【譯文】偽標籤學習導論 - 一種半監督學習方法
作者 SHUBHAM JAIN
譯者 錢亦欣
引言
在有監督學習領域,我們已經取得了長足的進步,但這也意味著我們需要大量資料來做影像分類和銷量預測,這些演算法需要把這些資料掃描一遍又一遍來尋找模式。
.然而,這其實不是人類的學習方法,我們的大腦不需要成千上萬的資料迴圈往復地學習來了解一類圖片的主題,我們只需要少量的特徵點來習得模式,所以現有的機器學習方法是有所缺陷的。
好在現有已經有一些針對這個問題的研究,我們或許可以構建一個系統,它只需要最少量的監督資料輸入但能學得每個任務的主要模式。本文將會介紹其中一種名為偽標籤學習的方法,我會深入淺出的講解原理並演示一個案例。
走起!
注:我既定你已經對機器學習又基本瞭解,如果沒有請學習相關知識再看本文。
目錄
- 什麼是半監督學習 (SSL)?
- 如何利用無標籤資料
- 偽標籤學習
- 半監督學習的應用
- 取樣率的作用
- 半監督學習的應用場景
1. 什麼是半監督學習 (SSL) ?
假設我們目前面臨一個簡單的影像分類問題,我們的資料有兩類標籤(如下所示)。

我們的目標就是區分影像中有無日食,現在的問題就是如何僅從兩幅圖片的資訊中構建一個分類系統。
一般而言,為了構建一個穩定的分類系統我們需要更多資料,我們從網上下載了更多相關圖片來擴充我們的訓練集。

但是,如果從監督學習的方法出發,我們還要給這些圖片貼上標籤,因此我們要藉助人工完成這個過程。

基於這些資料執行了監督學習的演算法,我們的模型表現顯著高於那個僅基於兩張圖片的演算法。
但是這個方法只在任務量不大的時候起效,資料量一大繼續人工介入會消耗大量資源。
為了解決這一類問題,我們定義了一種名為半監督學習的方法,能從有標籤(監督學習)和無標籤資料(無監督學習)中共同習得模式。
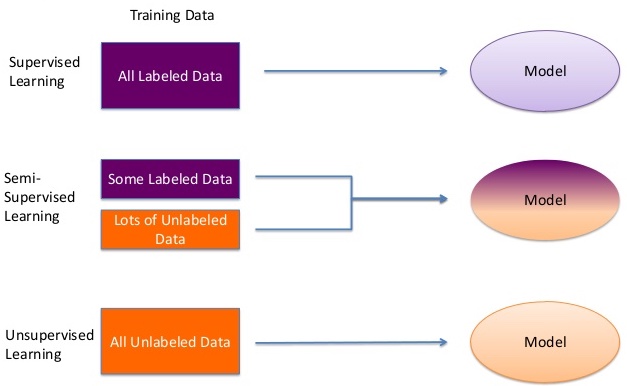
來源: 連結
因此,現在就讓我們學習下如何利用無標籤資料。
2. 如何利用無標籤資料?
考慮如下的情形
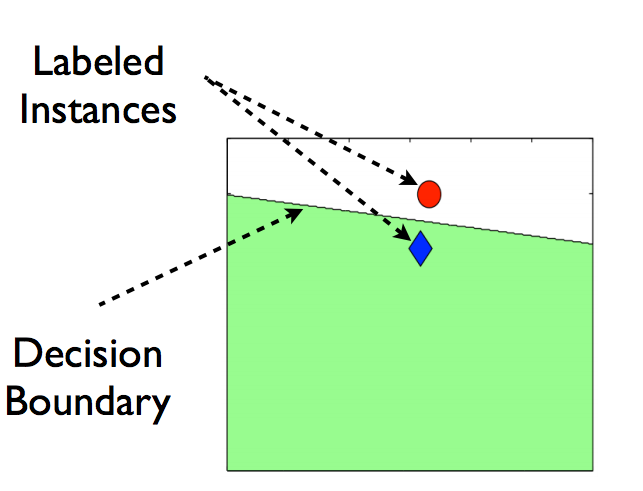
我們只有分屬兩個類別的兩個資料點,途中的線代表著任意有監督模型的決策邊界。
現在,讓我們再途中加一些無標籤資料,如下所示。
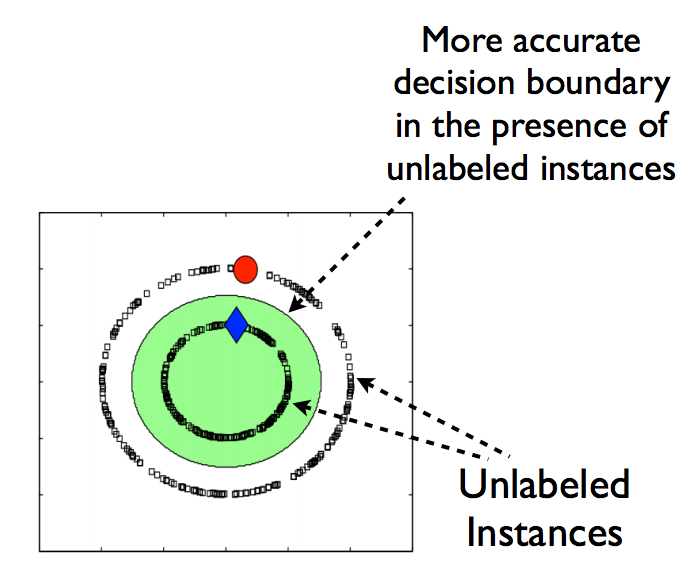
圖片來源: 連結
如果我們注意到兩幅圖的差異,我們就可以發現有了無標籤資料後,兩個類別的決策邊界變地更加精確了。
因此,使用無標籤資料的優點如下:
- 有標籤資料往往意味著高成本和難以獲得,但無標籤資料量大又便宜。
- 通過提高決策邊界的精確性,它們能提高模型的穩健性。
現在,我們對於半監督學習已經有了直觀的認識,當然這個領域也有許多種方法,本文就介紹其中的偽標籤學習法。
3. 偽標籤學習
這一技術,讓我們不必再手工標註無標籤資料,我們只需要基於有標籤資料的技術來給出一個近似的標籤,我們把這個過程分成多個步驟逐一介紹。
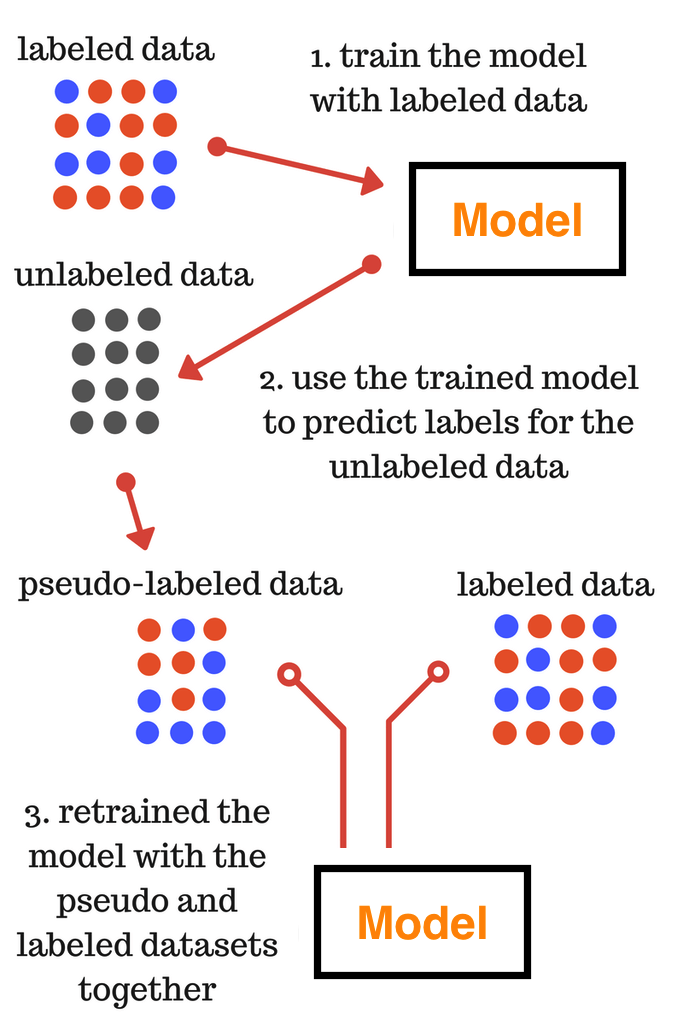 來源: 連結
來源: 連結
我假設你已經看懂了上圖的流程,第三步訓練的模型將會用來給測試集分類。
為了讓你有更好地理解,我會結合一個實際問題來講解原理。
4. 半監督學習的應用
此處我們使用 Big Mart Sales 問題作為例子。我們先下載這個資料集並做一些探索。
先載入一些基礎的庫
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.preprocessing import LabelEncoder
之後讀入下載好的訓練集和測試機,並作簡單的預處理
train = pd.read_csv('/Users/shubhamjain/Downloads/AV/Big Mart/train.csv')
test = pd.read_csv('/Users/shubhamjain/Downloads/AV/Big Mart/test.csv')
# 預處理
### 均值插值
train['Item_Weight'].fillna((train['Item_Weight'].mean()), inplace=True)
test['Item_Weight'].fillna((test['Item_Weight'].mean()), inplace=True)
### 把脂肪含量這一變數變為二分類
train['Item_Fat_Content'] = train['Item_Fat_Content'].replace(['low fat','LF'], ['Low Fat','Low Fat'])
train['Item_Fat_Content'] = train['Item_Fat_Content'].replace(['reg'], ['Regular'])
test['Item_Fat_Content'] = test['Item_Fat_Content'].replace(['low fat','LF'], ['Low Fat','Low Fat'])
test['Item_Fat_Content'] = test['Item_Fat_Content'].replace(['reg'], ['Regular'])
## 計算創立年份
train['Outlet_Establishment_Year'] = 2013 - train['Outlet_Establishment_Year']
test['Outlet_Establishment_Year'] = 2013 - test['Outlet_Establishment_Year']
### 查補 size 變數的缺失值
train['Outlet_Size'].fillna('Small',inplace=True)
test['Outlet_Size'].fillna('Small',inplace=True)
### 給 cate. var. 編碼
col = ['Outlet_Size','Outlet_Location_Type','Outlet_Type','Item_Fat_Content']
test['Item_Outlet_Sales'] = 0
combi = train.append(test)
number = LabelEncoder()
for i in col:
combi[i] = number.fit_transform(combi[i].astype('str'))
combi[i] = combi[i].astype('int')
train = combi[:train.shape[0]]
test = combi[train.shape[0]:]
test.drop('Item_Outlet_Sales',axis=1,inplace=True)
## 去除 id 這一變數
training = train.drop(['Outlet_Identifier','Item_Type','Item_Identifier'],axis=1)
testing = test.drop(['Outlet_Identifier','Item_Type','Item_Identifier'],axis=1)
y_train = training['Item_Outlet_Sales']
training.drop('Item_Outlet_Sales',axis=1,inplace=True)
features = training.columns
target = 'Item_Outlet_Sales'
X_train, X_test = training, testing
訓練不同的有監督模型,選取效果最好的那一個
from xgboost import XGBRegressor
from sklearn.linear_model import BayesianRidge, Ridge, ElasticNet
from sklearn.neighbors import KNeighborsRegressor
from sklearn.ensemble import RandomForestRegressor, ExtraTreesRegressor, GradientBoostingRegressor
#from sklearn.neural_network import MLPRegressor
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import cross_val_score
model_factory = [
RandomForestRegressor(),
XGBRegressor(nthread=1),
#MLPRegressor(),
Ridge(),
BayesianRidge(),
ExtraTreesRegressor(),
ElasticNet(),
KNeighborsRegressor(),
GradientBoostingRegressor()
]
for model in model_factory:
model.seed = 42
num_folds = 3
scores = cross_val_score(model, X_train, y_train, cv=num_folds, scoring='neg_mean_squared_error')
score_description = " {} (+/- {})".format(np.sqrt(scores.mean()*-1), scores.std() * 2)
print('{model:25} CV-5 RMSE: {score}'.format(
model=model.__class__.__name__,
score=score_description
))

可以發現XGB的表現最好,同時請注意偽了方便我沒有調參。
現在讓我們使用偽標籤學習法,我將把測試集作為無標籤資料。
from sklearn.utils import shuffle
from sklearn.base import BaseEstimator, RegressorMixin
class PseudoLabeler(BaseEstimator, RegressorMixin):
'''
偽標籤學習中的 sci-kit learn 演算法封裝
'''
def __init__(self, model, unlabled_data, features, target, sample_rate=0.2, seed=42):
'''
@取樣率 - 無標籤樣本中被用作偽標籤樣本的比率
'''
assert sample_rate <= 1.0, 'Sample_rate should be between 0.0 and 1.0.'
self.sample_rate = sample_rate
self.seed = seed
self.model = model
self.model.seed = seed
self.unlabled_data = unlabled_data
self.features = features
self.target = target
def get_params(self, deep=True):
return {
"sample_rate": self.sample_rate,
"seed": self.seed,
"model": self.model,
"unlabled_data": self.unlabled_data,
"features": self.features,
"target": self.target
}
def set_params(self, **parameters):
for parameter, value in parameters.items():
setattr(self, parameter, value)
return self
def fit(self, X, y):
'''
用偽標籤樣本填充資料集
'''
augemented_train = self.__create_augmented_train(X, y)
self.model.fit(
augemented_train[self.features],
augemented_train[self.target]
)
return self
def __create_augmented_train(self, X, y):
'''
生成並返回包括標籤樣本和偽變遷樣本的 augmented_train 集合
'''
num_of_samples = int(len(self.unlabled_data) * self.sample_rate)
# 訓練模型並生成偽標籤
self.model.fit(X, y)
pseudo_labels = self.model.predict(self.unlabled_data[self.features])
# 在測試集中加入偽標籤
pseudo_data = self.unlabled_data.copy(deep=True)
pseudo_data[self.target] = pseudo_labels
# 將測試集中又偽標籤的部分資料合併入訓練集
sampled_pseudo_data = pseudo_data.sample(n=num_of_samples)
temp_train = pd.concat([X, y], axis=1)
augemented_train = pd.concat([sampled_pseudo_data, temp_train])
return shuffle(augemented_train)
def predict(self, X):
'''
返回預測值
'''
return self.model.predict(X)
def get_model_name(self):
return self.model.__class__.__name__
這看起來很複雜,不過不用擔心其實就和前面介紹的流程一毛一樣,所以每次複製上面的程式碼就可以投入到別的用例了。
現在讓我們來檢測下偽標籤學習的效果。
model_factory = [
XGBRegressor(nthread=1),
PseudoLabeler(
XGBRegressor(nthread=1),
test,
features,
target,
sample_rate=0.3
),
]
for model in model_factory:
model.seed = 42
num_folds = 8
scores = cross_val_score(model, X_train, y_train, cv=num_folds, scoring='neg_mean_squared_error', n_jobs=8)
score_description = "MSE: {} (+/- {})".format(np.sqrt(scores.mean()*-1), scores.std() * 2)
print('{model:25} CV-{num_folds} {score_cv}'.format(
model=model.__class__.__name__,
num_folds=num_folds,
score_cv=score_description
))

本例中,我們得到了一個比任何有監督學習演算法都小的rmse值。
你或許已經注意到 取樣比例(sample_rate)這個引數,它代表無標籤資料中本用作偽標籤樣本的比率。
下面我就就來測試下這個引數對偽標籤學習法預測表現的影響。
5. 取樣比例的作用
為了說明這個引數的作用,我們來畫個圖。時間有限,我就只花了兩個演算法的圖,你自己可以試試別的。
sample_rates = np.linspace(0, 1, 10)
def pseudo_label_wrapper(model):
return PseudoLabeler(model, test, features, target)
# 受試模型列表
model_factory = [
RandomForestRegressor(n_jobs=1),
XGBRegressor(),
]
# 對每個模型使用偽標籤法
model_factory = map(pseudo_label_wrapper, model_factory)
# 用不同的取樣率訓練模型
results = {}
num_folds = 5
for model in model_factory:
model_name = model.get_model_name()
print('{}'.format(model_name))
results[model_name] = list()
for sample_rate in sample_rates:
model.sample_rate = sample_rate
# 計算 CV-3 R2 得分
scores = cross_val_score(
model, X_train, y_train, cv=num_folds, scoring='neg_mean_squared_error', n_jobs=8)
results[model_name].append(np.sqrt(scores.mean()*-1))
plt.figure(figsize=(16, 18))
i = 1
for model_name, performance in results.items():
plt.subplot(3, 3, i)
i += 1
plt.plot(sample_rates, performance)
plt.title(model_name)
plt.xlabel('sample_rate')
plt.ylabel('RMSE')
plt.show()
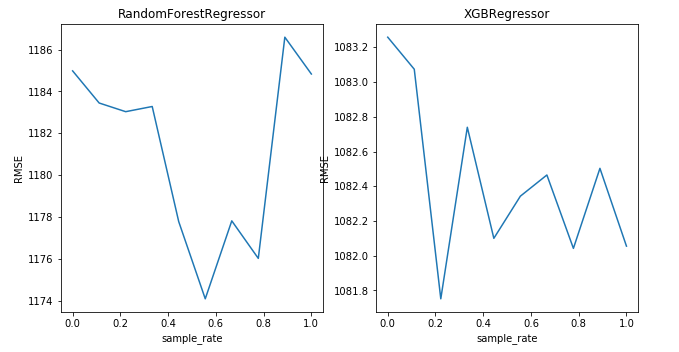
如此一來,我們發現對於不同的模型我們都要選取特定的取樣率來達到最佳的效果,因而調節這個引數就顯得很有必要了。
6. 半監督學習的應用場景
過去,半監督學習的應用場景著實有限,但如今在不少領域已經出現了它的身影。我找到的場景如下:
1. 圖片分類中的多模式半監督學習
通常來講,圖片分類的目標是判斷一幅圖是否屬於一個特定類別。但在這篇文章裡,不光是圖片本身,與之相關聯的關鍵詞夜奔由來提升半監督學習的分類質量。

來源: 連結
2. 在人口販賣中的作用
人口販賣一直都是最惡劣的犯罪行為之一,需要全球一起關注。使用半監督學習可以比普通的方法提供更好的結果。
來源:連結
結語
我希望你現在對班監督學習有了初步認識,並知道如何再具體問題中應用它了。不妨試著學習其他的半監督演算法並和大家分享吧。
本文的所有的程式碼可以再我的 github 上找到。
相關文章
- 一圖看懂監督學習、無監督學習和半監督學習
- Hinton新作!越大的自監督模型,半監督學習需要的標籤越少模型
- 機器學習——監督學習&無監督學習機器學習
- 自監督、半監督和有監督全涵蓋,四篇論文遍歷對比學習的研究進展
- 有監督學習和無監督學習
- 【半監督學習】MixMatch、UDA、ReMixMatch、FixMatchREM
- 【機器學習基礎】半監督學習簡介機器學習
- 監督學習
- 【論文解讀】【半監督學習】【Google教你水論文】A Simple Semi-Supervised Learning Framework for Object DetectionGoFrameworkObject
- 什麼是有監督學習和無監督學習
- 機器學習:監督學習機器學習
- 自監督學習
- 基於自編碼器的表徵學習:如何攻克半監督和無監督學習?
- 【ML吳恩達】3 有監督學習和無監督學習吳恩達
- 自監督學習概述
- 監督學習or無監督學習?這個問題必須搞清楚
- 監督學習基礎概念
- 003.00 監督式學習
- 監督學習之迴歸
- 有監督學習——梯度下降梯度
- 從監督式到DAgger,綜述論文描繪模仿學習全貌
- 基於attention的半監督GCN | 論文分享GC
- 監督學習,無監督學習常用演算法集合總結,引用scikit-learn庫(監督篇)演算法
- 論文學習
- InfoGAN:一種無監督生成方法 | 經典論文復現
- 利用DP-SSL對少量的標記樣本進行有效的半監督學習
- 監督學習之支援向量機
- 非監督學習最強攻略
- 無監督學習之降維
- 【機器學習】李宏毅——自監督式學習機器學習
- 有監督學習——高斯過程
- [譯] Python 中的無監督學習演算法Python演算法
- 吳恩達《Machine Learning》精煉筆記 1:監督學習與非監督學習吳恩達Mac筆記
- 詳解基於圖卷積的半監督學習(附程式碼)卷積
- ZGC論文學習GC
- git學習——打標籤Git
- 監督學習之高斯判別分析
- 有監督學習——線性迴歸