C/C++編譯過程詳解
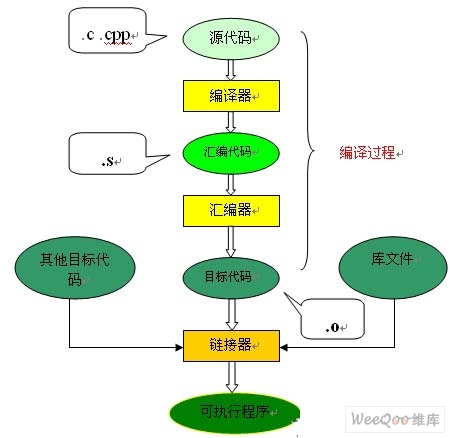
從圖上可以看到,整個程式碼的編譯過程分為編譯和連結兩個過程,編譯對應圖中的大括號括起的部分,其餘則為連結過程。
編譯過程
編譯過程又可以分成兩個階段:編譯和彙編。
編譯
編譯是讀取源程式(字元流),對之進行詞法和語法的分析,將高階語言指令轉換為功能等效的彙編程式碼,原始檔的編譯過程包含兩個主要階段:
第一個階段是預處理階段,在正式的編譯階段之前進行。預處理階段將根據已放置在檔案中的預處理指令來修改原始檔的內容。如#include指令就是一個預處理指令,它把標頭檔案的內容新增到.cpp檔案中。這個在編譯之前修改原始檔的方式提供了很大的靈活性,以適應不同的計算機和作業系統環境的限制。一個環境需要的程式碼跟另一個環境所需的程式碼可能有所不同,因為可用的硬體或作業系統是不同的。在許多情況下,可以把用於不同環境的程式碼放在同一個檔案中,再在預處理階段修改程式碼,使之適應當前的環境。
主要是以下幾方面的處理:
(1)巨集定義指令,如 #define a b
對於這種偽指令,預編譯所要做的是將程式中的所有a用b替換,但作為字串常量的 a則不被替換。還有 #undef,則將取消對某個巨集的定義,使以後該串的出現不再被替換。
(2)條件編譯指令,如#ifdef,#ifndef,#else,#elif,#endif等。
這些偽指令的引入使得程式設計師可以通過定義不同的巨集來決定編譯程式對哪些程式碼進行處理。預編譯程式將根據有關的檔案,將那些不必要的程式碼過濾掉。
(3) 標頭檔案包含指令,如#include "FileName"或者#include <FileName>等。
在標頭檔案中一般用偽指令#define定義了大量的巨集(最常見的是字元常量),同時包含有各種外部符號的宣告。採用標頭檔案的目的主要是為了使某些定義可以供多個不同的C源程式使用。因為在需要用到這些定義的C源程式中,只需加上一條#include語句即可,而不必再在此檔案中將這些定義重複一遍。預編譯程式將把標頭檔案中的定義統統都加入到它所產生的輸出檔案中,以供編譯程式對之進行處理。包含到c源程式中的標頭檔案可以是系統提供的,這些標頭檔案一般被放在 /usr/include目錄下。在程式中#include它們要使用尖括號(< >)。另外開發人員也可以定義自己的標頭檔案,這些檔案一般與c源程式放在同一目錄下,此時在#include中要用雙引號("")。
(4)特殊符號,預編譯程式可以識別一些特殊的符號。
例如在源程式中出現的LINE標識將被解釋為當前行號(十進位制數),FILE則被解釋為當前被編譯的C源程式的名稱。預編譯程式對於在源程式中出現的這些串將用合適的值進行替換。
預編譯程式所完成的基本上是對源程式的“替代”工作。經過此種替代,生成一個沒有巨集定義、沒有條件編譯指令、沒有特殊符號的輸出檔案。這個檔案的含義同沒有經過預處理的原始檔是相同的,但內容有所不同。下一步,此輸出檔案將作為編譯程式的輸出而被翻譯成為機器指令。
第二個階段編譯、優化階段,經過預編譯得到的輸出檔案中,只有常量;如數字、字串、變數的定義,以及C語言的關鍵字,如main,if,else,for,while,{,}, +,-,*,\等等。
編譯程式所要作得工作就是通過詞法分析和語法分析,在確認所有的指令都符合語法規則之後,將其翻譯成等價的中間代碼錶示或彙編程式碼。
優化處理是編譯系統中一項比較艱深的技術。它涉及到的問題不僅同編譯技術本身有關,而且同機器的硬體環境也有很大的關係。優化一部分是對中間程式碼的優化。這種優化不依賴於具體的計算機。另一種優化則主要針對目的碼的生成而進行的。
對於前一種優化,主要的工作是刪除公共表示式、迴圈優化(程式碼外提、強度削弱、變換迴圈控制條件、已知量的合併等)、複寫傳播,以及無用賦值的刪除,等等。
後一種型別的優化同機器的硬體結構密切相關,最主要的是考慮是如何充分利用機器的各個硬體暫存器存放的有關變數的值,以減少對於記憶體的訪問次數。另外,如何根據機器硬體執行指令的特點(如流水線、RISC、CISC、VLIW等)而對指令進行一些調整使目的碼比較短,執行的效率比較高,也是一個重要的研究課題。
彙編
彙編實際上指把組合語言程式碼翻譯成目標機器指令的過程。對於被翻譯系統處理的每一個C語言源程式,都將最終經過這一處理而得到相應的目標檔案。目標檔案中所存放的也就是與源程式等效的目標的機器語言程式碼。目標檔案由段組成。通常一個目標檔案中至少有兩個段:
程式碼段:該段中所包含的主要是程式的指令。該段一般是可讀和可執行的,但一般卻不可寫。
資料段:主要存放程式中要用到的各種全域性變數或靜態的資料。一般資料段都是可讀,可寫,可執行的。
UNIX環境下主要有三種型別的目標檔案:
(1)可重定位檔案
其中包含有適合於其它目標檔案連結來建立一個可執行的或者共享的目標檔案的程式碼和資料。
(2)共享的目標檔案
這種檔案存放了適合於在兩種上下文裡連結的程式碼和資料。第一種是連結程式可把它與其它可重定位檔案及共享的目標檔案一起處理來建立另一個 目標檔案;第二種是動態連結程式將它與另一個可執行檔案及其它的共享目標檔案結合到一起,建立一個程式映象。
(3)可執行檔案
它包含了一個可以被作業系統建立一個程式來執行之的檔案。彙編程式生成的實際上是第一種型別的目標檔案。對於後兩種還需要其他的一些處理方能得到,這個就是連結程式的工作了。
連結過程
由彙編程式生成的目標檔案並不能立即就被執行,其中可能還有許多沒有解決的問題。
例如,某個原始檔中的函式可能引用了另一個原始檔中定義的某個符號(如變數或者函式呼叫等);在程式中可能呼叫了某個庫檔案中的函式,等等。所有的這些問題,都需要經連結程式的處理方能得以解決。
連結程式的主要工作就是將有關的目標檔案彼此相連線,也即將在一個檔案中引用的符號同該符號在另外一個檔案中的定義連線起來,使得所有的這些目標檔案成為一個能夠誒作業系統裝入執行的統一整體。
根據開發人員指定的同庫函式的連結方式的不同,連結處理可分為兩種:
(1)靜態連結
在這種連結方式下,函式的程式碼將從其所在地靜態連結庫中被拷貝到最終的可執行程式中。這樣該程式在被執行時這些程式碼將被裝入到該程式的虛擬地址空間中。靜態連結庫實際上是一個目標檔案的集合,其中的每個檔案含有庫中的一個或者一組相關函式的程式碼。
(2) 動態連結
在此種方式下,函式的程式碼被放到稱作是動態連結庫或共享物件的某個目標檔案中。連結程式此時所作的只是在最終的可執行程式中記錄下共享物件的名字以及其它少量的登記資訊。在此可執行檔案被執行時,動態連結庫的全部內容將被對映到執行時相應程式的虛地址空間。動態連結程式將根據可執行程式中記錄的資訊找到相應的函式程式碼。
對於可執行檔案中的函式呼叫,可分別採用動態連結或靜態連結的方法。使用動態連結能夠使最終的可執行檔案比較短小,並且當共享物件被多個程式使用時能節約一些記憶體,因為在記憶體中只需要儲存一份此共享物件的程式碼。但並不是使用動態連結就一定比使用靜態連結要優越。在某些情況下動態連結可能帶來一些效能上損害。
我們在linux使用的gcc編譯器便是把以上的幾個過程進行捆綁,使使用者只使用一次命令就把編譯工作完成,這的確方便了編譯工作,但對於初學者瞭解編譯過程就很不利了,下圖便是gcc代理的編譯過程:
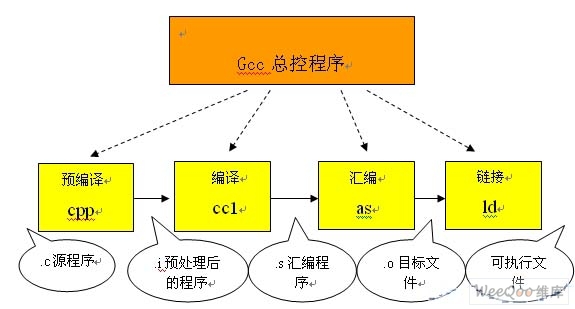
從上圖可以看到:
預編譯
將.c 檔案轉化成 .i檔案
使用的gcc命令是:gcc –E
對應於預處理命令cpp
編譯
將.c/.h檔案轉換成.s檔案
使用的gcc命令是:gcc –S
對應於編譯命令 cc –S
彙編
將.s 檔案轉化成 .o檔案
使用的gcc 命令是:gcc –c
對應於彙編命令是 as
連結
將.o檔案轉化成可執行程式
使用的gcc 命令是: gcc
對應於連結命令是 ld
總結起來編譯過程就上面的四個過程:預編譯、編譯、彙編、連結。瞭解這四個過程中所做的工作,對我們理解標頭檔案、庫等的工作過程是有幫助的,而且清楚的瞭解編譯連結過程還對我們在程式設計時定位錯誤,以及程式設計時儘量調動編譯器的檢測錯誤會有很大的幫助的。
相關文章
- C++ 編譯過程C++編譯
- 編譯C++ 程式的過程編譯C++
- Hive SQL 編譯過程詳解HiveSQL編譯
- [轉]:xmake編譯配置過程詳解編譯
- 詳解Linux 程式編譯過程Linux編譯
- C/C++預處理、編譯、連結過程【Z】C++編譯
- 優化C++程式碼(2):C++程式碼的編譯過程優化C++編譯
- Hive SQL的底層編譯過程詳解HiveSQL編譯
- C程式編譯過程淺析C程式編譯
- C語言編譯全過程C語言編譯
- 3- C語言編譯過程C語言編譯
- C語言編譯過程簡介C語言編譯
- 編譯過程編譯
- C++二叉查詢樹實現過程詳解C++
- 圖解Java程式編譯解釋過程圖解Java編譯
- C++運算子過載詳解C++
- Javac編譯過程Java編譯
- 編譯核心過程編譯
- 編譯器的編譯基本過程編譯
- windows 下c++編譯WindowsC++編譯
- CMM編譯器和C編譯器過程呼叫實現的比較編譯
- 編譯連結過程編譯
- 編譯過程簡介編譯
- C++編譯器優化C++編譯優化
- C++物件模型:編譯分析C++物件模型編譯
- C語言的編譯連結執行過程C語言編譯
- C語言編譯和連結過程簡介C語言編譯
- 安裝c, c++編譯器 on AIXC++編譯AI
- 編譯 TensorFlow 的 C/C++ 介面編譯C++
- Oracle 編譯儲存過程卡死解決方法Oracle編譯儲存過程
- vscode 自定義c++標頭檔案,編譯過程中遇到的問題VSCodeC++編譯
- C/C++—— C++編譯器是如何實現多型C++編譯多型
- ios底層 編譯過程iOS編譯
- 編譯器的工作過程編譯
- EVC編譯TCPMP的過程編譯TCP
- .NET 程式碼編譯過程編譯
- glade 編譯過程 (轉)編譯
- C語言程式碼區錯誤以及編譯過程C語言編譯