Facebook 的應用機器學習平臺
機器學習是Facebook許多重要產品和服務的核心技術。這篇論文來自Facebook的17位科學家和工程師,向世界介紹了Facebook應用機器學習的軟體及硬體架構。
\\本著“賦予人們建立社群的力量,使世界更緊密地聯絡在一起”的使命,到2017年12月,Facebook已經將全球超過二十億人連線在一起。同時,在過去幾年裡,機器學習在實際問題上的應用正在發生一場革命,這場革命的基石便是機器學習演算法創新、大量的模型訓練資料和高效能運算機體系結構進展的良性迴圈。在Facebook,機器學習提供了驅動幾乎全部使用者服務的關鍵動力,包括News Feed、語音和文字翻譯、照片和實時視訊分類等服務。
\\Facebook在這些服務中用到了各種各樣的機器學習演算法,包括支援向量機、梯度提升決策樹和多種的神經網路。Facebook的機器學習架構主要包括內部“機器學習作為服務”工作流、開源機器學習框架、以及分散式訓練演算法。從硬體角度看,Facebook利用了大量的CPU和GPU平臺來訓練模型,以支援必要的訓練頻率,以滿足服務的延遲需求。
\\關鍵摘要:
\\- 機器學習在幾乎所有的服務中都有應用,而計算機視覺只代表一小部分的資源需求。\\t
- Facebook採用多種機器學習方法,包括但不限於神經網路。\\t
- 大量的資料通過機器學習管道,這一點所帶來的工程效率的挑戰,遠遠不是計算節點可以解決的。\\t
- Facebook目前在很大程度上依賴於CPU進行測試階段的推斷,以及CPU和GPU進行訓練,但是也在不斷地從每瓦特效能的視角創造和評估新的硬體解決方案。\
Facebook的機器學習
\\機器學習一般包括兩個階段:
\\1)訓練階段:搭建模型,一般線上下(offline)進行。
\2)推斷階段:在生產中執行訓練好的模型,並且進行一系列的實時預測,該階段線上上(online)進行。
Facebook機器學習的一個顯著特點是大量的資料對模型的訓練有潛在的影響。這些資料的規模在整個架構的跨度上有許多意義。
\\A.主要機器學習應用服務
\\News Feed(Facebook資訊流服務)排序演算法可以讓人們在每次訪問Facebook時第一眼看到與他們最相關的故事。首先訓練一般模型,以選擇最終用來確定內容排序的各種使用者和環境因素。然後,當一個人訪問Facebook時,該模型會從成百上千的候選中生成一組個性化的最佳狀態、圖片以及其他內容來顯示,以及所選內容的最佳排序。
\\Ads利用機器學習來決定對某一使用者應顯示哪些廣告。Ads模型被訓練來學習如何通過使用者特徵、使用者環境、先前的互動以及廣告屬性來更好地預測點選廣告、訪問網站或購買產品的可能性。
\\Search服務針對各個垂直行業推出了一系列不同的、特定的子搜尋,如視訊、照片、人、事件等。分類層執行在各種垂直搜尋頂部,來預測要搜尋的是哪個方面。
\\Sigma是整體分類和異常檢測框架,用於許多內部應用,包括站點完整性、垃圾郵件檢測、付款、註冊、未經授權的員工訪問和事件推薦。
\\Lumos從影像和內容中提取高階屬性和對映關係,使演算法自動理解它。
\\Facer是Facebook的人臉檢測和識別框架。對於給定影像,它首先找出影像中的所有人臉。然後,執行鍼對特定使用者的面部識別演算法,來確定圖中的人臉是你的好友的可能性。Facebook通過這個服務幫助你選擇想在照片中標記的好友。
\\Language Translation是管理Facebook內容國際化的服務。該系統支援超過45種語言、2000種翻譯方向,每天幫助6億人打破語言障礙,讓他們能夠看到翻譯版本的News Feed。
\\Speech Recognition將音訊轉換成文字,主要應用於為視訊自動填補字幕。
\\B. 機器學習模型
\\Facebook使用的機器學習模型包括邏輯迴歸(Logistic Regression,LR)、支援向量機(Support Vector Machine,SVM)、梯度提升決策樹(Gradient Boosted Decision
\Tree,GBDT),以及深度神經網路(Deep Neural Network,DNN)。LR和SVM用於訓練和預測的效率很高。GBDT使用額外的計算資源可以提高準確性。DNN是最具表現力的模型,有能力達到最高的準確性,但是它利用的資源最多(計算量至少超過像LR和SVM這樣的線性模型一個數量級)。
在DNN中,主要使用的網路型別有三種:多層感知器(Multi-Layer Perceptrons,MLP)一般用於結構化的輸入特徵(如排序),卷積神經網路(Convolutional Neural Networks,CNN)作為空間處理器(如影像處理),以及迴圈神經網路(RNN、LSTM)主要用於序列處理器(如語言處理)。
\\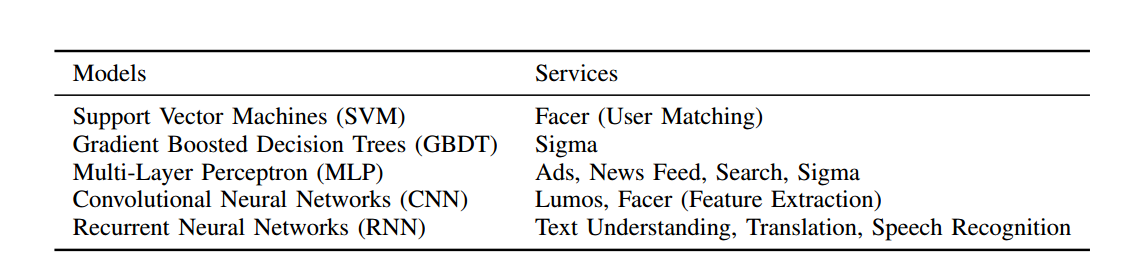
Facebook產品或服務使用的機器學習演算法。
\\C.Facebook內部“機器學習作為服務”
\\Facebook有幾個內部平臺和工具包,目的是簡化在Facebook產品中利用機器學習的任務。例如FBLearner、Caffe2和PyTorch。FBLearner包含三個工具,每一個都重點負責機器學習管道的不同部分。FBLearner利用內部作業排程程式在GPU和CPU的共享池分配資源、安排工作。Facebook大多數的機器學習訓練通過FBLearner平臺完成。這些工具和平臺協同工作的目的是提高機器學習工程師的生產力,並幫助他們專注於演算法的創新。
\\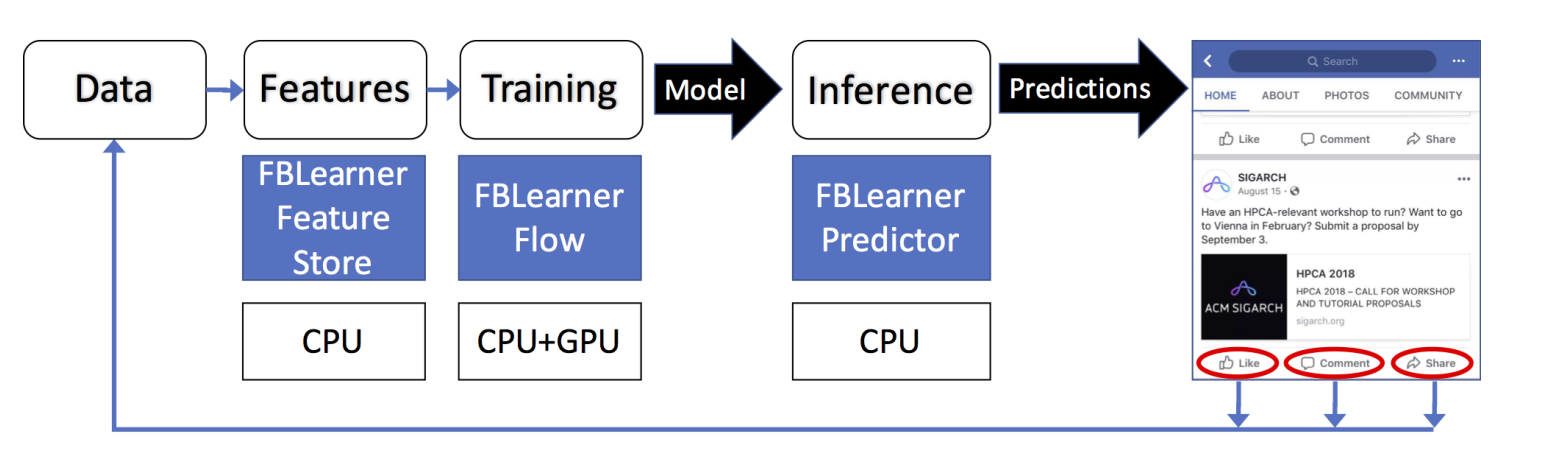
Facebook機器學習流和架構。
\\FBLearner Feature Store(特徵倉庫)。許多機器學習建模任務的出發點是聚集和生成特徵。特徵倉庫本質上是一個可以用於訓練和實時預測的多個特徵生成器的目錄,並且也可以將它看做一個市場,多個團隊可以在這裡共享並發現特徵。
\\FBLearner Flow是Facebook用於模型訓練的機器學習平臺。Flow是一個通道管理系統,執行workflow(工作流),其中描述了訓練或評測模型的步驟,以及所需資源。workflow是由離散的單元構成的,稱作操作器(operater),每個operator都有輸入和輸出。Flow也含有實驗管理的工具以及一個簡單的使用者介面,來跟蹤每個workflow執行或實驗中生成的所有工件和資料。
\\FBLearner Predictor(預測器)是Facebook內部的推理引擎,採用Flow中訓練的模型提供實時的預測。
\\D. 深度學習框架
\\Facebook使用兩種完全不同、但協同工作的深度學習框架:PyTorch,主要用於優化研究環境,和Caffe2,用於優化生產環境。
\\Caffe2是Facebook的內部訓練和部署大規模機器學習模型的框架。Caffe2關注產品要求的幾個關鍵的特徵:效能、跨平臺支援,以及基本的機器學習演算法。Caffe2的設計使用的是模組化的方法,所有的後端實現(CPU,GPU,和加速器)共享一個統一的圖表示。單獨的執行引擎滿足不同圖的執行需求,並且Caffe2加入了第三方庫(例如,cuDNN、MKL,和Metal),以在不同的平臺上優化執行。
\\PyTorch是Facebook人工智慧研究所用的框架。它的前端注重靈活性、除錯以及動態神經網路,能夠快速進行實驗。由於它依賴Python,所以它沒有針對生產和移動部署而優化。當研究專案產生了有價值的結果時,模型需要轉移到生產中。傳統方法是通過在產品環境中用其他框架來重寫訓練流程來實現轉移。最近Facebook開始搭建ONNX工具來簡化這一轉移過程。
\\ONNX,該深度學習工具系統在整個行業中仍處於初期階段。由於不同的框架(Caffe2和PyTorch)針對不同的問題有各自的優點,因此在不同的框架或平臺之間交換訓練好的模型是目前的一大生產需求。在2017年底,Facebook與其他相關團隊合作推出ONNX(Open Neural Network Exchange,開源神經網路交換),是一種以標準方式表示深度學習模型的格式,以便在不同的框架和供應商優化庫之間實現互操作。Facebook內部使用ONNX作為將PyTorch環境下的研究模型轉移到高效能生產環境Caffe2中的首要方法。
\\機器學習的資源解讀
\\A.Facebook硬體資源總結
\\Facebook的架構有著悠久的歷史,為主要的軟體服務提供高效的平臺,包括自定義的伺服器、儲存和網路支援,以滿足每個主要工作的資源需求。Facebook目前支援8個主要的計算和儲存框架,對應8個主要服務。
\\
2U Chassis,具有三個計算插槽,支援兩種可供選擇的伺服器型別。一個是單插槽CPU伺服器(1xCPU),包含4個Monolake伺服器子卡,另一個是雙插槽CPU伺服器(2xCPU)。
\\為了加速更大以及更深神經網路的訓練過程,Facebook打造了Big Basin,最新一代GPU伺服器。
\\
最初的Big Basin GPU伺服器包含8塊NVIDIA Tesla P100 GPU加速器。
\\與之前的Big Sur GPU伺服器相比,Big Basin平臺在每瓦特效能上有了極大的提高,受益於單精度浮點運算從7 teraflops到15.7 teraflops的提高,以及900GB/s的頻寬。
\\B. 訓練階段資源配置
\\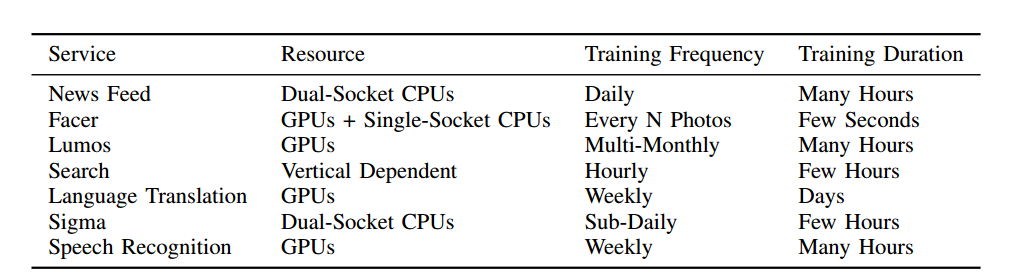
不同服務的機器學習訓練平臺、頻率、持續時間。
\\計算型別和位置
\\- 在GPU進行訓練:Lumos, Speech Recognition、Language Translation。\\t
- 在CPU進行訓練:News Feed、Sigma。\\t
- 在CPU和GPU上進行訓練:Facer(整體模型在GPU上每隔幾年進行訓練,因為該模型比較穩定,使用者特定模型在1xCPU進行訓練)、Search(利用多個獨立的垂直搜尋,並將預測分類器應用在最合適的領域)。\
訓練過程大量利用生產儲存的資料,出於效能和頻寬的原因,生產環境中GPU需要佈局在資料獲取的附近。每個模型利用的資料都在快速增加,所以靠近資料來源的位置隨時間而變得越來越重要。
\\記憶體、儲存,以及網路
\\從記憶體容量的角度來看,CPU平臺和GPU平臺都提供了足夠的訓練空間。例如Facer,在32GB RAM的1xCPU上訓練使用者特定的SVM模型。Facebook的機器學習會用到大部分儲存資料,這也為資料儲存附近的計算資源的放置建立了區域性偏好。隨著時間的推移,大多數服務顯示出利用更多使用者資料的趨勢,因此這將增加對其他Facebook服務的依賴性,同時也增加了資料訪問的網路頻寬。
\\規模考慮與分散式訓練
\\訓練神經網路需要用隨機梯度下降演算法來優化引數權重,通過對資料分批(batch、mini-batch)評估的迭代權重更新來完成。傳統的模型在一個機器上完成訓練,訓練效能可以通過增加模型、資料並行達到最優。但是考慮到訓練所需資料會隨時間而增長,硬體限制會增加整體的訓練延遲和收斂時間,甚至到無法接受的地步。為了克服這些硬體帶來的侷限性,分散式訓練是一個解決方案,也是目前AI領域很活躍的研究方向之一。
\\一個常見的假設是,跨機器的資料並行需要一個專門的連線。然而,在關於分散式訓練的工作中,研究人員發現基於乙太網的網路就足夠提供近似線性的擴充套件能力。
\\C. 推斷階段的資源配置
\\訓練完成後,線上推斷步驟包括將模型載入到機器上,並用實時輸入執行該模型,以生成實時結果。
\\
線上推斷資源要求
\\這裡以Ads排序模型來介紹線上推斷模型的工作。Ads排序模型過濾掉成百上千的廣告,只在News Feed中顯示前1-5個。這是通過對越來越小的廣告子集進行逐漸複雜的排序計算過濾的結果。排序計算使用一個類MLP的模型,包含稀疏嵌入層,每一次過濾都在縮小廣告的範圍。稀疏嵌入層是記憶體密集型的,對於後面的過濾操作,引數會越來越多,它會從MLP過濾分離,在單獨的伺服器上執行。
\\從計算角度來說,大量的線上推斷執行在1xCPU(單插槽)或2xCPU(雙插槽)上,對於Facebook的服務,1xCPU比2xCPU更節能高效,因此要儘可能的將模型從2xCPU遷移到1xCPU上。
\\資料中心規模的機器學習
\\除了資源需求外,在資料中心規模部署機器學習時還有一些重要因素要考慮,包括重要資料的要求,以及在面對災難時的可靠性。
\\A.從資料到模型
\\對於Facebook的許多複雜機器學習應用,例如Ads和Feed Ranking,每一個訓練任務需要處理的資料量超過上百的百萬位元組(terabytes)。此外,複雜的預處理操作用於確保資料的清理和規範化,以便高效傳輸和學習。這就對儲存、網路和CPU提出了很高的資源要求。
\\Facebook採用將資料負載和訓練負載分開的方法來解決這一問題。將不同的負載分配給不同的機器:資料處理機器“reader”從儲存中讀取資料,處理並壓縮它們,隨後傳遞給訓練機器“trainer”,訓練機器只需要快速高效地執行訓練操作。
\\B. 使用規模
\\Facebook必須維護大量的伺服器,以在任何時間都可以處理峰值負載。
\\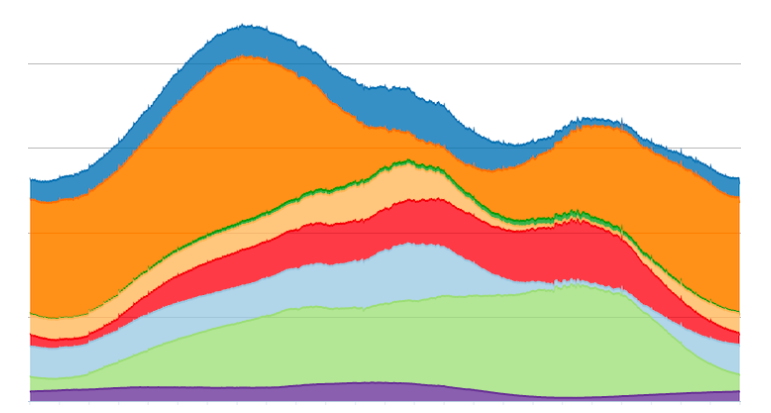
在特殊日期,由於使用者活動的變化,會導致日負荷高峰,大量的伺服器池往往在某些時間段內處於閒置狀態,這為非峰值時間提供了大量的計算資源。對於機器學習應用程式,這提供了一個充分利用分散式訓練機制的機會,這些機制可以擴充套件到大量的異質資源(例如不同的CPU和GPU平臺,具有不同的RAM分配)。例如,在1xCPU結構中,有四個主機共享一個50G的NIC,如果4個主機試圖同時與其他主機同步梯度,共享的NIC馬上就會變成瓶頸,導致丟失包以及響應超時。因此,需要在網路拓撲和排程器之間進行協同設計,以在非峰值時間有效地利用空閒的伺服器。
\\C. 災難發現
\\當Facebook全球計算、儲存和網路痕跡的一部分丟失時,能夠無縫地處理該問題一直是Facebook Infrastructure的長期目標。在內部,Facebook的災難恢復小組定期進行演練,以識別和補救全球架構和軟體堆疊中最薄弱的環節。破壞行動包括把整個資料中心離線而幾乎不被發覺,以確保Facebook的任何一個全球資料中心的丟失對業務造成最小的干擾。
\\如果不訓練模型會發生什麼?
\\作者分析了使用機器學習的三個關鍵服務,來說明如果在訓練過程中模型不能進行頻繁地更新所帶來的影響。
\\Community Integrity(社群完整性):Facebook的Community Integrity團隊充分利用機器學習技術來檢測文字、影像和視訊中的攻擊性內容。攻擊內容檢測是垃圾郵件檢測的一種特殊形式。對手會不斷尋找新的方法繞過Facebook的鑑別器,向使用者顯示不良內容。如果不能進行完全訓練,會導致無法抵禦這些不良內容。
\\News Feed:在使用者每次訪問Facebook時為每一個使用者識別最相關的內容,將顯著地依賴於最先進的機器學習演算法,以便正確地找到併為該內容排序。舊的News Feed模型對該服務會產生質的影響。即使是一週的訓練計算損失也會阻礙News Feed團隊探索新模型和新引數的能力。
\\Ads:該服務為人們尋找並展示最好的廣告,對機器學習有重要的依賴性。研究人員發現,利用過時的機器學習模型的影響是以小時衡量的。換句話說,使用一天前的模型比使用一小時前的模型影響更糟。
\\災難恢復的架構支援
\\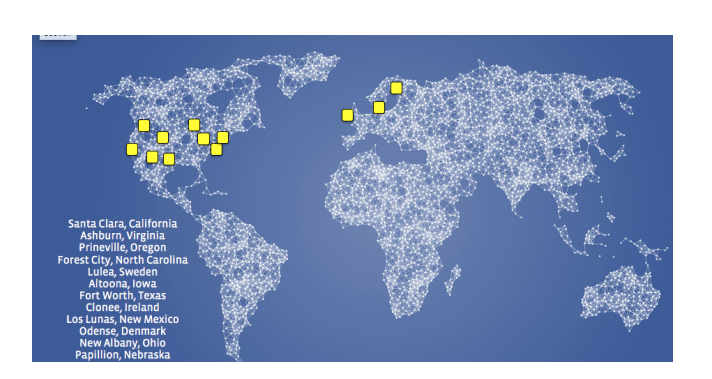
2017年12月Facebook全球資料中心位置。
\\隨著深度學習在多個產品中得到應用,GPU計算和大資料之間的佈局越來越重要。並且面向巨型區域儲存的戰略支點使計算-資料的共同佈局變得更加複雜。巨型區域的概念意味著少量的資料中心區域將容納大部分Facebook的資料。並且容納整個GPU機群的區域並不位於儲存的巨型區域內。
\因此,除了協同定位的重要性計算資料,很快就要考慮如果完全失去儲存GPU的區域可能發生什麼事情。這一考慮推動了多樣化GPU物理位置的需求。
未來方向:硬體、軟體及演算法的協同設計
\\增加計算強度通常會提高底層硬體的效率,所以在延遲允許的範圍下,用更大的batchsize進行訓練是可取的。計算範圍內的機器學習工作負載將受益於更寬的SIMD單元、專用卷積或矩陣乘法引擎,以及專門的協同處理器。
\\有些情況下,每個計算節點的小批次是固定要求,這通常會降低計算密集度。因此,當完整的模型不適用於固定的SRAM或最後一級快取時,可能會降低表現效能。這可以通過模型壓縮、量化和高頻寬儲存器來解決這一問題。
\\減少訓練時間和加快模型交付需要分散式訓練。分散式訓練需要細緻的網路拓撲和排程的協同設計,以有效地利用硬體達到良好的訓練速度和質量。分散式訓練中最常用的並行形式是資料並行,這就要求梯度下降在所有的節點上同步。
\\總結
\\在Facebook,研究人員發現了應用機器學習平臺的規模和驅動決策方面設計中出現的幾個關鍵因素:資料與計算機聯合佈局的重要性、處理各種機器工作負載的重要性,不僅僅是計算機視覺,以及來自日計算週期的空閒容量的機會。在設計端到端的解決方案時,研究人員考慮了每一個因素,這些解決方案包括定製設計的、現成的、開放原始碼的硬體,以及一個平衡效能和可用性的開源軟體生態系統。這些解決方案為服務了全球超過21億人的大規模機器學習工作提供了動力,反映了專家們在機器學習演算法和系統設計方面的跨學科努力。
\\論文原文:Applied Machine Learning at Facebook: A Datacenter Infrastructure Perspective
\\感謝蔡芳芳對本文的審校。
相關文章
- 揭秘FACEBOOK未來的機器學習平臺機器學習
- 揭祕FACEBOOK未來的機器學習平臺機器學習
- MediaPipe - 跨平臺機器學習應用開發框架API機器學習框架
- Endeavour的機器學習平臺機器學習
- 用PMML實現機器學習模型的跨平臺上線機器學習模型
- 16個用於資料科學和機器學習的頂級平臺資料科學機器學習
- tensorflow機器學習模型的跨平臺上線機器學習模型
- 史丹佛大學-機器學習的動機與應用機器學習
- 滴滴機器學習平臺架構演進機器學習架構
- 真正的機器學習平臺根本不存在?機器學習
- 吳恩達機器學習筆記 —— 11 應用機器學習的建議吳恩達機器學習筆記
- 【機器學習】--LDA初始和應用機器學習LDA
- Apache Hudi在Hopworks機器學習的應用Apache機器學習
- 滴滴機器學習平臺架構演進之路機器學習架構
- 機器學習在金融比賽中的應用機器學習
- 機器學習在SAP Cloud for Customer中的應用機器學習Cloud
- 【機器學習】--Adaboost從初始到應用機器學習
- 如何快速應用機器學習技術?機器學習
- AI開發平臺系列2:整合式機器學習平臺對比分析AI機器學習
- 網易雲音樂機器學習平臺實踐機器學習
- 使用pmml實現跨平臺部署機器學習模型機器學習模型
- 流批一體機器學習演算法平臺機器學習演算法
- MLFlow機器學習管理平臺入門教程一覽機器學習
- 【Numpy應用】--對於圖片處理的機器學習庫的應用機器學習
- 頭歌實踐教學平臺-機器學習 --- PCA-答案機器學習PCA
- 機器學習的技術原理、應用與挑戰機器學習
- 機器學習實戰 | SKLearn最全應用指南機器學習
- 在物聯網中應用機器學習機器學習
- 【機器學習篇】--SVD從初始到應用機器學習
- 【機器學習】--xgboost從初識到應用機器學習
- 從零開始學機器學習——網路應用機器學習
- Comet如何在GitLab DevOps平臺上簡化機器學習?Gitlabdev機器學習
- 機器學習應用面臨的一些問題機器學習
- 機器學習與移動應用開發的未來機器學習
- 機器學習在客戶管理場景中的應用機器學習
- 格物致知—機器學習應用效能調優機器學習
- 【機器學習】--譜聚類從初始到應用機器學習聚類
- 以太坊學習筆記————3、WEB:去中心化應用平臺筆記Web中心化
- vivo網際網路機器學習平臺的建設與實踐機器學習