開放網路作業系統 ONOS Blackbird效能評估
目標
ONOS是一個網路控制器。applications透過intent APIs與ONOS進行互動。ONOS透過其南向適配層控制資料網路的轉發(例如,openflow網路)。ONOS控制層與資料轉發層之間是ONOS流 子系統,ONOS流子系統是將application intens轉換為openflow流規則的重要組成部分。ONOS也是一個分散式系統,至關重要的是ONOS分散式架構使其效能隨著叢集數量增加而提 高。這份評估報告將ONOS看作一個整體的叢集系統,計劃從應用和操作環境兩個角度去評估ONOS效能。
我們設計了一系列的實驗,測試在各種應用和網路環境下ONOS的延遲和吞吐量。並透過分析結果,我們希望提供給網路運營商和應用開發商第一手資料去了解ONOS的效能。此外,實驗的結果將有助於開發人員發現效能瓶頸並最佳化。
下圖把ONOS分散式系統作為一個整體,介紹了關鍵的測試點。
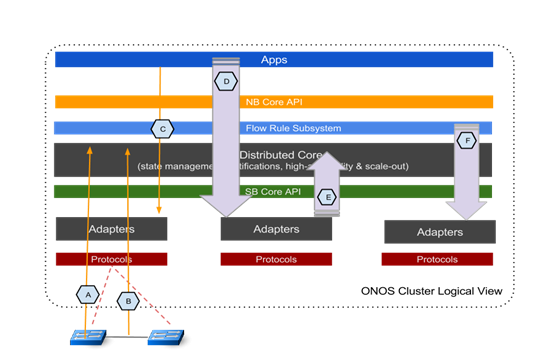
圖中包括如下效能測試點:
延遲:
- A -交換機 連線/斷開;
- B -link啟用/斷開;
- C -intent的批次安裝/刪除/路徑切換;
吞吐量:
- D -intent操作;
- E -link事件(測試暫緩);
- F –迸發流規則安裝。
通用實驗設定
叢集規模效能測試:
ONOS最突出的特點是其分散式架構。因此,ONOS效能測試的一個關鍵方面是比較和分析不同叢集大小下ONOS的效能。所有的測試用例將以ONOS叢集節點數量為1,3,5,7展開。
測試工具
為了展示ONOS的本質特徵,使測試不受測試儀器的瓶頸限制,我們採用了一些比較實用的工具進行實驗。所有實驗,除了與Openflow協議互動的 交換機和埠及其它相關的,我們在ONOS的適配層部署了一套Null Providers與ONOS core進行互動。Null Providers擔任著生成device,link,host以及大量的流規則的角色。透過使用Null Providers,我們可以避免並消除Openflow適配和使用真實裝置或者模擬的Openflow裝置所存在的潛在的效能瓶頸。
同時,我們也部署了一些負載生成器,這樣可以使應用或者網路介面生成高強度的負載去觸及ONOS的效能極限。
這些生成器包括:
1.Intent performance 生成器“onos-app-intent-perf”,它與intent API互動,生成intent安裝/刪除操作,並根據ONOS可承受的最高速度自我調節生成的Intent操作的負載。
2.流規則安裝Python指令碼工具與ONOS flow subsystem互動去安裝和刪除subsystem中的流規則。
3.Null LinkProvider中的link 事件(閃爍)生成器,可以迅速提升傳送速度到ONOS所能承受的極限並依此速率傳送link up/down資訊給ONOS core。
4.此外,我們在"topology-events-metrics" 和"intents-events-metrics" 應用中利用計數器去獲取關鍵事件的時間戳與處理速率來方便那些時間及速度相關的測試。
我們將在後續的每個不同的測試過程中詳細介紹這些生成器的配置。
測試環境配置
A 7臺 叢集實驗所需要的裸伺服器。每個伺服器的規格如下:
- 雙Intel Xeon E5-2670v2處理器為2.5GHz - 10核心/20超執行緒核心
- 32GB1600MHz的DDR3 DRAM
- 1Gbps的網路介面卡
- Ubuntu的14.04 OS
- 叢集之間使用ptpd同步
ONOS軟體環境
- Java HotSpot(TM) (TM)64-Bit server VM; version 1.8.0_31
- JAVA_OPTS=“${JAVA_OPTS: - Xms8G-Xmx8G}”
- onos-1.1.0 snapshot:
- a31e13471ee626abce2bc43c413fab17586f4fc3
- 其他的具體與用例相關的ONOS引數將在具體的用例中進行說明
下面將具體介紹每個用例的細節配置,測試結果討論及分析。
實驗A&B - 拓撲(Switch,Link)發現時延測試
目標
本實驗是測試ONOS控制器在不同規模的叢集環境中是如何響應拓撲事件的,測試拓撲事件的型別包括:
1)交換機連線或斷開ONOS節點
2)在現有拓撲中鏈路的up和down
ONOS作為一個分散式的系統架構,多節點叢集相比於獨立節點可能會發生額外的同步拓撲事件的延遲。除了限制獨立模式下的延遲時間,也要減少由於onos叢集間由於EW-wise通訊事件產生額外延時。
配置和方法—交換機連線/斷開的延遲
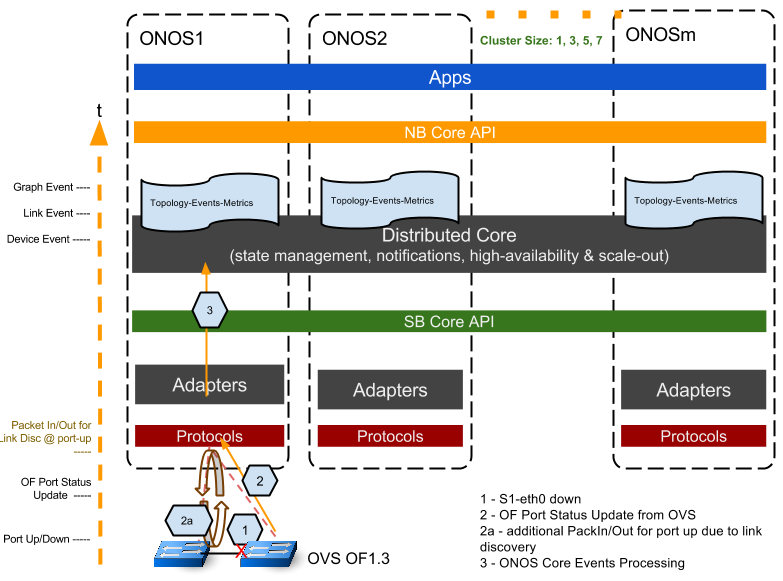
下面的圖表說明了測試設定。一個交換機連線事件,是在一個“floating”(即沒有交換機埠和鏈路)的OVS(OF1.3)上透過“set- controller”命令設定OVS橋連線到onos1控制器。我們在OF控制層面網路上使用tshark工具捕捉交換機上線的時間戳,ONOS Device和Graph使用“topology-event-metrics”應用記錄時間戳。透過整理核對這些時間戳,我們得出從最初的事件觸發到 ONOS在其拓撲中記錄此事件的“端到端”的時序曲線。

所需得到的幾個關鍵時間戳如下:
1.裝置啟動連線時間點t0,tcp syn/ ack;
2.OpenFlow協議的交換:
- t0 -> ONOS Features Reply;
- OVS Features Reply -> ONOS Role Request; (ONOS 在這裡處理選擇主備控制器);
- ONOS Role Request -> OVS Role Reply –OF協議的初始交換完成。
3.ONOS core處理事件的過程:
- OF協議交換完成後觸發Device Event;
- 本地節點的Device Event觸發Topology (Graph) Event。
同樣的,測試交換機斷開事件,我們使用ovs命令“del-controller”斷開交換機與它連線的ONOS節點,捕獲的時間戳如下:
1.OVS tcp syn/fin (t0);
2.OVS tcp fin;
3.ONOS Device Event;
4.ONOS Graph Event (t1).
交換機斷開端到端的延遲為(T1 - T0)
當我們增大ONOS叢集的大小,我們只連線和斷開ONOS1上的交換機,並記錄所有節點上的事件時間戳。叢集的整體延遲是Graph Event報告中最遲的節點的延時時間。在我們的測試指令碼中,我們一次測試執行多個迭代(例如,20次迭代)來收集統計結果。
設定和方法—鏈路up/down的延遲
測試一條連結up / down事件的延遲,除了我們用兩個OVS交換機建立鏈路(我們使用mininet建立一個簡單的兩個交換機的線性拓撲結構)外,我們使用了與交換機連線 測試的類似方法。這兩個交換機的主控權屬於ONOS1。參照下面的圖表。初步建立交換機-控制器連線後,設定一個交換機的介面up或down,我們透過端 口up或down事件來觸發此測試。
一些關鍵的時間戳記錄,如下所述:
1. 交換機埠up/down, t0;
2. OVS向ONOS1傳送OF PortStatus Update訊息;
2a.在埠up的情況下,ONOS透過給每個OVS交換機傳送鏈路發現訊息來產生鏈路發現事件,同時ONOS收到其他交換機傳送的Openflow PacketIn訊息。
3.ONOS core處理事件過程:
由OF port status訊息引起的Device事件; (ONOS處理)
鏈路down時,Link Event由Device Event觸發在本地節點產生,鏈路up時,Link Event是在鏈路發現PacketIn/out完成後產生的;(主要時間都是在OFP訊息和ONOS處理上)
本地節點生成Graph Event。(ONOS處理)
類似於交換機的連線測試,我們認為在Graph Event中登記的叢集中最遲的節點的延時時間為叢集的延遲。
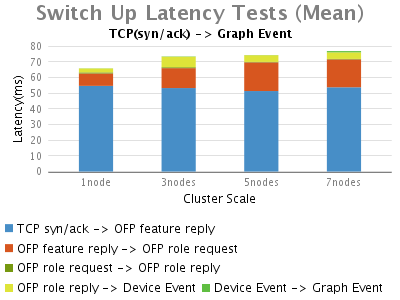
結果
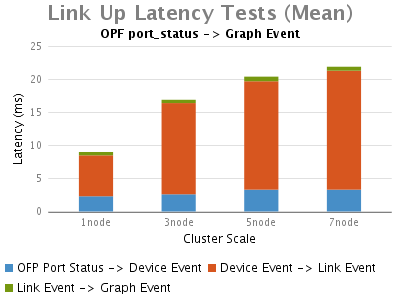
Switch-add Event:
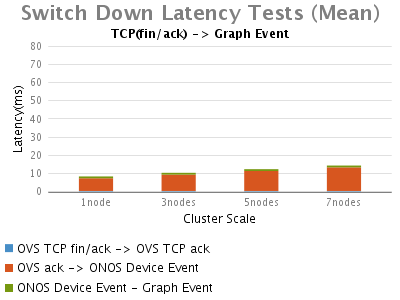
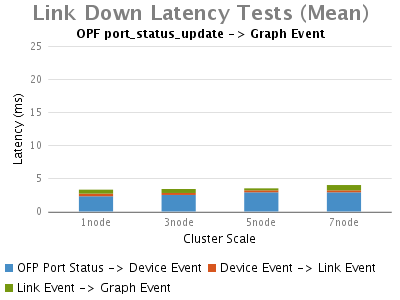
Link Up/Down Event:
分析和總結
Switch Connect/Disconnect Event:
當一個交換機連線到ONOS時,明顯的時延劃分為以下幾個部分:
1.鏈路發現的中時延最長的部分,是從最初的tcp連線到ONOS收到Openflow features-replay訊息。進一步分析資料包(在結果圖中未示出),我們可以看到大部分時間是花在初始化控制器與交換機的OpenFlow握手 階段,ONOS等待OVS交換機響應它的features_request。而這個時延很大程度上不是由ONOS的處理引起的。
2.其次是在"OFP feature reply -> OFP role request"部分,這部分時延也會隨著ONOS叢集規模增加而增加,其主要花費在ONOS給新上線的交換機選擇主控權上,這是由於單節點的ONOS只 需在本地處理,而多節點的叢集環境中,叢集節點之間的通訊將會帶來這個額外的延時
3.接著便是從OpenFlow握手完成(OFP role reply)到ONOS登記一個Device Event的過程中消耗的時延。這部分的時延也受多節點ONOS配置影響,因為此事件需要ONOS將其寫入Device Store。
4.最後一個延時比較長的是ONOS在本地處理來著Device store的Device event到向Graph中註冊拓撲資訊事件的部分。
斷開交換機時,隨著ONOS叢集規模的增大ONOS觸發Device事件的時延將略有增加。
總之,在OpenFlow訊息交換期間,OVS對feature-request的響應時延佔據了交換機建立連線事件中,整體時延的絕大部分。接 著,ONOS花費約9毫秒處理主控權選。最後,ONOS在多節點叢集環境下,由於各節點之間需要通訊選舉主節點,交換機上/下線時延將都會增加。
Link Up/Down Events:
此次測試,我們首先觀察到的是,鏈路up事件比鏈路down事件花費更長的時間。透過時延分析,我們可以看到OVS的埠up事件觸發了ONOS特 殊的行為鏈路發現,因此,絕大多數時延主要由處理鏈路發現事件引起。與單節點的ONOS相比這部分時延受叢集節點的影響也比較大。另外,大多數ONOS core花費在向Graph登記拓撲事件上的時延在個位數的ms級別。
在大部分的網路操作情況下,雖然整體拓撲事件的低延遲是可以被容忍的,但是交換機/鏈路斷開事件卻至關重要,因為它們被更多的看作是 applications的adverse events。當ONOS能更快速的檢測到link down/up事件時,pplications也就能更快速的響應此adverse events,我們測試的此版本的ONOS具有在個位數ms級發現switch/link down事件的能力。
實驗C :intent install/remove/re-route延遲測試
目的
這組測試旨在得到ONOS當一個application安裝,退出多種批大小的intents時的延遲特性(即響應時間)。
同時也得到ONOS路徑切換事件的延時特性,即最短路徑不可用,已安裝的intent由於路徑改變而需要重路由時所花費的時延。這是一個ONOS的 全方位系統測試,從ONOS的 NB API 經過intent 和flow subsystem 到ONOS的 SB API;採用Null Provider代替Openflow Adaptor進行測試。
這組測試結果將向網路運營商和應用開發者提供當operating intents時applications所期望的響應時間以及intents批的大小和叢集數量的大小對時延的影響的第一手資料。
配置和方法—batch intent安裝與退出
參考下圖,我們用ONOS內建的app“push-test-intent”從ONOS1並透過ONOS1的intent API推進一個批的點對點intents。“push-test-intent”工具構造一系列的基於終點的,批大小和application id的intents。然後透過intent API 傳送這些intents請求。當成功安裝所有的intents時,返回延遲(響應時間)。隨後退出這些intents並返回一個退出響應時間。當 intents請求被髮送時,ONOS內部轉換intents到流規則並寫入相應的分散式儲存來分發intents和流表。
參考下圖,特別是我們的實驗中,intents被構建在一個端到端的7個線性配置的交換機上,也就是說所有intents的入口是從S1的一個埠 和它們的出口是S7的一個埠。(我們使用在拓撲中額外的交換機S8進行intent re-route測試,這個測試後續描述)。我們透過Null Providers來構建交換機(Null Devices),拓撲(Null Links)和流量(Null Flows)。
當增大叢集節點數量時,我們重新平均分配switch的主控權到各個叢集節點。
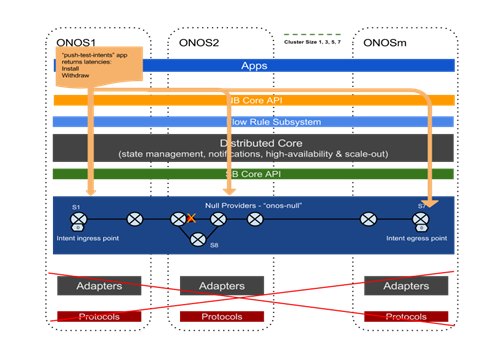
在這個實驗中,我們將使用如下指標來衡量ONOS效能:
- 所有安裝的intents是6hops點到點intents;
- Intent批的大小:1,10,100,1000,5000 intents;
- 測試次數:每個用例重複測試20次(4次預測試之後統計);
- 叢集規模大小從1到3,5,7個節點。
配置和方法--intent Re-route
同樣參照上圖,intent re-route延遲是一個測試ONOS在最短路徑不可用的情況下,重新安裝所有intents到新路徑的速度。
測試順序如下:
1.我們透過“push-test-intents -i”選項預安裝不會自動退出的intents線上性最短路徑上。然後我們透過修改Null Provider 鏈路定義檔案模擬最短路徑的故障。當新拓撲被ONOS發現時,我們透過檢查ONOS 日誌獲取觸發事件的初始時間戳t0;
2.由於 6-hop最短路徑已不可用。ONOS切換到透過S8的7-hop備份路徑。Intent和流系統響應該事件,退出舊intents並刪除舊流表(因為ONOS當前實現,所有intents和流已不可重新使用)。
3.接下來,ONOS重新編譯intents和流,並安裝。在驗證所有intents確實被成功安裝後,我們從“Intents-events-metrics”捕獲最後的intent安裝時間戳(t1)。
4.我們把(t1-t0)作為ONOS 重路由intent(s)的延遲。
5.測試指令碼迭代的幾個引數:
a. Intent初始安裝的批大小:1,10,100,1000和5000 intents;
b.每個測試結果統計的是執行20次的結果平均值(4個預測試之後開始統計);
c. ONOS叢集規模從1,到3,5,7節點。
結果
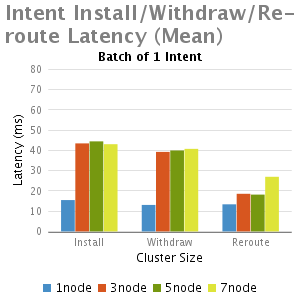
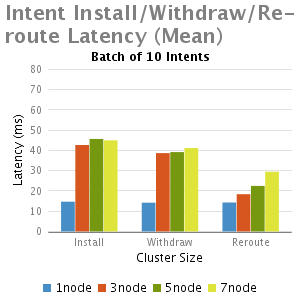
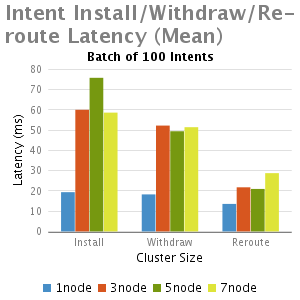
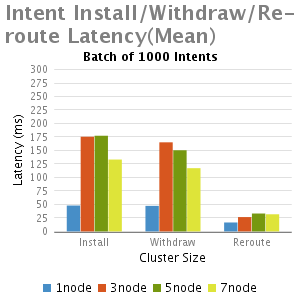
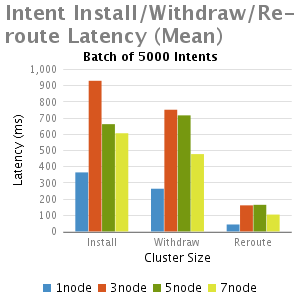
分析和總結
我們從這個實驗中得出結論:
1.正如預期,與單節點的ONOS相比,多個節點的ONOS叢集由於EW-wise通訊的需要延遲比較大
2.小批intents(1-100),不計批大小時,其主要的延時是一個固定的處理時延,因此當批大小增大,每一個intent安裝時間減少,這就是時延大批的優點。
3.批大小非常大的情況下(如5000),隨著叢集大小增加(從3到7),延遲減少,其主要是由於每個節點處理較小數量的intents;
4.Re-routeing延時比初始化安裝和退出的延遲都小。
實驗D:Intents Operation吞吐量
目標
本項測試的目的是衡量ONOS處理intents operations 請求的能力。SDN控制器其中一個重要用例就是允許agile applications透過intents和流規則頻繁更改網路配置。作為一款SDN控制器,ONOS應該具有高水平的intents安裝和撤銷處理能 力。ONOS使用的分散式架構, 隨著叢集規模的增加,理應能夠維持較高的intent operation吞吐量。
設定和方法
下圖描述了測試方法:

本測試使用工具"intent-perf"來產生大量的Intents operation請求。這個intent-perf工具可以在ONOS叢集環境中的任何一個節點啟用並使用。這個工具在使用過程中有個三個引數需要配置:
- numKeys – 唯一的intents數量, 預設 40,000;
- cyclePeriod – intents安裝和撤銷的週期(時間間隔),預設 1000ms;
- numNeighbors –程式執行時,傳送到各個叢集節點的方式。0表示本節點;-1表示所有的叢集節點
當intent-perf在ONOS節點執行時,以恆定的速率產生大量的、ONOS系統可以支援的intents安裝撤銷請求。在ONOS 日誌中或 cli request中,會週期性的給出總體的intents處理吞吐量。持續執行一段時間後,我們可以觀察到在叢集的某個或某些節點總體吞吐量達到了飽和狀 態。總體吞吐量需要包含intents安裝撤銷操作。統計所有執行intent-perf這個工具的ONOS節點上的吞吐量並求和,從而得到ONOS叢集 的總體吞吐量。
intent-perf只產生"1-hop" 的intents,即這些intents被編譯而成的流表的出口和入口都是在同一個交換機上,所以Null providers模組不需要生成一個健全的拓撲結構。
特別是本實驗中,我們使用兩個相鄰的場景。首先,設定numNeighbors = 0,這種場景下,intent-perf只需要為本地的ONOS節點產生的intents安裝和撤銷請求,從而把intents的東西向介面通訊降至最 低;其次,設定numNeighbors 為-1後,intent-perf生成器產生的intents安裝和撤銷請求需要分發到所有的ONOS叢集節點,這樣會把東西向介面的通訊量最大化。本次 測試持續進行了300秒的負載測試,統計叢集的總體吞吐量。其他的引數使用預設值。
結果
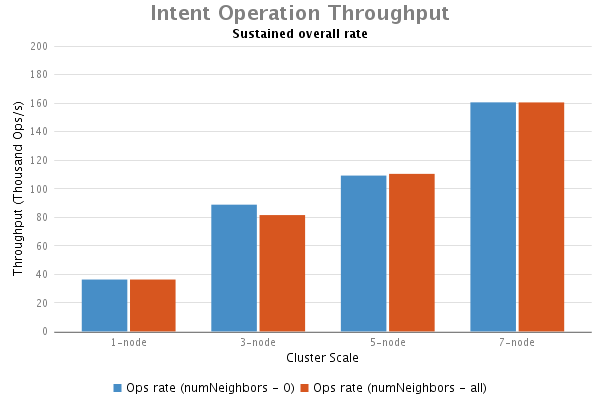
分析和結論
透過本次實驗得出結論如下:
1.我們看到在ONOS的intents operations測試中一個明顯趨勢:總體吞吐量隨著叢集節點的增加而增加;
2.在流表子系統測試中叢集的場景對吞吐量的影響微乎其微。
實驗F:Flow子系統迸發吞吐量測試
目的
如前面所提到的,流子系統是onos的一個組成部分,其作用是將Intents轉換成可以安裝到openflow交換機上的流規則。另外,應用程式 可以直接呼叫其北向api來注入流規則。使用北向api和intent框架是此次效能評估的關鍵。另外,此次實驗不但給我們暴漏了端到端Intent performance的效能缺陷,而且展示了當直接與流規則子系統互動時對應用的要求。
配置及方法
為了產生一批將被onos安裝刪除的流規則,我們使用指令碼“flow-tester.py”。實際上這些指令碼是onos工具執行的一部分。具體位置 在($ONOS_ROOT/tools/test/bin)目錄下。執行這個指令碼將觸發onos安裝一套流規則到所控制的交換機裝置,當所有流規則安裝成 功之後將會返回一個時延時間。這個指令碼也會根據接收的一系列的引數去決定這個測試怎麼執行。這些引數如下:
- 每個交換機所安裝的流規則的數量
- 鄰居的數量-由於交換機的連線的控制器並非本地的onos節點,需要onos本地節點同步流規則到(除了執行指令碼的onos本地節點之外的)onos節點
- 服務的數量-執行onos指令碼的節點數量,即產生流規則的onos節點數量
下圖簡要的描述了測試的配置:
從下圖可以看出,onos1,onos2是執行onos指令碼產生流規則的兩個伺服器;當兩個流生成伺服器生成流給兩個鄰居,也就是所生成的流規則被傳遞到兩個與之相鄰的節點安裝。(因為這個流規則屬於被鄰居節點控制器的交換機)。

我們使用了Null Provider作為流規則的消費者,繞過了使用Openflow介面卡和真實的或者模擬的交換機存在的潛在的效能限制。
具體實驗引數設定
- Null Devices的數量保持常量35不變,然後被平均的分配到叢集中的所有節點,例如,當執行的叢集中有5個節點,每個節點將控制7個Null Devices;
- 叢集一共安裝122500條流規則-選擇這個值其一是因為它足夠大,其二,它很容易平均分配到測試中所使用的叢集節點。這也是工具“flow-tester.py”計算每個交換機所安裝的流規則數量的一個依據。
- 我們測試了2個關聯場景:1)鄰居數量為0,即所有的流規則都安裝在產生流的伺服器上場景;2)鄰居數量為-1,即每個節點給自己以及叢集中的其它節點產生流規則
- 測試叢集規模1,3,5,7
- 響應時間為4次預測試之後20次的的測試時間統計整合得出
備註:版本釋出的時候,ONOS核心仍然採用Hazelcast作為儲存協議來備份流規則。
實驗表明,使用Hazelcast協議作為備份,可能導致流規則安裝速率頻繁迸發增長。
在這一系列實驗中,我們透過修改釋出版本如下路徑的程式碼關閉了流規則備份。($ONOS_ROOT/core/store/dist/src /main/java/org/onosproject/store/flow/impl /DistributedFlowRuleStore.java)
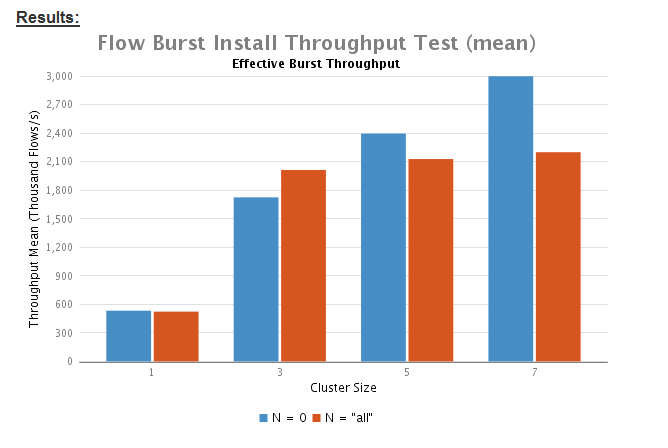
分析與結論
透過測試,可以得出如下系統效能測試結論:
1.根據測試資料顯示,當配置N=0時,與配置N=“all”相比,系統有更高的吞吐量。也就是說當生成的流規則只安裝給本地ONOS節點控制器的 裝置時,流子系統的效能比安裝給所有ONOS節點控制的裝置時高。因為,ONOS節點之間的EW-wise通訊存在開銷/瓶頸。即,當配置N=“all” 時,效能低,符合預期值。
2.總的來說,這兩種情況下透過增大叢集節點數量測試,吞吐量隨著叢集數量的增加有明顯的提高。但是這種提高是非線性的。例如,N=“all”與N=“0”相比,當節點間需要通訊同步時,平穩增加的效能趨於平緩。
3.設定N=“all”與N=“0”獲得的類似的效能資料說明,EW-wise通訊沒有成為ONOS intent operation效能的瓶頸。
相關文章
- 開放式漏洞評估系統 - OpenVAS
- 系統效能評價---效能評估
- 網路效能評估(六)
- 中小企業網路安全評估
- AIX系統磁碟I/O效能評估AI
- Linux作業系統網路模組Linux作業系統
- 推薦系統評估
- 企業ERP評估中財務與分銷系統評估措施(轉)
- 網路作業系統和"鮮果線上"作業系統
- MQTT 開放基準測試規範:全面評估你的 MQTT Broker 效能MQQT
- 【工業網際網路】重磅推薦:工業網際網路成熟度評估模型模型
- JuiceFS 效能評估指南UI
- 試用一款網路作業系統!作業系統
- 什麼是網路安全風險評估?需要評估哪些內容?
- 思科網際網路絡作業系統(IOS)——習題作業系統iOS
- 龍蜥作業系統通過工信部電子標準院首批開源專案成熟度評估作業系統
- 作業系統、網路等八股面試題作業系統面試題
- Linux作業系統網路應用解疑(轉)Linux作業系統
- AIX作業系統效能分析報告AI作業系統
- 推薦系統的評估方法
- Linux效能評估工具Linux
- 美創科技釋出資料安全綜合評估系統|推進安全評估高效開展
- 網路安全評估方式有哪些?為什麼要進行安全評估?
- 網路效能評價方法
- 對於網路安全風險評估 企業當如何妥善處理?
- 從 HPC 到 AI:探索檔案系統的發展及效能評估AI
- 效能優化-使用 RAIL 模型評估效能優化AI模型
- 利用OSW工具監控作業系統效能作業系統
- 作業系統(1)——作業系統概述作業系統
- 作業系統(一):作業系統概述作業系統
- 資訊系統安全評估報告
- AIX系統網路效能分析(轉)AI
- 網路分流器-網路分流器-網路安全評估探討
- AIX 5.3主機效能評估AI
- 記憶體效能評估(四)記憶體
- 系統效能評價---效能設計
- 物聯網作業系統列表作業系統
- 作業系統(二):作業系統結構作業系統