Caffe學習系列(21):caffe圖形化操作工具digits的安裝與執行
經過前面一系列的學習,我們基本上學會了如何在linux下執行caffe程式,也學會了如何用python介面進行資料及引數的視覺化。
如果還沒有學會的,請自行細細閱讀: caffe學習系列:http://www.cnblogs.com/denny402/tag/caffe/
也許有人會覺得比較複雜。確實,對於一個使用慣了windows視窗操作的使用者來說,各種命令就要了人命,甚至會非常牴觸命令操作。沒有學過python,要自己去用python程式設計實現視覺化,也是非常頭痛的事情。幸好現在有了nvidia digits這款工具,這些問題都可以解決了。
nvidia為了賣出更多的顯示卡,對深度學習的偏愛真是亮瞎了狗眼。除了cudnn, 又出了digits,真是希望小學生也能學會深度學習,然後去買他們的卡。
nvidia digits是一款web應用工具,在網頁上對caffe進行圖形化操作和視覺化,用於caffe初學者來說,幫助非常大。
不過有點遺憾的是,據nvidia官方文件稱,digits最佳支援系統是ubuntu 14.04,其它的系統效果如何,就不得而知了。
一、安裝digits 3.0
digits是執行在cuda和caffe基礎上的,所以要先配置好cuda+caffe那是毫無疑問的了。還不會配置的,請參考:Caffe學習系列(1):安裝配置ubuntu14.04+cuda7.5+caffe+cudnn
開啟一個終端,依次執行下列命令:
cd
sudo -s
進入當前使用者根目錄,並切換到超級使用者(符號由$變成#,不用每句都輸sudo)
CUDA_REPO_PKG=cuda-repo-ubuntu1404_7.5-18_amd64.deb &&
wget http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1404/x86_64/$CUDA_REPO_PKG &&
sudo dpkg -i $CUDA_REPO_PKG
接著,
ML_REPO_PKG=nvidia-machine-learning-repo_4.0-2_amd64.deb &&
wget http://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1404/x86_64/$ML_REPO_PKG &&
sudo dpkg -i $ML_REPO_PKG
apt-get update
apt-get install digits
ok,保持網路通暢,慢慢安裝吧!
二、執行digits
預設情況下,digits的安裝目錄為 /usr/share/digits
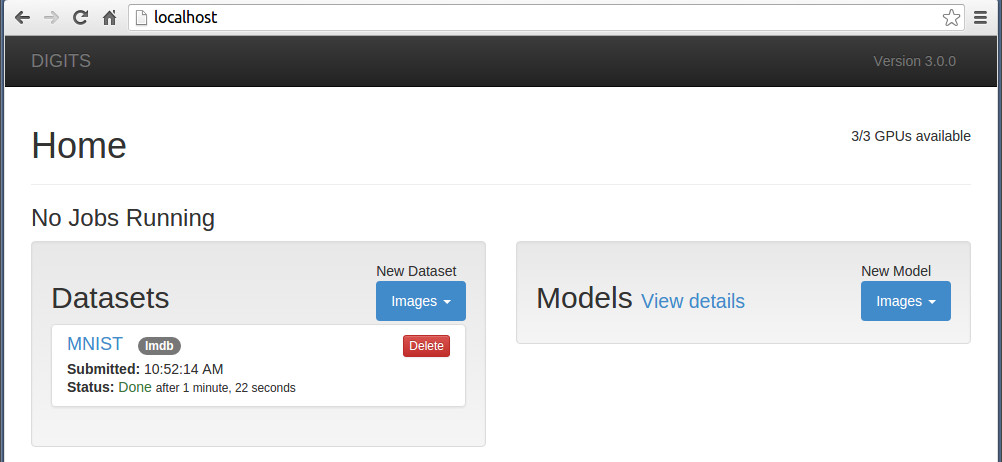
安裝完成後,開啟瀏覽器,位址列輸入 http://localhost/ 就可以了,就是這麼簡單。
更強悍的是:在局域內的其它機子上,也可以用瀏覽器訪問,只是localhost變成了主機 ip地址。很多人喜歡在windows系統上遠端連線linux來執行caffe。現在好了,不需要遠端連線了,只需要訪問一個網站就可以了。。。還有誰!!!!
三、執行mnist例項
現在來執行一個例項:mnist(名符其實的helloworld)
原始資料需要的是圖片,但網上提供的mnist資料並不是圖片格式的資料,因此我們需要將它轉換成圖片才能執行。
digits提供了一個指令碼檔案,用於下載mnist, cifar10 和cifar100 三類資料,並轉換成png格式圖片。檔案路徑為:
/usr/share/digits/tools/download_data/main.py
我們先在當前使用者的根目錄下,新建一個mnist資料夾用來儲存mnist圖片。
# cd
# mkdir mnist
然後執行指令碼
# /usr/share/digits/tools/download_data/main.py mnist ~/mnist
main.py帶兩個引數,第一個為資料集名稱(可設定為mnist, cifar10或cifar100),第二個為輸出路徑(~/mnist)
執行成功後,會在mnist資料夾下,生成兩個資料夾(train資料夾和test資料夾),每個資料夾下面就是我們需要的圖片(10類分別放在10個子資料夾內),同時還生成了對應在圖片列表檔案train.txt和test.txt

接下來,在瀏覽器上執行digits, 點選左邊Dataset模組的"Image"按鈕選擇“classification", 建立一個dataset
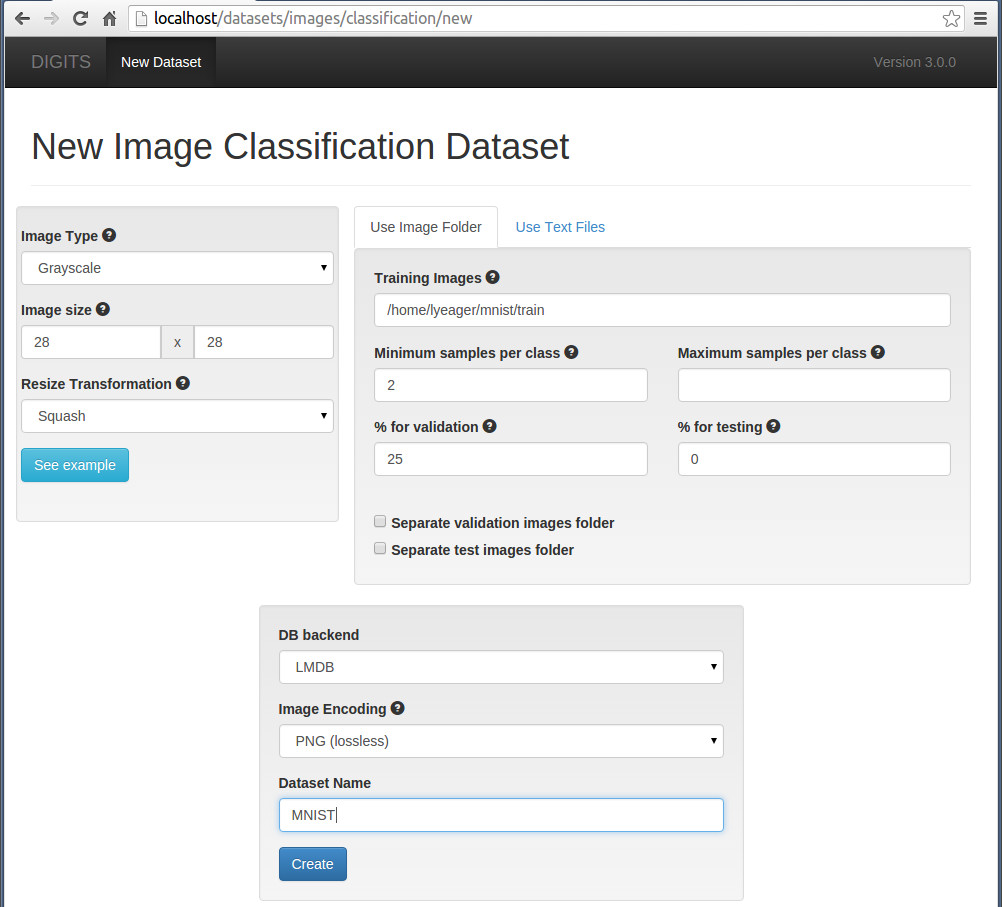
在這個頁面的左邊,可以設定圖片是彩色圖片還是灰度圖片,如果提供的原始圖片大小不一致,還可用Resize Transformation功能轉換成一致大小 。從頁面中間可以看出,系統預設將訓練圖片中的25%取出來作為驗證集(for validation)。
如果想把用來測試的圖片,也生成lmdb, 則把“ separate test image folder" 這個選項選上。
全部設定好後,點選"create" 按鈕,開始生成lmdb資料。
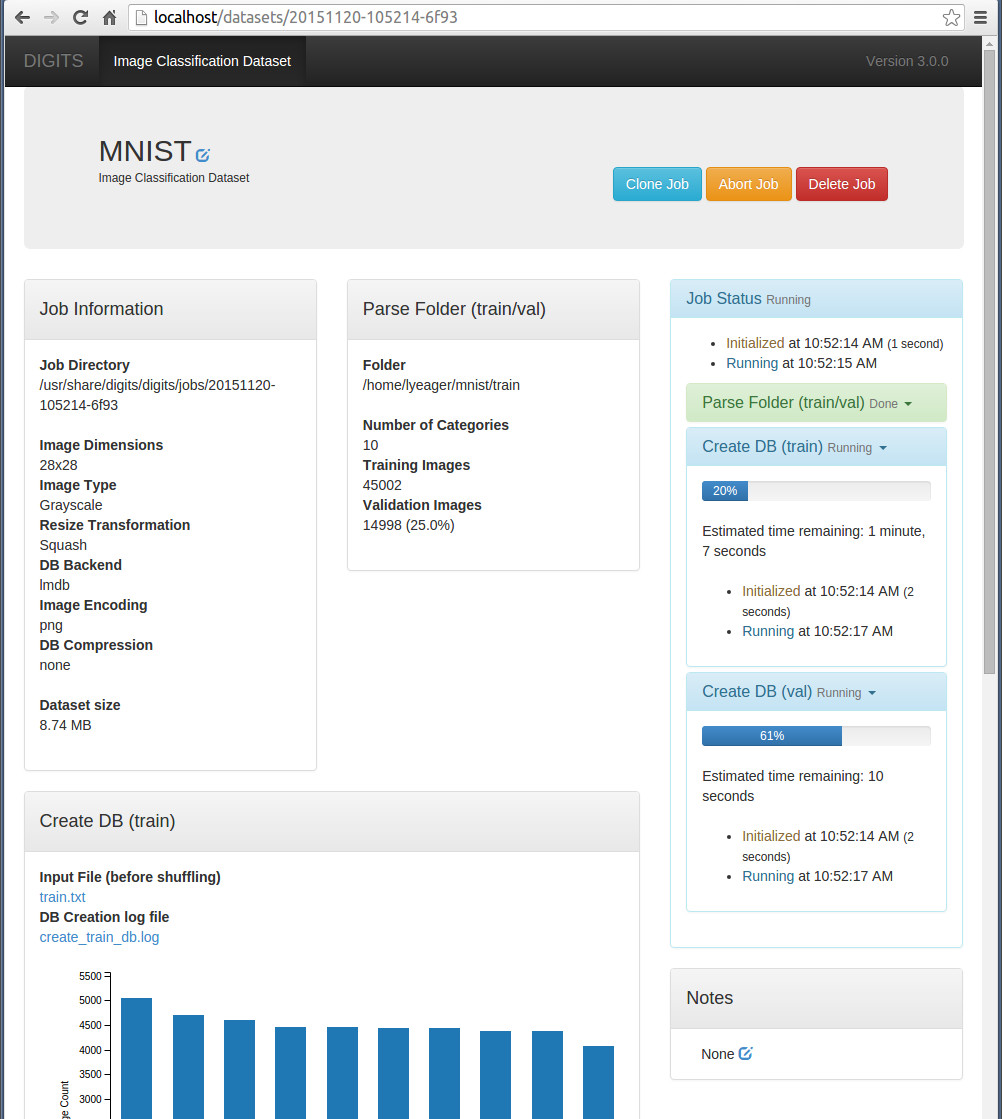
注意左上角的Job Directory(工作目錄),生成的lmdb檔案就放在這個目錄下面,大家最好開啟這個目錄去看看,看一下生成了些什麼檔案,瞭解一下執行原理。
在這個介面,我們還可以視覺化檢視訓練和測試的圖片,如下圖:
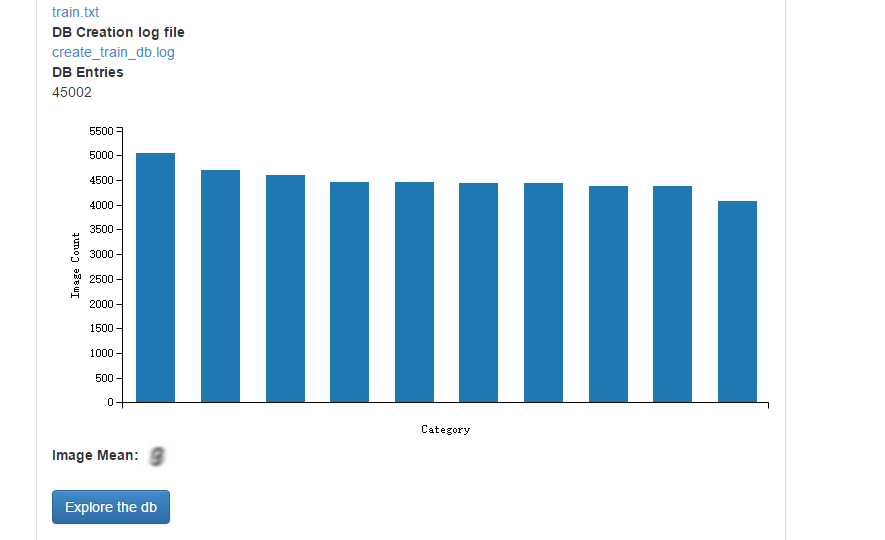
train.txt裡面存放的是所有訓練圖片的列表清單,柱狀圖清晰地顯示了10類樣本各自的數量。點選" Explorer the db” 即可檢視圖片。
最後,點選最左上角“ DIGITS" 連結回到網站根目錄。
由於圖片太多,因此本文很長,所以在此截斷一下,後續。。
相關文章
- caffe安裝系列——安裝OpenCVOpenCV
- 《深度學習:21天實戰Caffe》深度學習
- caffe學習(1)caffe模型三種結構模型
- 【caffe2從頭學】:2.學習caffe2
- Caffe:Layer的相關學習
- Caffe學習紀錄01
- Ubuntu 14 Caffe安裝(無GPU)UbuntuGPU
- Windows10 下caffe-Windows安裝與配置Windows
- Ubuntu 16.04 下安裝配置caffeUbuntu
- 執行caffe自帶的mnist例項教程
- Caffe 深度學習框架上手教程深度學習框架
- Caffe中的優化方法優化
- caffe層解讀系列——BatchNormBATORM
- caffe+SSD封裝封裝
- caffe整體框架的學習的部落格,這個部落格山寨了一個caffe框架框架
- 賈揚清分享_深度學習框架caffe深度學習框架
- 深度學習 Caffe 初始化流程理解(資料流建立)深度學習
- 深度學習 Caffe 初始化流程理解(資料流建立)深度學習
- 安裝Nmap圖形化前端工具Zenmap前端
- Caffe + Ubuntu 15.04 + CUDA 7.0 安裝以及配置Ubuntu
- window7下caffe安裝與mnist資料集測試
- 深度學習 Caffe 記憶體管理機制理解深度學習記憶體
- 深度學習---之caffe如何加入Leaky_relu層深度學習
- Caffe轉mxnet模型——mxnet工具模型
- 圖形化安裝OracleOracle
- 【Caffe篇】--Caffe solver層從初始到應用
- caffe之提取任意層特徵並進行視覺化特徵視覺化
- 在Centos7上安裝圖形化桌面工具CentOS
- MongoDB圖形化工具的使用與java操作MongoDBJava
- (14)caffe總結之Linux下Caffe如何除錯Linux除錯
- opencv呼叫caffe模型OpenCV模型
- caffe make 編譯編譯
- MySQL學習(二)圖形介面管理工具Navicat for MySQL安裝和使用MySql
- 【Caffe篇】--Caffe從入門到初始及各層介紹
- Caffe Windows版本的編譯Windows編譯
- 安裝配置 Ubuntu 14.04 + CUDA8.0 + cuDNN v5 + caffeUbuntuDNN
- TensorFlow和Caffe、MXNet、Keras等深度學習框架的對比Keras深度學習框架
- 賈揚清:希望Caffe成為深度學習領域的Hadoop深度學習Hadoop