在list長度較少時候,我們可以直接的使用資料庫的翻頁功能,如
SELECT * FROM LIST_TABLE LIMIT offset, row_count;
根據經驗,在大部分場景下,單個業務的list資料長度99%在1000條以下,在資料規模較小時候,上面的方法非常適合。但剩下的1%的資料可能多達100萬條,在資料規模較大的時候,當訪問offset較大的資料,上述方法非常低效(可參看Why does MYSQL higher LIMIT offset slow the query down?),但在實現方案的時候不能忽視這些超大資料集的問題,因此要實現一個適合各種變長list的翻頁方案,考慮到資料的長尾問題,並沒有簡單高效的方案。這也體現了常說的80%+的時間在優化20%-的功能。
List資料訪問模型常見的有兩種方式
1. 扶梯方式
扶梯方式在導航上通常只提供上一頁/下一頁這兩種模式,部分產品甚至不提供上一頁功能,只提供一種“更多/more”的方式,也有下拉自動載入更多的方式,在技術上都可以歸納成扶梯方式。

(圖:blogspot的導航條)

(圖:很多瀑布流式的產品只提供一個more的導航條)
扶梯方式在技術實現上比較簡單及高效,根據當前頁最後一條的偏移往後獲取一頁即可,在MySQL可使用以下方法實現。
SELECT * FROM LIST_TABLE WHERE id > offset_id LIMIT n;
由於where條件中指定了位置,因此演算法複雜度是O(log n)
2. 電梯方式
另外一種資料獲取方式在產品上體現成精確的翻頁方式,如1,2,3……n,同時在導航上也可以由使用者輸入直達n頁。國內大部分產品經理對電梯方式有特殊的喜好,如圖

但電梯方式在技術實現上相對成本較高,當使用以下SQL時
SELECT * FROM LIST_TABLE LIMIT offset, row_count;
我們可以使用MySQL explain來分析,從下文可以看到,當offset=10000時候,實際上MySQL也掃描了10000行記錄。
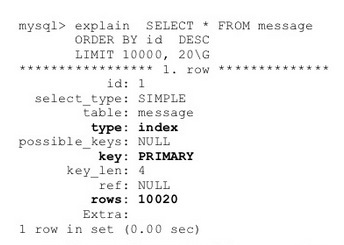
為什麼會這樣?在MySQL中,索引通常是b-tree方式(但儲存引擎如InnoDB實際是b+tree),如圖

從圖中可以看到,使用電梯方式時候,當使用者指定翻到第n頁時候,並沒有直接方法定址到該位置,而是需要從第一樓逐個count,scan到count*page時候,獲取資料才真正開始,所以導致效率不高。對應的演算法複雜度是O(n),n指offset,也就是page*count。
另外Offset並不能有效的快取,這是由於
1、在資料存在新增及刪除的情況下,只要有一條變化,原先的樓層可能會全部發生變化。在一個使用者併發訪問的場景,頻繁變化的場景比較常見。
2、電梯使用比較離散,可能一個20萬條的list,使用者使用了一次電梯直達100樓之後就走了,這樣即使快取100樓之下全部資料也不能得到有效利用。
以上描述的場景屬於單機版本,在資料規模較大時候,網際網路系統通常使用分庫的方式來儲存,實現方法更為複雜。
在面向使用者的產品中,資料分片通常會將同一使用者的資料存在相同的分割槽,以便更有效率的獲取當前使用者的資料。如下圖所示
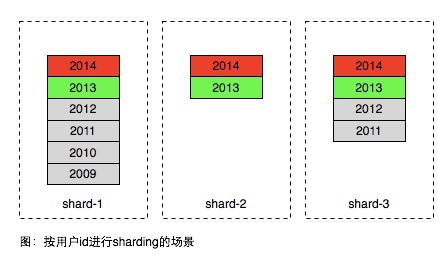
(圖:資料按使用者uid進行hash拆分)
圖中的不同年份的資料的格子是邏輯概念,實際上同一使用者的資料是儲存在一張表中。因此方案在常見的使用場景中存在很大不足,大部分產品使用者只訪問最近產生的資料,歷史的資料只有極小的概率被訪問到,因此同一個區域內部的資料訪問是非常不均勻,如圖中2014年生成的屬於熱資料,2012年以前的屬於冷資料,只有極低的概率被訪問到。但為了承擔紅色部分的訪問,資料庫通常需要高速昂貴的裝置如SSD,因此上面方案所有的資料都需要存在SSD裝置中,即使這些資料已經不被訪問。
簡單的解決方案是按時間遠近將資料進行進一步分割槽,如圖。
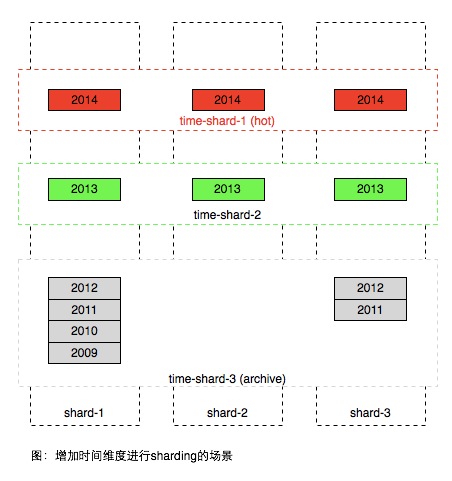
注意在上圖中使用時間方式sharding之後,在一個時間分割槽內,也需要用前一種方案將資料進行sharding,因為一個時間片區通常也無法用一臺伺服器容納。
上面的方案較好的解決了具體場景對於key list訪問效能及成本的平衡,但是它存在以下不足
- 資料按時間進行滾動無法全自動,需要較多人為介入或干預
- 資料時間維度需要根據訪問資料及模型進行精巧的設計,如果希望實現一個公用的key-list服務來儲存所有業務的資料,這個公用服務可能很難實現
- 為了實現電梯直達功能,需要增加額外的二級索引,比如2013年某使用者總共有多少條記錄
由於以上問題,尤其是二級索引的引入,顯然它不是理想中的key list實現,後文繼續介紹適合大資料翻頁key list設計的一些思路及嘗試。
來自:程式師
評論(2)