最優化之無約束優化
轉自:http://blog.csdn.net/mytestmy/article/details/16903537
1.1問題定義
1.1.1優化問題定義
最優化問題數學上定義,最優化問題的一般形式為
其中的是自變數,f(x)是目標函式,
為約束集或者說可行域。
可行域這個東西,有等式約束,也有不等式約束,或者沒有約束,這次的精力主要還是集中在無約束的優化問題上,如果有精力,再討論有約束的。
1.1.2最優化方法定義
優化問題的解法叫最優化方法。最優化方法通常採用迭代的方法求它的最優解,其基本思想是:給定一個初始點
好吧,上面是一堆描述,來點定義,設為第k次迭代點,
第k次搜尋方向,
為第k次步長因子,則第k次迭代為
(2)
然後後面的工作幾乎都在調整這個項了,不同的步長
和不同的搜尋方向
分別構成了不同的方法。
當然步長和搜尋方向
是得滿足一些條件,畢竟是求最小值,不能越迭代越大了,下面是一些條件
(3)
(4)
式子(3)的意義是搜尋方向必須跟梯度方向(梯度也就是)夾角大於90度,也就是基本保證是向梯度方向的另外一邊搜尋,至於為什麼要向梯度方向的另外一邊搜尋,就是那樣才能保證是向目標函式值更小的方向搜尋的,因為梯度方向一般是使目標函式增大的(不增大的情況是目標函式已經到達極值)。
式子(4)的意義就很明顯了,迭代的下一步的目標函式比上一步小。
最優化方法的基本結構為:
給定初始點,
(a) 確定搜尋方向,即按照一定規則,構造目標函式f在
點處的下降方向作為搜尋方向。
(b) 確定步長因子,使目標函式值有某種意義的下降。
(c) 令
能不能收斂到最優解是衡量最優化演算法的有效性的一個重要方面。
1.1.3收斂速度簡介
收斂速度也是衡量最優化方法有效性的一個重要方面。
設演算法產生的迭代點列在某種範數意義下收斂,即
(5)
若存在實數(這個
不是步長)以及一個與迭代次數k無關的常數
,使得
(6)
(a) 當,
時,迭代點列
叫做具有Q-線性收斂速度;
(b) 當,q>0時或
,q=0時,迭代點列
叫做具有Q-超線性收斂速度;
(c) 當時,迭代點列
叫做具有Q-二階收斂速度;
一般認為,具有超線性收斂速度和二階收斂速度的方法是比較快速的。但是對於一個演算法,收斂性和收斂速度的理論結果並不保證演算法在實際執行時一定有好的實際計算特性。一方面是由於這些結果本身並不能保證方法一定有好的特性,另一方面是由於演算法忽略了計算過程中十分重要的舍入誤差的影響。
1.2步長確定
1.2.1一維搜尋
如前面的討論,優化方法的關鍵是構造搜尋方向
設
這樣,從x_k出發,沿搜尋方向,確定步長因子
,使得
的問題就是關於α的一維搜尋問題。注意這裡是假設其他的和
都確定了的情況下做的搜尋,要搜尋的變數只有α。
如果求得的,使得目標函式沿搜尋方向
達到最小,即達到下面的情況
或者說
如果能求導這個最優的,那麼這個
就稱為最優步長因子,這樣的搜尋方法就稱為最優一維搜尋,或者精確一維搜尋。
但是現實情況往往不是這樣,實際計算中精確的最優步長因子一般比較難求,工作量也大,所以往往會折中用不精確的一維搜尋。
不精確的一維搜尋,也叫近似一維搜尋。方法是選擇,使得目標函式f得到可接受的下降量,即使得下降量
是使用者可接受的。也就是,只要找到一個步長,使得目標函式下降了一個比較滿意的量就可以了。
為啥要選步長?看下圖,步長選不好,方向哪怕是對的,也是跑來跑去,不往下走,二維的情況簡單點,高維的可能會弄出一直原地不動的情況來。
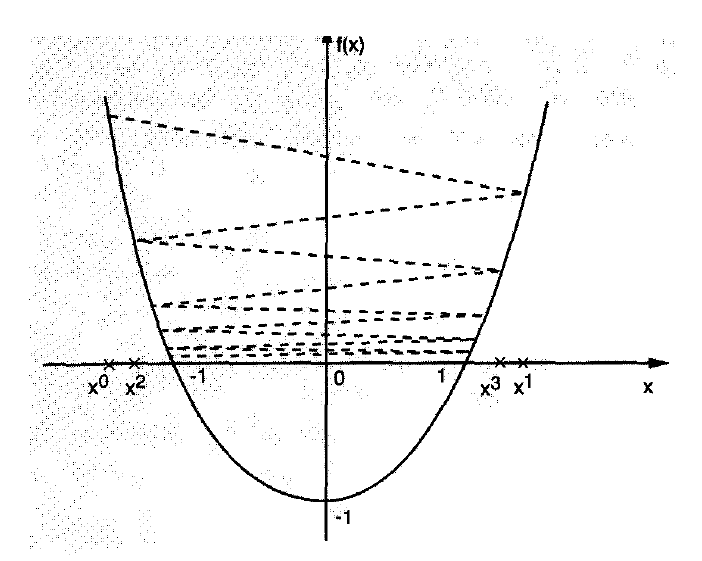
一維搜尋的主要結構如下:1)首先確定包含問題最優解的搜尋區間,再採用某種分割技術或插值方法縮小這個區間,進行搜尋求解。
當然這個搜尋方法主要是適應單峰區間的,就是類似上面的那種,只有一個谷底的。
1.2.1.1確定搜尋區間
確定搜尋區間一般用進退法,思想是從某一點出發,按某步長,確定函式值呈現“高-低-高”的三個點,一個方向不成功,就退回來,沿相反方向尋找。
下面是步驟。
1.2.1.2搜尋求解
搜尋求解的話,0.618法簡單實用。雖然Fibonacci法,插值法等等雖然好,複雜,就不多說了。下面是0.618法的步驟。

普通的0.618法要求一維搜尋的函式是單峰函式,實際上遇到的函式不一定是單峰函式,這時,可能產生搜尋得到的函式值反而大於初始區間端點出函式值的情況。有人建議每次縮小區間是,不要只比較兩個內點處的函式值,而是比較兩內點和兩端點處的函式值。當左邊第一個或第二個點是這四個點中函式值最小的點是,丟棄右端點,構成新的搜尋區間;否則,丟棄左端點,構成新的搜尋區間,經過這樣的修改,演算法會變得可靠些。步驟就不列了。
1.2.2不精確一維搜尋方法
一維搜尋過程是最優化方法的基本組成部分,精確的一維搜尋方法往往需要花費很大的工作量。特別是迭代點遠離問題的解時,精確地求解一個一維子問題通常不是十分有效的。另外,在實際上,很多最優化方法,例如牛頓法和擬牛頓法,其收斂速度並不依賴於精確一維搜尋過程。因此,只要保證目標函式f(x)在每一步都有滿意的下降,這樣就可以大大節省工作量。
有幾位科學家Armijo(1966)和Goldstein(1965)分別提出了不精確一維搜尋過程。設
是一個區間。看下圖
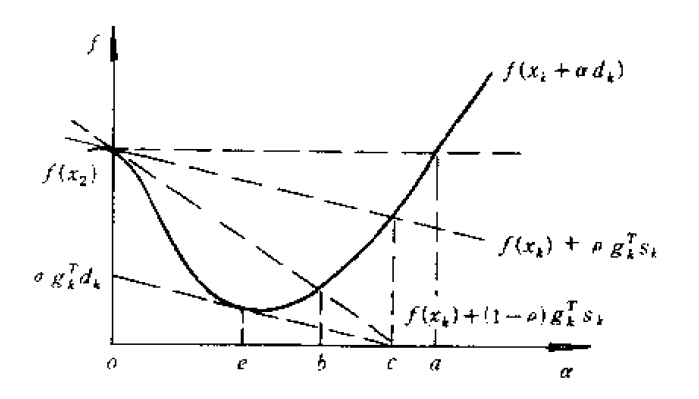
在圖中,區間J=(0,a)。為了保證目標函式單調下降,同時要求f的下降不是太小(如果f的下降太小,可能導致序列的極限值不是極小值),必須避免所選擇的α太靠近區間j的短短。一個合理的要求是
(2.5.2)
(2.5.3)
其中0<ρ<1/2,。滿足(2.5.2)要求的α_k構成區間J_1=(0,c],這就扔掉了區間J右端附件的點。但是為了避免α太小的情況,又加上了另一個要求(2.5.3),這個要求扔掉了區間J的左端點附件的點。看圖中
和
兩條虛線夾出來的區間J_2=[b,c]就是滿足條件(2.5.2)和(2.5.3)的搜尋區間,稱為可接受區間。條件(2.5.2)和(2.5.3)稱為Armijo-Goldstein準則。無論用什麼辦法得到步長因子α,只要滿足條件(2.5.2)和(2.5.3),就可以稱它為可接受步長因子。
其中這個要求是必須的,因為不用這個條件,可能會影響牛頓法和擬牛頓法的超線性收斂。
在圖中可以看到一種情況,極小值e也被扔掉了,為了解決這種情況,Wolfe-Powell準則給出了一個更簡單的條件代替
(2.5.4)
其幾何解釋是在可接受點處切線的斜率大於或等於初始斜率的σ倍。準則(2.5.2)和(2.5.4)稱為Wolfe-Powell準則,其可接受區間為J_3=[e,c]。
要求ρ<σ<1是必要的,它保證了滿足不精確線性搜尋準則的步長因子的存在,不這麼弄,可能
這個虛線會往下壓,沒有交點,就搞不出一個區間來了。
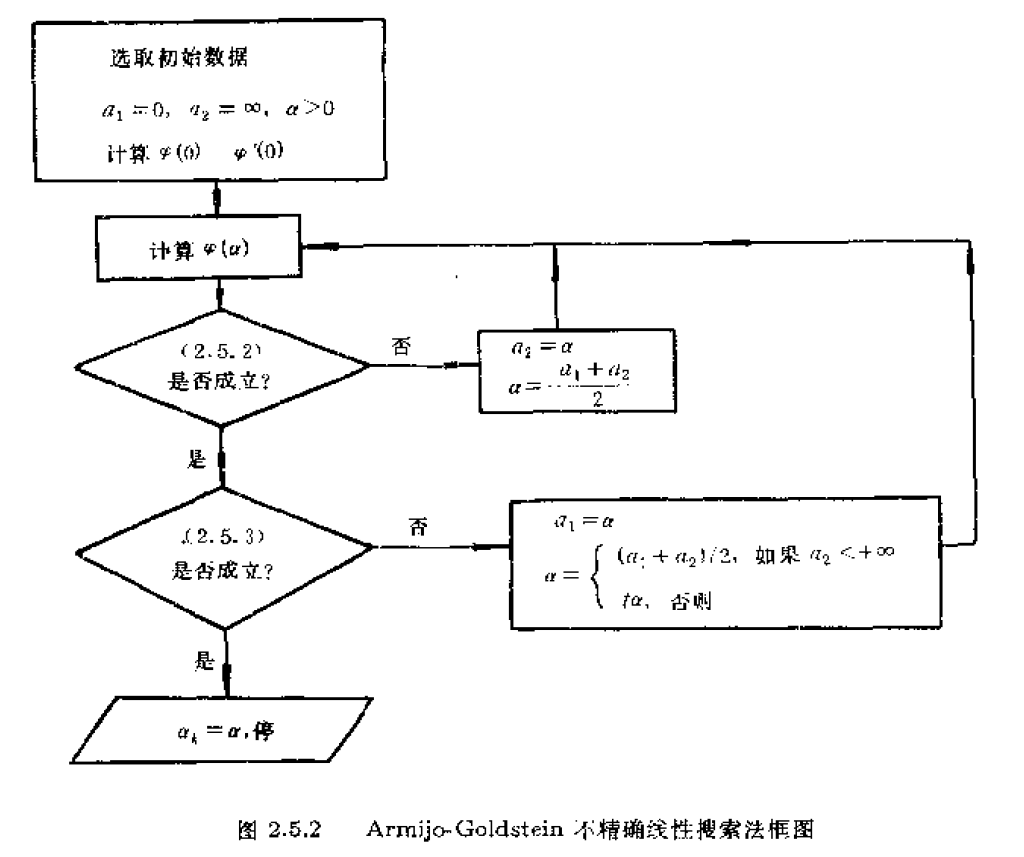
下面就給出Armijo-Goldstein準則和Wolfe-Powell準則的框圖。
從演算法框圖中可以看出,兩種方法是類似的,只是在準則不成立,需要計算新的時,一個利用了簡單的求區間中點的方法,另一個採用了二次插值方法。
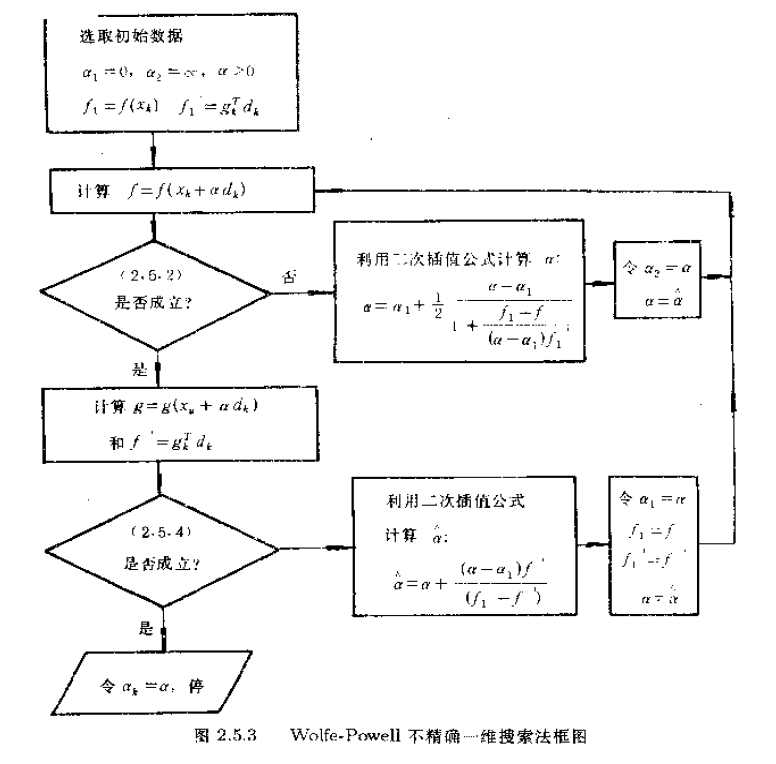
演算法步驟只給出Armijo-Goldstein不精確一維搜尋方法的,下面就是

好了,說到這,確定步長的方法也說完了,其實方法不少,實際用到的肯定是最簡單的幾種,就把簡單的幾種提了一下,至於為什麼這樣,收斂如何,證明的東西大家可以去書中慢慢看。
1.3方向確定
1.3.1最速下降法
最速下降法以負梯度方向作為最優化方法的下降方向,又稱為梯度下降法,是最簡單實用的方法。
1.3.1.1演算法步驟
下面是步驟。

看個例子。
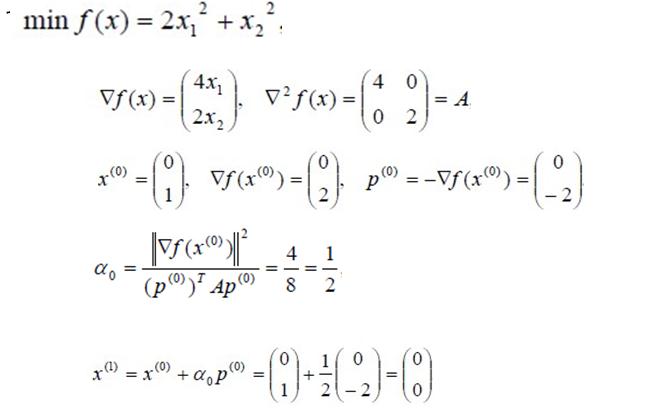
這個選步長的方法是對二次函式下的特殊情況,是比較快而且好的顯式形式,說明步長選得好,收斂很快。
1.3.1.2缺點
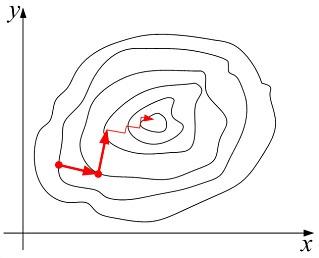
數值實驗表明,當目標函式的等值線接近一個圓(球)時,最速下降法下降較快,當目標函式的等值線是一個扁長的橢球是,最速下降法開始幾步下降較快,後來就出現鋸齒線性,下降就十分緩慢。原因是一維搜尋滿足下圖是鋸齒的一個圖。
1.3.2牛頓法
1.3.2.1演算法思想和步驟
牛頓法的基本思想是利用目標函式的二次Taylor展開,並將其極小化。設f(x)是二次可微實函式,
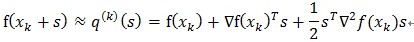
其中,,
為f(x)的二次近似。將上式右邊極小化,便得
這就是牛頓迭代公式。在這個公式中,步長因子。令
,
,則上面的迭代式也可以寫成
。
其中的Hesse矩陣的形式如下。

一個例子如下。
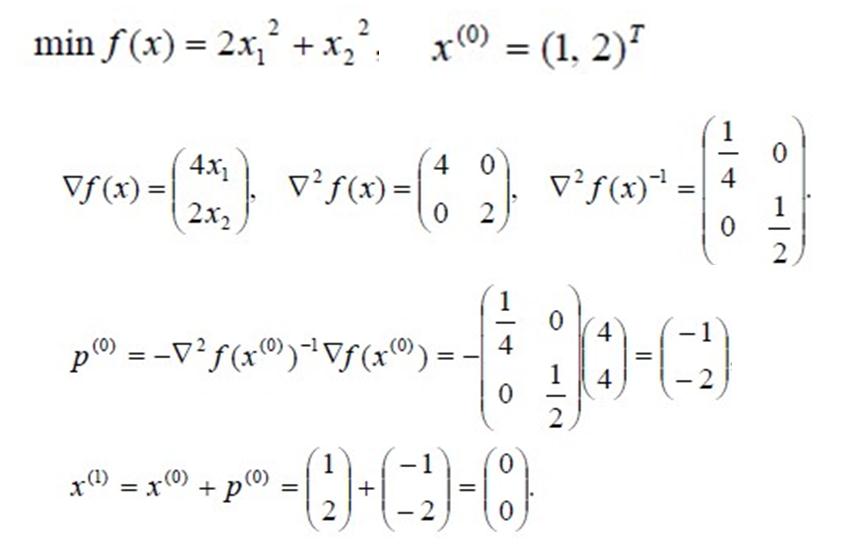
對於正定二次函式,牛頓法一步就可以得到最優解。
對於非二次函式,牛頓法並不能保證經過有限次迭代求得最優解,但由於目標函式在極小點附近近似於二次函式,所以當初始點靠近極小點時,牛頓法的收斂速度一般是快的。
當初始點遠離最優解,不一定正定,牛頓方向不一定是下降方向,其收斂性不能保證,這說明步長一直是1是不合適的,應該在牛頓法中採用某種一維搜尋來確定步長因子。但是要強調一下,僅當步長因子
收斂到1時,牛頓法才是二階收斂的。
這時的牛頓法稱為阻尼牛頓法,步驟如下。

下面看個例子。
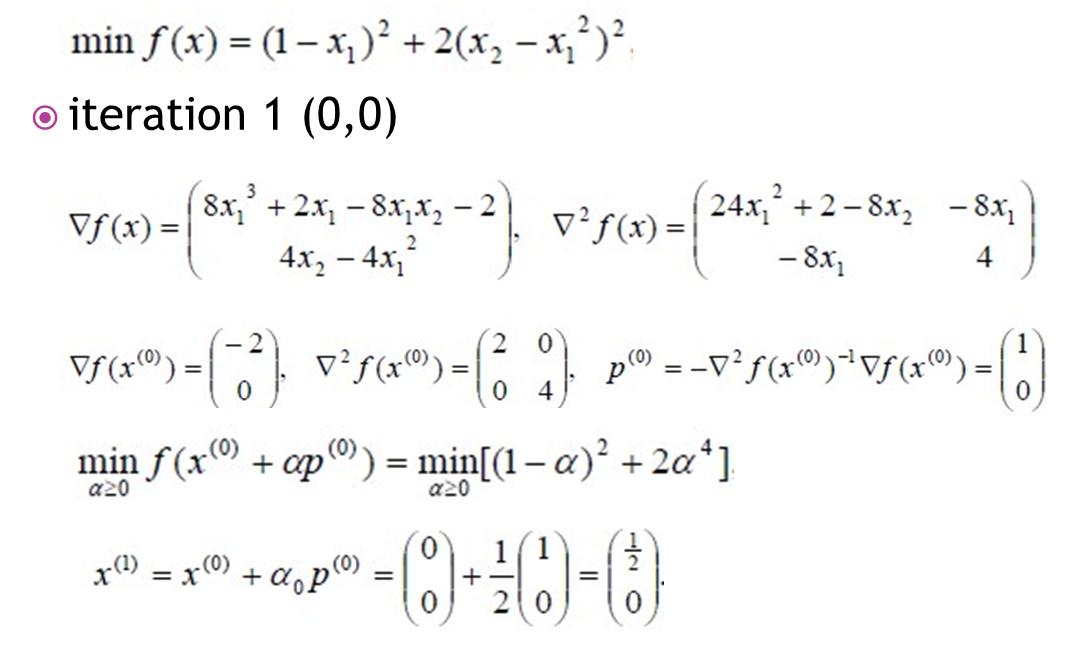

這樣的牛頓法是總體收斂的。
1.3.2.2缺點
牛頓法面臨的主要困難是Hesse矩陣為了克服這種困難,有多種方法,常用的方法是使牛頓方向偏向最速下降方向
1.3.3擬牛頓法
牛頓法在實際應用中需要儲存二階導數資訊和計算一個矩陣的逆,這對計算機的時間和空間要求都比較高,也容易遇到不正定的Hesse矩陣和病態的Hesse矩陣,導致求出來的逆很古怪,從而演算法會沿一個不理想的方向去迭代。
有人提出了介於最速下降法與牛頓法之間的方法。一類是共軛方向法,典型的是共軛梯度法,還有擬牛頓法。
其中擬牛頓法簡單實用,這裡就特地介紹,其他方法感興趣的讀者可以去看相關資料。
1.3.3.1演算法思想和步驟
牛頓法的成功的關鍵是利用了Hesse矩陣提供的曲率資訊。但是計算Hesse矩陣工作量大,並且有些目標函式的Hesse矩陣很難計算,甚至不好求出,這就使得僅利用目標函式的一階導數的方法更受歡迎。擬牛頓法就是利用目標函式值f和一階導數g(梯度)的資訊,構造出目標函式的曲率近似,而不需要明顯形成Hesse矩陣,同時具有收斂速度快的特點。設
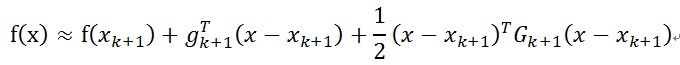
兩邊求導,得
令,得
其中,是梯度。那麼,只要構造出Hesse矩陣的逆近似
滿足這種上式就可以,即滿足關係
這個關係就是擬牛頓條件或擬牛頓方程。
擬牛頓法的思想就是——用一個矩陣去近似Hesse矩陣的逆矩陣,這樣就避免了計算矩陣的逆。
當然需要滿足一些條件:
(a) 是一個正定的矩陣
(b) 如果存在,則
。
(c) 初始正定矩陣取定後,
應該由
遞推給出,即
;其中
是修正矩陣,
是修正公式。
常用而且有效的修正公式是BFGS公式,如下
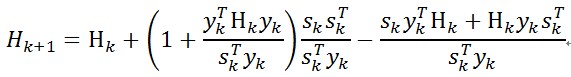
下面給出BFGS公式下的擬牛頓法

在上述步驟中,初始正定矩陣通常取為單位矩陣,即
。這樣,擬牛頓法的第一次迭代相當於一個最速下降迭代。
1.3.3.2優缺點
與牛頓法相比,有兩個優點:
(a) 僅需一階導數
(b) 校正保持正定性,因而下降性質成立
(c) 無需計算逆矩陣,但具有超線性收斂速度
(d) 每次迭代僅需要次乘法計算
缺點是初始點距離最優解遠時速度還是慢。
解決方法是,迭代前期用最速下降法進行迭代,得到一定解以後用擬牛頓法迭代。
1.1問題定義
1.1.1優化問題定義
最優化問題數學上定義,最優化問題的一般形式為
其中的是自變數,f(x)是目標函式,
為約束集或者說可行域。
可行域這個東西,有等式約束,也有不等式約束,或者沒有約束,這次的精力主要還是集中在無約束的優化問題上,如果有精力,再討論有約束的。
1.1.2最優化方法定義
優化問題的解法叫最優化方法。最優化方法通常採用迭代的方法求它的最優解,其基本思想是:給定一個初始點
好吧,上面是一堆描述,來點定義,設為第k次迭代點,
第k次搜尋方向,
為第k次步長因子,則第k次迭代為
(2)
然後後面的工作幾乎都在調整這個項了,不同的步長
和不同的搜尋方向
分別構成了不同的方法。
當然步長和搜尋方向
是得滿足一些條件,畢竟是求最小值,不能越迭代越大了,下面是一些條件
(3)
(4)
式子(3)的意義是搜尋方向必須跟梯度方向(梯度也就是)夾角大於90度,也就是基本保證是向梯度方向的另外一邊搜尋,至於為什麼要向梯度方向的另外一邊搜尋,就是那樣才能保證是向目標函式值更小的方向搜尋的,因為梯度方向一般是使目標函式增大的(不增大的情況是目標函式已經到達極值)。
式子(4)的意義就很明顯了,迭代的下一步的目標函式比上一步小。
最優化方法的基本結構為:
給定初始點,
(a) 確定搜尋方向,即按照一定規則,構造目標函式f在
點處的下降方向作為搜尋方向。
(b) 確定步長因子,使目標函式值有某種意義的下降。
(c) 令
能不能收斂到最優解是衡量最優化演算法的有效性的一個重要方面。
1.1.3收斂速度簡介
收斂速度也是衡量最優化方法有效性的一個重要方面。
設演算法產生的迭代點列在某種範數意義下收斂,即
(5)
若存在實數(這個
不是步長)以及一個與迭代次數k無關的常數
,使得
(6)
(a) 當,
時,迭代點列
叫做具有Q-線性收斂速度;
(b) 當,q>0時或
,q=0時,迭代點列
叫做具有Q-超線性收斂速度;
(c) 當時,迭代點列
叫做具有Q-二階收斂速度;
一般認為,具有超線性收斂速度和二階收斂速度的方法是比較快速的。但是對於一個演算法,收斂性和收斂速度的理論結果並不保證演算法在實際執行時一定有好的實際計算特性。一方面是由於這些結果本身並不能保證方法一定有好的特性,另一方面是由於演算法忽略了計算過程中十分重要的舍入誤差的影響。
1.2步長確定
1.2.1一維搜尋
如前面的討論,優化方法的關鍵是構造搜尋方向
設
這樣,從x_k出發,沿搜尋方向,確定步長因子
,使得
的問題就是關於α的一維搜尋問題。注意這裡是假設其他的和
都確定了的情況下做的搜尋,要搜尋的變數只有α。
如果求得的,使得目標函式沿搜尋方向
達到最小,即達到下面的情況
或者說
如果能求導這個最優的,那麼這個
就稱為最優步長因子,這樣的搜尋方法就稱為最優一維搜尋,或者精確一維搜尋。
但是現實情況往往不是這樣,實際計算中精確的最優步長因子一般比較難求,工作量也大,所以往往會折中用不精確的一維搜尋。
不精確的一維搜尋,也叫近似一維搜尋。方法是選擇,使得目標函式f得到可接受的下降量,即使得下降量
是使用者可接受的。也就是,只要找到一個步長,使得目標函式下降了一個比較滿意的量就可以了。
為啥要選步長?看下圖,步長選不好,方向哪怕是對的,也是跑來跑去,不往下走,二維的情況簡單點,高維的可能會弄出一直原地不動的情況來。
一維搜尋的主要結構如下:1)首先確定包含問題最優解的搜尋區間,再採用某種分割技術或插值方法縮小這個區間,進行搜尋求解。
當然這個搜尋方法主要是適應單峰區間的,就是類似上面的那種,只有一個谷底的。
1.2.1.1確定搜尋區間
確定搜尋區間一般用進退法,思想是從某一點出發,按某步長,確定函式值呈現“高-低-高”的三個點,一個方向不成功,就退回來,沿相反方向尋找。
下面是步驟。
1.2.1.2搜尋求解
搜尋求解的話,0.618法簡單實用。雖然Fibonacci法,插值法等等雖然好,複雜,就不多說了。下面是0.618法的步驟。
普通的0.618法要求一維搜尋的函式是單峰函式,實際上遇到的函式不一定是單峰函式,這時,可能產生搜尋得到的函式值反而大於初始區間端點出函式值的情況。有人建議每次縮小區間是,不要只比較兩個內點處的函式值,而是比較兩內點和兩端點處的函式值。當左邊第一個或第二個點是這四個點中函式值最小的點是,丟棄右端點,構成新的搜尋區間;否則,丟棄左端點,構成新的搜尋區間,經過這樣的修改,演算法會變得可靠些。步驟就不列了。
1.2.2不精確一維搜尋方法
一維搜尋過程是最優化方法的基本組成部分,精確的一維搜尋方法往往需要花費很大的工作量。特別是迭代點遠離問題的解時,精確地求解一個一維子問題通常不是十分有效的。另外,在實際上,很多最優化方法,例如牛頓法和擬牛頓法,其收斂速度並不依賴於精確一維搜尋過程。因此,只要保證目標函式f(x)在每一步都有滿意的下降,這樣就可以大大節省工作量。
有幾位科學家Armijo(1966)和Goldstein(1965)分別提出了不精確一維搜尋過程。設
是一個區間。看下圖
在圖中,區間J=(0,a)。為了保證目標函式單調下降,同時要求f的下降不是太小(如果f的下降太小,可能導致序列的極限值不是極小值),必須避免所選擇的α太靠近區間j的短短。一個合理的要求是
(2.5.2)
(2.5.3)
其中0<ρ<1/2,。滿足(2.5.2)要求的α_k構成區間J_1=(0,c],這就扔掉了區間J右端附件的點。但是為了避免α太小的情況,又加上了另一個要求(2.5.3),這個要求扔掉了區間J的左端點附件的點。看圖中
和
兩條虛線夾出來的區間J_2=[b,c]就是滿足條件(2.5.2)和(2.5.3)的搜尋區間,稱為可接受區間。條件(2.5.2)和(2.5.3)稱為Armijo-Goldstein準則。無論用什麼辦法得到步長因子α,只要滿足條件(2.5.2)和(2.5.3),就可以稱它為可接受步長因子。
其中這個要求是必須的,因為不用這個條件,可能會影響牛頓法和擬牛頓法的超線性收斂。
在圖中可以看到一種情況,極小值e也被扔掉了,為了解決這種情況,Wolfe-Powell準則給出了一個更簡單的條件代替
(2.5.4)
其幾何解釋是在可接受點處切線的斜率大於或等於初始斜率的σ倍。準則(2.5.2)和(2.5.4)稱為Wolfe-Powell準則,其可接受區間為J_3=[e,c]。
要求ρ<σ<1是必要的,它保證了滿足不精確線性搜尋準則的步長因子的存在,不這麼弄,可能
這個虛線會往下壓,沒有交點,就搞不出一個區間來了。
下面就給出Armijo-Goldstein準則和Wolfe-Powell準則的框圖。
從演算法框圖中可以看出,兩種方法是類似的,只是在準則不成立,需要計算新的時,一個利用了簡單的求區間中點的方法,另一個採用了二次插值方法。
演算法步驟只給出Armijo-Goldstein不精確一維搜尋方法的,下面就是
好了,說到這,確定步長的方法也說完了,其實方法不少,實際用到的肯定是最簡單的幾種,就把簡單的幾種提了一下,至於為什麼這樣,收斂如何,證明的東西大家可以去書中慢慢看。
1.3方向確定
1.3.1最速下降法
最速下降法以負梯度方向作為最優化方法的下降方向,又稱為梯度下降法,是最簡單實用的方法。
1.3.1.1演算法步驟
下面是步驟。
看個例子。
這個選步長的方法是對二次函式下的特殊情況,是比較快而且好的顯式形式,說明步長選得好,收斂很快。
1.3.1.2缺點
數值實驗表明,當目標函式的等值線接近一個圓(球)時,最速下降法下降較快,當目標函式的等值線是一個扁長的橢球是,最速下降法開始幾步下降較快,後來就出現鋸齒線性,下降就十分緩慢。原因是一維搜尋滿足下圖是鋸齒的一個圖。
1.3.2牛頓法
1.3.2.1演算法思想和步驟
牛頓法的基本思想是利用目標函式的二次Taylor展開,並將其極小化。設f(x)是二次可微實函式,
其中,,
為f(x)的二次近似。將上式右邊極小化,便得
這就是牛頓迭代公式。在這個公式中,步長因子。令
,
,則上面的迭代式也可以寫成
。
其中的Hesse矩陣的形式如下。
一個例子如下。
對於正定二次函式,牛頓法一步就可以得到最優解。
對於非二次函式,牛頓法並不能保證經過有限次迭代求得最優解,但由於目標函式在極小點附近近似於二次函式,所以當初始點靠近極小點時,牛頓法的收斂速度一般是快的。
當初始點遠離最優解,不一定正定,牛頓方向不一定是下降方向,其收斂性不能保證,這說明步長一直是1是不合適的,應該在牛頓法中採用某種一維搜尋來確定步長因子。但是要強調一下,僅當步長因子
收斂到1時,牛頓法才是二階收斂的。
這時的牛頓法稱為阻尼牛頓法,步驟如下。
下面看個例子。
這樣的牛頓法是總體收斂的。
1.3.2.2缺點
牛頓法面臨的主要困難是Hesse矩陣為了克服這種困難,有多種方法,常用的方法是使牛頓方向偏向最速下降方向
1.3.3擬牛頓法
牛頓法在實際應用中需要儲存二階導數資訊和計算一個矩陣的逆,這對計算機的時間和空間要求都比較高,也容易遇到不正定的Hesse矩陣和病態的Hesse矩陣,導致求出來的逆很古怪,從而演算法會沿一個不理想的方向去迭代。
有人提出了介於最速下降法與牛頓法之間的方法。一類是共軛方向法,典型的是共軛梯度法,還有擬牛頓法。
其中擬牛頓法簡單實用,這裡就特地介紹,其他方法感興趣的讀者可以去看相關資料。
1.3.3.1演算法思想和步驟
牛頓法的成功的關鍵是利用了Hesse矩陣提供的曲率資訊。但是計算Hesse矩陣工作量大,並且有些目標函式的Hesse矩陣很難計算,甚至不好求出,這就使得僅利用目標函式的一階導數的方法更受歡迎。擬牛頓法就是利用目標函式值f和一階導數g(梯度)的資訊,構造出目標函式的曲率近似,而不需要明顯形成Hesse矩陣,同時具有收斂速度快的特點。設
兩邊求導,得
令,得
其中,是梯度。那麼,只要構造出Hesse矩陣的逆近似
滿足這種上式就可以,即滿足關係
這個關係就是擬牛頓條件或擬牛頓方程。
擬牛頓法的思想就是——用一個矩陣去近似Hesse矩陣的逆矩陣,這樣就避免了計算矩陣的逆。
當然需要滿足一些條件:
(a) 是一個正定的矩陣
(b) 如果存在,則
。
(c) 初始正定矩陣取定後,
應該由
遞推給出,即
;其中
是修正矩陣,
是修正公式。
常用而且有效的修正公式是BFGS公式,如下
下面給出BFGS公式下的擬牛頓法
在上述步驟中,初始正定矩陣通常取為單位矩陣,即
。這樣,擬牛頓法的第一次迭代相當於一個最速下降迭代。
1.3.3.2優缺點
與牛頓法相比,有兩個優點:
(a) 僅需一階導數
(b) 校正保持正定性,因而下降性質成立
(c) 無需計算逆矩陣,但具有超線性收斂速度
(d) 每次迭代僅需要次乘法計算
缺點是初始點距離最優解遠時速度還是慢。
解決方法是,迭代前期用最速下降法進行迭代,得到一定解以後用擬牛頓法迭代。
相關文章
- 第一週【任務2】無約束最優化優化
- 無約束凸優化演算法優化演算法
- 05-無約束優化演算法優化演算法
- 約束優化的拉格朗日乘子(KKT)優化
- 支援向量機(SVM)的約束和無約束優化、理論和實現優化
- 運籌優化(十一)--無約束非線性規劃優化
- 06-等式約束優化演算法優化演算法
- sql優化之邏輯優化SQL優化
- 04 最優化方法優化
- 運籌優化(十二)--帶約束非線性規劃(NLP)優化
- Android效能優化之佈局優化Android優化
- 數值最優化—優化問題的解(二)優化
- Android 效能優化之記憶體優化Android優化記憶體
- Android效能優化篇之服務優化Android優化
- MySQL優化之系統變數優化MySql優化變數
- MySQL調優之索引優化MySql索引優化
- 資料庫優化之臨時表優化資料庫優化
- Android記憶體優化之圖片優化Android記憶體優化
- Android應用優化之冷啟動優化Android優化
- 層次和約束:專案中使用vuex的3條優化方案Vue優化
- Webpack之模組化優化Web優化
- MySQL調優之查詢優化MySql優化
- 面試Tip:Android優化之APP啟動優化面試Android優化APP
- 運籌優化(十七)--儲存論基礎及其最優化求解優化
- 運籌優化(十八)--對策論基礎及其最優化求解優化
- 運籌優化(十九)--決策論基礎及其最優化求解優化
- 運籌優化(十六)--排隊論基礎及其最優化求解優化
- 六、Android效能優化之UI卡頓分析之渲染效能優化Android優化UI
- 前端效能優化(JS/CSS優化,SEO優化)前端優化JSCSS
- 效能優化之關於畫素管道及優化(二)優化
- oracle之優化一用group by或exists優化distinctOracle優化
- iOS效能優化系列篇之“列表流暢度優化”iOS優化
- iOS效能優化系列篇之“優化總體原則”iOS優化
- win10最詳細優化設定_win10怎麼優化最流暢Win10優化
- 效能優化(一)APP 啟動優化(不敢說秒開,但是最終優化完真不到 1s)優化APP
- 非線性最優化最佳教材優化
- MySQL查詢優化之優化器工作流程以及優化的執行計劃生成MySql優化
- hadoop之yarn(優化篇)HadoopYarn優化
- MySQL優化之索引解析MySql優化索引