正規表示式教程——語法篇
正規表示式,名字聽上去就沒有吸引力,我發現很多前端對正規表示式都很難做到如數家珍,每次能夠執行全憑運氣,更有甚者完全靠複製貼上,其實這樣並不好
正規表示式其實並不難,語法就那麼多,而且一旦掌握在某些時候能夠給解決問題提供捷徑,更重要的是面試可能會被問到,要是不會那就尷尬了
本文主要介紹正規表示式的語法部分,下面將正規表示式簡稱為正則
正則是啥?
同學你可以出門右轉了,下面是我自己的理解
正則就是用有限的符號,表達無限的序列,殆已!
正規表示式的語法一般如下(js),兩條斜線中間是正則主體,這部分可以有很多字元組成;i部分是修飾符,i的意思表示忽略大小寫
/^abc/i
正則定義了很多特殊意義的字元,有名詞,量詞,謂詞等,下面逐一介紹
簡單字元
沒有特殊意義的字元都是簡單字元,簡單字元就代表自身,絕大部分字元都是簡單字元,舉個例子
/abc/ // 匹配 abc
/123/ // 匹配 123
/-_-/ // 匹配 -_-
/海鏡/ // 匹配 海鏡
轉義字元
\是轉義字元,其後面的字元會代表不同的意思,轉義字元主要有三個作用:
第一種,是為了匹配不方便顯示的特殊字元,比如換行,tab符號等
第二種,正則中預先定義了一些代表特殊意義的字元,比如\w等
第三種,在正則中某些字元有特殊含義(比如下面說到的),轉義字元可以讓其顯示自身的含義
下面是常用轉義字元列表:
| \n | 匹配換行符 |
| \r | 匹配回車符 |
| \t | 匹配製表符,也就是tab鍵 |
| \v | 匹配垂直製表符 |
| \x20 | 20是2位16進位制數字,代表對應的字元 |
| \u002B | 002B是4位16進位制數字,代表對應的字元 |
| \u002B | 002B是4位16進位制數字,代表對應的字元 |
| \w | 匹配任何一個字母或者數字或者下劃線 |
| \W | 匹配任何一個字母或者數字或者下劃線以外的字元 |
| \s | 匹配空白字元,如空格,tab等 |
| \S | 匹配非空白字元 |
| \d | 匹配數字字元,0~9 |
| \D | 匹配非數字字元 |
| \b | 匹配單詞的邊界 |
| \B | 匹配非單詞邊界 |
| \\ | 匹配\本身 |
字符集和
有時我們需要匹配一類字元,字符集可以實現這個功能,字符集的語法用[``]分隔,下面的程式碼能夠匹配a或b或c
[abc]
如果要表示字元很多,可以使用-表示一個範圍內的字元,下面兩個功能相同
[0123456789]
[0-9]
在前面新增^,可表示非的意思,下面的程式碼能夠匹配a``b``c之外的任意字元
[^abc]
其實正則還內建了一些字符集,在上面的轉義字元有提到,下面給出內建字符集對應的自定義字符集
- . 匹配除了換行符(\n)以外的任意一個字元 = [^\n]
- \w = [0-9a-zA-Z_]
- \W = [^0-9a-zA-Z_]
- \s = [ \t\n\v]
- \S = [^ \t\n\v]
- \d = [0-9]
- \D = [^0-9]
量詞
如果我們有三個蘋果,我們可以說自己有個3個蘋果,也可以說有一個蘋果,一個蘋果,一個蘋果,每種語言都有量詞的概念
如果需要匹配多次某個字元,正則也提供了量詞的功能,正則中的量詞有多個,如?、+、*、{n}、{m,n}、{m,}
{n}匹配n次,比如a{2},匹配aa
{m, n}匹配m-n次,優先匹配n次,比如a{1,3},可以匹配aaa、aa、a
{m,}匹配m-∞次,優先匹配∞次,比如a{1,},可以匹配aaaa...
?匹配0次或1次,優先匹配1次,相當於{0,1}
+匹配1-n次,優先匹配n次,相當於{1,}
*匹配0-n次,優先匹配n次,相當於{0,}
正則預設和人心一樣是貪婪的,也就是常說的貪婪模式,凡是表示範圍的量詞,都優先匹配上限而不是下限
a{1, 3} // 匹配字串'aaa'的話,會匹配aaa而不是a
有時候這不是我們想要的結果,可以在量詞後面加上?,就可以開啟非貪婪模式
a{1, 3}? // 匹配字串'aaa'的話,會匹配a而不是aaa
字元邊界
有時我們會有邊界的匹配要求,比如以xxx開頭,以xxx結尾
^在[]外表示匹配開頭的意思
^abc // 可以匹配abc,但是不能匹配aabc
$表示匹配結尾的意思
abc$ // 可以匹配abc,但是不能匹配abcc
上面提到的\b表示單詞的邊界
abc\b // 可以匹配 abc ,但是不能匹配 abcc
選擇表示式
有時我們想匹配x或者y,如果x和y是單個字元,可以使用字符集,[abc]可以匹配a或b或c,如果x和y是多個字元,字符集就無能為力了,此時就要用到分組
正則中用|來表示分組,a|b表示匹配a或者b的意思
123|456|789 // 匹配 123 或 456 或 789
分組與引用
分組是正則中非常強大的一個功能,可以讓上面提到的量詞作用於一組字元,而非單個字元,分組的語法是圓括號包裹(xxx)
(abc){2} // 匹配abcabc
分組不能放在[]中,分組中還可以使用選擇表示式
(123|456){2} // 匹配 123123、456456、123456、456123
和分組相關的概念還有一個捕獲分組和非捕獲分組,分組預設都是捕獲的,在分組的(後面新增?:可以讓分組變為非捕獲分組,非捕獲分組可以提高效能和簡化邏輯
'123'.match(/(?:123)/) // 返回 ['123']
'123'.match(/(123)/) // 返回 ['123', '123']
和分組相關的另一個概念是引用,比如在匹配html標籤時,通常希望<xxx></xxx>後面的xxx能夠和前面保持一致
引用的語法是\數字,數字代表引用前面第幾個捕獲分組,注意非捕獲分組不能被引用
<([a-z]+)><\/\1> // 可以匹配 `<span></span>` 或 `<div></div>`等
預搜尋
如果你想匹配xxx前不能是yyy,或者xxx後不能是yyy,那就要用到預搜尋
js只支援正向預搜尋,也就是xxx後面必須是yyy,或者xxx後面不能是yyy
1(?=2) // 可以匹配12,不能匹配22
1(?!2) // 可有匹配22,不能匹配12
修飾符
預設正則是區分大小寫,這可能並不是我們想要的,正則提供了修飾符的功能,修復的語法如下
/xxx/gi // 最後面的g和i就是兩個修飾符
g正則遇到第一個匹配的字元就會結束,加上全域性修復符,可以讓其匹配到結束
i正則預設是區分大小寫的,i可以忽略大小寫
m正則預設情況下,^和$只能匹配字串的開始和結尾,m修飾符可以讓^和$匹配行首和行尾,不理解就看例子
/jing$/ // 能夠匹配 'yanhaijing,不能匹配 'yanhaijing\n'
/jing$/m // 能夠匹配 'yanhaijing, 能夠匹配 'yanhaijing\n'
/^jing/ // 能夠匹配 'jing',不能匹配 '\njing'
/^jing/m // 能夠匹配 'jing',能夠匹配 '\njing'
總結
刻意練習,方能遊刃有餘,知己知彼,方能百戰百勝,正則是前端的一個武器,技多不壓身
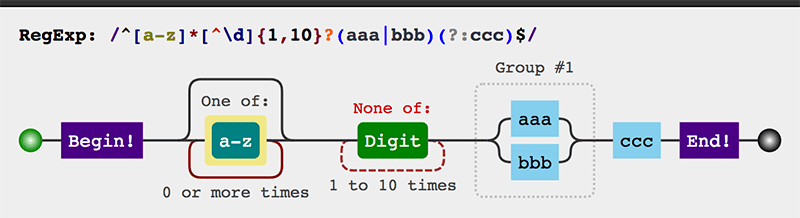
有時我們會遇到特別複雜的正則,有時候可能不太直觀,下面推薦一個圖形化展示的工具,我們把涉及到的語法羅列一下
/^[a-z]*[^\d]{1,10}?(aaa|bbb)(?:ccc)$/
可以看到工具能夠更快的幫我們理清頭緒
本文僅講述了語法,下一篇文章將詳細介紹如何在js中使用正則,推薦一下glob,號稱給人看的正則,比正則的語法簡單多了,也是平時開發的神器
原文網址:http://yanhaijing.com/javascript/2017/08/06/regexp-syntax/
歡迎訂閱我的微信公眾帳號,只推送原創文字。掃碼或搜尋:顏海鏡

相關文章
- 正規表示式-語法大全
- 正規表示式的基本語法
- java 正規表示式語法學習Java
- 正規表示式 教程
- 通過js正規表示式例項學習正規表示式基本語法JS
- Python語法進階(2)- 正規表示式Python
- js正規表示式基本語法學習JS
- Java正規表示式的語法與示例Java
- 正規表示式小結篇
- Swift 正規表示式完整教程Swift
- 正規表示式簡明教程
- 正規表示式完整教程(略長)
- (一) 爬蟲教程 |正規表示式爬蟲
- 正規表示法
- 一次性搞懂JavaScript正規表示式之語法JavaScript
- 正規表示式
- 正規表示式.
- 還不會正規表示式?看這篇!
- 正規表示式系列之中級進階篇
- 正規表示式系列之初級入門篇
- 【正規表示式】常用的正規表示式(數字,漢字,字串,金額等的正規表示式)字串
- 正規表示式教程之位置匹配詳解
- 正規表示式及多語言操作指南
- 常用正規表示式
- JavaScript 正規表示式JavaScript
- MySQL正規表示式MySql
- 正規表示式(java)Java
- SQL正規表示式SQL
- python正規表示式Python
- 正規表示式合集
- 正規表示式(一)
- Python 正規表示式Python
- Python——正規表示式Python
- PHP正規表示式PHP
- 正規表示式概括
- javascript正規表示式JavaScript
- java正規表示式Java
- Shell正規表示式
- 正規表示式 【四】