學習排序演算法(二):Pairwise方法之RankNet
學習排序演算法(二):Pairwise方法之RankNet
前面一篇博文介紹的Ranking SVM是把LTR問題轉化為二值分類問題,而RankNet演算法是從另外一個角度來解決,那就是概率的角度。
1. RankNet的基本思想
RankNet方法就是使用交叉熵作為損失函式,學習出一些模型(例如神經網路、決策樹等)來計算每個pair的排序得分,學習模型的過程可以使用梯度下降法。
2. 方法流程
首先,我們要明確RankNet方法的目的就是要學習出一個模型,這個模型就是給文件演算法的函式f(d, w)。其中d為文件特徵,w為模型引數。
輸入:query的許多個文件結果,每個文件需要人為標註得分,等分越高的說明排名越靠前;
輸出:打分模型f(d, w)。
Step 1:把query的結果分成pair,計算pair中排名的概率。在pair中,如果Ui排在Uj的前面,概率為:
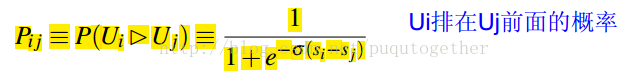
而Ui排在Uj的前面的真實概率計算為:
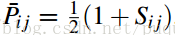
其中Sij=1表明Ui真實情況就是排在Uj的前面;否則,就是Ui排在Uj的後面。
Step 2:交叉熵作為損失函式。

這個損失函式是用來衡量Pij和Pij_的擬合程度的,當兩個文件的不相關時,給與了一定的懲罰,讓它們分開。RankNet演算法沒有使用學習排序中的一些衡量指標直接作為損失函式的原因在於,它們的函式形式都不是很連續,不太好求導,也就不太好用梯度下降法。而交叉熵的函式形式比較適合梯度下降法。
Step 3:梯度下降法更新迭代求最優的模型引數w。顯然,我們需要設定一定的學習步長,不斷的更新學習新的w,具體公式如下:
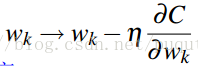
後面就是求損失函式C關於w的偏導計算公式了,如下:
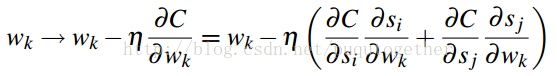
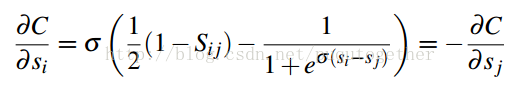
上式中,得分s關於w的偏導和具體的學習模型有關,原始的RankNet方法使用的是神經網路模型。這個需要具體模型,具體分析。
這樣我們便直到了如何通過梯度下降法來求RankNet中的打分模型了~
最後我們說一下RankNet演算法的一大好處:使用的是交叉熵作為損失函式,它求導方便,適合梯度下降法的框架;而且,即使兩個不相關的文件的得分相同時,C也不為零,還是會有懲罰項的。
相關文章
- 演算法學習之簡單排序演算法排序
- 演算法學習之選擇排序和堆排序:演算法排序
- 演算法導論學習之二:插入排序演算法排序
- 演算法導論學習之五:快速排序演算法排序
- 再理解RankNet演算法演算法
- 演算法導論學習之六:歸併排序演算法排序
- 看動畫學演算法之:排序-count排序動畫演算法排序
- 看動畫學演算法之:排序-快速排序動畫演算法排序
- 排序演算法之——二分插入排序演算法排序演算法
- 演算法學習之直接插入排序(java)演算法排序Java
- 看動畫學演算法之:排序-基數排序動畫演算法排序
- 演算法學習 – 歸併排序演算法排序
- 演算法學習 - 歸併排序演算法排序
- 演算法學習之路|快速排序演算法排序
- 演算法學習-遞迴排序演算法遞迴排序
- IOS中學習排序演算法iOS排序演算法
- 演算法學習 - 基礎排序演算法演算法排序
- 學習筆記--- 比較排序之堆排序筆記排序
- 複習資料結構:排序演算法(二)——氣泡排序資料結構排序演算法
- PHP常見排序演算法學習PHP排序演算法
- 排序演算法(二)排序演算法
- 【一起學習排序演算法】3 選擇排序排序演算法
- 【一起學習排序演算法】2 氣泡排序排序演算法
- 【一起學習排序演算法】4 插入排序排序演算法
- 演算法導論學習之三:排序之C語言實現:選擇排序,插入排序,歸併排序演算法排序C語言
- 【SQL 學習】排序問題之order by與索引排序SQL排序索引
- 排序演算法之 '快速排序'排序演算法
- 排序演算法之——桶排序排序演算法
- 排序演算法之希爾排序排序演算法
- golang sort.Sort () 排序演算法學習Golang排序演算法
- Java學習之7種排序演算法的完整例項程式碼Java排序演算法
- 排序演算法之 '歸併排序'排序演算法
- PHP 排序演算法之希爾排序PHP排序演算法
- 常用排序演算法之桶排序排序演算法
- InnoDB學習(二)之ChangeBuffer
- 【一起學習排序演算法】0 序言排序演算法
- Elasticsearch聚合學習之四:結果排序Elasticsearch排序
- RSA演算法之學習演算法