筆記:Deep multi patch aggregation network for image style, aesthetics and quality estimation
在Image style, aesthetics and quality estimation三類任務中往往需要依靠更多的高畫素(high resolution)圖片中的細紋理(fine-grained)資訊。通常CNN網路的輸入是256*256*3的尺寸,通常的做法是,通常的做法是將一個高畫素(比如1024*768)圖片隨機裁剪為一個patch,用這個patch表示整幅影像,這樣會丟失掉其餘部分的細紋理資訊。本文用一個patch集合(multi patch)來表示整個圖片。基於multiple patch,文章提出了一種特徵學習以及聚集(aggregation)不同patch特徵的框架。具體而言,首先在一個圖片上提取多個patch,然後為每個patch做特徵提取,將各個patch的特徵進行聚集,從而得到用於分類的特徵。在這個框架上,本文提出了兩種用於特徵聚集的方法,分別是statistics aggregation structure和fully-connected sorting aggregation。整個框架本文用下圖表示:
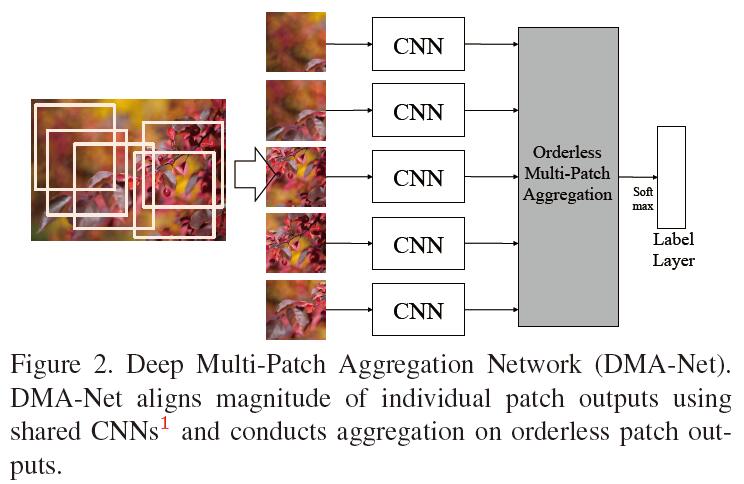
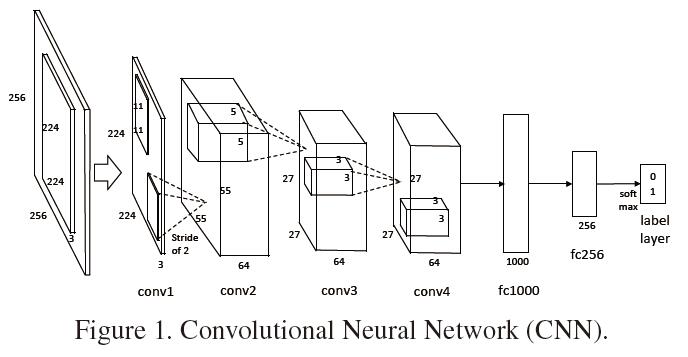
這裡的CNN表示下面結構中從input layer到fc256.(沒有softmax層)
詳細的步驟如下:
1) 對影像選擇patch,構成patch集;訓練階段隨機每個影像隨機選取5個patch,測試階段沒個圖片隨機選取250個patch,每5個構成一個patches集合,作為第(2)步的輸入,每個影像共50個集合,最後取50個集合的平均值作為結果。
2) 對patch集中的每個patch單獨進行特徵提取:方法是將每個patch用CNN提取特徵。在訓練階段,首先用任意一個patch訓練一個CNN,然後將所有CNN初始化為該值,然後用對應的patch對各個CNN進行單獨訓練。在將CNN特徵傳去到aggregation層的時候,為了保持它們之間的可比性,將各個CNN columns上的權重設為相同。
3) 然後將patch的特徵進行aggregation。本文講了兩種策略,每個patch的特徵為K,每個影像用M個patch表示,分別是:
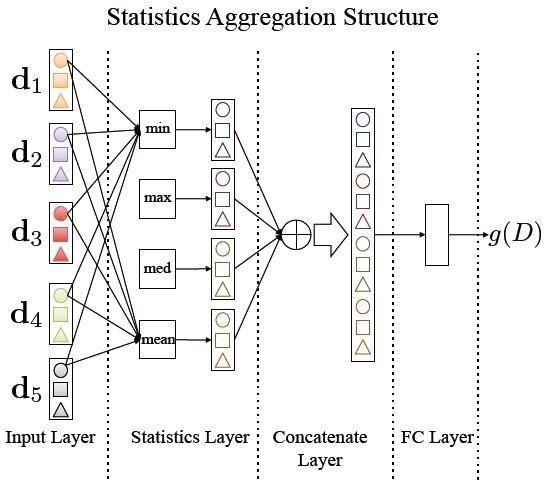
a) the statistics aggregation structure:這個結構保留每個patches特徵上的統計特徵,文章提到的包括max, min, median and mean. 聚集的過程為:分別計算multi patch上對應維度上的每個統計特徵,將每維相同的統計特徵串聯起來得到M維向量,然後將U個統計特徵分別得到的M維特徵向量串聯,得到U*K的向量(假設考慮U個統計特徵),這個向量被傳到一個全連結層,生成特徵向量g(D)。整個流程在文中如下圖表示:(K=3,U=4)
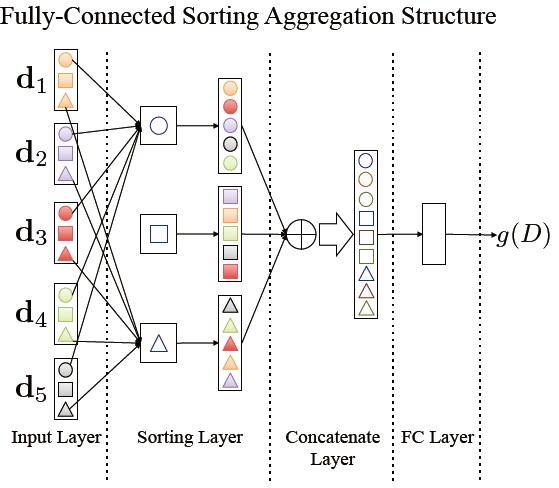
b) the fully-connected sorting aggregation:這個將上面的statistics layer替換為sorting layer,文章提到的sorting 方式為按值遞增排序。首先提取每個patch的特徵,然後將不同patch對應維度上的進行排序,每個維度上形成一個排序後的M維特徵向量,將K個維度上的M維特徵向量串聯得到K*M維特徵。這個結果在全連線層後得到特徵向量g(D)。流程在文中如下表示
4)最後根據全連線層輸出的特徵分類用的CNN上的soft-max層。
相關文章
- [論文閱讀筆記] Structural Deep Network Embedding筆記Struct
- Deep Unfolding Network for Image Super-Resolution 論文解讀
- 論文筆記 Deep Patch Learning for Weakly Supervised Object Classication and Discovery筆記Object
- 論文筆記 SimpleNet A Simple Network for Image Anomaly Detection and Localization筆記
- Spatio-Temporal Representation With Deep Neural Recurrent Network in MIMO CSI Feedback閱讀筆記筆記
- list-style-image屬性用法
- Deep Upsupervised Cardinality Estimation 解讀(2019 VLDB)
- 《Docker Deep Dive》閱讀筆記(一)Docker筆記
- Oracle安裝Patch相關筆記Oracle筆記
- Deep Hashing Network for Efficient Similarity RetrievalMILA
- Paxos 學習筆記2 - Multi-Paxos筆記
- Deep Robust Multi-Robot Re-localisation in Natural Environments
- 「Deep & Cross Network for Ad Click Predictions」- 論文摘要ROS
- Fauce:Fast and Accurate Deep Ensembles with Uncertainty for Cardinality Estimation 論文解讀(VLDB 2021)ASTAI
- Deep Transfer Learning綜述閱讀筆記筆記
- 論文解讀SDCN《Structural Deep Clustering Network》Struct
- 論文解讀(SDNE)《Structural Deep Network Embedding》Struct
- 論文解讀(DFCN)《Deep Fusion Clustering Network》
- Multi-Patch Prediction Adapting LLMs for Time Series Representation LearningAPT
- 深度學習 DEEP LEARNING 學習筆記(一)深度學習筆記
- 深度學習 DEEP LEARNING 學習筆記(二)深度學習筆記
- 【論文筆記】A Survey on Deep Learning for Named Entity Recognition筆記
- 「Deep Interest Network for Click-Through Rate Prediction」- 論文摘要REST
- 十一:引數binlog_row_image(筆記)筆記
- flutter隨筆- Text and StyleFlutter
- 01神經網路和深度學習-Deep Neural Network for Image Classification: Application-第四周程式設計作業2神經網路深度學習APP程式設計
- Deep Learning(深度學習)學習筆記整理系列深度學習筆記
- 文章學習29“Crafting a Toolchain for Image Restoration by Deep Reinforcement Learning”RaftAIREST
- 計網學習筆記六 Network Layer Overview筆記View
- Docker 學習筆記(第二集:image)Docker筆記
- 學習筆記 ProgressBar三種style 水平兩種寫法筆記
- 筆記:Deep attributes from context aware regional neural codes筆記Context
- A Unified Deep Model of Learning from both Data and Queries for Cardinality Estimation 論文解讀(SIGMOD 2021)Nifi
- CTR預估專欄 | 一文搞懂阿里Deep Interest Network阿里REST
- 《Cascade R-CNN: Delving into High Quality Object Detection》論文筆記CNNObject筆記
- 學習筆記(十六):ArkUi-顯示圖片 (Image)筆記UI
- 強化學習-學習筆記9 | Multi-Step-TD-Target強化學習筆記
- 筆記:ML-LHY-17/18: Unsupervised Learning - Deep Generative Model筆記