理解並從頭搭建redis叢集
部分開發人員工作當中只是在應用中使用redis,比如用來做資料結果的快取。而且現在有很多不錯的redis客戶端工具(redisson),基本上可以不用關注redis命令就可以完成相當部分的功能。所以可能會對如下這些問題關注點不夠:
- 如何容災?即某個redis節點出了問題如何保證服務的高可用性
- 如何橫向擴容?當資料量特別大時,如何解決單個redis的效能問題
- 叢集至少需要幾臺機器?或者幾個redis節點
- 叢集搭建都利用什麼技術,哪些工具?
如何容災?
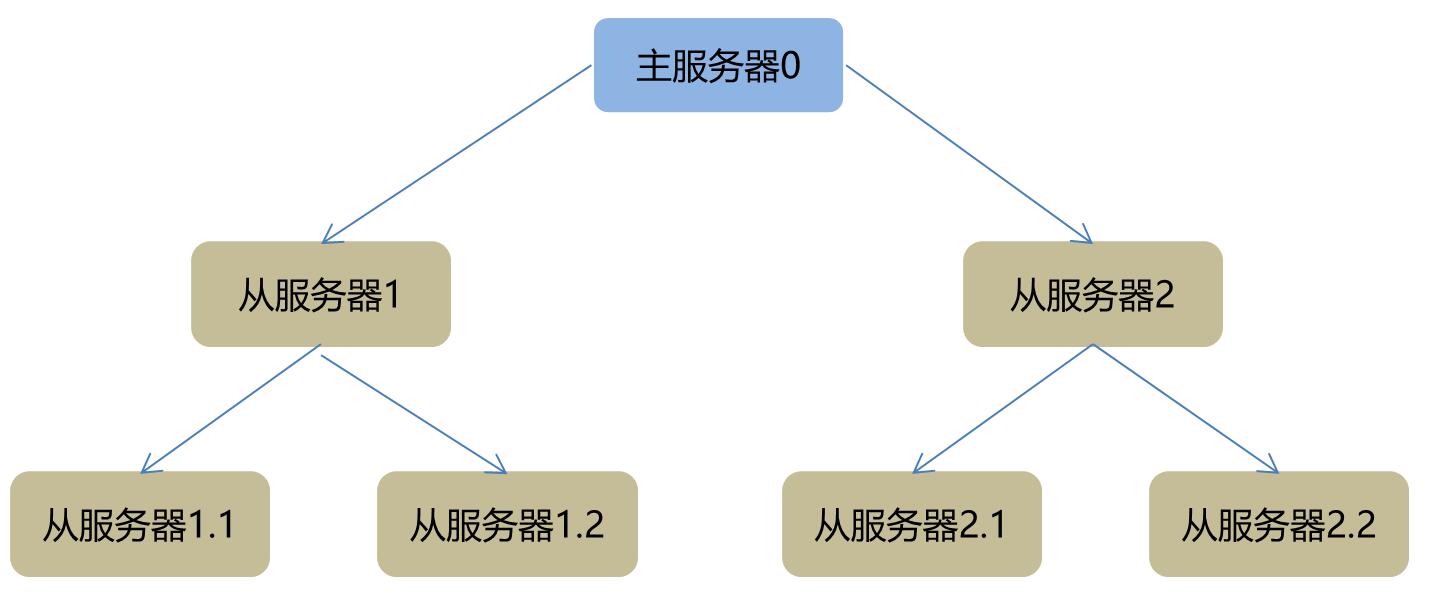
redis提供了主從熱備機制,主伺服器的資料同步到從伺服器,透過哨兵實時監控主伺服器狀態並負責選舉主伺服器。當發現主伺服器異常時根據一定的演算法重新選舉主伺服器並將問題伺服器從可用列表中去除,最後通知客戶端。主從是一對多的樹型結構,如下圖:
哨兵
哨兵是sentinel的中文名稱,是redis出的一個高可用架構的工具,自身是一個獨立的程式,可以同時監控一個以上的redis叢集。
哨兵叢集
基於高可用的考慮,哨兵自身也是需要支援叢集的,如果只有一個哨兵就會存在單點問題。
哨兵決策
哨兵有一個數量配置,當多少個哨兵同時認為某個主服務不可用時才進行主從切換,比如總共有5個哨兵,當3個哨兵認為服務不可用時才決定做主從切換。這麼做可以避免一些誤切換,降低切換成本,比如瞬時的網路異常等。
如何橫向擴容?
無論是redis還是其它一些資料庫之類的產品,當單節點的資料容量達到一定上限後,服務對外提供的能力會越來越弱。redis在高版本中提供了redis-trib.rb來實現叢集功能,也可以使用第三方的工具twemproxy。
去中心化,每個節點都是平等的
redis叢集從設計上沒有考慮中心化,這樣可以避免中心節點的單點等問題。每個節點都能掌握整個叢集的狀態,連線任意的節點都可以訪問到所有的key,就像單節點的redis一樣。
叢集原理圖
自己理解畫的,如有理解不對的地方可以指出。
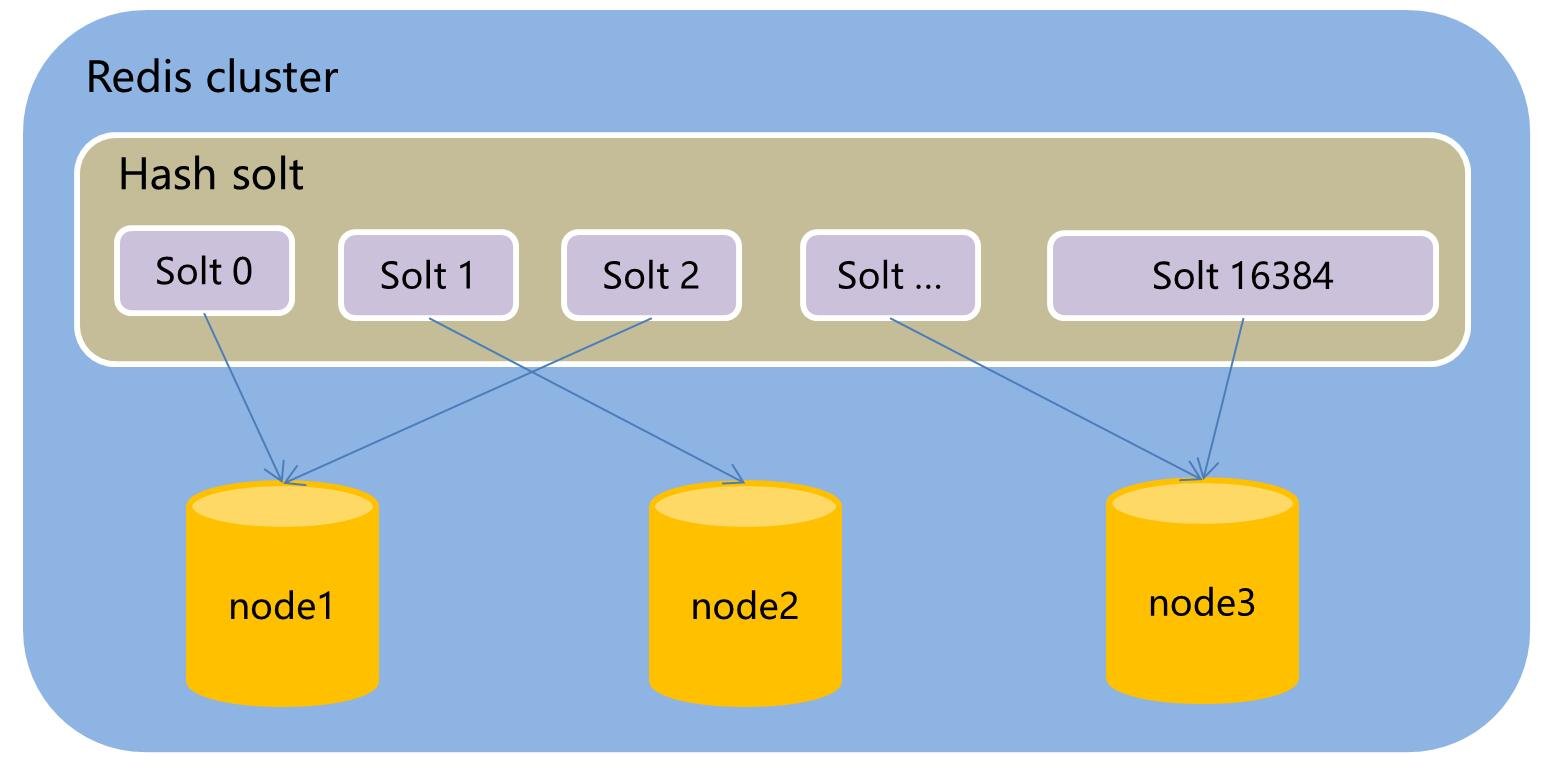
key與redis節點的關係
引入了hasy solt,中文理解為雜湊槽。總共16384個,我們操作的key透過取模演算法確認key落在哪個槽上。
HASH_SLOT = CRC16(key) mod 16384
雜湊槽與節點之間有一定關係,所以我們就可以將key分配到某個具體的redis節點上了。
詳細的關係可再研究,簡單的比如節點A負責0-5000編號的雜湊槽,節點B負責5001-1000
一步一步搭建
開始搭建三主三從的叢集,系統是ubuntu,採用redis提供的叢集工具redis-trib.rb。
- 安裝最新redis
- 建立redis_cluster目錄,並且建立7000到7005這6個目錄
- 將redis目錄下的redis.conf複製到上面建立的6個目錄中
- 分別修改redis.conf檔案,對6個檔案做類似的修改。
port 7000 //埠7000
bind 127.0.0.1 //預設ip為127.0.0.1 需要改為其他節點機器可訪問的ip
daemonize yes //後臺執行
pidfile /var/run/redis_7000.pid //pidfile檔案對應7000
cluster-enabled yes //開啟叢集
cluster-config-file nodes_7000.conf //叢集的配置
cluster-node-timeout 15000 //請求超時 預設15秒,可自行設定
bind需要注意的就是需要配置為其它機器可以訪問的ip,否則無論是建立叢集還是客戶端連線都會有問題。
- 啟動6個redis
redis-server redis_cluster/7000/redis.conf
redis-server redis_cluster/7001/redis.conf
redis-server redis_cluster/7002/redis.conf
redis-server redis_cluster/7003/redis.conf
redis-server redis_cluster/7004/redis.conf
redis-server redis_cluster/7005/redis.conf
- 建立叢集
redis的src目錄下有個redis-trib.rb,將它複製到/usr/local/bin中,然後執行如下指令碼:
redis-trib.rb create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005
--replicas後面的1代表從伺服器的個數,上面可以理解為前面3個為主伺服器,後面三個分別做為從伺服器,即三對主從。
執行過程中會遇到提示需要安裝ruby,安裝完成之後又會提示安裝 gem redis。
安裝gem redis,折騰了好久,最終發現是因為在國內訪問不了某些網站導致透過apt-get install安裝不成功,最後透過下載原始碼的方式安裝成功。
![]()
再次執行建立叢集的指令碼,出現如下提示:
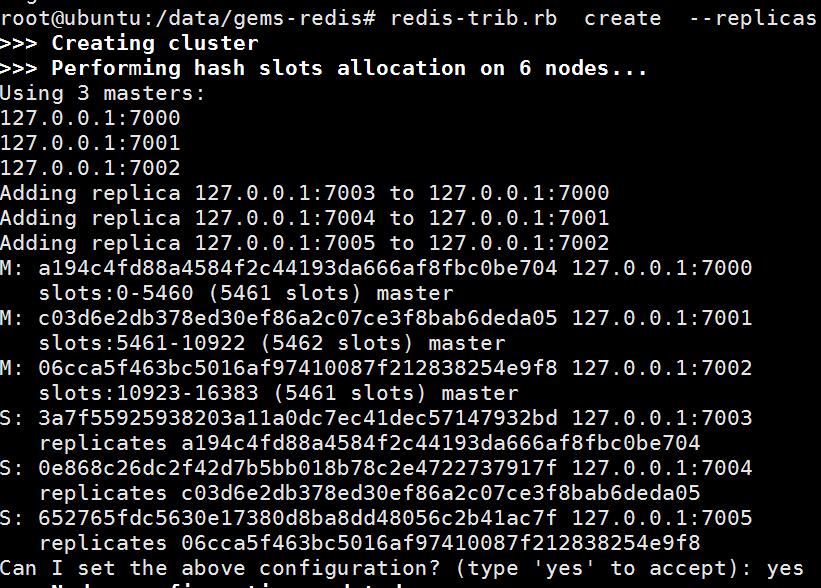
輸入yes,繼續
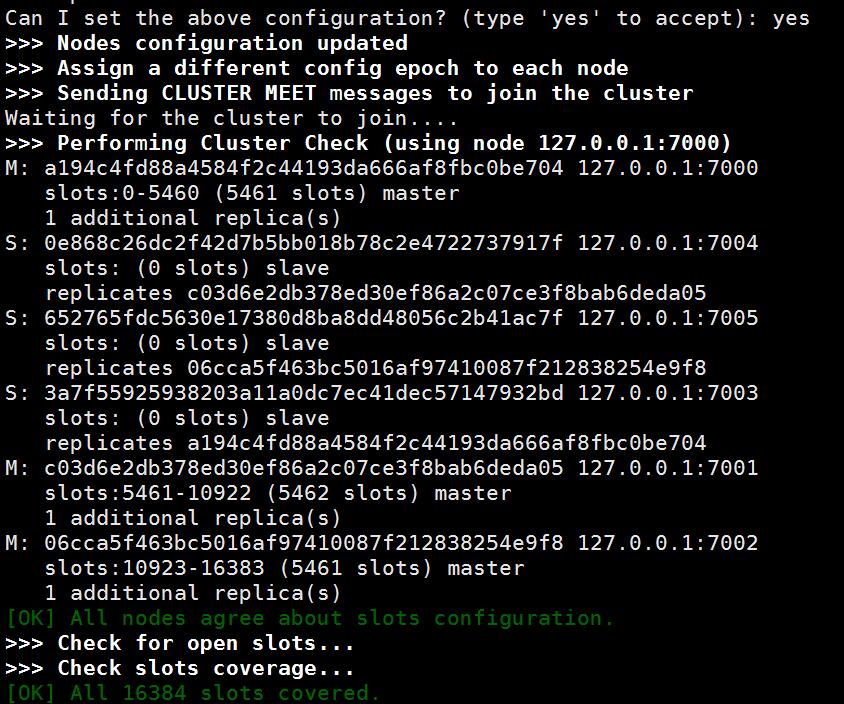
最少需要多少個主伺服器?
可能是基於某些約定,叢集約定只有當可用節點數大於半數以上時才具備對外提供服務的能力。首先數量一定是奇數,其實必須大於1,所以最少的主伺服器數量為3。
- 測試叢集
連線客戶端,由於我的所有節點都是在本地,所以不需要輸入ip,但需要加-c的引數。
redis-cli -c -p 7000
連線成功後,增加一個key
set mykey 123
有一行提示語,指向到埠7002,這說明雖然我們連線的是7000的例項,但透過hash演算法最終會將key分配到7002的例項上。

再連線7005埠查詢下key,測試下是否任意一個例項都可以查詢到key
get mykey
顯示指向到埠7002

叢集需要注意的地方
這塊還未仔細研究,有些命令在叢集下是不支援的,待後續求證。
引用
- http://www.cnblogs.com/wuxl360/p/5920330.html
- https://segmentfault.com/a/1190000002680804
- http://blog.csdn.net/lifeiaidajia/article/details/45370377
總結
真實環境的部署與單機部署還是差異比較大的,但也不復雜,儘管部分開發人員可能一輩子都不會有機會線上上搭建redis叢集,但瞭解redis的高可用可擴充套件的方案對設計大型系統還是有比較大的幫助的,也有助於分析解決線上問題。看了上面的這些,對於本文開頭提到的問題就不難理解了。