筆記:harvesting discriminative meta objects with deep CNN features for scene classification
本文提出了一種基於CNN特徵,通過分析場景中的元目標(meta objects)進而進行場景分析的流程。這裡的假設就是一個場景的類別通常與場景中包含的物體有關,場景的物體就對應所說的meta object。要分析圖片中的物體就要進行分割,然後選擇有效的分割區域,再將這些區域構造整個圖的特徵用於分類。這個流程可以分為五個部分:在整個圖片上構造region proposal選取patch、對patch進行選取保留對應圖片中有效的meta object的patch、對保留的patch進行聚類分析、構造整個圖片的特徵、分類。文章用下圖表示:
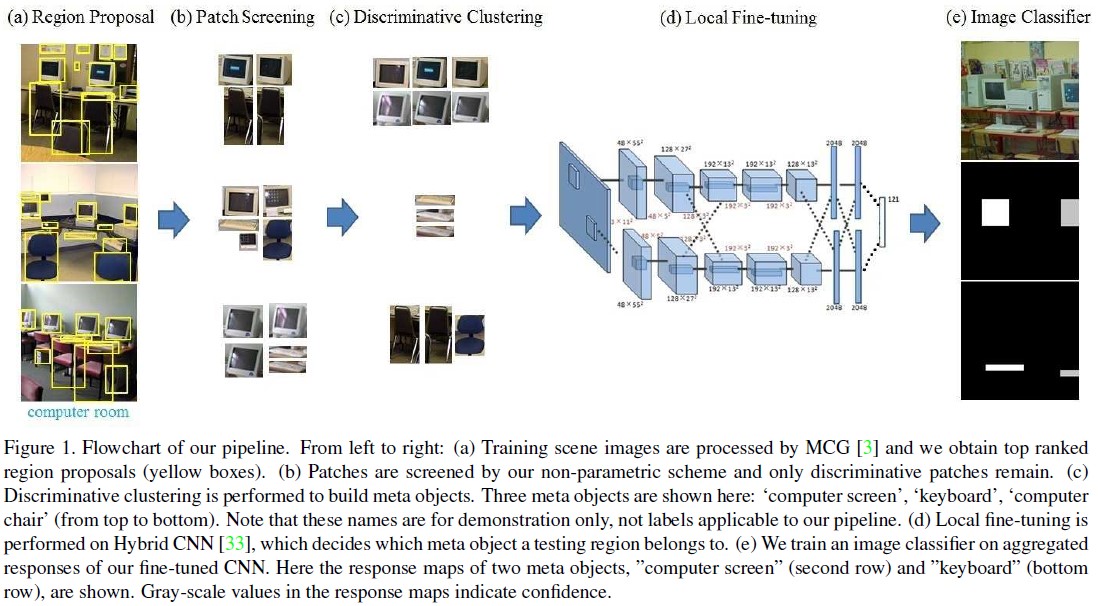
下面分別分析這五個部分。
1)region proposal generation
由於本文要分析scene image中的object,首先要提取恰當的proposal。
提取場景圖片中的region proposal,本文采用的是2014cvpr文章Arbeláez P, Pont-Tuset J, Barron J, et al. Multiscale combinatorial grouping[C]中提出的MCG方法。文章提到也可以用edge box和selective search 來生成proposal的方法。提取到proposal之後,用在Places資料集上預訓練的CNN模型來提取特徵。使用FC7層的特徵作為patches的特徵。
2)patch screening
為每類選擇具有代表性的patches,同時根據每個patch對scene image判別的幫助資訊(轉化為後驗概率)來給出一個權重,具體分為兩個部分:
(一)首先對每個類中所有影像提取的patches進行一個篩選,方法是無監督的學習一個one class SVM,使得出現頻率高的patches(representative patches)通過分類器得到正值,頻率低的(non -presentative)為負值;這一步採用了三層的瀑布模型(cascaded classifier),每一層篩掉輸入的15%。
(二)然後對上一步剩下的representative patches進行評分,這一步就是計算這個分數,分數高代表這個patch對整個影像的label的判定起的作用大。權重表示如下:
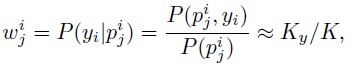
其中i是影像的索引,j是patch的索引,w(i,j)表示第i個影像中第j個patch的權重,p(i,j)代表第i影像中第j個patch,y(i)代表第i個影像樣本的label,可以看出它的計算最後轉化為後驗概率,即:在出現p(i,j)這個patch的影像中,label與第i幅影像相同所佔的比例。由於現在的patches並沒有標籤,也就沒有類別資訊,所以沒法判斷patches之間是否相同,最後這裡用了一個近似,尋找patches中K個最近鄰,其中包含這K個最近鄰且label為 的影像數目記為 ,將兩者的比值作為估計的權重。這裡沒有具體說判斷最近鄰的方法,也沒有找到程式碼,應該是用它們特徵的歐式距離做的。這個權重也是用來對patches進行篩選,策略就是直接刪掉一些權重低的patches,刪除的比例實驗中通過cross validation確定。實驗中並不是直接用這些patches,而是在這個基礎上採用了data augmentation擴充了4倍。
3)meta object creation and classification
在第二步選取了patches後開始分析每個patch的語義資訊,將patch的類別與scene image對應的類別建立聯絡。
首先需要對patches進行聚類,這是一個無監督的過程。文章採用的方法是2010年nips文章Krause A, Perona P, Gomes R G. Discriminative clustering by regularized information maximization[C]提出的RIM方法。聚類的結果,也就是聚類後的類別輸出就是本文的meta object。本文還分析了另外一種情況,如果不進行聚類操作,將每個保留的patch看成一個meta object,然後繼續下面的步驟,精度下降6%。聚類的作用可以看成是增加了這個類別裡面共性的重要性而忽略了一個類別中細微差別,相當於去掉了patch類中的細枝末節。
在聚類的基礎上,需要對未判定類別的patch進行分類還需要學習一個分類器,就是patch classification。文章採用對一個pre-trained CNN進行local fine tuning來構造分類器,同時將最後1000個輸出的層換成需要的輸出層。
4)image representation with Meta object
能夠將影像中的patches用分類器分到對應的meta objects, 如何通過meta objects來構造整個影像的特徵。文章提到了兩種pooling的方法:SPM和modified VLAD(vector of Locally Aggregated Descriptors).整個影像在Places CNN上的feature最後用了,權重係數通過交叉驗證選優。
影像還採用了multi-level的representation。這是為了方便檢測不同尺寸的meta object。方案是在1),2),3)中採用multi-level proposal分別提取,在最後訓練影像分類器之前將所有level得到的特徵串聯。
5)image classifier
分類器是一個包含兩個隱含層的神經網路,每個隱含層包括200個節點,啟用函式為rectified linear function。 輸入層包含的節點數對應特徵維數,輸出層節點數對應最終的類別數。
最後,除了與其他方法對比,文章通過對比實驗說明了框架中:local fine tuning、proposal extractors、outlier removal、clustering在實驗中的作用並進行了分析。
個人筆記,多多指教~
相關文章
- 《A Discriminative Feature Learning Approach for Deep Face Recognition》閱讀筆記APP筆記
- 語音學習筆記10------如何利用Deep CNN大幅提升識別準確率?筆記CNN
- PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation3DSegmentation
- 《Docker Deep Dive》閱讀筆記(一)Docker筆記
- 我的前端筆記之 meta 篇前端筆記
- Deep Transfer Learning綜述閱讀筆記筆記
- 深度學習 DEEP LEARNING 學習筆記(一)深度學習筆記
- 深度學習 DEEP LEARNING 學習筆記(二)深度學習筆記
- 【論文筆記】A Survey on Deep Learning for Named Entity Recognition筆記
- [論文解讀] DXSLAM: A Robust and Efficient Visual SLAM System with Deep FeaturesSLAM
- Deep Learning模型之:CNN卷積神經網路(三)CNN常見問題總結模型CNN卷積神經網路
- Deep learning:五十一(CNN的反向求導及練習)CNN求導
- Light Head R-CNN論文筆記CNN筆記
- CNN筆記:通俗理解卷積神經網路CNN筆記卷積神經網路
- [CS231N課程筆記] Lecture 2. Image Classification筆記
- [論文閱讀筆記] Structural Deep Network Embedding筆記Struct
- Deep Learning(深度學習)學習筆記整理系列深度學習筆記
- 遷移學習(JDDA) 《Joint domain alignment and discriminative feature learning for unsupervised deep domain adaptation》遷移學習AIAPT
- 筆記:Deep attributes from context aware regional neural codes筆記Context
- Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency MapsIDE
- 論文閱讀—第一篇《ImageNet Classification with Deep Convolutional Neural Networks》
- 軒田機器學習基石課程學習筆記11 — Linear Models for Classification機器學習筆記
- 論文筆記 Deep Patch Learning for Weakly Supervised Object Classication and Discovery筆記Object
- 筆記:ML-LHY-17/18: Unsupervised Learning - Deep Generative Model筆記
- Deep Learning(深度學習)學習筆記整理系列之(一)深度學習筆記
- 如何獲取objects的定義 - imp show=y 以及 impdp sqlfile=meta_sql.sqlObjectSQL
- 【面向程式碼】學習 Deep Learning(三)Convolution Neural Network(CNN)CNN
- 《End-to-End Adversarial Memory Network for Cross-domain Sentiment Classification》閱讀筆記ROSAI筆記
- 論文筆記(3)-Extracting and Composing Robust Features with Denoising Autoencoders筆記
- 林軒田機器學習技法課程學習筆記13 — Deep Learning機器學習筆記
- 筆記:Deep multi patch aggregation network for image style, aesthetics and quality estimation筆記
- 論文閱讀《Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising》CNN
- 【Stanford CNN課程筆記】4. 反向傳播演算法CNN筆記反向傳播演算法
- 深度殘差學習筆記:Deep Residual Networks with Dynamically Weighted Wavelet筆記
- Spatio-Temporal Representation With Deep Neural Recurrent Network in MIMO CSI Feedback閱讀筆記筆記
- 【深度學習】大牛的《深度學習》筆記,Deep Learning速成教程深度學習筆記
- 《Towards Good Practices for Very Deep Two-Stream ConvNets》閱讀筆記Go筆記
- 論文筆記之:Human-level control through deep reinforcement learning筆記