開篇介紹
先簡單的演示一下使用 Lookup 元件實現一個簡單示例 - 從資料來源表 A 中匯出資料到目標資料表 B,如果 A 資料在 B 中不存在就插入新資料到B,如果存在就更新B 和 A 表資料保持統一。
隨後再來解釋在這個過程中使用到的一些術語,以及分析一下 Lookup 中出現的幾種快取模式,各自的特點以及常用的場合。
案例講解
兩張表,一張是目標表 DEMO_LK_Customer,一張是 DEMO_LK_LegacyCustomer 舊系統表。我們可以理解我們這個示例要實現的目標是 DEMO_LK_Customer 表的資料要和DEMO_LK_LegacyCustomer 實現同步,保持一致。
USE BIWORK_SSIS GO -- Look up demo table IF OBJECT_ID('DEMO_LK_Customer','U') IS NOT NULL DROP TABLE DEMO_LK_Customer GO IF OBJECT_ID('DEMO_LK_LegacyCustomer','U') IS NOT NULL DROP TABLE DEMO_LK_LegacyCustomer GO CREATE TABLE DEMO_LK_Customer ( CustomerID INT PRIMARY KEY, CustomerCompany NVARCHAR(255), CustomerName NVARCHAR(20), CustomerAddress NVARCHAR(255) ) CREATE TABLE DEMO_LK_LegacyCustomer ( CustomerID INT PRIMARY KEY, CustomerCompany NVARCHAR(255), ContactName NVARCHAR(20), ContactTitle NVARCHAR(50), CustomerAddress NVARCHAR(255) ) INSERT INTO DEMO_LK_Customer VALUES (1,'HFBZG','Allen,Michael','Obere Str. 0123'), (2,'MLTDN','Hassall, Mark','Avda. de la Constitución 5678'), (3,'KBUDE','Peoples, John','Mataderos 1000') INSERT INTO DEMO_LK_LegacyCustomer VALUES (1,'NRZBB','Allen,Michael','Sales Representative','Obere Str. 0123'), (2,'MLTDN','Hassall, Mark','Owner','Avda. de la Constitución 5678'), (3,'KBUDE','Peoples, John','Owner','Mataderos 7890'), (4,'HFBZG','Arndt, Torsten','Sales Representative','7890 Hanover Sq.'), (5,'HGVLZ','Higginbotham, Tom','Order Administrator','Berguvsvägen 5678') SELECT * FROM DEMO_LK_Customer SELECT * FROM DEMO_LK_LegacyCustomer --UPDATE DEMO_LK_Customer SET CustomerName = ?, CustomerCompany = ?, CustomerAddress = ? WHERE CustomerID = ? --UPDATE DEMO_LK_Customer SET CustomerName = ? WHERE CustomerID = ? --UPDATE DEMO_LK_Customer SET CustomerAddress = ? WHERE CustomerID = ?
在測試資料中,我們認為兩張表的 ID 都是不變的唯一的,第1條資料和第3條資料不一致,第4條和第5條資料在目標表中不存在。
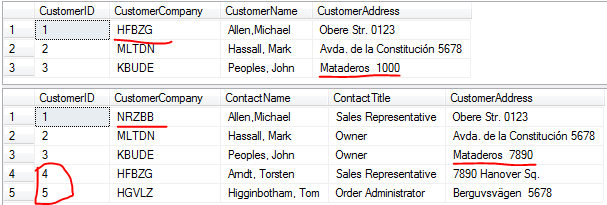
先看一下實現這個例子的 SSIS Package 結構,最外面的是一個資料流 DF_Lookup。

在資料流中,資料來源 OLE_SRC_LegacyCustomer 在這個例子中使用的是 SQL Server 資料庫表,但是這個資料來源也可以是文字檔案,Excel 或者其它資料庫的表或者查詢的結果集。
這個資料來源相對於 Lookup 元件 LKP_Customer 來說是 Lookup 元件的輸入項。
LKP_Customer 之後有兩個分支 - 匹配和不匹配分支,做的事情就是匹配的資料做更新,不匹配的資料做插入動作。
輸入源 OLE_SRC_LegacyCustomer 的配置

輸入源中要向下輸出的列 - 相對於 Lookup 元件,它的輸出是 Lookup 的輸入。

LKP_Customer 的快取模式選擇的是預設模式 - Full Cache 完全快取,連線型別 OLE DB Connection 。

從上一個元件中輸出的列即這裡的資料來源 Input 要到下面展示的表或者檢視 DEMO_LK_Customer 中查詢匹配項,下面的 DEMO_LK_Customer 在Lookup 元件中被稱為 - Reference Table/Set 引用表/引用集,前面預設的 Full Cache 快取的就是這裡的 Reference Table - DEMO_LK_Customer。

解釋一下這個關聯和配置的含義 -
左邊 Available Input Columns 來源於 Input 即資料來源中輸出的列,這些列會作為 Lookup 元件繼續向下一個元件輸出的列。
Available Lookup Columns 來源於 Reference table 即在快取中的資料,已選中的 CustomerID 也會作為 Lookup 元件繼續向下一個元件輸出的列。
中間的黑色實心線描述了查詢時的關聯規則,以左邊為驅動表到右邊快取表中查詢 CustomerID 一致的資料,找到了則匹配成功,找不到則不匹配。

設定瞭如果不匹配則輸出不匹配的選項,因此在 Lookup 元件之後能看到 Lookup Match Output 和 Lookup No Match Output 選項。
我們要把匹配的 CustomerID, 將 Input 作為源,將 Reference Table 作為目標表,將 CustomerID 匹配的其它列的資料更新到目標表中。
新增元件 OLE_Command 來更新 DEMO_LK_Customer 目標表,選擇的是 Lookup Match Output -
UPDATE DEMO_LK_Customer SET CustomerName = ?, CustomerCompany = ?, CustomerAddress = ? WHERE CustomerID = ?

設定引數,這裡就能看到有兩個 CustomerID,一個是來源於 Input 的 CustomerID,一個則是上一個資料來源中 OLE_SRC_LegacyCustomer 的 CustomerID,這裡隨便制定哪一個 CustomerID 都可以。

新增一個新元件 OLE DB Destination 連線的是 Lookup NO Match Output,並設定 DEMO_LK_Customer 為目標表,表示如果不匹配則新增新資料。

輸入輸出的 Mapping 關係。

執行 Package,看到從資料來源中向下輸出 5 條資料,其中有 3 條資料與 Reference Table 通過 CustomerID 匹配上,因此根據 CustomerID 將最新的從 Input 中輸出的資訊更新到已存在的目標表中。另外兩條不匹配,則新增到目標表中。
注意這裡提到的幾個表雖然有的是同一張表,但是它們的角色是不一樣的 -
- OLE_SRC_LegacuCustomer 中的表 DEMO_LK_LegacyCustomer - 作為 Lookup 元件 LKP_Customer 中的輸入源,被稱為 Input Table。
- LKP_Customer 中引用的表 DEMO_LK_Customer 在 Lookup 元件中被稱為 Reference Table。
- OLE_CMD_UpdateCustomer 和 OLE_DST_InsertNewCustomer 中出現的表 DEMO_LK_Customer 是目標表。

對於一下最後源表和目標表的資料,保持了同步,前提就是 CustomerID 在兩張表中都能夠唯一確定一條資料。在資料倉儲的設計中,也會設計一個 Key 能夠唯一確定業務系統和資料倉儲中的一條資料,使它們能夠在邏輯上能夠關聯起來。

但是這裡有一個問題,就是第2條資料沒有變化,但是也會執行一次 Update 操作,可以看上面的例子中,Update 操作顯示的是3條資料輸入了。如果資料量比較多的情況下,像這樣的 Update 是沒有必要的。
因此下面要對這個例子進行一個簡單的改造,假設只有 CustomerCompany 和 CustomerAddress 會不一致的情況下,可以如何處理來避免無謂的更新操作。
我的改造是在查詢匹配之後,新增一個元件 Conditional Split - CS_CheckValues 對輸出列做一個判斷,只在 CustomerCompany 和 CustomerAddress 不一致的情況下做出更新。
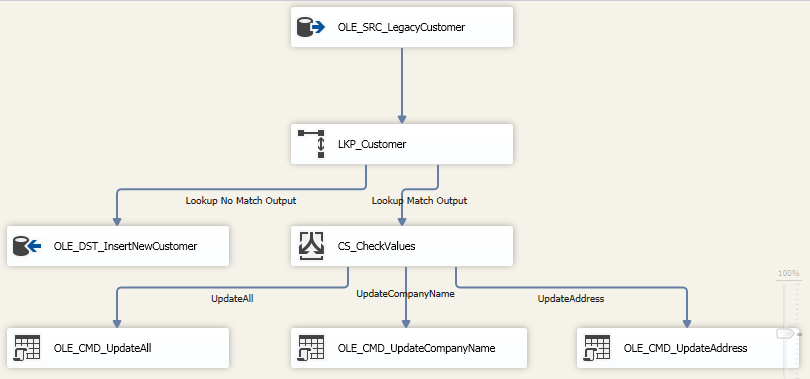
並且在 Lookup 元件中做出修改,因為要比較 Input table 和 Reference table 的兩個列,因此選中右邊的幾個列。

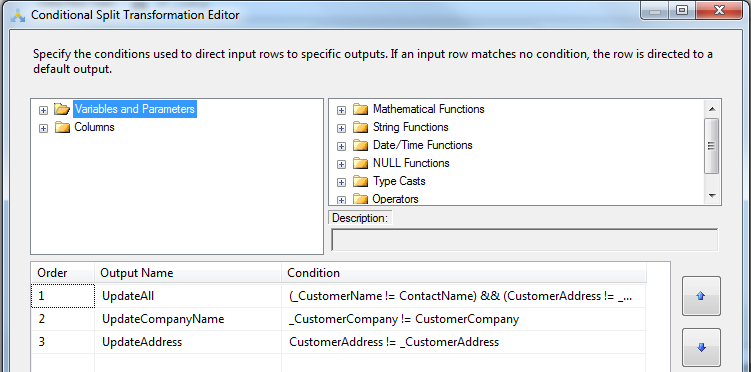
檢查的規則有3個,當兩個列都不一致的時候,到某一個列不一致的時候,並且也應該按照這種順序來確保第一種規則應該最先檢查。
(_CustomerName != ContactName) && (CustomerAddress != _CustomerAddress) && (CustomerCompany != _CustomerCompany)
_CustomerCompany != CustomerCompany
CustomerAddress != _CustomerAddress
最後新增相應的元件按照不同的規則執行對應的更新語句 -
--UPDATE DEMO_LK_Customer SET CustomerName = ?, CustomerCompany = ?, CustomerAddress = ? WHERE CustomerID = ?
--UPDATE DEMO_LK_Customer SET CustomerName = ? WHERE CustomerID = ?
--UPDATE DEMO_LK_Customer SET CustomerAddress = ? WHERE CustomerID = ?
再次執行這個 Package 的時候就能看到更新的時候只有兩條資料更新了,這樣就避免了不必要的全部更新。

這個例子往小了說就是一個表到另外一個表根據那些列然後關聯查詢出一些列合併或者不合並輸出,往大了說可以想象一下更多的場景。比如資料來源是一個或者一批檔案,Excel,需要定期將檔案或者Excel中的資料同步更新到一個資料表中。比如將業務系統中的表資料更新到資料倉儲中,更新一下資料倉儲中的一些維度屬性或者事實資料(事實資料一般很少更新),或者新增一些新的事實資料。所以,Lookup 的使用在 SSIS 中相當於大多陣列件來說使用的頻率還是比較高的。雖然,它的某些功能實現完全可以用其它的元件或者邏輯來代替,甚至直接使用 SQL 語句。但是某些時候,我們還是還考慮使用 Lookup,因為 Lookup 裡有一些快取的設計,可以提高我們處理資料的效率,特別是在 SSIS Package 中反覆使用到同一個 Reference 物件的時候。
瞭解 Lookup 的快取模式
下面提到的快取模式只適用於 OLE DB Connection Manager, Cache connection manager 類似於 OLE DB Connection Manager 中的 Full Cache Mode。
Full Cache 完全快取模式

這是 Lookup 的預設選項,選擇這個模式後,在資料流 Data flow 真正執行之前就會將表中的資料或者對應查詢結果的資料一次性的從資料來源中將資料快取到記憶體中。
特點:
- 資料流(SSIS)執行之前快取全部結果集。
- 消耗記憶體大,增加了資料流的啟動時間。
- 在資料流啟動之後執行速度要快,資料不需要從資料來源中再次讀取。
- 資料來源中的資料更新此時將不再影響到快取中的資料。
- 快取中的資料可以被後面的元件重複使用。
什麼時候該使用 Full Cache?
- Lookup 資料集比較大的時候,一次載入到記憶體可以反覆使用,而不需要反覆的去查詢資料庫。
- 資料庫伺服器不在本地,為了減少查詢次數的情況下也要考慮使用 Full Cache。
使用 Full Cache 模式時要注意的地方:
- 資料全部快取在記憶體中,如果記憶體不夠並不會將超出部分的資料快取到磁碟上,而是直接報錯 - Run out of memory。
- 由於資料集快取在記憶體中,所以在使用 Lookup 的時候不應該直接使用表物件,而應該通過寫 SELECT 語句來減少不必要的列輸出並且可以加上 WHERE 條件來限定一下資料集的大小,簡而言之快取的資料應該只包含有用的資料。
- 資料一旦快取,那麼在資料流執行過程中就不會再去檢測之前源資料是否發生改變或者更新等等,除非資料流重新啟動執行。
Partial Cache 部分快取模式
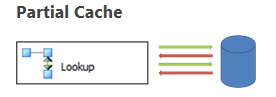
部分快取模式下,資料流開始時快取還是空的。當時資料流開始執行後,當 Lookup 元件需要根據輸入行找匹配資料的時候,這時 Lookup 元件會先檢查一下快取有沒有匹配的資料,如果沒有就查詢資料庫,如果在資料庫中查到匹配的資料行的時候就把這個資料行快取起來,以便下次使用。
查詢的過程可以這樣理解,比如 Input Source 中有一個 ID1 與 Lookup 物件的 ID2 匹配,那麼每次就是拿 ID1 到 Lookup 的快取中查一下有沒有 ID2的值和ID1的值匹配,如果沒有的話就用 ID1的值作為一個引數到 ID2 所在的資料庫進行查詢,因為每次查詢的結構是一樣的,所以只通過傳引數的形式,某種程式上重用了查詢語句。
特點:
- 資料流啟動之前,快取為空,資料流啟動時間要比完全快取的情況下要快。
- Lookup 的時候會慢,因為總要檢查快取,如果有的話就直接用,如果沒有的話就需要查詢資料庫,每次查詢都是一次開銷。如果資料量比較大的話,那麼開銷就會非常大。
- 可以在 Advanced Options 中設定最大快取,一旦快取中的實際資料大小超過這個最大值的話,就會自動清理那些較少使用的資料為新的資料騰出空間。
什麼時候該使用部分快取?
- Lookup 快取物件資料量較少的時候,不需要花時間等待全部快取結束後再開始資料流的執行。
No Cache 無快取模式

每次匹配查詢都會去資料庫查一次。這種快取模式下,資料量不大並且記憶體比較緊張的情況下才會使用,當然它對記憶體的消耗也相對最小。
以上三種都是 OLE DB 的連線模式,從 SQL Server 2008 開始也支援了一種新的快取模式 - 檔案快取模式。檔案快取是將 Reference table 中的資料存放到一個共享檔案中可以供後面使用同一 Reference table 的 lookup 使用。它對記憶體的消耗很少,檔案的資料直接存放在磁碟上,因此可以處理非常大的 Reference table 資料。
我個人覺得大多數情況下會選擇 OLE DB 下的 Full Cache, 因為一般的BI專案資料量比較大並且資料大多主要是分析歷史資料,所以對資料的實時性要求不高。同時,現在大多數伺服器的環境也有條件讓我們一次性載入足夠多G的資料放到記憶體中快取起來以重複使用。
更多 BI 文章請參看 BI 系列隨筆列表 (SSIS, SSRS, SSAS, MDX, SQL Server) 如果覺得這篇文章看了對您有幫助,請幫助推薦,以方便他人在 BIWORK 部落格推薦欄中快速看到這些文章。