1. HTTP2.0的前世
http2.0的前世是http1.0和http1.1這兩兄弟。雖然之前僅僅只有兩個版本,但這兩個版本所包含的協議規範之龐大,足以讓任何一個有經驗的工程師為之頭疼。http1.0誕生於1996年,協議文件足足60頁。之後第三年,http1.1也隨之出生,協議文件膨脹到了176頁。不過和我們手機端app升級不同的是,網路協議新版本並不會馬上取代舊版本。實際上,1.0和1.1在之後很長的一段時間內一直並存,這是由於網路基礎設施更新緩慢所決定的。今天的http2.0也是一樣,新版協議再好也需要業界的產品錘鍊,需要基礎設施逐年累月的升級換代才能普及。
1.1 HTTP站在TCP之上
理解http協議之前一定要對TCP有一定基礎的瞭解。HTTP是建立在TCP協議之上,TCP協議作為傳輸層協議其實離應用層並不遠。HTTP協議的瓶頸及其優化技巧都是基於TCP協議本身的特性。比如TCP建立連線時三次握手有1.5個RTT(round-trip time)的延遲,為了避免每次請求的都經歷握手帶來的延遲,應用層會選擇不同策略的http長連結方案。又比如TCP在建立連線的初期有慢啟動(slow start)的特性,所以連線的重用總是比新建連線效能要好。
1.1 HTTP應用場景
http誕生之初主要是應用於web端內容獲取,那時候內容還不像現在這樣豐富,排版也沒那麼精美,使用者互動的場景幾乎沒有。對於這種簡單的獲取網頁內容的場景,http表現得還算不錯。但隨著網際網路的發展和web2.0的誕生,更多的內容開始被展示(更多的圖片檔案),排版變得更精美(更多的css),更復雜的互動也被引入(更多的js)。使用者開啟一個網站首頁所載入的資料總量和請求的個數也在不斷增加。今天絕大部分的入口網站首頁大小都會超過2M,請求數量可以多達100個。另一個廣泛的應用是在移動網際網路的客戶端app,不同性質的app對http的使用差異很大。對於電商類app,載入首頁的請求也可能多達10多個。對於微信這類IM,http請求可能僅限於語音和圖片檔案的下載,請求出現的頻率並不算高。
1.2 因為延遲,所以慢
影響一個網路請求的因素主要有兩個,頻寬和延遲。今天的網路基礎建設已經使得頻寬得到極大的提升,大部分時候都是延遲在影響響應速度。http1.0被抱怨最多的就是連線無法複用,和head of line blocking這兩個問題。理解這兩個問題有一個十分重要的前提:客戶端是依據域名來向伺服器建立連線,一般PC端瀏覽器會針對單個域名的server同時建立6~8個連線,手機端的連線數則一般控制在4~6個。顯然連線數並不是越多越好,資源開銷和整體延遲都會隨之增大。
連線無法複用會導致每次請求都經歷三次握手和慢啟動。三次握手在高延遲的場景下影響較明顯,慢啟動則對檔案類大請求影響較大。
head of line blocking會導致頻寬無法被充分利用,以及後續健康請求被阻塞。假設有5個請求同時發出,如下圖:
[圖1] 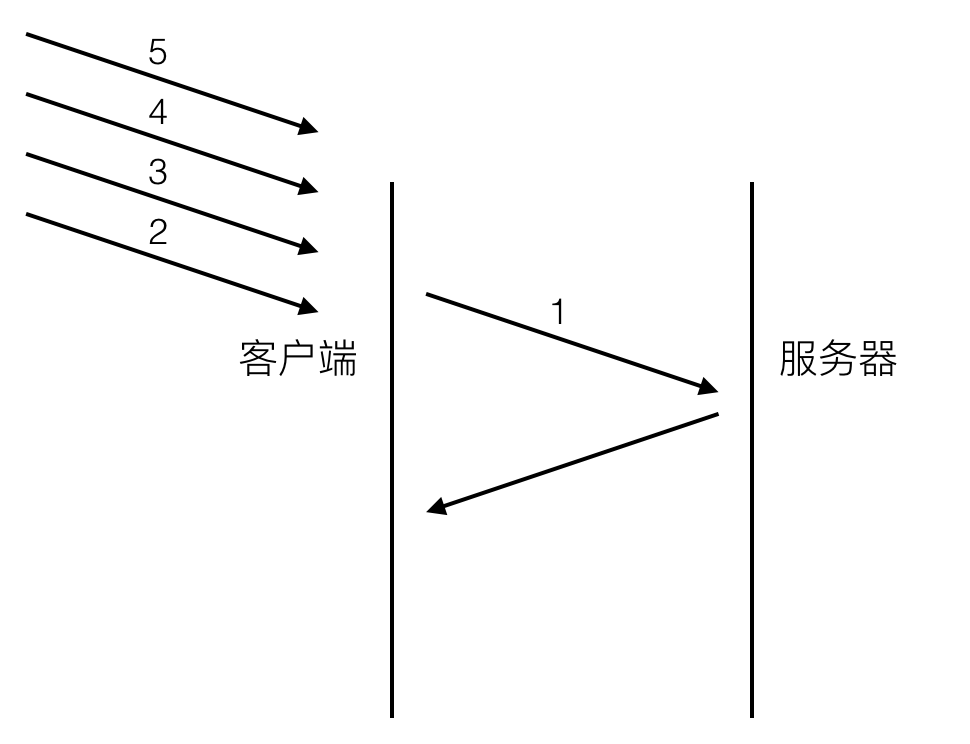
對於http1.0的實現,在第一個請求沒有收到回覆之前,後續從應用層發出的請求只能排隊,請求2,3,4,5只能等請求1的response回來之後才能逐個發出。網路通暢的時候效能影響不大,一旦請求1的request因為什麼原因沒有抵達伺服器,或者response因為網路阻塞沒有及時返回,影響的就是所有後續請求,問題就變得比較嚴重了。
1.3 解決連線無法複用
http1.0協議頭裡可以設定Connection:Keep-Alive。在header裡設定Keep-Alive可以在一定時間內複用連線,具體複用時間的長短可以由伺服器控制,一般在15s左右。到http1.1之後Connection的預設值就是Keep-Alive,如果要關閉連線複用需要顯式的設定Connection:Close。一段時間內的連線複用對PC端瀏覽器的體驗幫助很大,因為大部分的請求在集中在一小段時間以內。但對移動app來說,成效不大,app端的請求比較分散且時間跨度相對較大。所以移動端app一般會從應用層尋求其它解決方案,長連線方案或者偽長連線方案:
方案一:基於tcp的長連結
現在越來越多的移動端app都會建立一條自己的長連結通道,通道的實現是基於tcp協議。基於tcp的socket程式設計技術難度相對複雜很多,而且需要自己制定協議,但帶來的回報也很大。資訊的上報和推送變得更及時,在請求量爆發的時間點還能減輕伺服器壓力(http短連線模式會頻繁的建立和銷燬連線)。不止是IM app有這樣的通道,像淘寶這類電商類app都有自己的專屬長連線通道了。現在業界也有不少成熟的方案可供選擇了,google的protobuf就是其中之一。
方案二:http long-polling
long-polling可以用下圖表示:
[圖2]
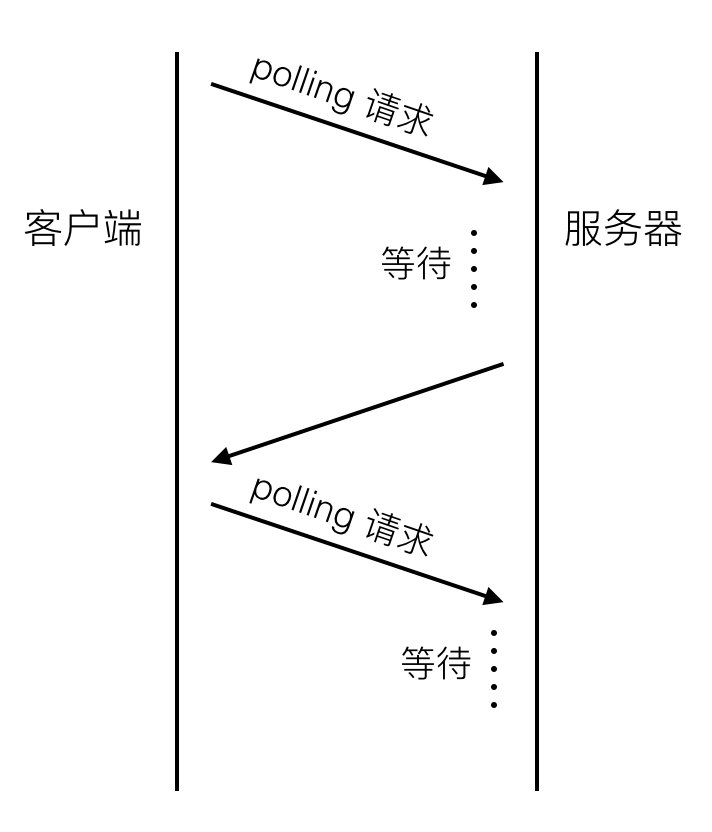
客戶端在初始狀態就會傳送一個polling請求到伺服器,伺服器並不會馬上返回業務資料,而是等待有新的業務資料產生的時候再返回。所以連線會一直被保持,一旦結束馬上又會發起一個新的polling請求,如此反覆,所以一直會有一個連線被保持。伺服器有新的內容產生的時候,並不需要等待客戶端建立一個新的連線。做法雖然簡單,但有些難題需要攻克才能實現穩定可靠的業務框架:
- 和傳統的http短連結相比,長連線會在使用者增長的時候極大的增加伺服器壓力
- 移動端網路環境複雜,像wifi和4g的網路切換,進電梯導致網路臨時斷掉等,這些場景都需要考慮怎麼重建健康的連線通道。
- 這種polling的方式穩定性並不好,需要做好資料可靠性的保證,比如重發和ack機制。
- polling的response有可能會被中間代理cache住,要處理好業務資料的過期機制。
long-polling方式還有一些缺點是無法克服的,比如每次新的請求都會帶上重複的header資訊,還有資料通道是單向的,主動權掌握在server這邊,客戶端有新的業務請求的時候無法及時傳送。
方案三:http streaming
http streaming流程大致如下:
[圖3]
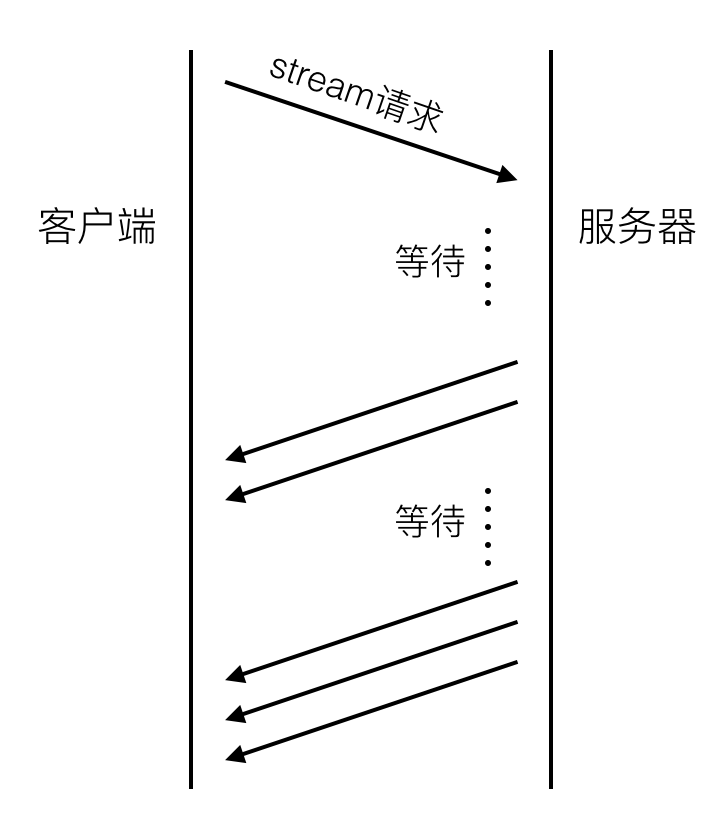
同long-polling不同的是,server並不會結束初始的streaming請求,而是持續的通過這個通道返回最新的業務資料。顯然這個資料通道也是單向的。streaming是通過在server response的頭部裡增加"Transfer Encoding: chunked"來告訴客戶端後續還會有新的資料到來。除了和long-polling相同的難點之外,streaming還有幾個缺陷:
- 有些代理伺服器會等待伺服器的response結束之後才會將結果推送到請求客戶端。對於streaming這種永遠不會結束的方式來說,客戶端就會一直處於等待response的過程中。
- 業務資料無法按照請求來做分割,所以客戶端沒收到一塊資料都需要自己做協議解析,也就是說要做自己的協議定製。
streaming不會產生重複的header資料。
方案四:web socket
WebSocket和傳統的tcp socket連線相似,也是基於tcp協議,提供雙向的資料通道。WebSocket優勢在於提供了message的概念,比基於位元組流的tcp socket使用更簡單,同時又提供了傳統的http所缺少的長連線功能。不過WebSocket相對較新,2010年才起草,並不是所有的瀏覽器都提供了支援。各大瀏覽器廠商最新的版本都提供了支援。
1.4 解決head of line blocking
Head of line blocking(以下簡稱為holb)是http2.0之前網路體驗的最大禍源。正如圖1中所示,健康的請求會被不健康的請求影響,而且這種體驗的損耗受網路環境影響,出現隨機且難以監控。為了解決holb帶來的延遲,協議設計者設計了一種新的pipelining機制。
http pipelining
pipelining的流程圖可以用下圖表示:
[圖4]
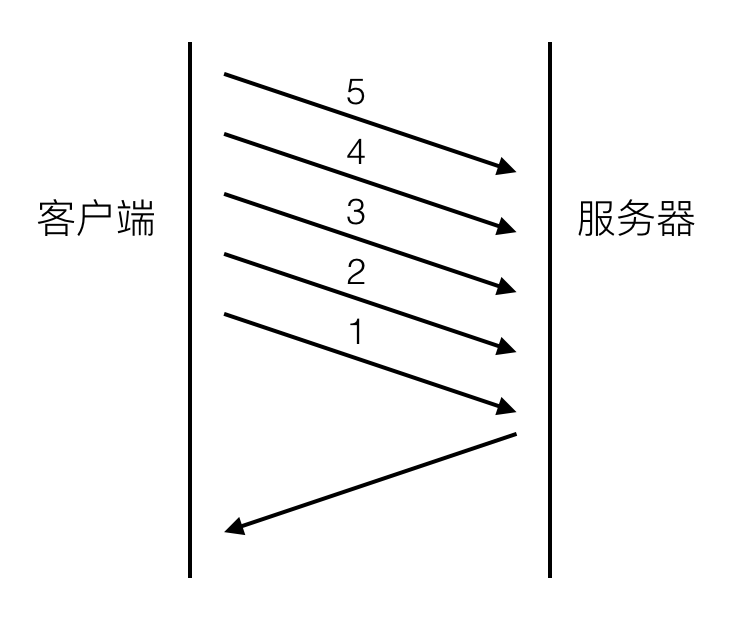
和圖一相比最大的差別是,請求2,3,4,5不用等請求1的response返回之後才發出,而是幾乎在同一時間把request發向了伺服器。2,3,4,5及所有後續共用該連線的請求節約了等待的時間,極大的降低了整體延遲。下圖可以清晰的看出這種新機制對延遲的改變:
[圖5]
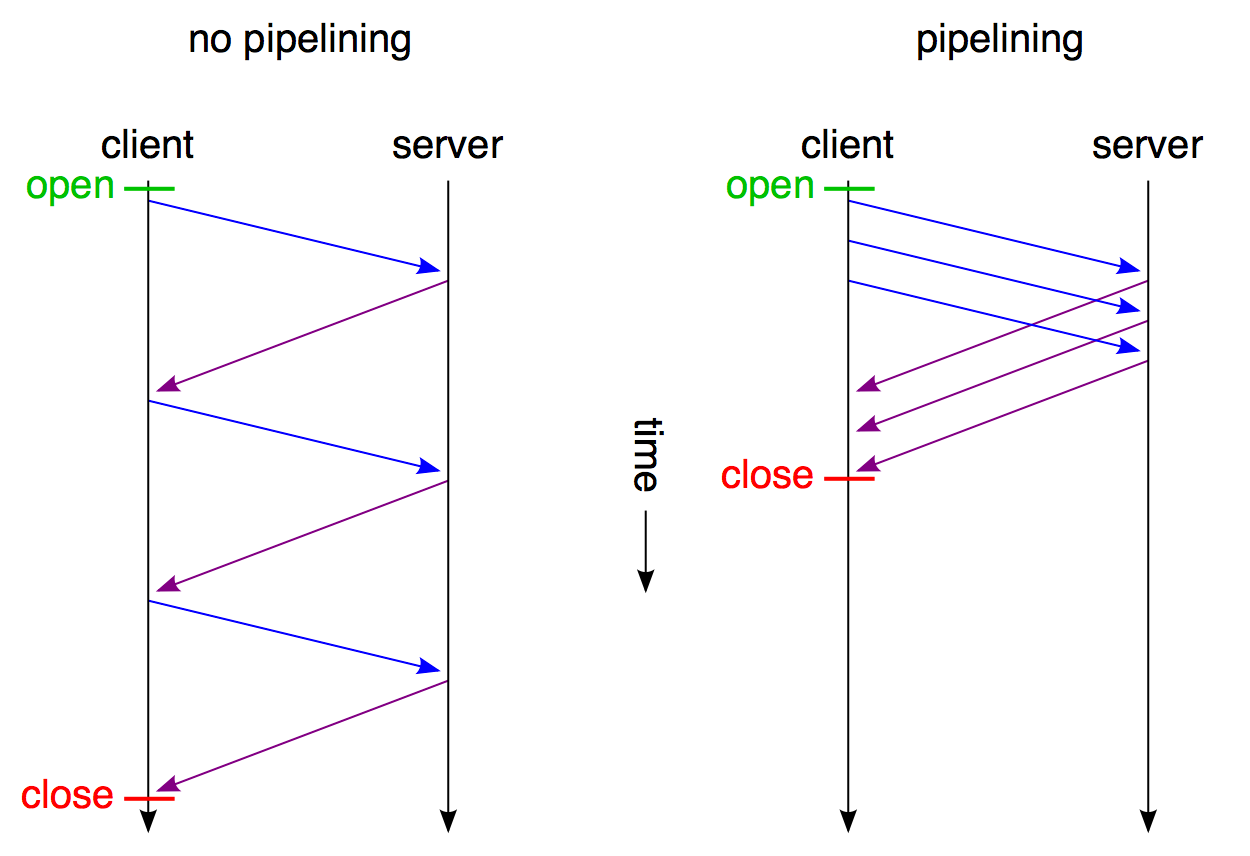
不過pipelining並不是救世主,它也存在不少缺陷:
- pipelining只能適用於http1.1,一般來說,支援http1.1的server都要求支援pipelining。
- 只有冪等的請求(GET,HEAD)能使用pipelining,非冪等請求比如POST不能使用,因為請求之間可能會存在先後依賴關係。
- head of line blocking並沒有完全得到解決,server的response還是要求依次返回,遵循FIFO(first in first out)原則。也就是說如果請求1的response沒有回來,2,3,4,5的response也不會被送回來。
- 絕大部分的http代理伺服器不支援pipelining。
- 和不支援pipelining的老伺服器協商有問題。
- 可能會導致新的Front of queue blocking問題。
正是因為有這麼多的問題,各大瀏覽器廠商要麼是根本就不支援pipelining,要麼就是預設關掉了pipelining機制,而且啟用的條件十分苛刻。可以參考chrome對於pipeling的問題描述。
1.5 其它奇技淫巧
為了解決延遲帶來的苦惱,永遠都會有聰明的探索者找出新的捷徑來。網際網路的蓬勃興盛催生出了各種新奇技巧,我們來依次看下這些“捷徑”及各自的優缺點。
Spriting(圖片合併)
Spriting指的是將多個小圖片合併到一張大的圖片裡,這樣多個小的請求就被合併成了一個大的圖片請求,然後再利用js或者css檔案來取出其中的小張圖片使用。好處顯而易見,請求數減少,延遲自然低。壞處是檔案的粒度變大了,有時候我們可能只需要其中一張小圖,卻不得不下載整張大圖,cache處理也變得麻煩,在只有一張小圖過期的情況下,為了獲得最新的版本,不得不從伺服器下載完整的大圖,即使其它的小圖都沒有過期,顯然浪費了流量。
Inlining(內容內嵌)
Inlining的思考角度和spriting類似,是將額外的資料請求通過base64編碼之後內嵌到一個總的檔案當中。比如一個網頁有一張背景圖,我們可以通過如下程式碼嵌入:
background: url(data:image/png;base64,)
data部分是base64編碼之後的位元組碼,這樣也避免了一次多餘的http請求。但這種做法也有著和spriting相同的問題,資原始檔被繫結到了其它檔案,粒度變得難以控制。
Concatenation(檔案合併)
Concatenation主要是針對js這類檔案,現在前端開發互動越來越多,零散的js檔案也在變多。將多個js檔案合併到一個大的檔案裡在做一些壓縮處理也可以減小延遲和傳輸的資料量。但同樣也面臨著粒度變大的問題,一個小的js程式碼改動會導致整個js檔案被下載。
Domain Sharding(域名分片)
前面我提到過很重要的一點,瀏覽器或者客戶端是根據domain(域名)來建立連線的。比如針對www.example.com只允許同時建立2個連線,但mobile.example.com被認為是另一個域名,可以再建立兩個新的連線。依次類推,如果我再多建立幾個sub domain(子域名),那麼同時可以建立的http請求就會更多,這就是Domain Sharding了。連線數變多之後,受限制的請求就不需要等待前面的請求完成才能發出了。這個技巧被大量的使用,一個頗具規模的網頁請求數可以超過100,使用domain sharding之後同時建立的連線數可以多到50個甚至更多。
這麼做當然增加了系統資源的消耗,但現在硬體資源升級非常之快,和使用者寶貴的等待時機相比起來實在微不足道。
domain sharding還有一大好處,對於資原始檔來說一般是不需要cookie的,將這些不同的靜態資原始檔分散在不同的域名伺服器上,可以減小請求的size。
不過domain sharding只有在請求數非常之多的場景下才有明顯的效果。而且請求數也不是越多越好,資源消耗是一方面,另一點是由於tcp的slow start會導致每個請求在初期都會經歷slow start,還有tcp 三次握手,DNS查詢的延遲。這一部分帶來的時間損耗和請求排隊同樣重要,到底怎麼去平衡這二者就需要取一個可靠的連線數中間值,這個值的最終確定要通過反覆的測試。移動端瀏覽器場景建議不要使用domain sharding,具體細節參考這篇文章。
2. 開拓者SPDY
http1.0和1.1雖然存在這麼多問題,業界也想出了各種優化的手段,但這些方法手段都是在嘗試繞開協議本身的缺陷,都有種隔靴搔癢,治標不治本的感覺。直到2012年google如一聲驚雷提出了SPDY的方案,大家才開始從正面看待和解決老版本http協議本身的問題,這也直接加速了http2.0的誕生。實際上,http2.0是以SPDY為原型進行討論和標準化的。為了給http2.0讓路,google已決定在2016年不再繼續支援SPDY開發,但在http2.0出生之前,SPDY已經有了相當規模的應用,作為一個過渡方案恐怕在還將一段時間內繼續存在。現在不少app客戶端和server都已經使用了SPDY來提升體驗,http2.0在老的裝置和系統上還無法使用(iOS系統只有在iOS9+上才支援),所以可以預見未來幾年spdy將和http2.0共同服務的情況。
2.1 SPDY的目標
SPDY的目標在一開始就是瞄準http1.x的痛點,即延遲和安全性。我們上面通篇都在討論延遲,至於安全性,由於http是明文協議,其安全性也一直被業界詬病,不過這是另一個大的話題。如果以降低延遲為目標,應用層的http和傳輸層的tcp都是都有調整的空間,不過tcp作為更底層協議存在已達數十年之久,其實現已深植全球的網路基礎設施當中,如果要動必然傷經動骨,業界響應度必然不高,所以SPDY的手術刀對準的是http。
- 降低延遲,客戶端的單連線單請求,server的FIFO響應佇列都是延遲的大頭。
- http最初設計都是客戶端發起請求,然後server響應,server無法主動push內容到客戶端。
- 壓縮http header,http1.x的header越來越膨脹,cookie和user agent很容易讓header的size增至1kb大小,甚至更多。而且由於http的無狀態特性,header必須每次request都重複攜帶,很浪費流量。
為了增加業界響應的可能性,聰明的google一開始就避開了從傳輸層動手,而且打算利用開源社群的力量以提高擴散的力度,對於協議使用者來說,也只需要在請求的header裡設定user agent,然後在server端做好支援即可,極大的降低了部署的難度。SPDY的設計如下:
[圖6]

SPDY位於HTTP之下,TCP和SSL之上,這樣可以輕鬆相容老版本的HTTP協議(將http1.x的內容封裝成一種新的frame格式),同時可以使用已有的SSL功能。SPDY的功能可以分為基礎功能和高階功能兩部分,基礎功能預設啟用,高階功能需要手動啟用。
SPDY基礎功能
- 多路複用(multiplexing)。多路複用通過多個請求stream共享一個tcp連線的方式,解決了http1.x holb(head of line blocking)的問題,降低了延遲同時提高了頻寬的利用率。
- 請求優先順序(request prioritization)。多路複用帶來一個新的問題是,在連線共享的基礎之上有可能會導致關鍵請求被阻塞。SPDY允許給每個request設定優先順序,這樣重要的請求就會優先得到響應。比如瀏覽器載入首頁,首頁的html內容應該優先展示,之後才是各種靜態資原始檔,指令碼檔案等載入,這樣可以保證使用者能第一時間看到網頁內容。
- header壓縮。前面提到過幾次http1.x的header很多時候都是重複多餘的。選擇合適的壓縮演算法可以減小包的大小和數量。SPDY對header的壓縮率可以達到80%以上,低頻寬環境下效果很大。
SPDY高階功能
- server推送(server push)。http1.x只能由客戶端發起請求,然後伺服器被動的傳送response。開啟server push之後,server通過X-Associated-Content header(X-開頭的header都屬於非標準的,自定義header)告知客戶端會有新的內容推送過來。在使用者第一次開啟網站首頁的時候,server將資源主動推送過來可以極大的提升使用者體驗。
- server暗示(server hint)。和server push不同的是,server hint並不會主動推送內容,只是告訴有新的內容產生,內容的下載還是需要客戶端主動發起請求。server hint通過X-Subresources header來通知,一般應用場景是客戶端需要先查詢server狀態,然後再下載資源,可以節約一次查詢請求。
2.2 SPDY的成績
SPDY的成績可以用google官方的一個數字來說明:頁面載入時間相比於http1.x減少了64%。而且各大瀏覽器廠商在SPDY誕生之後的1年多裡都陸續支援了SPDY,不少大廠app和server端框架也都將SPDY應用到了線上的產品當中。
google的官網也給出了他們自己做的一份測試資料。測試物件是25個訪問量排名靠前的網站首頁,家用網路%1的丟包率,每個網站測試10次取平均值。結果如下:
[圖7]
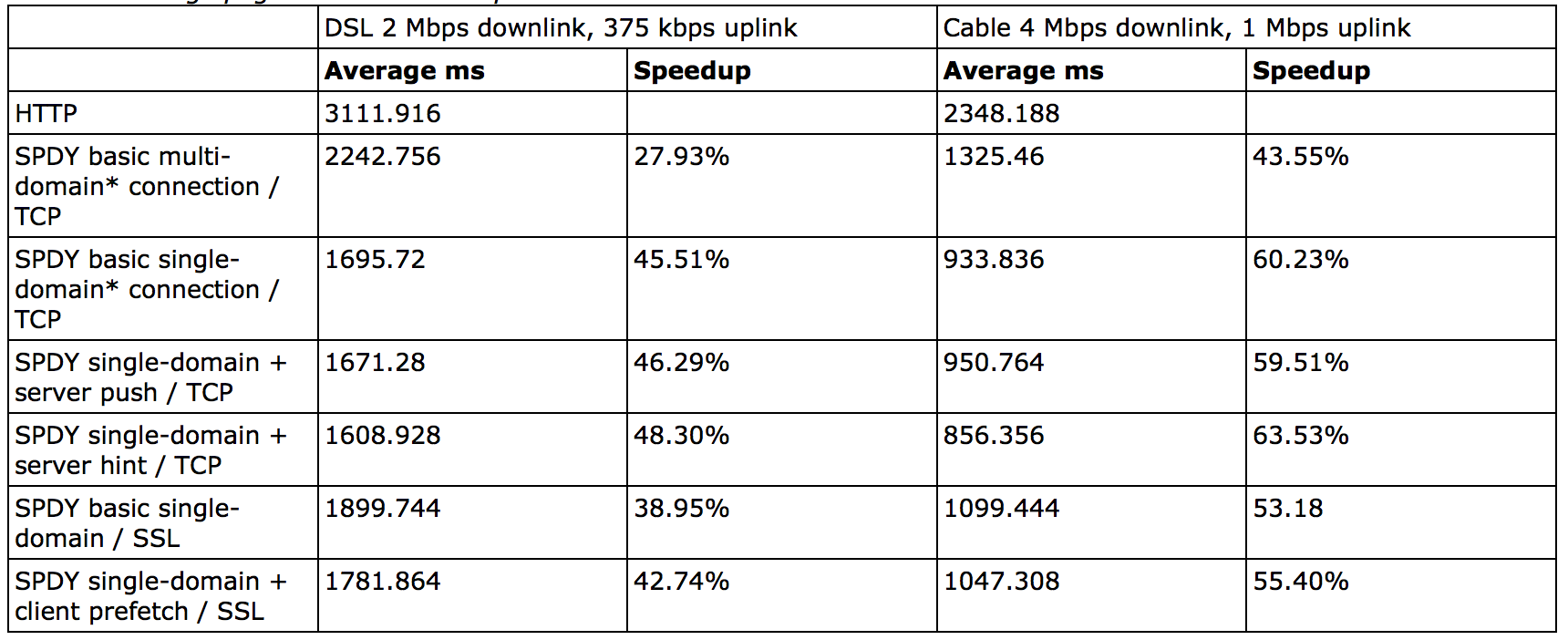
不開啟ssl的時候提升在 27% - 60%,開啟之後為39% - 55%。 這份測試結果有兩點值得特別注意:
連線數的選擇
連線到底是基於域名來建立,還是不做區分所有子域名都共享一個連線,這個策略選擇上值得商榷。google的測試結果測試了兩種方案,看結果似乎是單一連線效能高於多域名連線方式。之所以出現這種情況是由於網頁所有的資源請求並不是同一時間發出,後續發出的子域名請求如果能複用之前的tcp連線當然效能更好。實際應用場景下應該也是單連線共享模式表現好。
頻寬的影響
測試基於兩種頻寬環境,一慢一快。網速快的環境下對減小延遲的提升更大,單連線模式下可以提升至60%。原因也比較簡單,頻寬越大,複用連線的請求完成越快,由於三次握手和慢啟動導致的延遲損耗就變得更明顯。
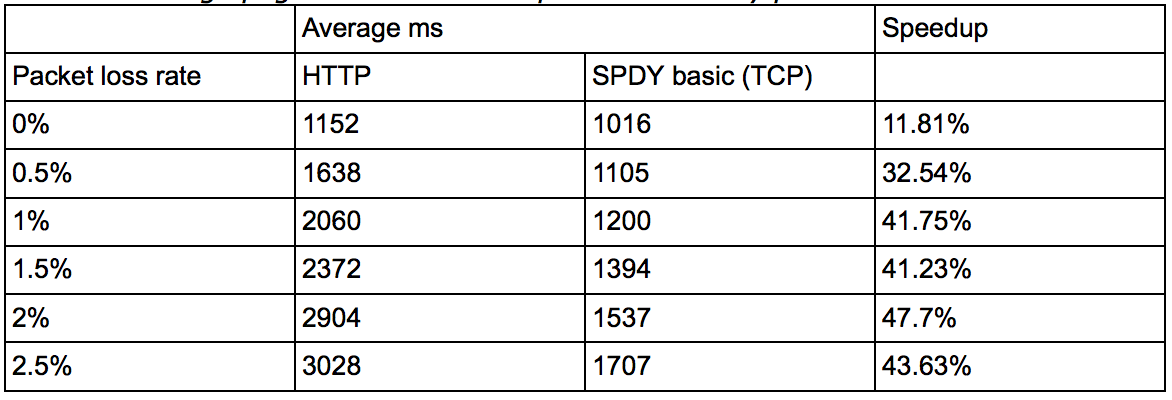
出了連線模式和頻寬之外,丟包率和RTT也是需要測試的引數。SPDY對header的壓縮有80%以上,整體包大小能減少大概40%,傳送的包越少,自然受丟包率影響也就越小,所以丟包率大的惡劣環境下SPDY反而更能提升體驗。下圖是受丟包率影響的測試結果,丟包率超過2.5%之後就沒有提升了:
[圖8]
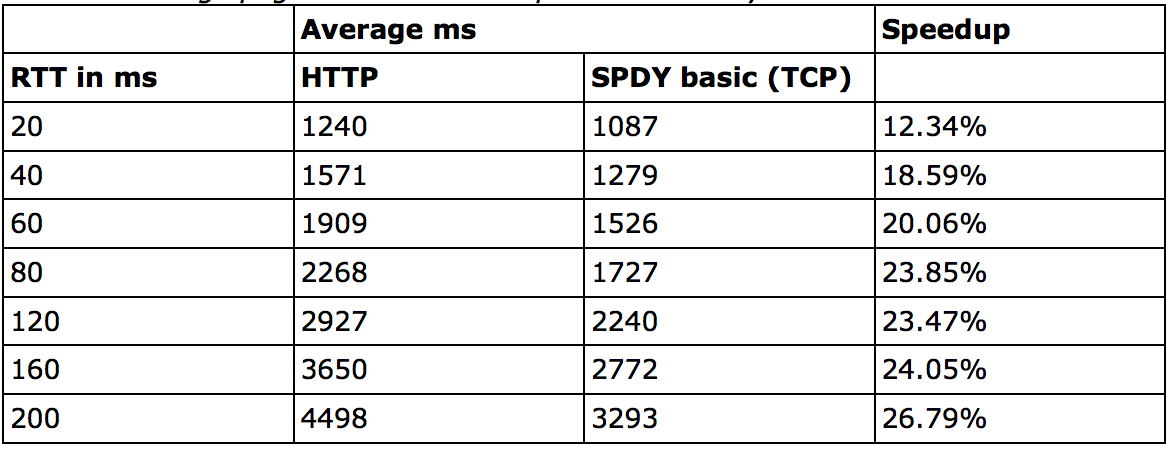
RTT越大,延遲會越大,在高RTT的場景下,由於SPDY的request是併發進行的,所有對包的利用率更高,反而能更明顯的減小總體延遲。測試結果如下:
[圖9]
SPDY從2012年誕生到2016停止維護,時間跨度對於網路協議來說其實非常之短。如果HTTP2.0沒有出來,google或許能收集到更多業界產品的真實反饋和資料,畢竟google自己的測試環境相對簡單。但SPDY也完成了自己的使命,作為一貫扮演拓荒者角色的google應該也早就預見了這樣的結局。SPDY對產品網路體驗的提升到底如何,恐怕只有各大廠產品經理才清楚了。
3. 救世主HTTP2.0
SPDY的誕生和表現說明了兩件事情:一是在現有網際網路設施基礎和http協議廣泛使用的前提下,是可以通過修改協議層來優化http1.x的。二是針對http1.x的修改確實效果明顯而且業界反饋很好。正是這兩點讓IETF(Internet Enginerring Task Force)開始正式考慮制定HTTP2.0的計劃,最後決定以SPDY/3為藍圖起草HTTP2.0,SPDY的部分設計人員也被邀請參與了HTTP2.0的設計。
3.1 HTTP2.0需要考慮的問題
HTTP2.0與SPDY的起點不同,SPDY可以說是google的“玩具”,最早出現在自家的chrome瀏覽器和server上,好不好玩以及別人會不會跟著一起玩對google來說無關痛癢。但HTTP2.0作為業界標準還沒出生就是眾人矚目的焦點,一開始如果有什麼瑕疵或者不相容的問題影響可能又是數十年之久,所以考慮的問題和角度要非常之廣。我們來看下HTTP2.0一些重要的設計前提:
- 客戶端向server傳送request這種基本模型不會變。
- 老的scheme不會變,使用http://和https://的服務和應用不會要做任何更改,不會有http2://。
- 使用http1.x的客戶端和伺服器可以無縫的通過代理方式轉接到http2.0上。
- 不識別http2.0的代理伺服器可以將請求降級到http1.x。
因為客戶端和server之間在確立使用http1.x還是http2.0之前,必須要要確認對方是否支援http2.0,所以這裡必須要有個協商的過程。最簡單的協商也要有一問一答,客戶端問server答,即使這種最簡單的方式也多了一個RTT的延遲,我們之所以要修改http1.x就是為了降低延遲,顯然這個RTT我們是無法接受的。google制定SPDY的時候也遇到了這個問題,他們的辦法是強制SPDY走https,在SSL層完成這個協商過程。ssl層的協商在http協議通訊之前,所以是最適合的載體。google為此做了一個tls的擴充,叫NPN(Next Protocol Negotiation),從名字上也可以看出,這個擴充主要目的就是為了協商下一個要使用的協議。HTTP2.0雖然也採用了相同的方式,不過HTTP2.0經過激烈的討論,最終還是沒有強制HTTP2.0要走ssl層,大部分瀏覽器廠商(除了IE)卻只實現了基於https的2.0協議。HTTP2.0沒有使用NPN,而是另一個tls的擴充叫ALPN(Application Layer Protocol Negotiation)。SPDY也打算從NPN遷移到ALPN了。
各瀏覽器(除了IE)之所以只實現了基於SSL的HTTP2.0,另一個原因是走SSL請求的成功率會更高,被SSL封裝的request不會被監聽和修改,這樣網路中間的網路裝置就無法基於http1.x的認知去幹涉修改request,http2.0的request如果被意外的修改,請求的成功率自然會下降。
HTTP2.0協議沒有強制使用SSL是因為聽到了很多的反對聲音,畢竟https和http相比,在不優化的前提下效能差了不少,要把https優化到幾乎不增加延遲的程度又需要花費不少力氣。IETF面對這種兩難的處境做了妥協,但大部分瀏覽器廠商(除了IE)並不買帳,他們只認https2.0。對於app開發者來說,他們可以堅持使用沒有ssl的http2.0,不過要承擔一個多餘的RTT延遲和請求可能被破壞的代價。
3.1 HTTP2.0主要改動
HTTP2.0作為新版協議,改動細節必然很多,不過對應用開發者和服務提供商來說,影響較大的就幾點。
新的二進位制格式(Binary Format)
http1.x誕生的時候是明文協議,其格式由三部分組成:start line(request line或者status line),header,body。要識別這3部分就要做協議解析,http1.x的解析是基於文字。基於文字協議的格式解析存在天然缺陷,文字的表現形式有多樣性,要做到健壯性考慮的場景必然很多,二進位制則不同,只認0和1的組合。基於這種考慮http2.0的協議解析決定採用二進位制格式,實現方便且健壯。
有人可能會覺得基於文字的http除錯方便很多,像firebug,chrome,charles等不少工具都可以即時除錯修改請求。實際上現在很多請求都是走https了,要除錯https請求必須有私鑰才行。http2.0的絕大部分request應該都是走https,所以除錯方便無法作為一個有力的考慮因素了。curl,tcpdump,wireshark這些工具會更適合http2.0的除錯。
http2.0用binary格式定義了一個一個的frame,和http1.x的格式對比如下圖:
[圖10]

http2.0的格式定義更接近tcp層的方式,這張二機制的方式十分高效且精簡。length定義了整個frame的開始到結束,type定義frame的型別(一共10種),flags用bit位定義一些重要的引數,stream id用作流控制,剩下的payload就是request的正文了。
雖然看上去協議的格式和http1.x完全不同了,實際上http2.0並沒有改變http1.x的語義,只是把原來http1.x的header和body部分用frame重新封裝了一層而已。除錯的時候瀏覽器甚至會把http2.0的frame自動還原成http1.x的格式。具體的協議關係可以用下圖表示:
[圖11]
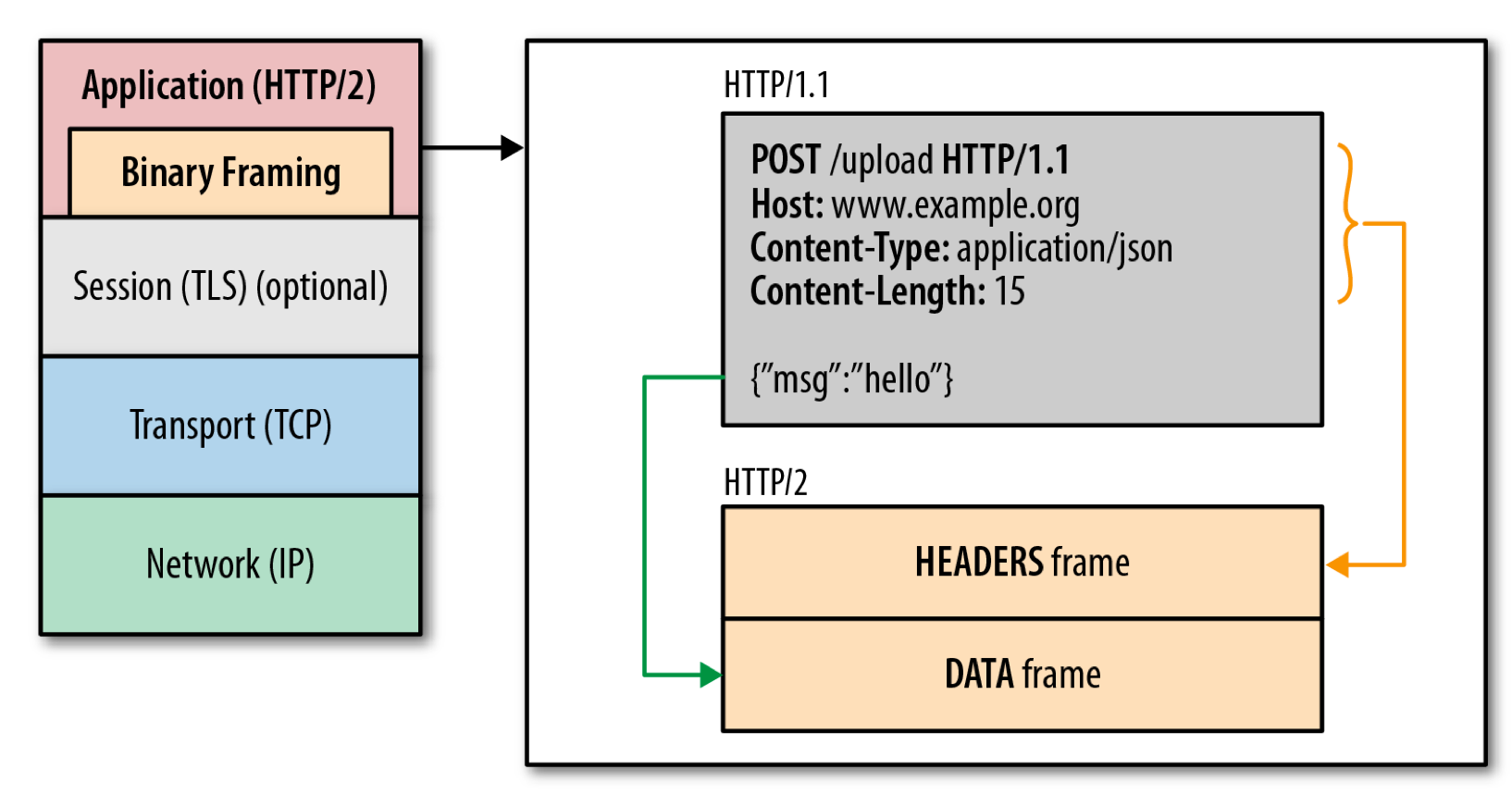
連線共享
http2.0要解決的一大難題就是多路複用(MultiPlexing),即連線共享。上面協議解析中提到的stream id就是用作連線共享機制的。一個request對應一個stream並分配一個id,這樣一個連線上可以有多個stream,每個stream的frame可以隨機的混雜在一起,接收方可以根據stream id將frame再歸屬到各自不同的request裡面。
前面還提到過連線共享之後,需要優先順序和請求依賴的機制配合才能解決關鍵請求被阻塞的問題。http2.0裡的每個stream都可以設定又優先順序(Priority)和依賴(Dependency)。優先順序高的stream會被server優先處理和返回給客戶端,stream還可以依賴其它的sub streams。優先順序和依賴都是可以動態調整的。動態調整在有些場景下很有用,假想使用者在用你的app瀏覽商品的時候,快速的滑動到了商品列表的底部,但前面的請求先發出,如果不把後面的請求優先順序設高,使用者當前瀏覽的圖片要到最後才能下載完成,顯然體驗沒有設定優先順序好。同理依賴在有些場景下也有妙用。
header壓縮
前面提到過http1.x的header由於cookie和user agent很容易膨脹,而且每次都要重複傳送。http2.0使用encoder來減少需要傳輸的header大小,通訊雙方各自cache一份header fields表,既避免了重複header的傳輸,又減小了需要傳輸的大小。高效的壓縮演算法可以很大的壓縮header,減少傳送包的數量從而降低延遲。
這裡普及一個小知識點。現在大家都知道tcp有slow start的特性,三次握手之後開始傳送tcp segment,第一次能傳送的沒有被ack的segment數量是由initial tcp window大小決定的。這個initial tcp window根據平臺的實現會有差異,但一般是2個segment或者是4k的大小(一個segment大概是1500個位元組),也就是說當你傳送的包大小超過這個值的時候,要等前面的包被ack之後才能傳送後續的包,顯然這種情況下延遲更高。intial window也並不是越大越好,太大會導致網路節點的阻塞,丟包率就會增加,具體細節可以參考IETF這篇文章。http的header現在膨脹到有可能會超過這個intial window的值了,所以更顯得壓縮header的重要性。
壓縮演算法的選擇
SPDY/2使用的是gzip壓縮演算法,但後來出現的兩種攻擊方式BREACH和CRIME使得即使走ssl的SPDY也可以被破解內容,最後綜合考慮採用的是一種叫HPACK的壓縮演算法。這兩個漏洞和相關演算法可以點選連結檢視更多的細節,不過這種漏洞主要存在於瀏覽器端,因為需要通過javascript來注入內容並觀察payload的變化。
重置連線表現更好
很多app客戶端都有取消圖片下載的功能場景,對於http1.x來說,是通過設定tcp segment裡的reset flag來通知對端關閉連線的。這種方式會直接斷開連線,下次再發請求就必須重新建立連線。http2.0引入RST_STREAM型別的frame,可以在不斷開連線的前提下取消某個request的stream,表現更好。
Server Push
Server Push的功能前面已經提到過,http2.0能通過push的方式將客戶端需要的內容預先推送過去,所以也叫“cache push”。另外有一點值得注意的是,客戶端如果退出某個業務場景,出於流量或者其它因素需要取消server push,也可以通過傳送RST_STREAM型別的frame來做到。
流量控制(Flow Control)
TCP協議通過sliding window的演算法來做流量控制。傳送方有個sending window,接收方有receive window。http2.0的flow control是類似receive window的做法,資料的接收方通過告知對方自己的flow window大小表明自己還能接收多少資料。只有Data型別的frame才有flow control的功能。對於flow control,如果接收方在flow window為零的情況下依然更多的frame,則會返回block型別的frame,這張場景一般表明http2.0的部署出了問題。
Nagle Algorithm vs TCP Delayed Ack
tcp協議優化的一個經典場景是:Nagle演算法和Berkeley的delayed ack演算法的對立。http2.0並沒有對tcp層做任何修改,所以這種對立導致的高延遲問題依然存在。要麼通過TCP_NODELAY禁用Nagle演算法,要麼通過TCP_QUICKACK禁用delayed ack演算法。貌似http2.0官方建議是設定TCP_NODELAY。
更安全的SSL
HTTP2.0使用了tls的擴充ALPN來做協議升級,除此之外加密這塊還有一個改動,HTTP2.0對tls的安全性做了近一步加強,通過黑名單機制禁用了幾百種不再安全的加密演算法,一些加密演算法可能還在被繼續使用。如果在ssl協商過程當中,客戶端和server的cipher suite沒有交集,直接就會導致協商失敗,從而請求失敗。在server端部署http2.0的時候要特別注意這一點。
3.2 HTTP2.0裡的負能量
SPDY和HTTP2.0之間的曖昧關係,以及google作為SPDY的創造者,這兩點很容易讓陰謀論者懷疑google是否會成為協議的最終收益方。這其實是廢話,google當然會受益,任何新協議使用者都會從中受益,至於誰吃肉,誰喝湯看的是自己的本事。從整個協議的變遷史也可以粗略看出,新協議的誕生完全是針對業界現存問題對症下藥,並沒有google業務相關的痕跡存在,google至始至終只扮演了一個角色:you can you up。
HTTP2.0不會是萬金油,但抹了也不會有副作用。HTTP2.0最大的亮點在於多路複用,而多路複用的好處只有在http請求量大的場景下才明顯,所以有人會覺得只適用於瀏覽器瀏覽大型站點的時候。這麼說其實沒錯,但http2.0的好處不僅僅是multiplexing,請求壓縮,優先順序控制,server push等等都是亮點。對於內容型移動端app來說,比如淘寶app,http請求量大,多路複用還是能產生明顯的體驗提升。多路複用對延遲的改變可以參考下這個測試網址。
HTTP2.0對於ssl的依賴使得有些開發者望而生畏。不少開發者對ssl還停留在高延遲,CPU效能損耗,配置麻煩的印象中。其實ssl於http結合對效能的影響已經可以優化到忽略的程度了,網上也有不少文章可以參考。HTTP2.0也可以不走ssl,有些場景確實可能不適合https,比如對代理伺服器的cache依賴,對於內容安全性不敏感的get請求可以通過代理伺服器快取來優化體驗。
3.3 HTTP2.0的現狀
HTTP2.0作為新版本的網路協議肯定需要一段時間去普及,但HTTP本身屬於應用層協議,和當年的網路層協議IPV6不同,離底層協議越遠,對網路基礎硬體設施的影響就越小。HTTP2.0甚至還特意的考慮了與HTTP1.x的相容問題,只是在HTTP1.x的下面做了一層framing layer,更使得其普及的阻力變小。所以不出意外,HTTP2.0的普及速度可能會遠超大部分人的預期。
Firefox 2015年在其瀏覽器流量中檢測到,有13%的http流量已經使用了http2.0,27%的https也是http2.0,而且還處於持續的增長當中。一般使用者察覺不到是否使用了http2.0,不過可以裝這樣一個外掛,安裝之後如果網站是http2.0的,在位址列的最右邊會有個閃電圖示。還可以使用這個網站來測試。對於開發者來說,可以通過Web Developer的Network來檢視協議細節,如下圖:
[圖12]
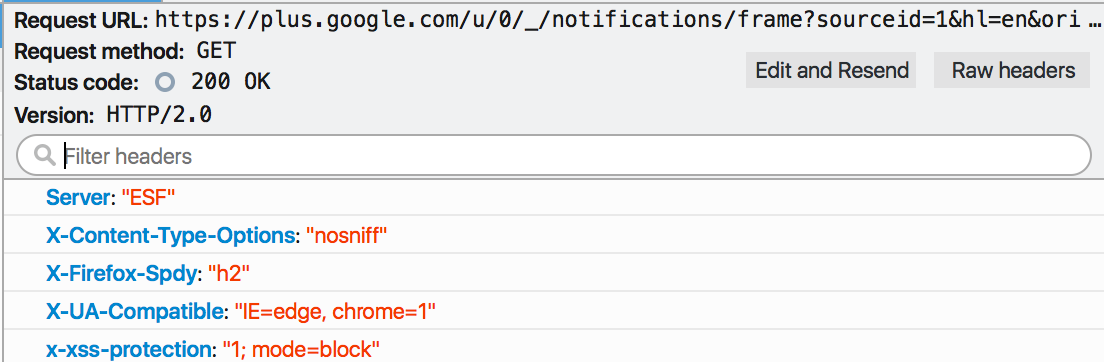
其中Version:HTTP/2.0已經很明確表明協議型別,Firefox還在header裡面插入了X-Firefox-Spdy:“h2”,也可以看出是否使用http2.0。
Chrome在2015年檢測到的http2.0流量大概有18%。不過這個數字本來會更高,因為Chrome現在很大一部分流量都在試驗QUIC(google正在開闢的另一塊疆土)。Chrome上也可以使用類似的外掛來判斷網站是否是使用http2.0。
4. 移動端HTTP現狀
4.1 iOS下http現狀
iOS系統是從iOS8開始才通過NSURLSession來支援SPDY的,iOS9+開始自動支援http2.0。實際上apple對http2.0非常有信心,推廣力度也很大。新版本ATS機制預設使用https來進行網路傳輸。APN(Apple Push Notifiction)在iOS9上也已經是通過http2.0來實現的了。iOS9 sdk裡的NSURLSession預設使用http2.0,而且對開發者來說是完全透明的,甚至沒有api來知道到底是用的哪個版本的http協議。
對於開發者來說到底怎麼去配置最佳的http使用方案呢?在我看來,因app而異,主要從兩方面來考慮:一是app本身http流量是否大而且密集,二是開發團隊本身的技術條件。http2.0的部署相對容易很多,客戶端開發者甚至不用做什麼改動,只需要使用iOS9的SDK編譯即可,但缺點是http2.0只能適用於iOS9的裝置。SPDY的部署相對麻煩一些,但優點是可以兼顧iOS6+的裝置。iOS端的SPDY可以使用twitter開發的CocoaSPDY方案,但有一點需要特別處理:
由於蘋果的TLS實現不支援NPN,所以通過NPN協商使用SPDY就無法通過預設443埠來實現。有兩種做法,一是客戶端和server同時約定好使用另一個埠號來做NPN協商,二是server這邊通過request header智慧判斷客戶端是否支援SPDY而越過NPN協商過程。第一種方法會簡單一點,不過需要從框架層將所有的http請求都map到另一個port,url mapping可以參考我之前的一篇文章。twitter自己的網站twitter.com使用的是第二種方法。
瀏覽器端(比如Chrome),server端(比如nginx)都陸續打算放棄支援spdy了,畢竟google官方都宣佈要停止維護了。spdy會是一個過渡方案,會隨著iOS9的普及會逐步消失,所以這部分的技術投入需要開發團隊自己去衡量。
4.2 Android下http現狀
android和iOS情況類似,http2.0只能在新系統下支援,spdy作為過渡方案仍然有存在的必要。
對於使用webview的app來說,需要基於chrome核心的webview才能支援spdy和http2.0,而android系統的webview是從android4.4(KitKat)才改成基於chrome核心的。
對於使用native api呼叫的http請求來說,okhttp是同時支援spdy和http2.0的可行方案。如果使用ALPN,okhttp要求android系統5.0+(實際上,android4.4上就有了ALPN的實現,不過有bug,知道5.0才正式修復),如果使用NPN,可以從android4.0+開始支援,不過NPN也是屬於將要被淘汰的協議。
結束語
以上是HTTP從1.x到SPDY,再到HTTP2.0的一些主要變遷技術點。HTTP2.0正處於逐步應用到線上產品和服務的階段,可以預見未來會有不少新的坑產生和與之對應的優化技巧,HTTP1.x和SPDY也將在一段時間內繼續發揮餘熱。作為工程師,需要了解這些協議背後的技術細節,才能打造高效能的網路框架,從而提升我們的產品體驗。