Kd-Tree演算法原理和開源實現程式碼
本文介紹一種用於高維空間中的快速最近鄰和近似最近鄰查詢技術——Kd- Tree(Kd樹)。Kd-Tree,即K-dimensional tree,是一種高維索引樹形資料結構,常用於在大規模的高維資料空間進行最近鄰查詢(Nearest Neighbor)和近似最近鄰查詢(Approximate Nearest Neighbor),例如影像檢索和識別中的高維影像特徵向量的K近鄰查詢與匹配。本文首先介紹Kd-Tree的基本原理,然後對基於BBF的近似查詢方法進行介紹,最後給出一些參考文獻和開源實現程式碼。
一、Kd-tree
Kd-Tree,即K-dimensional tree,是一棵二叉樹,樹中儲存的是一些K維資料。在一個K維資料集合上構建一棵Kd-Tree代表了對該K維資料集合構成的K維空間的一個劃分,即樹 中的每個結點就對應了一個K維的超矩形區域(Hyperrectangle)。
在介紹Kd-tree的相關演算法前,我們先回顧一下二叉查詢樹(Binary Search Tree)的相關概念和演算法。
二叉查詢樹(Binary Search Tree,BST),是具有如下性質的二叉樹(來自wiki):
1)若它的左子樹不為空,則左子樹上所有結點的值均小於它的根結點的值;
2)若它的右子樹不為空,則右子樹上所有結點的值均大於它的根結點的值;
3)它的左、右子樹也分別為二叉排序樹;
例如,圖1中是一棵二叉查詢樹,其滿足BST的性質。

圖1 二叉查詢樹(來源:Wiki)
給定一個1維資料集合,怎樣構建一棵BST樹呢?根據BST的性質就可以建立,即將資料點一個一個插入到BST樹中,插入後的樹仍然是BST樹,即根結點的左子樹中所有結點的值均小於根結點的值,而根結點的右子樹中所有結點的值均大於根結點的值。
將一個1維資料集用一棵BST樹儲存後,當我們想要查詢某個資料是否位於該資料集合中時,只需要將查詢資料與結點值進行比較然後選擇對應的子樹繼續往下查詢即可,查詢的平均時間複雜度為:O(logN),最壞的情況下是O(N)。
如果我們要處理的物件集合是一個K維空間中的資料集,那麼是否也可以構建一棵 類似於1維空間中的二叉查詢樹呢?答案是肯定的,只不過推廣到K維空間後,建立二叉樹和查詢二叉樹的演算法會有一些相應的變化(後面會介紹到兩者的區別), 這就是下面我們要介紹的Kd-tree演算法。
怎樣構造一棵Kd-tree?
對於Kd-tree這樣一棵二叉樹,我們首先需要確定怎樣劃分左子樹和右子樹,即一個K維資料是依據什麼被劃分到左子樹或右子樹的。
在構造1維BST樹時,一個1維資料根據其與樹的根結點和中間結點進行大小比 較的結果來決定是劃分到左子樹還是右子樹,同理,我們也可以按照這樣的方式,將一個K維資料與Kd-tree的根結點和中間結點進行比較,只不過不是對K 維資料進行整體的比較,而是選擇某一個維度Di,然後比較兩個K維數在該維度Di上的大小關係,即每次選擇一個維度Di來對K維資料進行劃分,相當於用一 個垂直於該維度Di的超平面將K維資料空間一分為二,平面一邊的所有K維資料在Di維度上的值小於平面另一邊的所有K維資料對應維度上的值。也就是說,我 們每選擇一個維度進行如上的劃分,就會將K維資料空間劃分為兩個部分,如果我們繼續分別對這兩個子K維空間進行如上的劃分,又會得到新的子空間,對新的子 空間又繼續劃分,重複以上過程直到每個子空間都不能再劃分為止。以上就是構造Kd-Tree的過程,上述過程中涉及到兩個重要的問題:1)每次對子空間的 劃分時,怎樣確定在哪個維度上進行劃分;2)在某個維度上進行劃分時,怎樣確保在這一維度上的劃分得到的兩個子集合的數量儘量相等,即左子樹和右子樹中的 結點個數儘量相等。
問題1: 每次對子空間的劃分時,怎樣確定在哪個維度上進行劃分?
最簡單的方法就是輪著來,即如果這次選擇了在第i維上進行資料劃分,那下一次就在第j(j≠i)維上進行劃分,例如:j = (i mod k) + 1。想象一下我們切豆腐時,先是豎著切一刀,切成兩半後,再橫著來一刀,就得到了很小的方塊豆腐。
可是“輪著來”的方法是否可以很好地解決問題呢?再次想象一下,我們現在要切 的是一根木條,按照“輪著來”的方法先是豎著切一刀,木條一分為二,乾淨利落,接下來就是再橫著切一刀,這個時候就有點考驗刀法了,如果木條的直徑(橫截 面)較大,還可以下手,如果直徑較小,就沒法往下切了。因此,如果K維資料的分佈像上面的豆腐一樣,“輪著來”的切分方法是可以奏效,但是如果K維度上數 據的分佈像木條一樣,“輪著來”就不好用了。因此,還需要想想其他的切法。
如果一個K維資料集合的分佈像木條一樣,那就是說明這K維資料在木條較長方向 代表的維度上,這些資料的分佈散得比較開,數學上來說,就是這些資料在該維度上的方差(invariance)比較大,換句話說,正因為這些資料在該維度 上分散的比較開,我們就更容易在這個維度上將它們劃分開,因此,這就引出了我們選擇維度的另一種方法:最大方差法(max invarince),即每次我們選擇維度進行劃分時,都選擇具有最大方差維度。
問題2:在某個維度上進行劃分時,怎樣確保在這一維度上的劃分得到的兩個子集合的數量儘量相等,即左子樹和右子樹中的結點個數儘量相等?
假設當前我們按照最大方差法選擇了在維度i上進行K維資料集S的劃分,此時我 們需要在維度i上將K維資料集合S劃分為兩個子集合A和B,子集合A中的資料在維度i上的值都小於子集合B中。首先考慮最簡單的劃分法,即選擇第一個數作 為比較物件(即劃分軸,pivot),S中剩餘的其他所有K維資料都跟該pivot在維度i上進行比較,如果小於pivot則劃A集合,大於則劃入B集 合。把A集合和B集合分別看做是左子樹和右子樹,那麼我們在構造一個二叉樹的時候,當然是希望它是一棵儘量平衡的樹,即左右子樹中的結點個數相差不大。而 A集合和B集合中資料的個數顯然跟pivot值有關,因為它們是跟pivot比較後才被劃分到相應的集合中去的。好了,現在的問題就是確定pivot了。 給定一個陣列,怎樣才能得到兩個子陣列,這兩個陣列包含的元素個數差不多且其中一個子陣列中的元素值都小於另一個子陣列呢?方法很簡單,找到陣列中的中值 (即中位數,median),然後將陣列中所有元素與中值進行比較,就可以得到上述兩個子陣列。同樣,在維度i上進行劃分時,pivot就選擇該維度i上 所有資料的中值,這樣得到的兩個子集合資料個數就基本相同了。
解決了上面兩個重要的問題後,就得到了Kd-Tree的構造演算法了。
Kd-Tree的構建演算法:
(1) 在K維資料集合中選擇具有最大方差的維度k,然後在該維度上選擇中值m為pivot對該資料集合進行劃分,得到兩個子集合;同時建立一個樹結點node,用於儲存<k, m>;
(2)對兩個子集合重複(1)步驟的過程,直至所有子集合都不能再劃分為止;如果某個子集合不能再劃分時,則將該子集合中的資料儲存到葉子結點(leaf node)。
以上就是建立Kd-Tree的演算法。下面給出一個簡單例子。
給定二維資料集合:(2,3), (5,4), (9,6), (4,7), (8,1), (7,2),利用上述演算法構建一棵Kd-tree。左圖是Kd-tree對應二維資料集合的一個空間劃分,右圖是構建的一棵Kd-tree。

圖2 構建的kd-tree
其中圓圈代表了中間結點(k, m),而紅色矩形代表了葉子結點。
Kd-Tree與一維二叉查詢樹之間的區別:
二叉查詢樹:資料存放在樹中的每個結點(根結點、中間結點、葉子結點)中;
Kd-Tree:資料只存放在葉子結點,而根結點和中間結點存放一些空間劃分資訊(例如劃分維度、劃分值);
構建好一棵Kd-Tree後,下面給出利用Kd-Tree進行最近鄰查詢的演算法:
(1)將查詢資料Q從根結點開始,按照Q與各個結點的比較結果向下訪問Kd-Tree,直至達到葉子結點。
其中Q與結點的比較指的是將Q對應於結點中的k維度上的值與m進行比較,若Q(k) < m,則訪問左子樹,否則訪問右子樹。達到葉子結點時,計算Q與葉子結點上儲存的資料之間的距離,記錄下最小距離對應的資料點,記為當前“最近鄰點”Pcur和最小距離Dcur。
(2)進行回溯(Backtracking)操作,該操作是為了找到離Q更近的“最近鄰點”。即判斷未被訪問過的分支裡是否還有離Q更近的點,它們之間的距離小於Dcur。
如果Q與其父結點下的未被訪問過的分支之間的距離小於Dcur,則認為該分支中存在離P更近的資料,進入該結點,進行(1)步驟一樣的查詢過程,如果找到更近的資料點,則更新為當前的“最近鄰點”Pcur,並更新Dcur。
如果Q與其父結點下的未被訪問過的分支之間的距離大於Dcur,則說明該分支內不存在與Q更近的點。
回溯的判斷過程是從下往上進行的,直到回溯到根結點時已經不存在與P更近的分支為止。
怎樣判斷未被訪問過的樹分支Branch裡是否還有離Q更近的點?
從幾何空間上來看,就是判斷以Q為中心center和以Dcur為半徑Radius的超球面(Hypersphere)與樹分支Branch代表的超矩形(Hyperrectangle)之間是否相交。
在實現中,我們可以有兩種方式來求Q與樹分支Branch之間的距離。第一種 是在構造樹的過程中,就記錄下每個子樹中包含的所有資料在該子樹對應的維度k上的邊界引數[min, max];第二種是在構造樹的過程中,記錄下每個子樹所在的分割維度k和分割值m,(k, m),Q與子樹的距離則為|Q(k) - m|。
以上就是Kd-tree的構造過程和基於Kd-Tree的最近鄰查詢過程。
下面用一個簡單的例子來演示基於Kd-Tree的最近鄰查詢的過程。
資料點集合:(2,3), (4,7), (5,4), (9,6), (8,1), (7,2) 。
已建好的Kd-Tree:
圖3 構建的kd-tree
其中,左圖中紅色點表示資料集合中的所有點。
查詢點: (8, 3) (在左圖中用茶色菱形點表示)
第一次查詢:
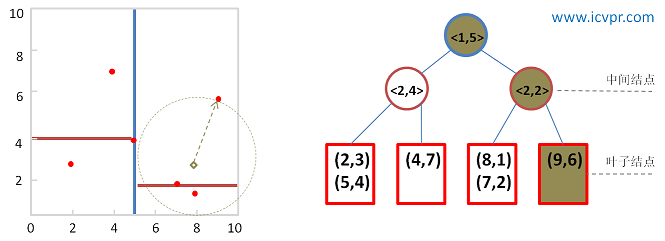
圖4 第一次查詢的kd-tree
當前最近鄰點: (9, 6) , 最近鄰距離: sqrt(10),
且在未被選擇的樹分支中存在於Q更近的點(如茶色圈圈內的兩個紅色點)
回溯:
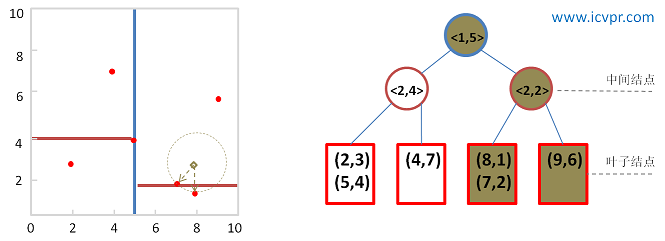
圖5 回溯kd-tree
當前最近鄰點: (8, 1)和(7, 2) , 最近鄰距離: sqrt(2)
最後,查詢點(8, 3)的近似最近鄰點為(8, 1)和(7, 2) 。
二、Kd-tree with BBF
上一節介紹的Kd-tree在維度較小時(例如:K≤30),演算法的查詢效 率很高,然而當Kd-tree用於對高維資料(例如:K≥100)進行索引和查詢時,就面臨著維數災難(curse of dimension)問題,查詢效率會隨著維度的增加而迅速下降。通常,實際應用中,我們常常處理的資料都具有高維的特點,例如在影像檢索和 識別中,每張影像通常用一個幾百維的向量來表示,每個特徵點的區域性特徵用一個高維向量來表徵(例如:128維的SIFT特徵)。因此,為了能夠讓Kd- tree滿足對高維資料的索引,Jeffrey S. Beis和David G. Lowe提出了一種改進演算法——Kd-tree with BBF(Best Bin First),該演算法能夠實現近似K近鄰的快速搜尋,在保證一定查詢精度的前提下使得查詢速度較快。
在介紹BBF演算法前,我們先來看一下原始Kd-tree是為什麼在低維空間中有效而到了高維空間後查詢效率就會下降。 在原始kd-tree的最近鄰查詢演算法中(第一節中介紹的演算法),為了能夠找到查詢點Q在資料集合中的最近鄰點,有一個重要的操作步驟:回溯,該步驟是在 未被訪問過的且與Q的超球面相交的子樹分支中查詢可能存在的最近鄰點。隨著維度K的增大,與Q的超球面相交的超矩形(子樹分支所在的區域)就會增加,這就 意味著需要回溯判斷的樹分支就會更多,從而演算法的查詢效率便會下降很大。
一個很自然的思路是:既然kd-tree演算法在高維空間中是由於過多的回溯次 數導致演算法查詢效率下降的話,我們就可以限制查詢時進行回溯的次數上限,從而避免查詢效率下降。這樣做有兩個問題需要解決:1)最大回溯次數怎麼確 定?2)怎樣保證在最大回溯次數內找到的最近鄰比較接近真實最近鄰,即查詢準確度不能下降太大。
問題1):最大回溯次數怎麼確定?
最大回溯次數一般人為設定,通常根據在資料集上的實驗結果進行調整。
問題2):怎樣保證在最大回溯次數內找到的最近鄰比較接近真實最近鄰,即查詢準確度不能下降太大?
限制回溯次數後,如果我們還是按照原來的回溯方法挨個地進行訪問的話,那很顯 然最後的查詢結果的精度就很大程度上取決於資料的分佈和回溯次數了。挨個訪問的方法的問題在於認為每個待回溯的樹分支中存在最近鄰的概率是一樣的,所以它 對所有的待回溯樹分支一視同仁。實際上,在這些待回溯樹分支中,有些樹分支存在最近鄰的可能性比其他樹分支要高,因為樹分支離Q點之間的距離或相交程度是 不一樣的,離Q更近的樹分支存在Q的最近鄰的可能性更高。因此,我們需要區別對待每個待回溯的樹分支,即採用某種優先順序順序來訪問這些待回溯樹分支,使得 在有限的回溯次數中找到Q的最近鄰的可能性很高。我們要介紹的BBF演算法正是基於這樣的解決思路,下面我們介紹BBF查詢演算法。
基於BBF的Kd-Tree近似最近鄰查詢演算法
已知:
Q:查詢資料; KT:已建好的Kd-Tree;
1. 查詢Q的當前最近鄰點P
1)從KT的根結點開始,將Q與中間結點node(k,m)進行比較,根據比較結果選擇某個樹分支Branch(或稱為Bin);並將未被選擇的另一個樹分支(Unexplored Branch)所在的樹中位置和它跟Q之間的距離一起儲存到一個優先順序佇列中Queue;
2)按照步驟1)的過程,對樹分支Branch進行如上比較和選擇,直至訪問到葉子結點,然後計算Q與葉子結點中儲存的資料之間的距離,並記錄下最小距離D以及對應的資料P。
注:
A、Q與中間結點node(k,m)的比較過程:如果Q(k) > m則選擇右子樹,否則選擇左子樹。
B、優先順序佇列:按照距離從小到大的順序排列。
C、葉子結點:每個葉子結點中儲存的資料的個數可能是一個或多個。
2. 基於BBF的回溯
已知:最大回溯次數BTmax
1)如果當前回溯的次數小於BTmax,且Queue不為空,則進行如下操作:
從Queue中取出最小距離對應的Branch,然後按照1.1步驟訪問該Branch直至達到葉子結點;計算Q與葉子結點中各個資料間距離,如果有比D更小的值,則將該值賦給D,該資料則被認為是Q的當前近似最近鄰點;
2)重複1)步驟,直到回溯次數大於BTmax或Queue為空時,查詢結束,此時得到的資料P和距離D就是Q的近似最近鄰點和它們之間的距離。
下面用一個簡單的例子來演示基於Kd-Tree+BBF的近似最近鄰查詢的過程。
資料點集合:(2,3), (4,7), (5,4), (9,6), (8,1), (7,2) 。
已建好的Kd-Tree:
圖6 構建的kd-tree
基於BBF的查詢的過程:
查詢點Q: (5.5, 5)
第一遍查詢:
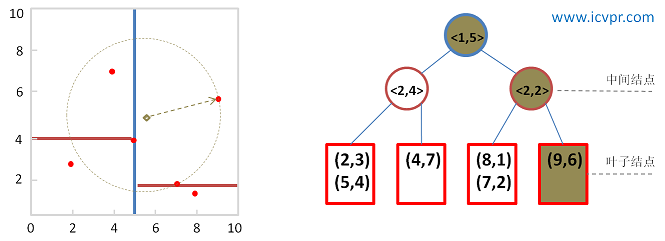
圖7 第一次查詢的kd-tree
當前最近鄰點: (9, 6) , 最近鄰距離: sqrt(13.25),
同時將未被選擇的樹分支的位置和與Q的距離記錄到優先順序佇列中。
BBF回溯:
從優先順序佇列裡選擇距離Q最近的未被選擇樹分支進行回溯。
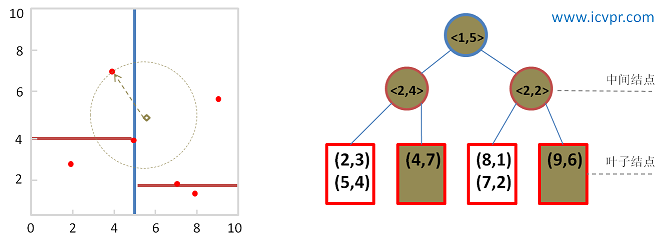
圖8 利用BBF方法回溯kd-tree
當前最近鄰點: (4, 7) , 最近鄰距離: sqrt(6.25)
繼續從優先順序佇列裡選擇距離Q最近的未被選擇樹分支進行回溯。
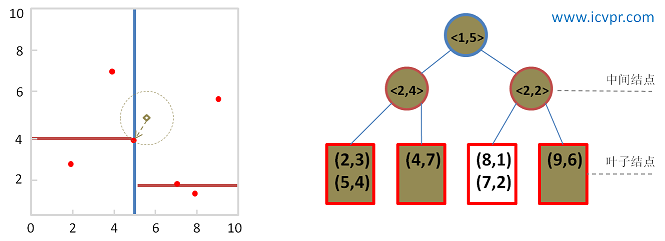
圖9 利用BBF方法回溯kd-tree
當前最近鄰點: (5, 4) , 最近鄰距離: sqrt(1.25)
最後,查詢點(5.5, 5)的近似最近鄰點為(5, 4) 。
三、參考文獻
Paper
[1] Multidimensional binary search trees used for associative searching
[2] Shape indexing using approximate nearest-neighbour search in high-dimensional spaces
Tutorial
[1] An introductory tutorial on kd trees
[2] Nearest-Neighbor Methods in Learning and Vision: Theory and Practice
Website
[1] wiki: http://en.wikipedia.org/wiki/K-d_tree
Code
[1] OpenCV
FLANN
[2] VLFeat
[3] FLANN
[4] KD-Tree Implementation in Java and C#
[5] C/C++
相關文章
- AsyncTask實現程式碼原理
- 常見排序演算法原理及JS程式碼實現排序演算法JS
- DES原理及程式碼實現
- vysor原理與程式碼實現
- IM敏感詞演算法原理和實現演算法
- 開源中國系列六:一行程式碼實現開源中國登入行程
- Python程式碼實現雙色球原理Python
- ConcurrentHashMap 實現原理和原始碼分析HashMap原始碼
- Rainbond 對接 Istio 原理講解和程式碼實現分析AI
- MVVM雙向繫結機制的原理和程式碼實現MVVM
- 排序演算法原理總結和Python實現排序演算法Python
- Cheeper:《CQRS By Example》一書的參考程式碼開源實現
- 將強化學習引入NLP:原理、技術和程式碼實現強化學習
- HTML程式碼混淆技術:原理、應用和實現方法詳解HTML
- UDP內網穿透和打洞原理的C語言程式碼實現UDP內網穿透C語言
- Java實現SSH模式加密原理及程式碼Java模式加密
- UITableView的原理——探究及重新實現程式碼UIView
- 第十四篇:Apriori 關聯分析演算法原理分析與程式碼實現演算法
- 【機器學習】:Kmeans均值聚類演算法原理(附帶Python程式碼實現)機器學習聚類演算法Python
- Struts2遠端程式碼執行漏洞檢測的原理和程式碼級實現
- 自動安裝程式的實現演算法和原始碼 (轉)演算法原始碼
- AES和DES程式碼實現
- 感知機演算法(PLA)程式碼實現演算法
- Svm演算法原理及實現演算法
- OutputStreamWriter介紹&程式碼實現和InputStreamReader介紹&程式碼實現
- 第四篇:決策樹分類演算法原理分析與程式碼實現演算法
- 《機器學習:演算法原理和程式設計實踐》4:推薦系統原理機器學習演算法程式設計
- 用程式碼探討KVC/KVO的實現原理
- 用程式碼探討 KVC/KVO 的實現原理
- Base64加密解密原理以及程式碼實現加密解密
- Android 熱更新實現原理及程式碼分析Android
- JavaScript:十大排序的演算法思路和程式碼實現JavaScript排序演算法
- Facebook開源演算法程式碼庫PySlowFast,輕鬆復現前沿視訊理解模型演算法AST模型
- DES演算法C++程式碼實現-密碼學演算法C++密碼學
- 圖解Dijkstra演算法+程式碼實現圖解演算法
- 機器學習系列文章:Apriori關聯規則分析演算法原理分析與程式碼實現機器學習演算法
- 第十三篇:K-Means 聚類演算法原理分析與程式碼實現聚類演算法
- 從微信小程式開發者工具原始碼看實現原理(二)- - 小程式技術實現微信小程式原始碼