字元編碼是計算機程式設計中不可迴避的問題,不管你用 Python2 還是 Python3,亦或是 C++, Java 等,我都覺得非常有必要釐清計算機中的字元編碼概念。本文主要分以下幾個部分介紹:
- 基本概念
- 常見字元編碼簡介
- Python 的預設編碼
- Python2 中的字元型別
- UnicodeEncodeError & UnicodeDecodeError 根源
基本概念
- 字元(Character)
在電腦和電信領域中,字元是一個資訊單位,它是各種文字和符號的總稱,包括各國家文字、標點符號、圖形符號、數字等。比如,一個漢字,一個英文字母,一個標點符號等都是一個字元。
- 字符集(Character set)
字符集是字元的集合。字符集的種類較多,每個字符集包含的字元個數也不同。比如,常見的字符集有 ASCII 字符集、GB2312 字符集、Unicode 字符集等,其中,ASCII 字符集共有 128 個字元,包含可顯示字元(比如英文大小寫字元、阿拉伯數字)和控制字元(比如空格鍵、Enter鍵);GB2312 字符集是中國國家標準的簡體中文字符集,包含簡化漢字、一般符號、數字等;Unicode 字符集則包含了世界各國語言中使用到的所有字元,
- 字元編碼(Character encoding)
字元編碼,是指對於字符集中的字元,將其編碼為特定的二進位制數,以便計算機處理。常見的字元編碼有 ASCII 編碼,UTF-8 編碼,GBK 編碼等。一般而言,字符集和字元編碼往往被認為是同義的概念,比如,對於字符集 ASCII,它除了有「字元的集合」這層含義外,同時也包含了「編碼」的含義,也就是說,ASCII 既表示了字符集也表示了對應的字元編碼。
下面我們用一個表格做下總結:
| 概念 | 概念描述 | 舉例 |
|---|---|---|
| 字元 | 一個資訊單位,各種文字和符號的總稱 | ‘中’, ‘a’, ‘1’, ‘$’, ‘¥’, … |
| 字符集 | 字元的集合 | ASCII 字符集, GB2312 字符集, Unicode 字符集 |
| 字元編碼 | 將字符集中的字元,編碼為特定的二進位制數 | ASCII 編碼,GB2312 編碼,Unicode 編碼 |
| 位元組 | 計算機中儲存資料的單元,一個 8 位(bit)的二進位制數 | 0x01, 0x45, … |
常見字元編碼簡介
常見的字元編碼有 ASCII 編碼,GBK 編碼,Unicode 編碼和 UTF-8 編碼等等。這裡,我們主要介紹 ASCII、Unicode 和 UTF-8。
ASCII
計算機是在美國誕生的,人家用的是英語,而在英語的世界裡,不過就是英文字母,數字和一些普通符號的組合而已。
在 20 世紀 60 年代,美國製定了一套字元編碼方案,規定了英文字母,數字和一些普通符號跟二進位制的轉換關係,被稱為 ASCII (American Standard Code for Information Interchange,美國資訊互換標準編碼) 碼。
比如,大寫英文字母 A 的二進位制表示是 01000001(十進位制 65),小寫英文字母 a 的二進位制表示是 01100001 (十進位制 97),空格 SPACE 的二進位制表示是 00100000(十進位制 32)。
Unicode
ASCII 碼只規定了 128 個字元的編碼,這在美國是夠用的。可是,計算機後來傳到了歐洲,亞洲,乃至世界各地,而世界各國的語言幾乎是完全不一樣的,用 ASCII 碼來表示其他語言是遠遠不夠的,所以,不同的國家和地區又制定了自己的編碼方案,比如中國大陸的 GB2312 編碼 和 GBK 編碼等,日本的 Shift_JIS 編碼等等。
雖然各個國家和地區可以制定自己的編碼方案,但不同國家和地區的計算機在資料傳輸的過程中就會出現各種各樣的亂碼(mojibake),這無疑是個災難。
怎麼辦?想法也很簡單,就是將全世界所有的語言統一成一套編碼方案,這套編碼方案就叫 Unicode,它為每種語言的每個字元設定了獨一無二的二進位制編碼,這樣就可以跨語言,跨平臺進行文字處理了,是不是很棒!
Unicode 1.0 版誕生於 1991 年 10 月,至今它仍在不斷增修,每個新版本都會加入更多新的字元,目前最新的版本為 2016 年 6 月 21 日公佈的 9.0.0。
Unicode 標準使用十六進位制數字,而且在數字前面加上字首 U+,比如,大寫字母「A」的 unicode 編碼為 U+0041,漢字「嚴」的 unicode 編碼為 U+4E25。更多的符號對應表,可以查詢 unicode.org,或者專門的漢字對應表。
UTF-8
Unicode 看起來已經很完美了,實現了大一統。但是,Unicode 卻存在一個很大的問題:資源浪費。
為什麼這麼說呢?原來,Unicode 為了能表示世界各國所有文字,一開始用兩個位元組,後來發現兩個位元組不夠用,又用了四個位元組。比如,漢字「嚴」的 unicode 編碼是十六進位制數 4E25,轉換成二進位制有十五位,即 100111000100101,因此至少需要兩個位元組才能表示這個漢字,但是對於其他的字元,就可能需要三個或四個位元組,甚至更多。
這時,問題就來了,如果以前的 ASCII 字符集也用這種方式來表示,那豈不是很浪費儲存空間。比如,大寫字母「A」的二進位制編碼為 01000001,它只需要一個位元組就夠了,如果 unicode 統一使用三個位元組或四個位元組來表示字元,那「A」的二進位制編碼的前面幾個位元組就都是 0,這是很浪費儲存空間的。
為了解決這個問題,在 Unicode 的基礎上,人們實現了 UTF-16, UTF-32 和 UTF-8。下面只說一下 UTF-8。
UTF-8 (8-bit Unicode Transformation Format) 是一種針對 Unicode 的可變長度字元編碼,它使用一到四個位元組來表示字元,例如,ASCII 字元繼續使用一個位元組編碼,阿拉伯文、希臘文等使用兩個位元組編碼,常用漢字使用三個位元組編碼,等等。
因此,我們說,UTF-8 是 Unicode 的實現方式之一,其他實現方式還包括 UTF-16(字元用兩個或四個位元組表示)和 UTF-32(字元用四個位元組表示)。
Python 的預設編碼
Python2 的預設編碼是 ascii,Python3 的預設編碼是 utf-8,可以通過下面的方式獲取:
- Python2
123456Python 2.7.11 (default, Feb 24 2016, 10:48:05)[GCC 4.2.1 Compatible Apple LLVM 7.0.2 (clang-700.1.81)] on darwinType "help", "copyright", "credits" or "license" for more information.>>> import sys>>> sys.getdefaultencoding()'ascii'
- Python3
123456Python 3.5.2 (default, Jun 29 2016, 13:43:58)[GCC 4.2.1 Compatible Apple LLVM 7.3.0 (clang-703.0.31)] on darwinType "help", "copyright", "credits" or "license" for more information.>>> import sys>>> sys.getdefaultencoding()'utf-8'
Python2 中的字元型別
Python2 中有兩種和字串相關的型別:str 和 unicode,它們的父類是 basestring。其中,str 型別的字串有多種編碼方式,預設是 ascii,還有 gbk,utf-8 等,unicode 型別的字串使用 u'...' 的形式來表示,下面的圖展示了 str 和 unicode 之間的關係:
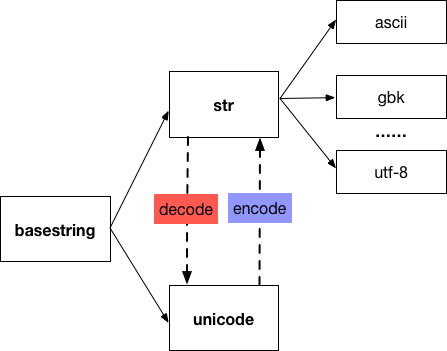
兩種字串的相互轉換概括如下:
- 把 UTF-8 編碼表示的字串 ‘xxx’ 轉換為 Unicode 字串 u’xxx’ 用
decode('utf-8')方法:
12>>> '中文'.decode('utf-8')u'\u4e2d\u6587'
- 把 u’xxx’ 轉換為 UTF-8 編碼的 ‘xxx’ 用
encode('utf-8')方法:
12>>> u'中文'.encode('utf-8')'\xe4\xb8\xad\xe6\x96\x87'
UnicodeEncodeError & UnicodeDecodeError 根源
用 Python2 編寫程式的時候經常會遇到 UnicodeEncodeError 和 UnicodeDecodeError,它們出現的根源就是如果程式碼裡面混合使用了 str 型別和 unicode 型別的字串,Python 會預設使用 ascii 編碼嘗試對 unicode 型別的字串編碼 (encode),或對 str 型別的字串解碼 (decode),這時就很可能出現上述錯誤。
下面有兩個常見的場景,我們最好牢牢記住:
- 在進行同時包含 str 型別和 unicode 型別的字串操作時,Python2 一律都把 str 解碼(decode)成 unicode 再運算,這時就很容易出現 UnicodeDecodeError。
讓我們看看例子:
|
1 2 3 4 5 6 |
>>> s = '你好' # str 型別, utf-8 編碼 >>> u = u'世界' # unicode 型別 >>> s + u # 會進行隱式轉換,即 s.decode('ascii') + u Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeDecodeError: 'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128) |
為了避免出錯,我們就需要顯示指定使用 ‘utf-8’ 進行解碼,如下:
|
1 2 3 4 5 |
>>> s = '你好' # str 型別,utf-8 編碼 >>> u = u'世界' >>> >>> s.decode('utf-8') + u # 顯示指定 'utf-8' 進行轉換 u'\u4f60\u597d\u4e16\u754c' # 注意這不是錯誤,這是 unicode 字串 |
- 如果函式或類等物件接收的是 str 型別的字串,但你傳的是 unicode,Python2 會預設使用 ascii 將其編碼成 str 型別再運算,這時就很容易出現 UnicodeEncodeError。
讓我們看看例子:
|
1 2 3 4 5 |
>>> u_str = u'你好' >>> str(u_str) Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128) |
在上面的程式碼中,u_str 是一個 unicode 型別的字串,由於 str() 的引數只能是 str 型別,此時 Python 會試圖使用 ascii 將其編碼成 ascii,也就是:
|
1 |
u_str.encode('ascii') // u_str 是 unicode 字串 |
上面將 unicode 型別的中文使用 ascii 編碼轉,肯定會出錯。
再看一個使用 raw_input 的例子,注意 raw_input 只接收 str 型別的字串:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
>>> name = raw_input('input your name: ') input your name: ethan >>> name 'ethan' >>> name = raw_input('輸入你的姓名:') 輸入你的姓名: 小明 >>> name '\xe5\xb0\x8f\xe6\x98\x8e' >>> type(name) <type 'str'> >>> name = raw_input(u'輸入你的姓名: ') # 會試圖使用 u'輸入你的姓名'.encode('ascii') Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-5: ordinal not in range(128) >>> name = raw_input(u'輸入你的姓名: '.encode('utf-8')) #可以,但此時 name 不是 unicode 型別 輸入你的姓名: 小明 >>> name '\xe5\xb0\x8f\xe6\x98\x8e' >>> type(name) <type 'str'> >>> name = raw_input(u'輸入你的姓名: '.encode('utf-8')).decode('utf-8') # 推薦 輸入你的姓名: 小明 >>> name u'\u5c0f\u660e' >>> type(name) <type 'unicode'> |
再看一個重定向的例子:
|
1 2 |
hello = u'你好' print hello |
將上面的程式碼儲存到檔案 hello.py,在終端執行 python hello.py 可以正常列印,但是如果將其重定向到檔案 python hello.py > result 會發現 UnicodeEncodeError。
這是因為:輸出到控制檯時,print 使用的是控制檯的預設編碼,而重定向到檔案時,print 就不知道使用什麼編碼了,於是就使用了預設編碼 ascii 導致出現編碼錯誤。
應該改成如下:
|
1 2 |
hello = u'你好' print hello.encode('utf-8') |
這樣執行 python hello.py > result 就沒有問題。
小結
- UTF-8 是一種針對 Unicode 的可變長度字元編碼,它是 Unicode 的實現方式之一。
- Unicode 字符集有多種編碼標準,比如 UTF-8, UTF-7, UTF-16。
- 在進行同時包含 str 型別和 unicode 型別的字串操作時,Python2 一律都把 str 解碼(decode)成 unicode 再運算。
- 如果函式或類等物件接收的是 str 型別的字串,但你傳的是 unicode,Python2 會預設使用 ascii 將其編碼成 str 型別再運算。