記憶體管理概述、記憶體分配與釋放、地址對映機制(mm_struct, vm_area_struct)、malloc/free 的實現
注:本分類下文章大多整理自《深入分析linux核心原始碼》一書,另有參考其他一些資料如《linux核心完全剖析》、《linux c 程式設計一站式學習》等,只是為了更好地理清系統程式設計和網路程式設計中的一些概念性問題,並沒有深入地閱讀分析原始碼,我也是草草翻過這本書,請有興趣的朋友自己參考相關資料。此書出版較早,分析的版本為2.4.16,故出現的一些概念可能跟最新版本核心不同。
此書已經開源,閱讀地址 http://www.kerneltravel.net
一、記憶體管理概述
(一)、虛擬記憶體實現結構





(1)記憶體對映模組(mmap):負責把磁碟檔案的邏輯地址對映到虛擬地址,以及把虛擬地址對映到實體地址。
(2)交換模組(swap):負責控制記憶體內容的換入和換出,它通過交換機制,使得在物理記憶體的頁面(RAM 頁)中保留有效的頁 ,即從主存中淘汰最近沒被訪問的頁,儲存近來訪問過的頁。
(3)核心記憶體管理模組(core):負責核心記憶體管理功能,即對頁的分配、回收、釋放及請頁處理等,這些功能將被別的核心子系統(如檔案系統)使用。
(4)結構特定的模組:負責給各種硬體平臺提供通用介面,這個模組通過執行命令來改變硬體MMU 的虛擬地址對映,並在發生頁錯誤時,提供了公用的方法來通知別的核心子系統。這個模組是實現虛擬記憶體的物理基礎。
(二)、核心空間和使用者空間
Linux 簡化了分段機制,使得虛擬地址與線性地址總是一致,因此,Linux 的虛擬地址空間也為0~4G 位元組。Linux 核心將這4G 位元組的空間分為兩部分。將最高的1G
位元組(從虛擬地址0xC0000000 到0xFFFFFFFF),供核心使用,稱為“核心空間”。而將較低的3G 位元組(從虛擬地址0x00000000 到0xBFFFFFFF),供各個程式使用,稱為“使用者空間”。因為每個程式可以通過系統呼叫進入核心,因此,Linux 核心由系統內的所有程式共享。於是,從具體程式的角度來看,每個程式可以擁有4G
位元組的虛擬空間。圖 6.3 給出了程式虛擬空間示意圖。
Linux 使用兩級保護機制:0 級供核心使用,3 級供使用者程式使用。從圖6.3 中可以看出,每個程式有各自的私有使用者空間(0~3G),這個空間對系統中的其他程式是不可見的。最高的1G
位元組虛擬核心空間則為所有程式以及核心所共享。
(三)、虛擬記憶體實現機制間的關係
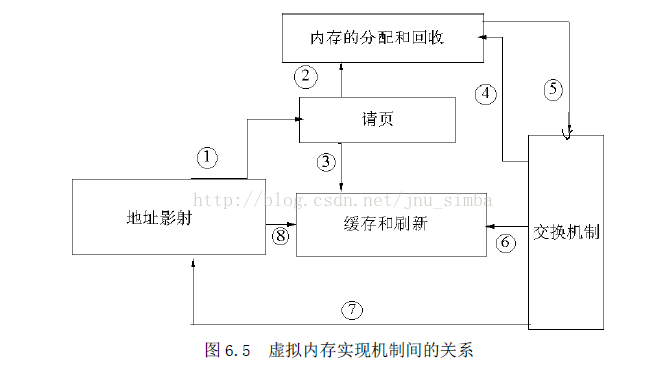
首先記憶體管理程式通過對映機制把使用者程式的邏輯地址對映到實體地址,在使用者程式運行時如果發現程式中要用的虛地址沒有對應的實體記憶體時,就發出了請頁要求①;如果有空閒的記憶體可供分配,就請求分配記憶體②(於是用到了記憶體的分配和回收),並把正在使用的物理頁記錄在頁快取中③(使用了快取機制)。如果沒有足夠的記憶體可供分配,那麼就呼叫交換機制,騰出一部分記憶體④⑤。另外在地址對映中要通過TLB(翻譯後援儲存器)來尋找物理頁⑧;交換機制中也要用到交換快取⑥,並且把物理頁內容交換到交換檔案中後也要修改頁表來對映檔案地址⑦。
二、記憶體分配與釋放
在Linux 中,CPU 不能按實體地址來訪問儲存空間,而必須使用虛擬地址;因此,對於記憶體頁面的管理,通常是先在虛存空間中分配一個虛存區間,然後才根據需要為此區間分配相應的物理頁面並建立起對映,也就是說,虛存區間的分配在前,而物理頁面的分配在後。
(一)、夥伴演算法(Buddy)
Linux 的夥伴演算法把所有的空閒頁面分為10 個塊組,每組中塊的大小是2 的冪次方個頁面,例如,第0 組中塊的大小都為2^0(1
個頁面),第1 組中塊的大小都為2^1(2 個頁面),第9 組中塊的大小都為2^9(512
個頁面)。也就是說,每一組中塊的大小是相同的,且這同樣大小的塊形成一個連結串列。
我們通過一個簡單的例子來說明該演算法的工作原理。
假設要求分配的塊的大小為128 個頁面(由多個頁面組成的塊我們就叫做頁面塊)。該演算法先在塊大小為128 個頁面的連結串列中查詢,看是否有這樣一個空閒塊。如果有,就直接分配;如果沒有,該演算法會查詢下一個更大的塊,具體地說,就是在塊大小256
個頁面的連結串列中查詢一個空閒塊。如果存在這樣的空閒塊,核心就把這256 個頁面分為兩等份,一份分配出去,另一份插入到塊大小為128 個頁面的連結串列中。如果在塊大小為256 個頁面的連結串列中也沒有找到空閒頁塊,就繼續找更大的塊,即512
個頁面的塊。如果存在這樣的塊,核心就從512 個頁面的塊中分出128 個頁面滿足請求,然後從384 個頁面中取出256 個頁面插入到塊大小為256 個頁面的連結串列中。然後把剩餘的128 個頁面插入到塊大小為128 個頁面的連結串列中。如果512
個頁面的連結串列中還沒有空閒塊,該演算法就放棄分配,併發出出錯訊號。
以上過程的逆過程就是塊的釋放過程,這也是該演算法名字的來由。滿足以下條件的兩個塊稱為夥伴:
(1)兩個塊的大小相同;
(2)兩個塊的實體地址連續。
夥伴演算法把滿足以上條件的兩個塊合併為一個塊,該演算法是迭代演算法,如果合併後的塊還可以跟相鄰的塊進行合併,那麼該演算法就繼續合併。
(二)、Slab 分配機制
可以根據對記憶體區的使用頻率來對它分類。對於預期頻繁使用的記憶體區,可以建立一組特定大小的專用緩衝區進行處理,以避免內碎片的產生。對於較少使用的記憶體區,可以建立一組通用緩衝區(如Linux
2.0 中所使用的2 的冪次方)來處理,即使這種處理模式產生碎
片,也對整個系統的效能影響不大。
硬體快取記憶體的使用,又為儘量減少對夥伴演算法的呼叫提供了另一個理由,因為對夥伴演算法的每次呼叫都會“弄髒”硬體快取記憶體,因此,這就增加了對記憶體的平均訪問次數。
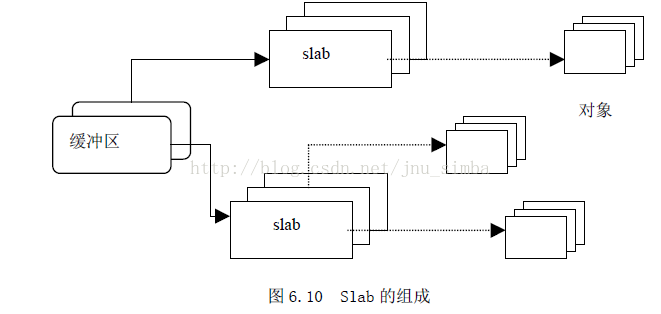
Slab 分配模式把物件分組放進緩衝區(儘管英文中使用了Cache 這個詞,但實際上指的是記憶體中的區域,而不是指硬體快取記憶體)。因為緩衝區的組織和管理與硬體快取記憶體的命中率密切相關,因此,Slab
緩衝區並非由各個物件直接構成,而是由一連串的“大塊(Slab)”構成,而每個大塊中則包含了若干個同種型別的物件,這些物件或已被分配,或空閒,如圖6.10 所示。一般而言,物件分兩種,一種是大物件,一種是小物件。所謂小物件,是指在一個頁面中可以容納下好幾個物件的那種。例如,一個inode
結構大約佔300 多個位元組,因此,一個頁面中可以容納8 個以上的inode 結構,因此,inode 結構就為小物件。Linux 核心中把小於512 位元組的物件叫做小物件。
實際上,緩衝區就是主存中的一片區域,把這片區域劃分為多個塊,每塊就是一個Slab,每個Slab 由一個或多個頁面組成,每個Slab 中存放的就是物件。
三、地址對映機制
在程式的task_struct 結構中包含一個指向 mm_struct 結構的指標,mm_strcut
用來描述一個程式的虛擬地址空間。程式的 mm_struct 則包含裝入的可執行映像資訊以及程式的頁目錄指標pgd。該結構還包含有指向 vm_area_struct 結構的幾個指標,每個
vm_area_struct 代表程式的一個虛擬地址區間。vm_area_struct 結構含有指向vm_operations_struct 結構的一個指標,vm_operations_struct 描述了在這個區間的操作。vm_operations
結構中包含的是函式指針;其中,open、close 分別用於虛擬區間的打開、關閉,而nopage 用於當虛存頁面不在實體記憶體而引起的“缺頁異常”時所應該呼叫的函數,當
Linux 處理這一缺頁異常時(請頁機制),就可以為新的虛擬記憶體區分配實際的實體記憶體。圖6.15 給出了虛擬區間的操作集。
C++ Code
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
struct mm_struct
{ struct vm_area_struct *mmap; /* list of VMAs */ struct rb_root mm_rb; struct vm_area_struct *mmap_cache; /* last find_vma result */ ... unsigned long start_code, end_code, start_data, end_data; unsigned long start_brk, brk, start_stack; ... }; struct vm_area_struct { struct mm_struct *vm_mm; /* The address space we belong to. */ unsigned long vm_start; /* Our start address within vm_mm. */ unsigned long vm_end; /* The first byte after our end address within vm_mm. */ .... /* linked list of VM areas per task, sorted by address */ struct vm_area_struct *vm_next; .... /* describe the permissable operation */ unsigned long vm_flags; /* operations on this area */ struct vm_operations_struct * vm_ops; struct file * vm_file; /* File we map to (can be NULL). */ } ; /* * These are the virtual MM functions - opening of an area, closing and * unmapping it (needed to keep files on disk up-to-date etc), pointer * to the functions called when a no-page or a wp-page exception occurs. */ struct vm_operations_struct { void (*open)(struct vm_area_struct *area); void (*close)(struct vm_area_struct *area); struct page * (*nopage)(struct vm_area_struct * area, unsigned long address, int unused); }; |
四、malloc 和 free 的實現
C++ Code
|
1
2 3 4 5 6 7 8 9 10 |
Normally, malloc() allocates memory from the heap, and adjusts the size of the heap as required, using sbrk(2). When
allocating blocks of memory larger than MMAP_THRESHOLD bytes, the glibc malloc() implementation allocates the memory as a private anonymous mapping using mmap(2). MMAP_THRESHOLD is 128 kB by default, but is adjustable using mallopt(3). Allo‐ cations performed using mmap(2) are unaffected by the RLIMIT_DATA resource limit (see getrlimit(2)). MAP_ANONYMOUS The mapping is not backed by any file; its contents are initialized to zero. The fd and offset arguments are ignored; however, some implementations require fd to be - 1 if MAP_ANONYMOUS ( or MAP_ANON) is specified, and portable applications should ensure this. The use of MAP_ANONYMOUS in conjunction with MAP_SHARED is only supported on Linux since kernel 2.4. |
每一次 malloc 的記憶體都比較大(大於128KB)時,都會呼叫 mmap 來完成,可能是系統效能降低的一個點。
(一)、使用brk()/ sbrk() 實現

圖中白色背景的框表示 malloc管理的空閒記憶體塊,深色背景的框不歸 malloc管,可能是已經分配給使用者的記憶體塊,也可能不屬於當前程式, Break之上的地址不屬於當前程式,需要通過 brk系統呼叫向核心申請。每個記憶體塊開頭都有一個頭節點,裡面有一個指標欄位和一個長度欄位,指標欄位把所有空閒塊的頭節點串在一起,組成一個環形連結串列,長度欄位記錄著頭節點和後面的記憶體塊加起來一共有多長,以 8位元組為單位(也就是以頭節點的長度為單位)。
1. 一開始堆空間由一個空閒塊組成,長度為 7×8=56位元組,除頭節點之外的長度為 48位元組。
2. 呼叫 malloc分配 8個位元組,要在這個空閒塊的末尾截出 16個位元組,其中新的頭節點佔了 8個位元組,另外 8個位元組返回給使用者使用,注意返回的指標 p1指向頭節點後面的記憶體塊。
3. 又呼叫 malloc分配 16個位元組,又在空閒塊的末尾截出 24個位元組,步驟和上一步類似。
4. 呼叫 free釋放 p1所指向的記憶體塊,記憶體塊(包括頭節點在內)歸還給了 malloc,現在 malloc管理著兩塊不連續的記憶體,用環形連結串列串起來。注意這時 p1成了野指標,指向不屬於使用者的記憶體, p1所指向的記憶體地址在 Break之下,是屬於當前程式的,所以訪問 p1時不會出現段錯誤,但在訪問 p1時這段記憶體可能已經被 malloc再次分配出去了,可能會讀到意外改寫資料。另外注意,此時如果通過 p2向右寫越界,有可能覆蓋右邊的頭節點,從而破壞 malloc管理的環形連結串列, malloc就無法從一個空閒塊的指標欄位找到下一個空閒塊了,找到哪去都不一定,全亂套了。
5. 呼叫 malloc分配 16個位元組,現在雖然有兩個空閒塊,各有 8個位元組可分配,但是這兩塊不連續, malloc只好通過 brk系統呼叫抬高 Break,獲得新的記憶體空間。在 [K&R]的實現中,每次呼叫 sbrk函式時申請 1024×8=8192個位元組,在 Linux系統上 sbrk函式也是通過 brk實現的,這裡為了畫圖方便,我們假設每次呼叫 sbrk申請 32個位元組,建立一個新的空閒塊。
6. 新申請的空閒塊和前一個空閒塊連續,因此可以合併成一個。在能合併時要儘量合併,以免空閒塊越割越小,無法滿足大的分配請求。
7. 在合併後的這個空閒塊末尾截出 24個位元組,新的頭節點佔 8個位元組,另外 16個位元組返回給使用者。
8. 呼叫 free(p3)釋放這個記憶體塊,由於它和前一個空閒塊連續,又重新合併成一個空閒塊。注意, Break只能抬高而不能降低,從核心申請到的記憶體以後都歸 malloc管了,即使呼叫 free也不會還給核心。
(二)、使用mmap() / munmap() 實現
在Linux下面,kernel 使用4096 byte來劃分頁面,而malloc的顆粒度更細,使用8 byte對齊,因此,分配出來的記憶體不一定是頁對齊的。而mmap 分配出來的記憶體地址是頁對齊的,所以munmap處理的記憶體地址必須頁對齊(Page Aligned)。此外,我們可以使用memalign或是posix_memalign來獲取一塊頁對齊的記憶體。
可以參考《linux的記憶體管理模型(上)》這篇文章。
擴充套件閱讀 http://blog.codinglabs.org/articles/a-malloc-tutorial.html
相關文章
- 記憶體的分配與釋放,記憶體洩漏記憶體
- 記憶體動態分配與釋放,malloc和new區別記憶體
- C/C++使用malloc為結構體陣列分配記憶體(及free釋放記憶體)的三種方法C++結構體陣列記憶體
- vector 避免記憶體頻繁分配釋放與手動釋放vector記憶體記憶體
- Linux 記憶體管理:記憶體對映Linux記憶體
- 【記憶體管理】頁面分配機制記憶體
- 記憶體管理 記憶體管理概述記憶體
- Python如何管理記憶體?記憶體分配機制是什麼?Python記憶體
- golang 釋放記憶體機制的探索Golang記憶體
- 關於c語言記憶體分配,malloc,free,和段錯誤,記憶體洩露C語言記憶體洩露
- 垃圾收集機制與記憶體分配策略記憶體
- 理解 glibc 記憶體分配器的機制與實現記憶體
- linux記憶體管理(一)實體記憶體的組織和記憶體分配Linux記憶體
- 記憶體對映記憶體
- jvm:記憶體模型、記憶體分配及GC垃圾回收機制JVM記憶體模型GC
- Linux記憶體管理:MallocLinux記憶體
- C/C++記憶體分配以及釋放C++記憶體
- java基礎:記憶體分配機制Java記憶體
- [CareerCup] 13.9 Aligned Malloc and Free Function 寫一對申請和釋放記憶體函式Function記憶體函式
- dm8127 記憶體分配和管理機制記憶體
- mmap記憶體對映記憶體
- javaScript 記憶體管理機制JavaScript記憶體
- Java記憶體管理機制Java記憶體
- Qt 記憶體管理機制QT記憶體
- jvm記憶體管理機制JVM記憶體
- [Virtualization]ESXi體系結構與記憶體管理(二)控制記憶體分配記憶體
- [Virtualization]ESXi體系結構與記憶體管理(三)控制記憶體分配記憶體
- 記憶體管理篇——實體記憶體的管理記憶體
- 動態分配記憶體地址(.NET)記憶體
- AntDB記憶體管理之記憶體上下文之記憶體上下文機制是怎麼實現的記憶體
- 垃圾收集器與記憶體分配策略_記憶體分配策略記憶體
- 01記憶體管理-概述記憶體
- C語言-記憶體管理之一[記憶體分配]C語言記憶體
- MySQL • 原始碼分析 • 記憶體分配機制MySql原始碼記憶體
- 記憶體分配詳解 malloc, new, HeapAlloc, VirtualAlloc,GlobalAlloc記憶體
- Redis的記憶體和實現機制Redis記憶體
- vector 的記憶體釋放記憶體
- Java的記憶體管理機制之記憶體區域劃分Java記憶體