MPLS學習( by quqi99 )
MPLS學習( by quqi99 )
作者:張華 發表於:2013-06-29
版權宣告:可以任意轉載,轉載時請務必以超連結形式標明文章原始出處和作者資訊及本版權宣告
http://blog.csdn.net/quqi99 )
在談MPLS時,先回顧一下路由選擇協議演算法(動態路由,動態自學習轉發規則。Linux本身將ipv4 forward功能開啟可新增路由規則做靜態路由器,動態路由可有一個軟體Quagga來模擬),它分為兩類:1)內部閘道器協議IGP,如RIP,OSPF等
2)外部閘道器協議EGP,如BGP。
RIP(Routing Information Protocol, 路由資訊協議)是一種基於距離向量的路由選擇協議,它僅和相鄰路由器交換資訊,交換的資訊是“我到本自治系統中所有網路的(最短)距離,以及每個網路應該經過的下一跳路由器。它的缺點是,網路中的一個路由器出現故障時,要經過比較長的時間才能將此資訊傳送到所有的路由器,即所謂的”好訊息傳播得快,而壞訊息傳播得慢“。
OSPF(Open Shortest Path First, 開放最短路徑優先)是一種基於鏈路狀態協議,它不像RIP只和相信路由器交換資訊,而是採取洪泛法和本自治系統內所有的路由器交換資訊,這樣每個路由器都知道全網的拓撲結構。為了使它應用於規模很大的網路,它將一個自治系統再劃分為若干個更小的自治系統,在一個區域內的路由器最好不要超過200個。
可以設定IP幀的服務型別(TOS)欄位,將它設定為代價加權值,這樣就可能算出多條代價相同的路徑,OSPF為每條路徑負載平衡分配通訊量。而RIP只能找到某個網路的一條路徑。
BGP(網路邊界協議)是一種基於路徑向量的路由演算法,它不是為了找最佳路由,而是為了找一個比較好的路由。每個自治系統出一個路由器作為BGP發言人和其他自治系統的BGP發言人通過TCP建立連線協商到達某一目的地址需要可經過哪個自治區域。
然後我們再回顧一下路由器的原理。
路由器是一種具有多個輸入埠和多個輸出埠的專用計算機,通過路由表來控制從哪個輸入埠轉到哪一個輸出埠。那麼它就分為“轉發”和路由選擇“兩個層面,如下圖,轉發表是根據路由表建立的。路由選擇是多個路由器協同構建路由表,當網路拓撲發生變化時,動態地改變所選擇的路由,它是用軟體實現的。而轉發表則根據路由表得出的從哪個埠進的要往哪個埠轉,為提高轉發速度它可以通過硬體來實現。在討論路由選擇的原理時,往往不去區分轉發表和路由表的區別,而是籠統地的使用路由表這一名詞。我在這裡專門提這事,是因為MPLS也就是在轉發表這一塊引入了標籤的概念,因為標籤是等長的,不像IP一樣不等長要用最大長度匹配演算法影響效率。

最早使用的路由器就是利用普通的計算機,用計算機的CPU作為路由器的路由選擇處理機。當某個輸入埠(網路卡)收到一個分組時,就中斷通過CPU,然後分組就從輸入埠複製到儲存器中,CPU再從分組首部中提取目的地址,查詢路由表,再將分組複製到合適的輸出埠(網路卡)的快取中,這就是下面基於儲存器的交換結構。
後來有不經過CPU直接走匯流排的,但匯流排忙的時候就會被阻塞去等。
再後來有基於互連網路的交換方式,它有2N條匯流排,可以使N個輸入埠和N個輸出埠相連。
上面已經談到了MPLS的實質就是在轉發表中引入了標籤的概念,以前的路由器是通過目的地址進行轉發的,發出資料的路由器不知道資料會怎麼轉發,而是走一步看一步。但是LSR(Label Switching Router)標籤路由器它先就通過LDP(Label Switched Protocol)標籤分配協議發一個包到目的地址,利用L3層的路由功能就把要轉發的路徑LSP(Label Switched Path)先事先確定下來了,接下來LDR就照著這個已經早就算好的LSP一步步轉發就好了,從而提供了效率。
並且它提供了轉發等價類(FEC, Forwarding Equivalence Class)的概念,即安同樣的方式對待,即可以由管理員靈活地將目的地址相同的資料包歸為一類,或者將目的地址和源地址相同的資料包歸為一類(就就相當於普通的路由器),具體將具有某種服務質量的資料包歸於一類。總之,非常靈活。歸為一類的FEC就會分配一個相同的具有本地意義的標籤。在用LDP協議確實LSP時也早就在每一個LSR上為每一個FEC分配好本地有意義的標籤了。通過FEC的靈活設定,可以很靈活的控制從入LSR到出LSR的路徑,從而實現負載均衡(也稱為流量工程)。
所以現在的關鍵就是LDP如何生成LSP。剛才已經說了LSP的建立實質就是將FEC和標籤進行繫結。例如當網路的路由改變時,如果有一個邊緣LSR發現自己的路由表中出現了新的目的地址,並且這一地址不屬於任何現有的FEC,則該邊緣LSR需要為這個新目的地址建立一個新的FEC。
1)邊緣LSR決定該FEC將要使用的路由,向其下游LSR發起標籤請求訊息,並指時是要為哪個FEC分配標籤。
2)下游LSR收到請求訊息後,根據本地的路由表找出對應該FEC的下一跳,繼續向下遊LSR發出標籤請求訊息。
3)出口LSR最終收到這種訊息之後,就為該FEC分配合法的標籤資訊,並向上遊報告它分配的標籤。
4)收到標籤分配訊息的LSR檢查本地儲存的標籤請求訊息狀態,如果資料庫中記錄了相應的標籤請求訊息,LSR將為該FEC進行標籤分配,然後繼續向上遊報告標籤分配訊息。
5)入口LSR也做上步同樣的操作。這時,就完成了LSP的建立,接下來就是各LSR根據這事先生成好的LDP進行轉發了。
另外值得一提的是,維護標籤可以使用上面提到的LDP專有協議,也可以通過擴充套件BGP來實現。
關於路由區分符(Route Distinguisher:RD)和路由目標(Route Target:RT)
RD, VPN中IP地址的規劃是由客戶自行制訂的,所以有可能重疊。地址重疊的後果之一就是BGP無法區分來自不同VPN的重疊路由,從而導致某個站點不可達。為了解決這個問題,BGP/MPLS VPN除了採用在PE路由器上使用多個VRF表的方法,還引入了RD的概念。RD具有全域性唯一性,通過將8個位元組的RD作為IPv4地址字首的擴充套件,使不唯一的IPv4地址轉化為唯一的VPN-IPv4地址。VPN-IPv4地址對客戶端裝置來說是不可見的,它只用於骨幹網路上路由資訊的分發。RD和VRF表之間建立了一一對應的關係。通常情況下,對於不同PE路由器上屬於同一個VPN的子介面,為其所對應的VRF表分配相同的RD,換句話說,就是為每一個VPN分配一個唯一的RD。但是對於重疊VPN,即某個站點屬於多個VPN的情況,由於PE路由器上的某個子介面屬於多個VPN,此時,該子介面所對應的VRF表只能被分配一個RD,從而多個VPN共享一個RD。
RT, RT的作用類似於BGP中擴充套件團體屬性,用於路由資訊的分發。它分成Import RT和Export RT,分別用於路由資訊的匯入、匯出策略。當從VRF表中匯出VPN路由時,要用Export RT對VPN路由進行標記;在往VRF表中匯入VPN路由時,只有所帶RT標記與VRF表中任意一個Import RT相符的路由才會被匯入到VRF表中。RT使得PE路由器只包含和其直接相連的VPN的路由,而不是全網所有VPN的路由,從而節省了PE路由器的資源,提高了網路擴充性。RT具有全域性唯一性,並且只能被一個VPN使用。通過對Import RT和Export RT的合理配置,運營商可以構建不同拓撲型別的VPN,如重疊式VPN和Hub-and-spoke VPN。
MPLS VPN網路主要由CE、PE和P等3部分組成,如下圖:

- CE(Custom EdgeRouter,使用者網路邊緣路由器)裝置直接與服務提供商網路相連,它“感知”不到VPN的存在;
- PE(Provider EdgeRouter,骨幹網邊緣路由器)裝置與使用者的CE直接相連,負責VPN業務接入,處理VPN-IPv4路由,是MPLS三層VPN的主要實現者:
- P(ProviderRouter,骨幹網核心路由器)負責快速轉發資料,不與CE直接相連。在整個MPLSVPN中,P、PE裝置需要支援MPLS的基本功能,CE裝置不必支援MPLS。
MPLSVPN網路存在問題
- 本地路由衝突問題,即:上圖中,在BLUE和YELLOW兩個VPN中可能會使用相同的IP地址段,那麼在PE上如何區分這個地址段的路由是屬於哪個VPN的;
- 路由在網路中的傳播問題,上述問題會在整個網路中存在;
- PE向CE的報文轉發問題,當PE接收到一個目的地址在10.1.1.0/24網段內的IP報文時,他如何判斷該發給哪個VPN;
VRF: Virtual RoutingForwarding,VPN路由轉發表,也稱VPN-instance(VPN例項),是PE為直接相連的site建立並維護的一個專門實體,每個site在PE上都有自己的VPN-instance,每個VPN-instance包含到一個或多個與該PE直接相連的CE的路由和轉發表,另外如果要實現同一VPN各個Site間的互通,該VPN-instance還就應該包含連線在其他PE上的發球該VPN的Site的路由資訊。
VPN路由傳遞過程
- PE從CE接收路由,放入相應的VRF;
- 傳送方PE將VRF中的IPv4路由新增VRF中配置的RT-Export,RD等引數變為VPN v4路由然後通過MP-iBGP鄰居傳遞給遠端PE;
- 遠端PE接收到VPN v4路由後,比較本地VRF中的Import RT和接收到的Export RT,如果發現至少一個匹配項,則將VPN v4路由還原成IPv4路由匯入到對應的VRF;
- 遠端PE將VRF中的路由傳遞給CE;
// RT是Route Target的縮寫,RT的本質是每個VRF表達自己的路由取捨及喜好的方式,主要用於控制VPN路由的釋出和安裝策略;
// RD是Route Distinguisher的縮寫,是說明路由屬於哪個VPN的標誌;
https://wiki.openstack.org/wiki/QuantumBGP_MPLS_VPN 這個連結是OpenStack中對MPLS的設計:
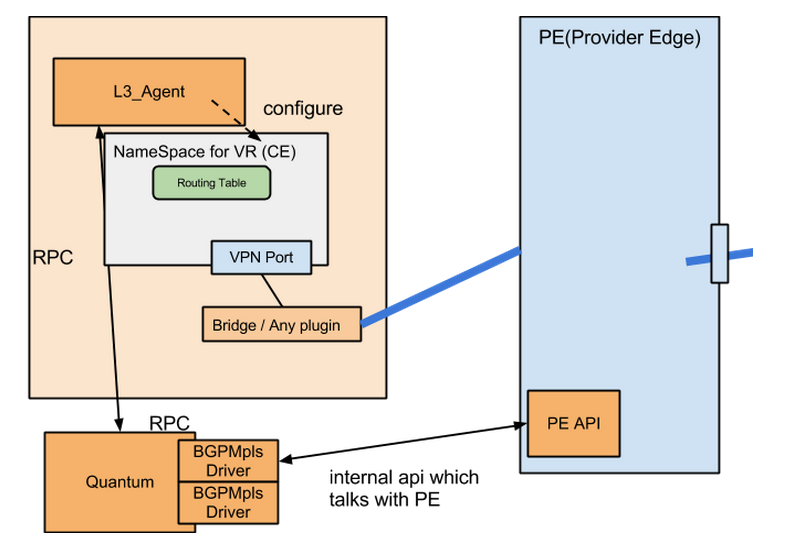
上面說了,兩個自治區域中會有兩個BGP發言人進行協商,那這兩個發言人稱之為一對peer, Neutron Server和BGP peer之間通過BGPMplsVPNDriver這個BGP發言人程式來實現協商過程。這個過程的命令使用順序如下:
Create bgpmplsvpngroup
quantum bgpmplsvpngroup-create --name test --route-target 6800:1
List bgpmplsvpngroup
quantum bgpmplsvpngroup-list -c id -c name -c route_target
Set bgpmplsvpngroup id to env variable
GROUP=`quantum bgpmplsvpngroup-list -c id -c name -c route_target | awk '/test/{print $2}'`
Delete bgpmplsvpngroup
quantum bgpmplsvpngroup-delete <id>
Create virtual router
quantum router-create router1
Create network which will connect virtual router and PE router
quantum net-create net-connect
Create subnet in the above network
quantum subnet-create net-connect 50.0.0.0/24 --name=subnet-connect
Create BGP MPLS VPN
quantum bgpmplsvpn-create --name=vpn1 --route_distinguisher=6800:1 --connected_subnet=subnet-connect --routes '[{"destination": ["10.0.0.0/24", "20.0.0.0/24"], "router_id": "router1"}]' --remote_prefixes list=true 30.0.0.0/24 40.0.0.0/24 --connect_to list=true $GROUP --connect_from list=true $GROUP
List BGP MPLS VPN
quantum bgpmplsvpn-list
Delete BGP MPLS VPN
quantum bgpmplsvpn-delete vpn1
Insert VPN service to the router
quantum router-service-insert router1 vpn1
20150116華為公司的另外一個類似的BP
資料模型
- MPLS VPN: /v2.0/inter_dc/, Mapping connectivity between attachment circuits in different DCs using tunnels
- Attachment Circuit: /v2.0/inter_dc/attachment_circuits, Mapping the connectivity between PE and CE in MPLS
- Provider Edge: /v2.0/inter_dc/provider_edges, Mapping the concept of PE in MPLS
- Tunnel: /v2.0/inter_dc/tunnels, Mapping the connectivity between PE and PE in MPLS that provide Qos, Backup-type and Bandwidth criteria
L2層DC間互聯,L2層直接使用overlay方式不交換路由,L3層互聯在CE和PE之間需要交換路由
L2層DC間互聯
1, First step is to create provider edges in Datacenter-1 and Datacenter-2.
POST /v2.0/inter_dc/provider_edges
{
"provider_edges": [
{
"name": "DC1_Provider_Edge”
},
{
"name": "DC2_Provider_Edge”
}]
}
2, Attachment circuits can be created for each tenant to attach the L2 networks to the provider edge in each datacenter.
POST /v2.0/inter_dc/attachment_circuits
{
"attachment_circuits": [
{
"name": "DataCenter 1",
"type": "L2" // Other options L3
"provider_edge_id": "<UUID of provider edge 1>",
"networks": [
{
"network_id": "<UUID of L2 network to be extended>"
}
// More L2 networks are allowed
},
{
"name": "DataCenter 2",
“type”: “L2” // Other options L3
"provider_edge_id": "<UUID of provider edge 2>",
"networks": [
{
"network_id": "<UUID of L2 network to be extended>"
}
// More L2 networks are allowed
}]
}
3, create mpls_vpn
POST /v2.0/inter_dc/mpls_vpns
{
"mpls_vpn":
{
"name": "Datacenter Interconnect",
“type”: “L2”, // Other options: L3
"tunnel_options": {
"tunnel_type": "fullmesh", //Other options: Customized
"tunnel_backup": "frr", // Other options: Secondary
"qos": "Gold", // Other options: Silver, Bronze
"bandwidth": "10" // Unit: Gbps
}
"attachment_circuits": [
{
"attachment_circuit_id": "<UUID of attachment circuit>"
},
{
"attachment_circuit_id": "<UUID of attachment circuit>"
}]
}
}
L3層DC間互聯
just associate with router rather network in attachement_ciruits, then define the tunnels.
[1], https://docs.google.com/a/canonical.com/file/d/0B3xdv0OBUS0SMmFQb0tZMmR3RUE/edit
[2], https://review.openstack.org/#/c/101044/
相關文章
- OpenDaylight學習 ( by quqi99 )
- OpenStack Neutron FWaaS 學習( by quqi99 )
- Quagga 路由軟體學習(by quqi99)路由
- different testing types ( by quqi99 )
- MPLS QoS的實現
- MPLS的完整工作指南
- MPLS基礎與工作原理
- mpls標籤分配原理——VecloudCloud
- MPLS 的最佳化——VecloudCloud
- mpls rd rt 的作用-VeCloudCloud
- 使用dmsetup命令生成snapshot ( by quqi99 )
- mpls l2vpn 原理--VeCloudCloud
- mpls ldp lsp建立過程——VecloudCloud
- MPLS RSVP訊息處理——VecloudCloud
- MPLS ARP的常用方法——VecloudCloud
- Vmware中的虛擬網路 ( by quqi99 )
- Screen/Tmux/Byobu分屏工具的使用 ( by quqi99 )UX
- MPLS L2 VPN部署模式--VeCloud模式Cloud
- MPLS VPN典型應用場景——VecloudCloud
- 華為ENSP MPLS-動態LSP配置
- MPLS與ATM/IP的區別-VeCloudCloud
- MPLS QoS的實現——微雲專線
- mpls atm交換技術 ip技術——VecloudCloud
- MPLS BGP標籤分發過程——VecloudCloud
- MPLS L2VPN實現方式-VeCloudCloud
- 編譯linux kernel及製作initrd ( by quqi99 )編譯Linux
- 學習學習再學習
- MPLS-VPN的幾種備份方式——VecloudCloud
- MPLS與專線的區別在哪裡?——VecloudCloud
- BGP/MPLS 虛擬專用網路 Option B
- 給Linux虛機擴充硬碟空間 ( by quqi99 )Linux硬碟
- 深度學習——學習目錄——學習中……深度學習
- MPLS標籤分發協議正確方式——Vecloud協議Cloud
- MPLS VPN:端到端全程全網技術——VecloudCloud
- BGP/MPLS 虛擬專用網路 Option B RR
- MPLS VPN技術概述-VeCloudMPLS VPN技術概述-VeCloudCloud
- HCIE Routing&Switching之MPLS LDP理論
- 深度學習(一)深度學習學習資料深度學習