C語言-指標操作
0.引入
在C語言中,對於任何型別T,我們都可以在T所在的記憶體地址處產生一個包含此物件地址的對應變數。如果用比較直觀地方式來看待這種變數,它們實際上是一種指向物件的變數,因此,這些變數稱為指標。在C語言中,指標的重要性不言而喻,但在很多時候指標又被認為是一把雙刃劍。一方面,指標是構建資料結構和操作記憶體的精確而高效的工具。另一方面,它們又很容易誤用,從而產生不可預知的軟體bug。瞭解到這一點之後,就不奇怪為什麼C語言程式設計師喜歡指標,而其他很多人對它卻深惡痛絕。無論如何,想要有效地使用C語言,我們必須對指標有透徹的瞭解。
理解指標的最佳方法:可以採用畫圖表的方式。
1、指標基礎
回想一下,一個指標其實只是一個變數,它儲存資料在記憶體中的地址而不是儲存資料本身。也就是說,指標包含記憶體地址。很多時候,即使是有經驗的開發人員都很難形象表達這種不太直觀的資料關係,特別是在處理類似於指向其他指標的指標這種更復雜的指標結構時就尤為明顯了。因此,用來理解指標的最好方法之一就是繪製圖表。指標通常都是按位置用箭頭一個一個連線起來,而不是在圖表中畫出實際的地址。當指標不指向任何資料,也就是說指標被設定成NULL時,用兩條豎線來表示。具體圖示如下:
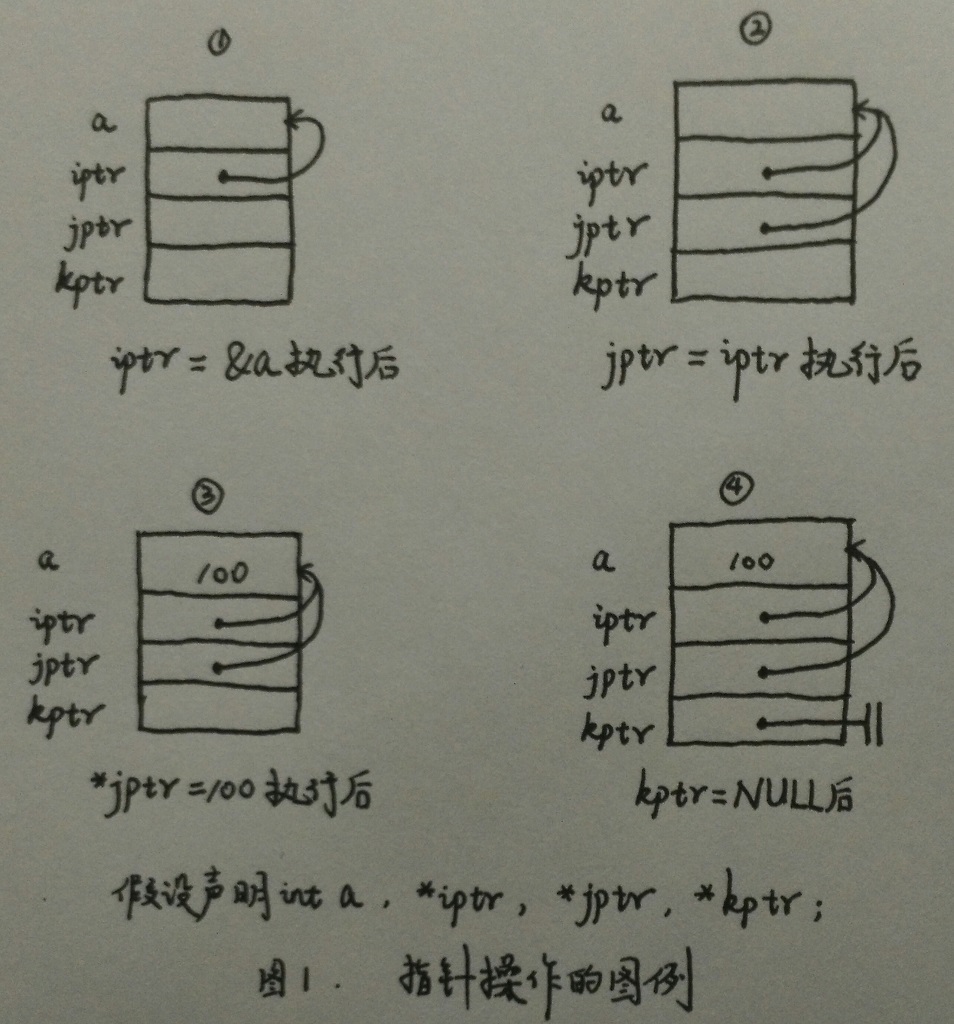
對於其他型別的任何變數,除非我們顯式地指定過,否則我們都不應該假設它指向一個有效的地址。同樣需要注意,在C語言中,我們無法改變的一個事實就是指標能夠指向一個無效的地址。指向無效地址的指標有時被稱為懸空指標。可能產生懸空指標的一些程式設計錯誤示例包括:將任意的整型變數強制轉換為指標變數;操作超出陣列邊界指標;釋放一個或多個仍被引用的指標。
2、儲存空間分配
當在C中宣告一個指標時,與宣告其他型別的變數類似,一定量的儲存空間會被分配給這個指標。通常情況下,指標會佔用一個機器字長的儲存空間,但有些時候它們的大小也有所不同。因此,為了保證程式碼的可移植性,不應該假設每個指標都佔有一個特定大小的儲存空間。指標變數的大小通常與編譯器的設定以及某些特定的C實現中的型別界定符有關。必須要記住一點:當宣告一個指標時,僅僅只是為指標本身分配了空間,並沒有為指標所引用的資料分配空間。而為資料分配儲存空間有兩種方法:一種是直接宣告一個變數;另一種是在執行時動態地分配儲存空間(例如:使用malloc或realloc)。
當宣告一個變數時,編譯器會根據變數的型別預留足夠的記憶體空間。變數的儲存空間是系統自動分配的,但此儲存空間不會在程式的整個生命週期中永久存在,這一點在處理自動變數時尤為重要。自動變數是一種在進入或離開一個模組或函式時其儲存空間能夠自動分配和釋放的變數。例如:在函式f中,iptr的賦值為變數a的地址,當函式f返回時,iptr變成了一個懸空指標。為什麼會這樣?因為當函式f返回時,變數a已經從函式棧中彈出,變成了一個不合法的變數。
int f(int **iptr) {
int a = 30;
*iptr = &a;
return 0;
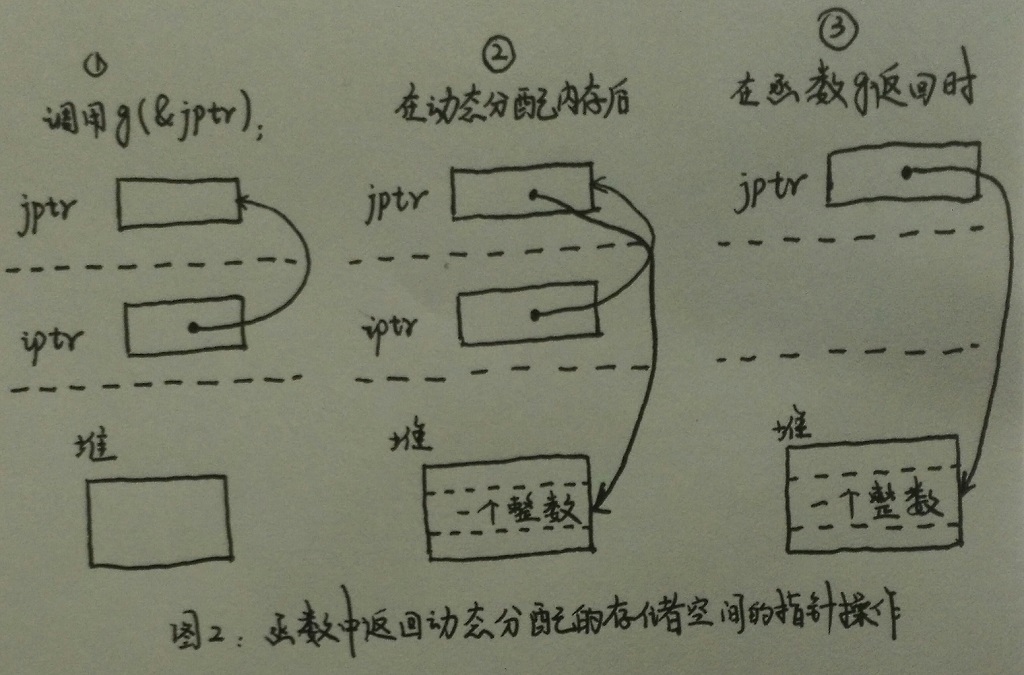
}在C語言中,當想要動態分配儲存空間時,我們會得到一個指向一個堆儲存空間的指標。此儲存空間由我們自行管理,並且會一直存在,除非我們顯式地將它釋放。例如:在下面這段程式碼中,用malloc分配的儲存空間會一直有效直到呼叫函式free來釋放它。所以,當函式g返回時,此儲存空間仍然有效(見圖2),這一點與之前自動分配儲存空間的變數完全不同。引數iptr是一個指向我們想要改變其內容的物件的指標(此物件也是一個指標),所以當g返回時,iptr指向由malloc申請的地址空間。
#include <stdlib.h>
int g(int **iptr) {
if((*iptr = (int *)malloc(sizeof(int))) == NULL)
return -1;
return 0;
}
有些時候,我們甚至會認為指標和動態儲存空間分配是C語言領域中不太好的特性。特別是當產生了由動態記憶體分配所造成的記憶體洩漏問題時。記憶體洩漏問題的產生是由於動態分類記憶體空間,但從未釋放它(甚至在程式不再使用此資料空間時都不釋放它)造成的。特別是在重複執行程式碼時,這種洩漏問題會表現得尤為嚴重。好在我們可以採用統一的記憶體管理方法來大大減少此類問題。
一種統一的記憶體管理方法例子就是資料結構例項。每種例項所遵循的理念是,由使用者來管理儲存空間以及與儲存空間相關的實際的資料結構,而資料結構自身只用於維護資料內部變數的儲存空間分配。所以在資料結構中,只使用指標所指向資料結構,而不是此資料的私有副本。這種應用的一個重要意義在於,一個資料結構的實現並不依賴於它所儲存的資料的型別和大小。同時,多個資料結構能夠以單個資料形態表現,這個特性在組織大量資料時非常有用。
此外,初始化和銷燬資料結構的操作也很重要。初始化可能會涉及很多步驟,其中之一便是記憶體分配。銷燬資料結構通常包括刪除它所有的資料,並釋放資料結構所用到的記憶體。釋放資料結構的記憶體往往也包含釋放與資料結構本身相關聯的所有記憶體。這裡有一個例外,那就是讓使用者自己管理資料的儲存。之所以每個資料結構在初始化的時候都需要使用由使用者提供的初始化函式,是因為資料儲存的管理實際上是一種與具體應用相關的操作。
3、資料集合與指標的算術運算
指標在C語言中最常見的用途就是用來引用資料集合。資料集合是由多個相關聯的元素構成的資料。C語言支援兩種資料集合:結構和陣列。(雖然聯合與結構類似,但一般它單獨被歸為一類。)
結構
結構通常是由各種各樣的有序的元素組成的,從而它可以被看做單個連續的資料型別。結構指標是構建一個資料結構的重要組成部分。結構使我們能把資料捆綁在一起,指標使我們能夠讓這些捆綁包在記憶體中一個一個連線起來。用這些連線起來的結構,我們可以對它們加以組織並用來解決實際的問題。
這裡有一個例子,考慮把記憶體中一些元素組合起來形成一個連結串列。要做到這一點,我們可能會使用下面的程式碼中所示的像listElmt一樣的結構,用每個元素的next來指向下一個元素,並把最後一個元素的next設定為NULL來表示連結串列的結尾。同時,每個元素的data指向此元素所包含的資料。一旦生成了這樣一個列表,就可以用next指標遍歷整個連結串列。
typedef struct ListElmt_ {
void *data;
struct ListElmt_ *next;
} ListElmt;結構ListElmt也指出了關於結構指標的另一個重要方面:結構不允許包含自身的例項,但可以包含指向自身例項的指標。這種程式設計思想非常重要,因為很多資料結構都可能是由它自身的結構變數所組成,例如,在一個連結串列中,每個ListElmt結構都指向另一個ListElmt結構。有些資料結構甚至會包含多個由自身結構型別組成的結構,例如,在一個二叉樹中,每個節點同時指向其他兩個二叉樹的節點。
陣列
陣列是在記憶體中連續排列的同類元素的序列。在C語言中,陣列與指標密不可分。事實上,當一個陣列識別符號在表示式中出現時,C語言顯然會把陣列轉換為一個指向陣列第一個元素的固定指標。考慮到這一點,以下兩個函式是等價的。
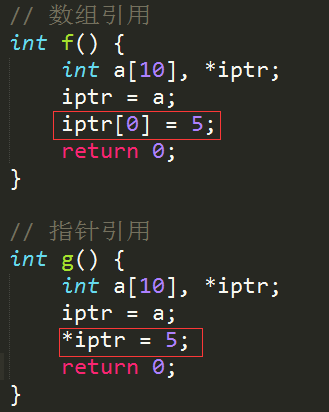
為了理解C語言中指標與陣列的關係,我們做如下解釋。我們知道要訪問一個陣列的第i個元素,用表示式:a[i];
之所以此表示式能夠訪問a的第i個元素,是因為在C語言中,這個表示式與指向a的第i元素的指標表達意思相同,也就是說,該表示式等同於以下表示式:*(a+i);
此表示式實際上使用指標運算的規則來訪問元素。簡單來說,當對指標進行加一個整數i操作時,實際得到了一個地址,這個地址由a所在的地址加上資料型別a所包含位元組數乘以i得到;而並不是簡單地在a所在的地址上加i個位元組。當從指標減去一個整數時也是執行類似的操作。這樣我們也就解釋了為什麼陣列的索引是從0開始的,因為陣列的第一個元素在位置0。
例如:如果一個指標或陣列包含5個4位元組的整數,並且起始地址為0x10000000,那麼a[3]訪問的地址為0x1000000c。這個地址是由0x10000000加上3×4=12=0xc得到的。另一方面,當陣列或指標引用的是20個字元變數時,a[3]將訪問地址0x10000003處的字元。這個地址是由0x10000000加上3×1=3=0x3得到的。當然,通過陣列或指標引用一塊資料與引用多塊資料並沒有什麼不同,因此,很重要的一點是必須對陣列或指標所引用的資料空間大小保持警惕,絕不能越雷池半步。
把一個多維陣列轉換為指標與把一維陣列轉換為指標的過程類似。但是同時要知道在C語言中,多維陣列其實是以行主序的方式儲存的,這也就說明多維陣列右邊下標變化速度要比左邊下標變化來的更快。要訪問一個二維陣列第i行第j列的元素,用以下表示式:a[i][j];
C語言在表示式中將a當做是指向該陣列第1行第1列中元素的指標。整個表示式等價於:*(*(a+i)+j)。
4、作為函式引數的指標
在C語言的函式呼叫中指標起著至關重要的作用。最重要的是,指標支援將引數作為引用傳遞給函式(即按引用呼叫)。按引用傳遞引數時,當函式改變此引數時,這個被改變引數的值會一直存在,甚至函式退出後都仍然存在。相對而言,當按值呼叫傳遞函式引數時,此時值的改變只能持續到函式返回時。無論是否要改變函式的輸入輸出引數,使用指標傳遞大容量複雜的函式引數也是十分高效的手段。這種方法高效的原因在於,我們只是傳遞一個指標而不是一個資料的完整副本到函式中,這樣就可以大大地節省記憶體空間。
按引用呼叫傳遞引數
在形式上,C語言只支援按值來傳遞引數。在按值呼叫傳遞引數的過程中,函式引數的一份私有副本將會用到函式的執行體中。然而,我們可以模仿按引用呼叫傳遞引數將一個指向引數的指標(而不是引數本身)傳遞給函式,這樣函式呼叫者就可以得到一個指標的私有副本用於函式體的執行過程。
要了解按引用呼叫是如何實現的,我們來看看swap1。swap1是一個實現將兩個整型變數相互交換的函式,函式引數是通過按值呼叫傳遞的,所以得到的結果是錯誤的。下圖給出了為什麼交換函式不起作用。

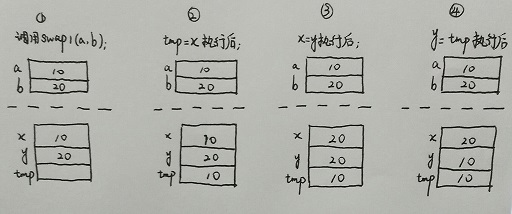
swap2同樣是一個交換函式嗎,只是它的引數是按引用呼叫傳遞的。下圖說明如何使用指標來修正swap1中的錯誤。

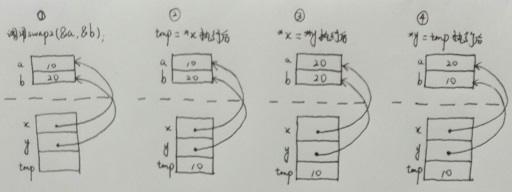
關於C語言中按引用呼叫傳遞引數,其好的一面是語言本身賦予了我們精確控制引數傳遞的能力。不好的方面是,這種控制有時候會顯得很麻煩,因為我們常常需要在函式中多次解引用按引用呼叫的引數。
另一個在函式呼叫時會用到指標的地方,就是把陣列傳遞給函式的時候。回顧之前我們所說的,C語言顯然把陣列名當做一個不可變的指標來使用,當向函式傳遞一個型別為T的陣列物件時,其實就等同於向函式傳遞一個指向型別為T的物件的指標。所以,我們可以交替使用這兩種方法。例如:函式f1和函式f2是功能相同的。
具體使用哪種方式來傳遞引數取決於約定俗成或函式處理引數的方法。當使用一個陣列作為引數時,陣列的邊界資訊並不重要,因此此時編譯器並不要求陣列有邊界資訊。但是,提供邊界資訊對於表達出函式內部處理該引數具有一定的侷限性是一種很有用的方法。在使用多維陣列作為引數的函式中,邊界資訊顯得尤為重要。


當把一個多維陣列傳遞給函式時,除了第一維以外,其他維的長度必須指定,這樣函式才能通過指標算術運算訪問具體元素,如以下程式碼所示:
int g(int a[][2]) {
a[2][0] = 5;
return 0;
}為了更清楚地理解為什麼必須指定其他維度的大小,設定有一個3行2列的整型二維陣列。在C語言中,此二維陣列的元素在記憶體中按照地址的遞增一行一行順序排列。就是說,第1行的兩個整數儲存在前兩個位置,接著是第2行的兩個整數,再接著是第3行的兩個整數。所以,如果想訪問到任意一行的元素(除了第一行)時,我們首先必須確定達到這一行我們需要跳過多少個連續的元素,故此需要知道後面其他維度的大小。
作為引數指向指標的指標
實際中,有很多把指標當做引數傳遞給函式的地方,這是由於函式想改變傳遞給它的指標。想做到這一點,向函式傳遞一個待改變的指向指標的指標。例如:
int list_rem_next(List *list, listElmt *element, void **data);假設這個函式的功能是從連結串列中刪除一個元素。當此函式返回時,data指向連結串列中被刪除的元素。由於此函式需要改變data使data指向被刪除的那個元素,因此必須將指標data的地址傳遞給函式以模仿按引用傳遞引數。所以,函式接受一個指向指標的指標作為它的第三個引數。具體圖示如下:
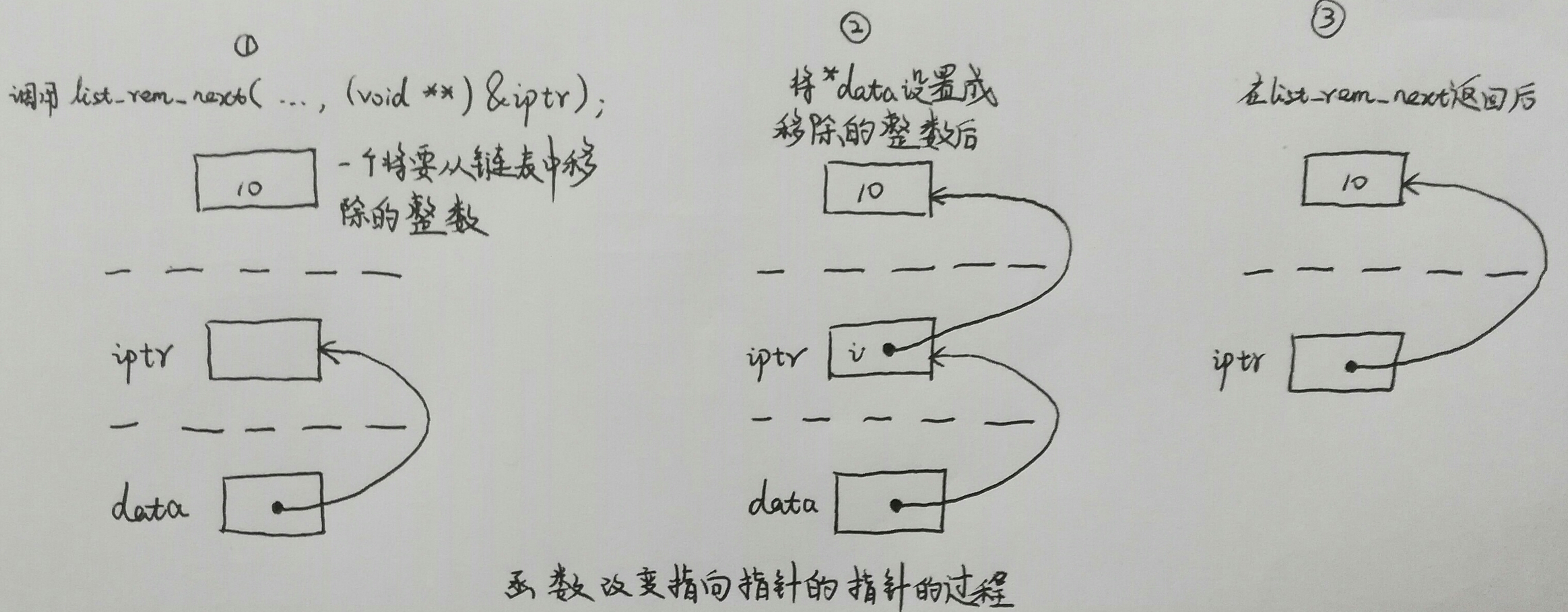
5、泛型指標與型別轉換
回想一下,在C語言中指標變數擁有與其他變數一樣的型別。之所以指標變數會有型別是因為當我們想獲取指標變數的值時,編譯器已經知道指標所指向的資料的型別,從而可以訪問相應的資料。但是,有些時候我們並不關心指標所指向的變數的型別。在這種情況下,就可以使用泛型指標,泛型指標並不指定具體的資料型別。
泛型指標
通常情況下,C只允許相同型別的指標之間進行轉換。例如:一個字元型指標sptr(一個字串)和一個整型指標iptr,我們不允許把sptr轉換為iptr或把iptr轉換為sptr。
但是泛型指標能夠轉換為任何型別的指標,反之亦然。因此,如果有一個泛型指標gptr,就可以把sptr轉換為gptr或者把gptr轉換為sptr。在C語言中,通常宣告一個void指標來表示泛型指標。
很多情況下,void指標都是非常有用的。例如:C標準函式庫中的memcpy函式,它將一段資料從記憶體中的一個地方複製到另一個地方。由於memcpy可能用來賦值任何型別的資料,因此,將它的指標引數設定為void指標是非常合理的。void指標同樣也可以用到其他普通的函式中。例如:之前提到的交換函式swap2,可以把函式引數改為void指標,這樣swap2就變成一個可以交換任何型別資料的通用交換函式,程式碼如下:
#include <stdlib.h>
#include <string.h>
int swap2(void *x, void *y, int size) {
void *tmp;
if((tmp = malloc(size)) == NULL)
return -1;
memcpy(tmp, x, size);
memcpy(x, y, size);
memcpy(y, tmp, size);
free(tmp);
return 0;
}void指標在用來實現資料結構時是非常有用的,因為可以通過void指標儲存和檢索任何型別的資料。我們再來看一下之前提到過的連結串列結構ListElmt,回想一下,這個結構包含兩個成員:data和next。如果data被宣告為一個void指標,那麼data就可以指向任何型別的資料。從而,我們就可以使用ListElmt結構來建立各種不同資料型別的連結串列。
假設定義了一個連結串列的操作函式list_ins_next,它的功能是將一個指向data的指標元素插入連結串列中:
int list_ins_next(List *list, ListElmt *element, void *data);要將指標iptr引用的整數插入名為list的整型連結串列中,element引用的元素後面,使用以下呼叫。C語言允許將整型指標iptr賦值給引數data,因為data是一個void指標。
retval = list_ins_next(&list, element, iptr);當然,當從一個連結串列中刪除資料時,必須使用正確的指標型別來檢索要刪除的資料。這樣做是為了保證當我們想要對資料進行操作時資料的型別是正確的。如前所述,從一個連結串列中刪除元素的函式是list_rem_next,它的第三個引數是一個指向void指標的指標:
int list_rem_next(List *list, ListElmt *element, void **data);想要從list中element引用的元素後面刪除一個整型變數,用如下呼叫方式。當函式返回時,iptr指向已刪除的資料。這是由於此操作改變了指標本身,使其指向已刪除的資料,因此傳遞iptr指標的地址:
retval = list_rem_next(&list, element, (void **)&iptr);同時,此函式呼叫包含一個將iptr臨時轉換為指向void指標的指標的過程。正如我們之後要講到的,型別轉換是C語言中一種特殊的轉換機制,它允許我們臨時把一種型別的變數轉換為另一種型別的變數。在這裡,型別轉換是必須的,因為C語言中雖然一個void指標與其他型別的指標相相容,但一個指向void指標的指標並不一定與其他型別的指標相容。
型別轉換
要將型別為T的變數t轉換成S型別,只需要在t前加上用圓括號括上的S。例如,要將一個整型指標iptr轉換為一個浮點型指標fptr,在整型指標前面加上一個用圓括號括起來的浮點指標即可,如下所示:
fptr = (float *)iptr;(通常來說,將一個整型指標轉換為一個浮點型指標是一種危險的做法,但是在這裡僅僅用這個例子做一個型別轉換的例項而已。)在型別轉換之後,iptr與fptr都指向同一塊記憶體地址。但是,從這個地址取到什麼型別的值是由我們用什麼型別的指標訪問它所決定的。
對於泛型指標來說型別轉換非常重要,因為只有告訴泛型指標是通過何種型別來訪問地址時,泛型指標才能取到正確的值。這是由於泛型指標不會告訴編譯器它所指向的是何種型別資料,因此編譯器既不知道多少個位元組要被訪問,也不知道應該如何解析位元組。當將泛型指標賦值給其他型別的指標時,使用型別轉換也是一種很好的程式碼自注釋方法。儘管這裡的轉換並不是必需的,但這樣做能夠大大提高程式的可讀性。
當轉換指標時,我們對記憶體中的資料對齊方式必須特別注意。具體來說,我們需要知道,指標的型別轉換會破壞計算機本身的對齊方式。很多計算機對對齊方式有要求,以便某些硬體的優化可以使訪問記憶體更有效率。例如,一個系統可能要求所有整數按字邊界對齊。所以,如果有一個非按字對齊的void指標,當將它轉換為一個整型指標並試圖獲取它的值時,程式可能在執行時出現異常。
6、函式指標
函式指標是指向可執行程式碼段或呼叫可執行程式碼段的資訊塊的指標,而不是指向某種資料的指標。函式指標將函式當做普通資料那樣儲存和管理。函式指標有一種固定的形式,就是包含一個確定的返回值型別和若干個函式引數。宣告一個函式指標看起來與宣告一個函式非常類似,只是在函式名之前有一個表示指標的星號(*),並且函式名和星號會用圓括號括起來。例如下面這段程式碼中,match被宣告為一個函式指標,它接受兩個void指標型別的引數,同時返回一個整型:
int (*match)(void *key1, void *key2);以上函式宣告的意思是,我們指定一個函式指標,它接受兩個void指標,返回一個整型數,命名為match。例如:假設有一個match_int函式,它的兩個void指標引數指向整型並返回1。考慮到之前的函式宣告match,可以這樣賦值:
match = match_int;要執行一個由函式指標所引用的函式,只需要在正常呼叫普通函式的地方呼叫函式指標。例如:想要呼叫之前提到的函式指標match,執行下面的語句,假設x,y和retval都已經宣告為整型:
retval = match(&x, &y);常見的函式指標的重要用途:將函式封裝到資料結構中。例如:在實現鏈式雜湊表時,這個雜湊表資料結構就包含一個成員,類似以上所提到的名為match的函式指標。此指標的作用是,當任何時候我們需要判斷正在查詢的元素是否匹配表中的元素時,都可以呼叫一個函式來完成。當雜湊表初始化時,把某個函式賦給這個指標。賦給指標的這個函式與match有相同的原型,不同之處是,在內部進行兩個元素的比較時,函式會根據雜湊表中的資料型別進行具體型別的資料比較。使用指標把函式另存為資料結構的一部分是C語言一種非常好的特性,因為它可以使資料結構或函式變得更具通用性。
相關文章
- C語言 C語言野指標C語言指標
- C語言(指標)C語言指標
- C語言指標C語言指標
- c 語言指標操作經典問題指標
- C語言指標(二) 指標變數 ----by xhxhC語言指標變數
- c語言指標彙總C語言指標
- C語言指標學習C語言指標
- c語言指標詳解C語言指標
- C語言基礎-指標C語言指標
- C語言 函式指標C語言函式指標
- C語言指標筆記C語言指標筆記
- C語言指標(三):陣列指標和字串指標C語言指標陣列字串
- C語言:指標,C的靈魂C語言指標
- C語言指標安全及指標使用問題C語言指標
- C語言知識彙總 | 51-C語言字串指標(指向字串的指標)C語言字串指標
- 搞清楚C語言指標C語言指標
- C語言 指標與陣列C語言指標陣列
- C語言指標基本知識C語言指標
- C語言指標詳解(一)C語言指標
- C語言指標詳解(二)C語言指標
- C語言指標用法大全C語言指標
- c語言實現this指標效果C語言指標
- C語言指標細節_1C語言指標
- 指標——C語言的靈魂指標C語言
- C語言基礎-1、指標C語言指標
- C語言知識彙總 | 56-C語言NULL空指標以及void指標C語言Null指標
- C語言指標常見問題C語言指標
- c語言-運算子,陣列,指標C語言陣列指標
- Swift中使用C語言的指標SwiftC語言指標
- C語言函式指標基礎C語言函式指標
- 走下“神壇”的C語言指標C語言指標
- C語言指標5分鐘教程C語言指標
- C 語言指標 5 分鐘教程指標
- C語言學習之:指標與字串C語言指標字串
- C語言_瞭解下結構體指標C語言結構體指標
- C語言指標部分教學總結C語言指標
- C語言指標和陣列基礎C語言指標陣列
- C語言指標應用程式設計C語言指標程式設計