轉自:http://www.cnblogs.com/yurunmiao/p/4936583.html
Spark相對於Hadoop MapReduce有一個很顯著的特性就是“迭代計算”(作為一個MapReduce的忠實粉絲,能這樣說,大家都懂了吧),這在我們的業務場景裡真的是非常有用。
假設我們有一個文字檔案“datas”,每一行有三列資料,以“\t”分隔,模擬生成檔案的程式碼如下:
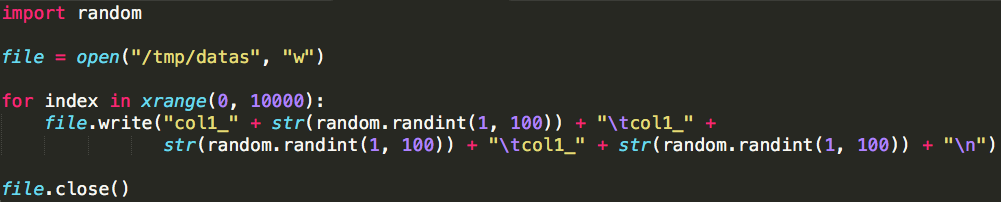
執行該程式碼之後,文字檔案會儲存於本地路徑:/tmp/datas,它包含1000行測試資料,將其上傳至我們的測試Hadoop叢集,路徑:/user/yurun/datas,命令如下:

查詢一下它的狀態:

我們通過Spark SQL API將其註冊為一張表,程式碼如下:
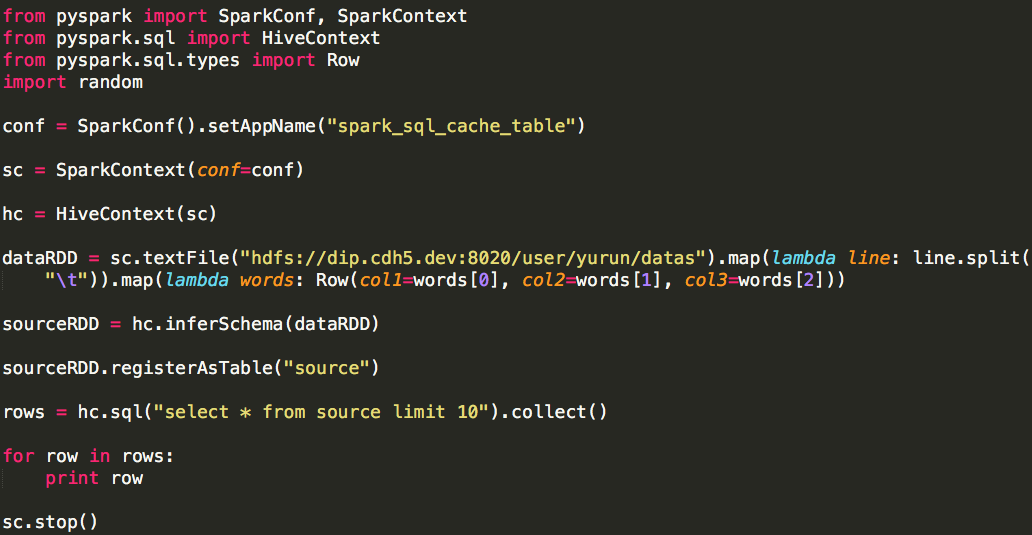
表的名稱為source,它有三列,列名分別為:col1、col2、col3,型別都為字串(str),測試列印其前10行資料:

假設我們的分析需求如下:
(1)過濾條件:col1 = ‘col1_50',以col2為分組,求col3的最大值;
(2)過濾條件:col1 = 'col1_50',以col3為分組,求col2的最小值;
注意:需求是不是很變態,再次注意我們只是模擬。
通過情況下我們可以這麼做:

每一個collect()(Action)都會產生一個Spark Job,

因為這兩個需求的處理邏輯是類似的,它們都有兩個Stage:


可以看出這兩個Job的資料輸入量是一致的,根據輸入量的具體數值,我們可以推斷出這兩個Job都是直接從原始資料(文字檔案)計算的。
這種情況在Hive(MapReduce)的世界裡是很難優化的,處理邏輯雖然簡單,卻無法使用一條SQL語句表述(有的是因為分析邏輯複雜,有的則因為各個處理邏輯的結果需要獨立儲存),只能一個需求對應一(多)條SQL語句(如上示例),帶來的問題就是全量原始資料多次被分析,在海量資料的場景下必然帶來叢集資源的巨大浪費。
其實這兩個需求有一個共同點:過濾條件相同(col1 = 'col1_50'),一個很自然的想法就是將滿足過濾條件的資料快取,然後在快取資料之上執行計算,Spark為我們做到了這一點。
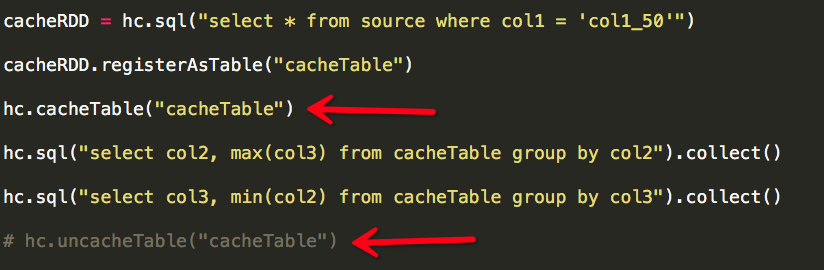
依然是兩個Job,每個Job仍然是兩個Stage,但這兩個Stage的輸入資料量(Input)已發生變化:


Job1的Input(資料輸入量)仍然是63.5KB,是因為“cacheTable”僅僅在RDD(cacheRDD)第一次被觸發計算並執行完成之後才會生效,因此Job1的Input是63.5KB;而Job2執行時“cacheTable”已生效,直接輸入快取中的資料即可,因此Job2的Input減少為3.4KB,而且因為所需快取的資料量小,可以完全被快取於記憶體中,因此效率極高。
我們也可以從Spark相關頁面中確認“cache”確實生效:

我們也需要注意cacheTable與uncacheTable的使用時機,cacheTable主要用於快取中間表結果,它的特點是少量資料且被後續計算(SQL)頻繁使用;如果中間表結果使用完畢,我們應該立即使用uncacheTable釋放快取空間,用於快取其它資料(示例中註釋uncacheTable操作,是為了頁面中可以清楚看到表被快取的效果)。