資料結構-各種排序演算法效率對比圖
為了加深記憶,製作此圖。
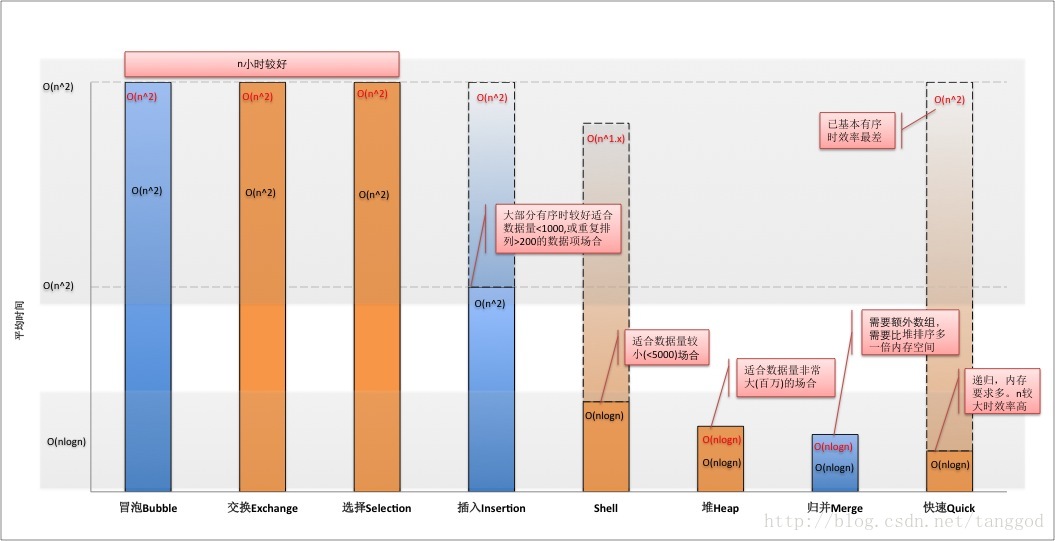
根據此表整理了排序對比圖,其中
1. 柱狀圖藍色表示是穩定的,柱狀圖黃色表示不穩定的;
2. 柱狀圖中間的數字表示時間複雜度,紅色字型表示最差時,黑色字型表示平均複雜度;
3. 柱狀圖虛線表示最差時的時間複雜度,因為氣泡排序,交換排序,選擇排序的最差和平均時間複雜度是一樣的,都是O(n^2),所以圖中看不見虛線;
4. 實線柱狀圖,即平均時間複雜度,效率從低到高依次是:
氣泡排序 ≈ 交換排序 ≈選擇排序 < 插入排序 <Shell排序 <堆排序 < 歸併排序 <快速排序
大多數情況下,快速排序效率最高,但如果資料已經基本有序的情況下,效率退化到O(n^2)。
-
氣泡排序是最慢的排序演算法。在實際運用中它是效率最低的演算法,時間複雜度為O(n^2)。
-
插入排序是把序列中的值插入一個已經排序好的序列中,直到該序列的結束。它比氣泡排序快2倍。一般不適合資料量比較大的場合或資料重複比較多的場合。
-
選擇排序在實際應用中和氣泡排序基本差不多,使用較少。
-
Shell排序是通過將資料分成不同的組,先對每一組進行排序,然後再對所有的元素進行一次插入排序,以減少資料交換和移動的次數,其中Shell排序比氣泡排序快5倍,比插入排序大致快2倍。Shell排序比起快速排序,歸併排序,堆排序慢很多。但shell演算法比較簡單,特別適合資料量在5000以下且效能要求不是很高的場合。
-
歸併排序先分解要排序的序列,從1分成2,2分成4,依次分解,當分解到只有1個一組的時候,就可以排序這些分組,然後依次合併回原來的序列中,這樣就可以排序所有資料。合併排序比堆排序稍微快一點,由於它需要一個額外的陣列,因此需要比堆排序多一些記憶體空間。
-
快速排序是利用分治法,進行大規模遞迴的演算法,具體見下面步驟: 步驟1: 如果不多於1個資料,直接返回。 步驟2:般選擇序列最左邊的值作為支點資料。
步驟3: 將序列分成2部分,一部分都大於支點資料,另外一部分都小於支點資料。
步驟4: 對兩邊利用遞迴排序數列。快速排序比大部分排序演算法都要快。儘管在某些特殊的情況下有比快速排序快的演算法,但通一般情況下,沒有比它更快的。
快速排序比大部分排序演算法都要快。儘管在某些特殊的情況下有比快速排序快的演算法,但通一般情況下,沒有比它更快的。
-
堆排序將是所有的資料先建成一個堆,如大頂堆(最大的資料在堆頂),然後將堆頂資料和序列的最後一個資料交換,然後重新建堆,交換資料,依次下去,就可以排序所有的資料。由於不需要大量的遞迴或者多維的暫存陣列,因此這對於資料量非常巨大的序列是很合適的,比如超過數百萬條記錄,因為快速排序,歸併排序都使用遞迴來設計演算法,在資料量非常大的時候,可能會發生堆疊溢位錯誤。
資料來源:
| 排序法 | 平均時間複雜度 | 最差情形 | 穩定度 | 額外空間 | 備註 |
| 氣泡排序 | O(n2) | O(n2) | 穩定 | O(1) | n小時較好 |
| 交換排序 | O(n2) | O(n2) | 不穩定 | O(1) | n小時較好 |
| 選擇排序 | O(n2) | O(n2) | 不穩定 | O(1) | n小時較好 |
| 插入排序 | O(n2) | O(n2) | 穩定 | O(1) | 大部分已排序時較好 |
| Shell排序 | O(nlogn) | O(ns) 1<s<2 | 不穩定 | O(1) | s是所選分組 |
| 快速排序 | O(nlogn) | O(n2) | 不穩定 | O(nlogn) | n大時較好 |
| 歸併排序 | O(nlogn) | O(nlogn) | 穩定 | O(1) | n大時較好 |
| 堆排序 | O(nlogn) | O(nlogn) | 不穩定 | O(1) | n大時較好 |
java排序原始碼下載:
http://download.csdn.net/detail/tanggod/6919719
相關文章
- 【資料結構】 各種排序演算法的實現資料結構排序演算法
- 複習資料結構:排序演算法(五)——快速排序的各種版本資料結構排序演算法
- 【資料結構與演算法】內部排序總結(附各種排序演算法原始碼)資料結構演算法排序原始碼
- IOS各種集合遍歷效率對比iOS
- FreeMarker對應各種資料結構解析資料結構
- 資料結構與演算法知識點總結(4)各類排序演算法資料結構演算法排序
- 資料結構與演算法——排序資料結構演算法排序
- 資料結構連結串列各種問題資料結構
- 資料結構與演算法 排序演算法 快速排序【詳細步驟圖解】資料結構演算法排序圖解
- 演算法資料結構 | 圖論基礎演算法——拓撲排序演算法資料結構圖論排序
- 資料結構與演算法——排序演算法-氣泡排序資料結構演算法排序
- 資料結構與演算法——排序演算法-選擇排序資料結構演算法排序
- 資料結構與演算法——排序演算法-歸併排序資料結構演算法排序
- 資料結構與演算法——排序演算法-基數排序資料結構演算法排序
- [資料結構與演算法] 排序演算法資料結構演算法排序
- 資料結構與演算法(八):排序資料結構演算法排序
- 資料結構與演算法——堆排序資料結構演算法排序
- 【資料結構與演算法】堆排序資料結構演算法排序
- 資料結構與演算法之排序資料結構演算法排序
- 資料結構與演算法----# 一、排序資料結構演算法排序
- 資料結構與演算法:堆排序資料結構演算法排序
- 資料結構與演算法——快速排序資料結構演算法排序
- 資料結構與演算法——桶排序資料結構演算法排序
- 對資料結構和演算法的總結和思考(三)--希爾排序資料結構演算法排序
- Dotnet演算法與資料結構:Hashset, List對比演算法資料結構
- 複習資料結構:排序演算法(六)——堆排序資料結構排序演算法
- 複習資料結構:排序演算法(七)——桶排序資料結構排序演算法
- 複習資料結構:排序演算法(八)——基排序資料結構排序演算法
- 5種排序演算法效能比較總結排序演算法
- 用Jupyter+pandas資料分析,6種資料格式效率對比
- 排序(3)--各類排序演算法的比較排序演算法
- 對資料結構和演算法的總結和思考(六)--計數排序資料結構演算法排序
- MySQL 對比資料庫表結構MySql資料庫
- 排序演算法對比排序演算法
- 資料結構與演算法 進階排序資料結構演算法排序
- 資料結構與演算法 基礎排序資料結構演算法排序
- 【資料結構與演算法】歸併排序資料結構演算法排序
- Java資料結構與排序演算法 (二)Java資料結構排序演算法