TensorFlow技術解析與實戰 4 基礎知識
4.1 系統架構
自底向上分為裝置層和網路層、資料操作層、圖計算層、API層、應用層。

4.2 設計理念
(1)將圖的定義和圖的執行完全分開。
程式設計模式通常分為指令式程式設計和符號式程式設計。指令式程式設計是編寫我們理解的通常意義上的程式,很容易理解和除錯,按照原有邏輯執行。符號式程式設計涉及很多的嵌入和優化,不容易理解和除錯,但執行速度相對有所提升。現有的深度學習框架中,Torch是典型的命令式的,Caffe、MXNet採用了兩種程式設計模式混合的方法,而TensorFlow完全採用符號式程式設計。
符號式計算一般是先定義各種變數,然後建立一個資料流圖,在資料流圖中規定各個變數之間的計算關係,最後需要對資料流圖進行編譯,但此時的資料流圖還是一個空殼兒,裡面沒有任何實際資料,只有把需要運算的輸入放進去後,才能在整個模型中形成資料流,從而形成輸出值。
import tensorflow as tf
t = tf.add(8, 9)
print(t) # 輸出 Tensor("Add _ 1:0", shape=(), dtype=int32)(2)TensorFlow中涉及的運算都要放在圖中,而圖的執行只發生在會話(session)中。開啟會話後,就可以用資料去填充節點,進行運算;關閉會話後,就不能進行計算了。因此,會話提供了操作執行和Tensor求值的環境。
import tensorflow as tf
#建立圖
a= tf.constant([1.0, 2.0])
b= tf.constant([3.0, 4.0])
c= a * b
# 建立會話
sess = tf.Session()
# 計算 c
print sess.run(c) # 進行矩陣乘法,輸出 [3., 8.]
sess.close()4.3 程式設計模型
TensorFlow是用資料流圖做計算的,先建立一個資料流圖(也稱為網路結構圖)
顧名思義,TensorFlow是指”張量的流動“,Tensorflow的資料流圖是有節點(node)和邊(edge)組成的有向無環圖(DAG)
邊有兩種連線關係:資料依賴和控制依賴。其中,實線邊表示資料依賴,代表資料,即張量(任意維度的資料統稱為張量)。虛線稱為控制依賴,可以用於控制操作的執行,這被用來確保happens-before關係,這類邊上沒有資料流過,但源節點必須在目的節點開始執行前完成執行。
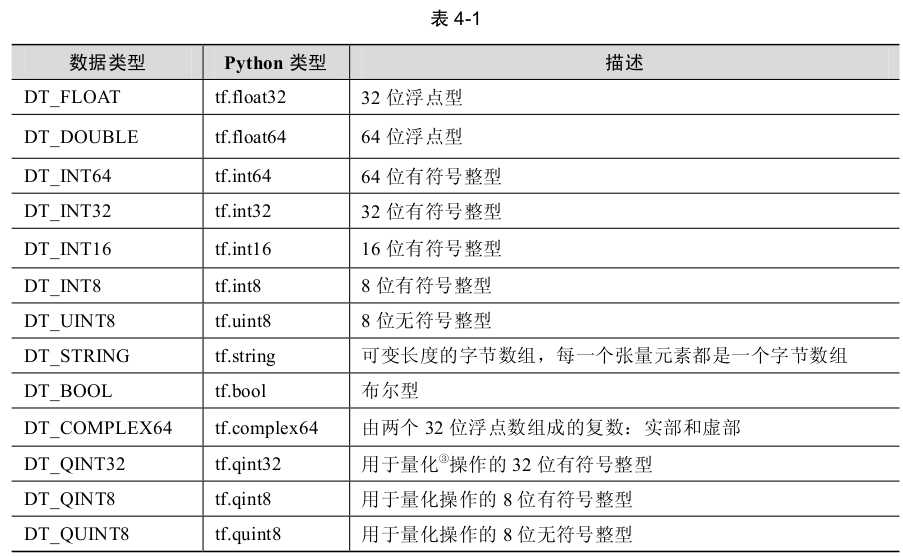
節點又稱為運算元,它代表一個操作(operation,OP)

圖:把操作任務描述成有向無環圖
會話:啟動圖的第一步是建立一個Session物件。run()執行圖時,傳入一些Tensor,這個過程叫填充,返回叫取回。
裝置:指一塊用來運算並且擁有自己的地址空間的硬體,如GPU和CPU
with tf.Session() as sess:
# 指定在第二個 gpu 上執行
with tf.device("/gpu:1"):
matrix1 = tf.constant([[3., 3.]])
matrix2 = tf.constant([[2.],[2.]])
product = tf.matmul(matrix1, matrix2)核心:能夠執行在特定裝置(如CPU、GPU)上的一種對操作的實現。因此,同一個操作可能會對應多個核心。
4.4 常用API
圖、操作和張量
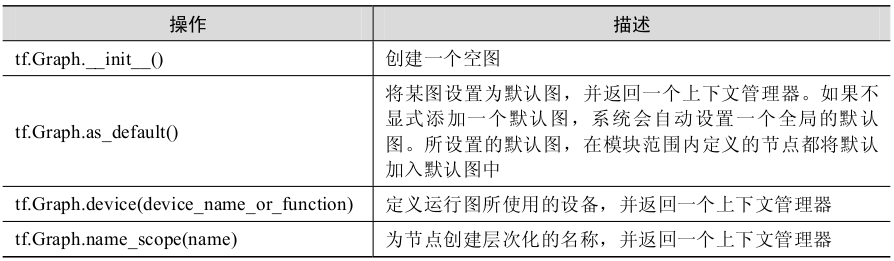


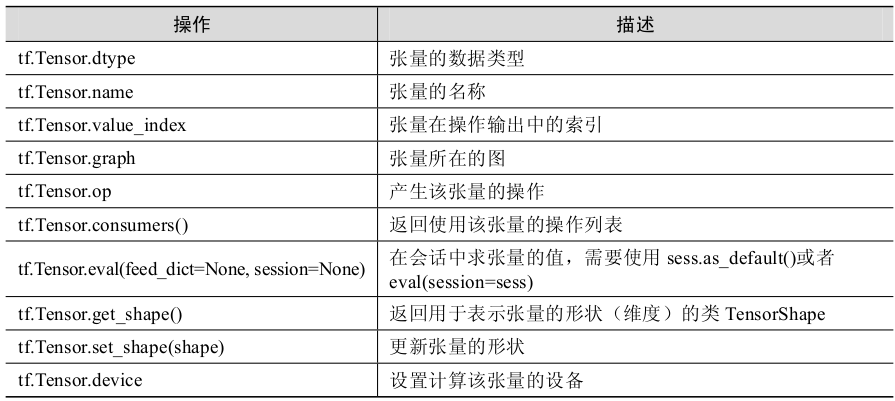
視覺化

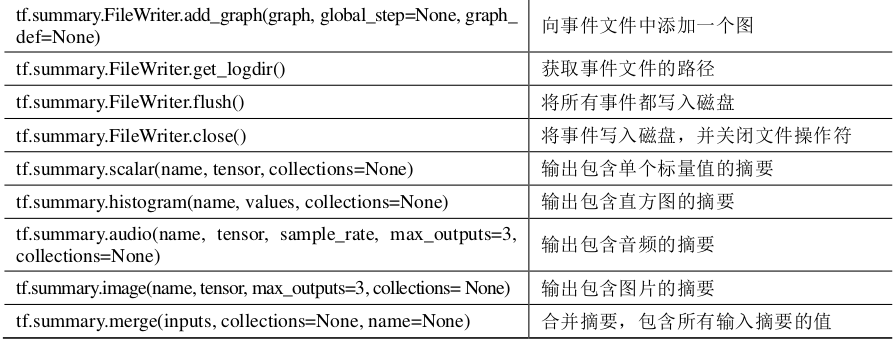
4.5 變數作用域
有兩個作用域,一個是name_scope,另一個是variable_scope。它們究竟有什麼區別呢?
獲得變數作用域
變數作用域的初始化
4.6 批標準化
為了克服神經網路層數加深導致難以訓練而誕生的。DNN隨著網路加深,訓練起來會越來越困難,收斂速度會很慢,常常會導致梯度彌散問題。
統計機器學習中有一個ICS(Internal Covariate Shift)理論,這是一個經典假設:源域和目標域的資料分佈是一致的。也就是說,訓練資料和測試資料是滿足相同分佈的。這是通過訓練資料獲得的模型能夠在測試集獲得好的效果的一個基本保障。
Covariate Shift是指訓練集的樣本資料和目標樣本集分佈不一致時,訓練得到的模型無法很好地泛化。它是分佈不一致假設之下的一個分支問題,也就是指源域和目標域的條件概率是一致的,但是其邊緣概率不同。的確,對於神經網路的各層輸出,在經過了層內操作後,各層輸出分佈就會與對應的輸入訊號分佈不同,而且差異會隨著網路深度增大而加大,但是每一層所指向的樣本標記仍然是不變的。
解決思路一般是根據訓練樣本和目標樣本的比例對訓練樣本做一個矯正。因此,通過引入批標準化來規劃化某些層或者所有層的輸入,從而固定每層輸入訊號的均值與方差。
方法:批標準化一般用在非線性對映(啟用函式)之前,對x=Wu+b做規範化,使結果(輸出訊號各個維度)的均值為0,方差為1。讓每一層的輸入有一個穩定的分佈會有利於網路的訓練。
優點:批標準化通過規範化讓啟用函式分佈線上性區間,結果就是加大了梯度,讓模型更加大膽地進行梯度下降,於是有如下優點:加大探索的步長,加快收斂的速度;更容易跳出區域性最小值;破壞原來的資料分佈,一定程度上緩解過擬合。
因此,在遇到神經網路收斂速度很慢或梯度爆炸等無法訓練的情況下,都可以嘗試用批標準化來解決。
Wx _ plus _ b = tf.nn.batch _ normalization(Wx _ plus _ b, fc _ mean, fc _ var, shift, scale, epsilon)
# 也就是在做:
# Wx _ plus _ b = (Wx _ plus _ b - fc _ mean) / tf.sqrt(fc _ var + 0.001)
# Wx _ plus _ b = Wx _ plus _ b * scale + shift
4.7 神經元函式及優化方法
務必把本屆介紹的常用API記熟。
啟用函式:它們定義在 tensorflow-1.1.0/tensorflow/python/ops/nn.py
tf.nn.relu()
tf.nn.sigmoid()
tf.nn.tanh()
tf.nn.elu()
tf.nn.bias _ add()
tf.nn.crelu()
tf.nn.relu6()
tf.nn.softplus()
tf.nn.softsign()
tf.nn.dropout() # 防止過擬合,用來捨棄某些神經元
卷積函式:定義在 tensorflow-1.1.0/tensorflow/python/ops 下的 nn_impl.py 和 nn_ops.py 檔案中
計算N維卷積的和:
tf.nn.convolution(input, filter, padding, strides=None, dilation _ rate=None, name=None, data _ format=None)
對一個四維的輸入資料input和四維的卷積核filter進行操作,然後對輸入資料進行一個二維的卷積操作,最後得到卷積之後的結果:
tf.nn.conv2d(input, filter, strides, padding, use _ cudnn _ on _ gpu=None, data _ format= None, name=None)
張量的資料維度是[batch, in_height, in_width, in_channels],卷積核的維度是[filter_height, filter_width, in_channels, channel_multiplier],在通道 in_channels 上面的卷積深度是1,depthwise_conv2d 函式將不同的卷積核獨立地應用在 in_channels 的每個通道上(從通道 1到通道 channel_multiplier),然後把所以的結果進行彙總。最後輸出通道的總數是 in_channels
* channel_multiplie
tf.nn.depthwise _ conv2d (input, filter, strides, padding, rate=None, name=None, data _ format=None)
用幾個分離的卷積核去做卷積。在這個 API 中,將應用一個二維的卷積核,在每個通道上,以深度 channel_multiplier 進行卷積
tf.nn.separable _ conv2d (input, depthwise _ filter, pointwise _ filter, strides, padding, rate=None, name=None, data _ format=None)
計算 Atrous 卷積,又稱孔卷積或者擴張卷積
tf.nn.atrous _ conv2d(value, filters, rate, padding, name=None)
在解卷積網路(deconvolutional network)中有時稱為“反摺積”,但實際上是 conv2d的轉置,而不是實際的反摺積。
tf.nn.conv2d _ transpose(value, filter, output _ shape, strides, padding='SAME', data _ format='NHWC', name=None)
和二維卷積類似。這個函式是用來計算給定三維的輸入和過濾器的情況下的一維卷積。不同的是,它的輸入是三維,如[batch, in_width, in_channels]。卷積核的維度也是三維,少了一維 filter_height,如 [filter_width, in_channels, out_channels]。stride 是一個正整數,代表卷積核向右移動每一步的長度。
tf.nn.conv1d(value, filters, stride, padding, use _ cudnn _ on _ gpu=None, data _ format= None, name=None)
和二維卷積類似。這個函式用來計算給定五維的輸入和過濾器的情況下的三維卷積。和二維卷積相對比:
tf.nn.conv3d(input, filter, strides, padding, name=None)
和二維反摺積類似
tf.nn.conv3d _ transpose(value, filter, output _ shape, strides, padding='SAME', name=None)
池化函式:定義在 tensorflow-1.1.0/tensorflow/python/ops 下的 nn.py 和 gen_nn_ops.py
計算池化區域中元素的平均值
tf.nn.avg _ pool(value, ksize, strides, padding, data _ format='NHWC', name=None)
計算池化區域中元素的最大值
tf.nn.max _ pool(value, ksize, strides, padding, data _ format='NHWC', name=None)
這個函式的作用是計算池化區域中元素的最大值和該最大值所在的位置
tf.nn.max _ pool _ with _ argmax(input, ksize, strides, padding, Targmax=None, name=None)
在三維下的平均池化和最大池化
tf.nn.avg _ pool3d(input, ksize, strides, padding, name=None)
tf.nn.max _ pool3d(input, ksize, strides, padding, name=None)
在三維下的平均池化和最大池化
tf.nn.fractional _ avg _ pool(value, pooling _ ratio, pseudo _ random=None, overlapping=None, deterministic=None, seed=None, seed2=None, name=None)
tf.nn.fractional _ max _ pool(value, pooling _ ratio, pseudo _ random=None, overlapping=None, deterministic=None, seed=None, seed2=None, name=None)
執行一個 N 維的池化操作
tf.nn.pool(input, window _ shape, pooling _ type, padding, dilation _ rate=None, strides=None, name=None, data _ format=None)
分類函式:定義在 tensorflow-1.1.0/tensorflow/python/ops 的nn.py 和 nn_ops.py 檔案
這個函式的輸入要格外注意,如果採用此函式作為損失函式,在神經網路的最後一層不需要進行 sigmoid 運算
tf.nn.sigmoid _ cross _ entropy _ with _ logits(logits, targets, name=None)
計算 Softmax 啟用
tf.nn.softmax(logits, dim=-1, name=None)
計算 log softmax 啟用
tf.nn.log _ softmax(logits, dim=-1, name=None)
tf.nn.softmax _ cross _ entropy _ with _ logits(logits, labels, dim=-1, name=None)
tf.nn.sparse _ softmax _ cross _ entropy _ with _ logits(logits, labels, name=None)
優化方法:目前基本都是基於梯度下降的
tf.train.GradientDescentOptimizer
tf.train.AdadeltaOptimizer
tf.train.AdagradOptimizer
tf.train.AdagradDAOptimizer
tf.train.MomentumOptimizer
tf.train.AdamOptimizer
tf.train.FtrlOptimizer
tf.train.RMSPropOptimizer
想要更深入研究各種優化方法,可以參參《An overview of gradient descent optimization algorithms》
4.8 模型的儲存與載入:
提供了以下兩種方式來儲存和載入模型
(1)生成檢查點檔案(checkpoint file),副檔名一般為.ckpt,通過在 tf.train.Saver 物件上呼叫 Saver.save()生成。它包含權重和其他在程式中定義的變數,不包含圖結構。如果需要在另一個程式中使用,需要重新建立圖形結構,並告訴 TensorFlow 如何處理這些權重。
(2)生成圖協議檔案(graph proto file),這是一個二進位制檔案,副檔名一般為.pb,用tf.train.write_graph()儲存,只包含圖形結構,不包含權重,然後使用 tf.import_graph_def()來載入圖形。
4.9 佇列和執行緒
P100
4.10 載入資料
tensorFlow作為符號程式設計框架,需要先構建資料流圖,再讀取資料,隨後進行模型訓練。
TensorFlow 官方網站給出了以下讀取資料 3 種方法 。
● 預載入資料(preloaded data):在 TensorFlow 圖中定義常量或變數來儲存所有資料。
● 填充資料(feeding):Python 產生資料,再把資料填充後端。
● 從檔案讀取資料(reading from file):從檔案中直接讀取,讓佇列管理器從檔案中讀取資料。
4.11 實現一個自定義操作
相關文章
- Pytest 實踐:Python 測試技術基礎知識Python
- 資訊處理技術基礎知識(2.4多媒體基礎知識 )--第2章
- 面向機器智慧的TensorFlow實戰4:機器學習基礎機器學習
- kubebuilder實戰之三:基礎知識速覽UI
- 收藏: 全面解析FPGA基礎知識FPGA
- 學習下區塊鏈技術基礎知識區塊鏈
- 前端基礎技術知識講解-面試圖譜前端面試
- 面試圖譜:前端基礎技術知識講解面試前端
- OpenStack關鍵技術系列: Libvirt基礎知識
- CSS基礎知識總結(4)CSS
- C#反射基礎知識和實戰應用C#反射
- Cookie 與 Session 基礎知識CookieSession
- VCS基礎知識與概念
- IO基礎知識與概念
- 知識圖譜 KnowledgeGraph基礎解析
- 使用Jquery解析Json基礎知識jQueryJSON
- Java核心技術 卷1 基礎知識 部分筆記Java筆記
- 儲存基礎知識(1)--主要技術DAS、SAN、NAS
- Elasticsearch技術解析與實戰(六)Elasticsearch併發Elasticsearch
- corejava基礎知識(4)-萬用字元Java字元
- 面向機器智慧的TensorFlow實戰2:TensorFlow基礎
- Python技術基礎知識點:OS模組的應用Python
- 小白系列:資料庫基礎知識解析資料庫
- JAVA與tomcat基礎知識JavaTomcat
- php基礎知識(五)魔術方法PHP
- 區塊鏈交易隱私如何保證?華為零知識證明技術實戰解析區塊鏈
- 《Elasticsearch技術解析與實戰》Chapter 1.2 Elasticsearch安裝ElasticsearchAPT
- 機器學習-ROC曲線:技術解析與實戰應用機器學習
- IdentityServer4系列 | 初識基礎知識點IDEServer
- 基礎知識
- 解碼知識圖譜:從核心概念到技術實戰
- Scikit-Learn 與 TensorFlow 機器學習實用指南學習筆記1 — 機器學習基礎知識簡介機器學習筆記
- Python基礎知識_第10節_檔案操作(IO技術)Python
- Spark SQL知識點與實戰SparkSQL
- Linux基本知識與基礎命令Linux
- 美團知識圖譜問答技術實踐與探索
- Oracle鎖的一些實驗與技術知識Oracle
- 走進JavaWeb技術世界1:JavaWeb的由來和基礎知識JavaWeb