hadoop2.2.0 搭建
第一部分 Hadoop 2.2 下載
Hadoop我們從Apache官方網站直接下載最新版本Hadoop2.2。官方目前是提供了linux32位系統可執行檔案,所以如果需要在64位系統上部署則需要單獨下載src 原始碼自行編譯。
下載地址:http://apache.claz.org/hadoop/common/hadoop-2.2.0/
如下圖所示,下載紅色標記部分即可。如果要自行編譯則下載src.tar.gz.
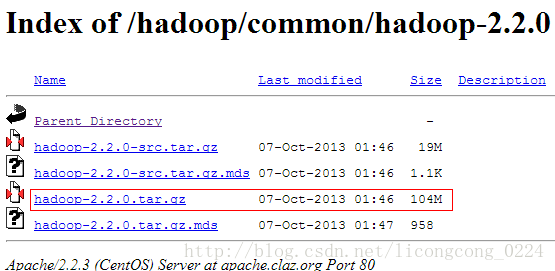
第二部分 叢集環境搭建
1、這裡我們搭建一個由三臺機器組成的叢集:
192.168.0.1 hduser/passwd cloud001 nn/snn/rm CentOS6 64bit
192.168.0.2 hduser/passwd cloud002 dn/nm Ubuntu13.04 32bit
192.168.0.3 hduser/passwd cloud003 dn/nm Ubuntu13.0432bit
1.1 上面各列分別為IP、user/passwd、hostname、在cluster中充當的角色(namenode, secondary namenode, datanode , resourcemanager, nodemanager)
1.2 Hostname可以在/etc/hostname中修改(ubuntu是在這個路徑下,redhat稍有不同)
1.3 這裡我們為每臺機器新建了一個賬戶hduser.這裡需要給每個賬戶分配sudo的許可權。(切換到root賬戶,修改/etc/sudoers檔案,增加:hduser ALL=(ALL) ALL )
2、修改/etc/hosts 檔案,增加三臺機器的ip和hostname的對映關係
192.168.0.1 cloud001
192.168.0.2 cloud002
192.168.0.3 cloud003
3、打通cloud001到cloud002、cloud003的SSH無密碼登陸
3.1 安裝ssh
一般系統是預設安裝了ssh命令的。如果沒有,或者版本比較老,則可以重新安裝:
sodu apt-get install ssh
3.2設定local無密碼登陸
安裝完成後會在~目錄(當前使用者主目錄,即這裡的/home/hduser)下產生一個隱藏資料夾.ssh(ls -a 可以檢視隱藏檔案)。如果沒有這個檔案,自己新建即可(mkdir .ssh)。
具體步驟如下:
1、 進入.ssh資料夾
2、 ssh-keygen -t rsa 之後一路回 車(產生祕鑰)
3、 把id_rsa.pub 追加到授權的 key 裡面去(cat id_rsa.pub >> authorized_keys)
4、 重啟 SSH 服 務命令使其生效 :service sshd restart(這裡RedHat下為sshdUbuntu下為ssh)
此時已經可以進行ssh localhost的無密碼登陸
【注意】:以上操作在每臺機器上面都要進行。
3.3設定遠端無密碼登陸
這裡只有cloud001是master,如果有多個namenode,或者rm的話則需要打通所有master都其他剩餘節點的免密碼登陸。(將001的authorized_keys追加到002和003的authorized_keys)
進入001的.ssh目錄
scp authorized_keys hduser@cloud002:~/.ssh/ authorized_keys_from_cloud001
進入002的.ssh目錄
cat authorized_keys_from_cloud001>> authorized_keys
至此,可以在001上面sshhduser@cloud002進行無密碼登陸了。003的操作相同。
4、安裝jdk(建議每臺機器的JAVA_HOME路徑資訊相同)
注意:這裡選擇下載jdk並自行安裝,而不是通過源直接安裝(apt-get install)
4.1、下載jkd( http://www.oracle.com/technetwork/java/javase/downloads/index.html)
4.1.1 對於32位的系統可以下載以下兩個Linux x86版本(uname -a 檢視系統版本)
4.1.2 64位系統下載Linux x64版本(即x64.rpm和x64.tar.gz)

4.2、安裝jdk(這裡以.tar.gz版本,32位系統為例)
安裝方法參考http://docs.oracle.com/javase/7/docs/webnotes/install/linux/linux-jdk.html
4.2.1 選擇要安裝java的位置,如/usr/目錄下,新建資料夾java(mkdirjava)
4.2.2 將檔案jdk-7u40-linux-i586.tar.gz移動到/usr/java
4.2.3 解壓:tar -zxvf jdk-7u40-linux-i586.tar.gz
4.2.4 刪除jdk-7u40-linux-i586.tar.gz(為了節省空間)
至此,jkd安裝完畢,下面配置環境變數
4.3、開啟/etc/profile(vim /etc/profile)
在最後面新增如下內容:
JAVA_HOME=/usr/java/jdk1.7.0_40(這裡的版本號1.7.40要根據具體下載情況修改)
CLASSPATH=.:$JAVA_HOME/lib.tools.jar
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOMECLASSPATH PATH
4.4、source /etc/profile
4.5、驗證是否安裝成功:java–version
【注意】每臺機器執行相同操作,最後將java安裝在相同路徑下
5、關閉每臺機器的防火牆
RedHat:
/etc/init.d/iptables stop 關閉防火牆。
chkconfig iptables off 關閉開機啟動。
Ubuntu:
ufw disable (重啟生效)
第三部分 Hadoop 2.2安裝過程
由於hadoop叢集中每個機器上面的配置基本相同,所以我們先在namenode上面進行配置部署,然後再複製到其他節點。所以這裡的安裝過程相當於在每臺機器上面都要執行。但需要注意的是叢集中64位系統和32位系統的問題。
1、 解壓檔案
將第一部分中下載的hadoop-2.2.tar.gz解壓到/home/hduser路徑下(或者將在64位機器上編譯的結果存放在此路徑下)。然後為了節省空間,可刪除此壓縮檔案,或將其存放於其他地方進行備份。
注意:每臺機器的安裝路徑要相同!!
2、 hadoop配置過程
配置之前,需要在cloud001本地檔案系統建立以下資料夾:
~/dfs/name
~/dfs/data
~/temp
這裡要涉及到的配置檔案有7個:
~/hadoop-2.2.0/etc/hadoop/hadoop-env.sh
~/hadoop-2.2.0/etc/hadoop/yarn-env.sh
~/hadoop-2.2.0/etc/hadoop/slaves
~/hadoop-2.2.0/etc/hadoop/core-site.xml
~/hadoop-2.2.0/etc/hadoop/hdfs-site.xml
~/hadoop-2.2.0/etc/hadoop/mapred-site.xml
~/hadoop-2.2.0/etc/hadoop/yarn-site.xml
以上檔案預設不存在的,可以複製相應的template檔案獲得。
配置檔案1:hadoop-env.sh
修改JAVA_HOME值(export JAVA_HOME=/usr/java/jdk1.7.0_40)
配置檔案2:yarn-env.sh
修改JAVA_HOME值(exportJAVA_HOME=/usr/java/jdk1.7.0_40)
配置檔案3:slaves (這個檔案裡面儲存所有slave節點)
寫入以下內容:
cloud002
cloud003
配置檔案4:core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://cloud001:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hduser/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>hadoop.proxyuser.hduser.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hduser.groups</name>
<value>*</value>
</property>
</configuration>
配置檔案5:hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>cloud001:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hduser/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hduser/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
配置檔案6:mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>cloud001:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>cloud001:19888</value>
</property>
</configuration>
配置檔案7:yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>cloud001:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value> cloud001:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value> cloud001:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value> cloud001:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value> cloud001:8088</value>
</property>
</configuration>
3、複製到其他節點
這裡可以寫一個shell指令碼進行操作(有大量節點時比較方便)
cp2slave.sh
#!/bin/bash
scp–r /home/hduser/hadoop-2.2.0 hduser@cloud002:~/
scp–r /home/hduser/hadoop-2.2.0 hduser@cloud003:~/
注意:由於我們叢集裡面001是64bit 而002和003是32bit的,所以不能直接複製,而採用單獨安裝hadoop,複製替換相關配置檔案:
Cp2slave2.sh
#!/bin/bash
scp /home/hduser/hadoop-2.2.0/etc/hadoop/slaveshduser@cloud002:~/hadoop-2.2.0/etc/hadoop/slaves
scp /home/hduser/hadoop-2.2.0/etc/hadoop/slaveshduser@cloud003:~/hadoop-2.2.0/etc/hadoop/slaves
scp /home/hduser/hadoop-2.2.0/etc/hadoop/core-site.xmlhduser@cloud002:~/hadoop-2.2.0/etc/hadoop/core-site.xml
scp /home/hduser/hadoop-2.2.0/etc/hadoop/core-site.xml hduser@cloud003:~/hadoop-2.2.0/etc/hadoop/core-site.xml
scp /home/hduser/hadoop-2.2.0/etc/hadoop/hdfs-site.xmlhduser@cloud002:~/hadoop-2.2.0/etc/hadoop/hdfs-site.xml
scp /home/hduser/hadoop-2.2.0/etc/hadoop/hdfs-site.xmlhduser@cloud003:~/hadoop-2.2.0/etc/hadoop/hdfs-site.xml
scp /home/hduser/hadoop-2.2.0/etc/hadoop/mapred-site.xmlhduser@cloud002:~/hadoop-2.2.0/etc/hadoop/mapred-site.xml
scp /home/hduser/hadoop-2.2.0/etc/hadoop/mapred-site.xmlhduser@cloud003:~/hadoop-2.2.0/etc/hadoop/mapred-site.xml
scp /home/hduser/hadoop-2.2.0/etc/hadoop/yarn-site.xmlhduser@cloud002:~/hadoop-2.2.0/etc/hadoop/yarn-site.xml
scp /home/hduser/hadoop-2.2.0/etc/hadoop/yarn-site.xmlhduser@cloud003:~/hadoop-2.2.0/etc/hadoop/yarn-site.xml
4、啟動驗證
4.1 啟動hadoop
進入安裝目錄: cd ~/hadoop-2.2.0/
格式化namenode:./bin/hdfs namenode –format
啟動hdfs: ./sbin/start-dfs.sh
此時在001上面執行的程式有:namenode secondarynamenode
002和003上面執行的程式有:datanode
啟動yarn: ./sbin/start-yarn.sh
此時在001上面執行的程式有:namenode secondarynamenoderesourcemanager
002和003上面執行的程式有:datanode nodemanaget
檢視叢集狀態:./bin/hdfs dfsadmin –report
檢視檔案塊組成: ./bin/hdfsfsck / -files -blocks
檢視HDFS: http://16.187.94.161:50070
檢視RM: http:// 16.187.94.161:8088
4.2 執行示例程式:
先在hdfs上建立一個資料夾
./bin/hdfs dfs –mkdir /input
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jarrandomwriter input
相關文章
- hadoop2.2.0叢集搭建Hadoop
- hadoop2.2.0 搭建初體驗Hadoop
- hadoop2.2.0偽分散式安裝Hadoop分散式
- Hadoop2.2.0多節點分散式安裝及測試Hadoop分散式
- hadoop之 Hadoop2.2.0中HDFS的高可用性實現原理Hadoop
- 最詳細的hadoop2.2.0叢集的HA高可靠的最簡單配置Hadoop
- 【環境搭建】RocketMQ叢集搭建MQ
- docker搭建Nexus搭建Maven私服DockerMaven
- MySQL叢集搭建(1)-主備搭建MySql
- MVVM框架的搭建(二)——專案搭建MVVM框架
- gradle手工搭建java專案搭建GradleJava
- Inception 搭建
- MYSQL搭建MySql
- Harbor 搭建
- ELK搭建
- elk 搭建
- ldap搭建LDA
- 搭建cacti
- 框架搭建框架
- DataGuard搭建
- lnmp搭建LNMP
- RAC 搭建
- elasticsearch搭建Elasticsearch
- DG搭建
- OJ搭建
- 搭建genieacs
- 精讀《視覺化搭建思考 - 富文字搭建》視覺化
- 從零搭建一個IdentityServer——專案搭建IDEServer
- 【Azkaban搭建】---Azkaban 3.25.0搭建細則 超實用
- Windows下搭建ESP-IDF環境搭建Windows
- Sentry 搭建
- redis cluster 搭建Redis
- docker rancher搭建Docker
- vue 快速搭建Vue
- windows搭建ftpWindowsFTP
- Docker 搭建 MongoDBDockerMongoDB
- 圖床搭建圖床
- chatgpt個人搭建ChatGPT