個分支分別返回型別 A 和型別 B,因此 v 必須既能接受 A 型別也能接受 B 型別,於是 Scala 將其推斷為二者的公共超型別 I。
泛型
與動態型別語言相比,靜態型別語言通常缺少對鴨子型別的支援。靜態型別語言通過泛型來解決這一問題,因此現代靜態型別語言都支援泛型。 例如實現一個交換兩個可變變數值的通用函式,以 Swift 為例:
func swap<T>(a: inout T, b: inout T) {
let tmp = a
a = b
b = tmp
}
其中 T 為泛型引數,代表任意型別,但 a 與 b 需要是相同型別。這樣 swap 就能用於交換任何型別的兩個可變變數的值了。
我們再看一個例子,實現一個函式,它接受兩個同樣型別的引數,返回二者中的最大值(也就是說返回值型別與兩個引數型別均相同),以 Rust 為例,程式碼如下:
fn max2<T: Ord>(a: T, b: T) -> T {
if a < b {
b
} else {
a
}
}
對於任何實現了 Ord 的型別(這樣才能比大小)T 都可用使用這個泛型函式 max2 來求兩個值中的最大值。Swift、Kotlin 的泛型語法與之相近,只是在 Kotlin 中可以更簡潔一些:
fun <T: Comparable<T>> max(a: T, b: T) = if (a > b) a else b
而在 F# 或者 Haskell 中只需這樣寫即可:
let max' a b = if (a < b) then b else a
與 Rust、Kotlin 等顯著不同的是,F#/Haskell 的這段程式碼並沒有顯式標註泛型。因為 F#/Haskell 能夠通過 < 自動推斷出 a、b 以及返回值具有可比較的泛型約束(comparison/Ord)。F#/Haskell 強大的型別推斷能力讓這段程式碼看起來如同動態語言一樣簡潔。
在 F# 中還可以用成員函式/屬性作為泛型約束,可以說是型別安全的鴨子型別:
type A() =
member this.info = "I'm A.";;
type B() =
member this.info = "I'm B.";;
let inline printInfo (x: ^T when ^T: (member info: string)) =
(^T: (member info: string) (x));;
A() |> printInfo;;
B() |> printInfo;;
只是其語法上有些囉嗦。
綜述
靜態型別具有很多優勢,對於動態型別語言同樣有積極意義。 現代靜態型別語言在不斷改進其簡潔性與便利性,與動態型別語言的差距在縮小,因此更加親民,近年來有很多現代靜態型別語言興起與流行。 另外由於靜態型別的優勢,很多動態型別語言也在引入靜態型別支援。可見靜態型別是現代語言發展的一個趨勢。
本文也發在我的個人部落格上:https://hltj.me/lang/2017/08/01/modern-lang-static-type.html。
相關文章
- 淺談程式語言型別的強型別,弱型別,動態型別,靜態型別型別
- 概念區別 【編譯型語言與解釋型語言、動態型別語言與靜態型別語言、強型別語言與弱型別語言】編譯型別
- 計算機語言:編譯型/解釋型、動態語言/靜態語言、強型別語言/弱型別語言計算機編譯型別
- 不用靜態型別函數語言程式設計語言的十大理由型別函數程式設計
- 讚美 void, ECMAScript 秒變靜態型別語言型別
- 動態語言與鴨子型別型別
- 現代程式語言系列2:安全表達可選值
- Python 語言特性:編譯+解釋、動態型別語言、動態語言Python編譯型別
- 智慧合約語言 Solidity 教程系列1 – 型別介紹Solid型別
- Go語言實現靜態伺服器Go伺服器
- 現代程式語言用什麼語言寫成?
- 為什麼動態型別程式語言會如此流行?型別
- Web程式語言和指令碼語言的就業趨勢Web指令碼就業
- 2013年Web 程式語言就業趨勢Web就業
- 雜談現代高階程式語言
- 理解 TypeScript 的靜態型別TypeScript型別
- 語言型別介紹及其Python的語言型別型別Python
- RedMonk:2014年GitHub程式語言流行趨勢Github
- 2012年Web程式語言就業趨勢Web就業
- PureBasic 現代 BASIC 程式語言編輯器
- 解釋型語言、編譯型語言 區別編譯
- Java 語言是強型別語言語言(轉)Java型別
- 手拉手教你實現一門程式語言 Enkel, 系列 1
- Vue TypeScript 實戰:掌握靜態型別程式設計VueTypeScript型別程式設計
- Python的靜態型別之旅Python型別
- React的靜態型別檢查React型別
- Scala: 感覺像動態的靜態語言
- 程式語言:型別系統的本質型別
- 程式語言模式:`=`表示賦值,`:`表示型別。模式賦值型別
- 2013年2月Web程式語言就業趨勢Web就業
- C 語言Struct 實現執行型別識別 RTTIStruct型別
- C 語言實現使用靜態陣列實現迴圈佇列陣列佇列
- Vue中的靜態型別檢查Vue型別
- 解釋型語言與編譯型語言的區別?編譯
- 羅素悖論 型別系統與程式語言型別
- go語言資料型別-基礎型別Go資料型別
- C語言--靜態區域性變數C語言變數
- C語言的本質(34)——靜態庫C語言