深入理解hadoop網路
原文地址 http://bradhedlund.com/2011/09/10/understanding-hadoop-clusters-and-the-network/
本文側重於Hadoop叢集的體系結構和方法,以及它與網路和伺服器基礎設施這件的關係。文章的素材主要來自於研究工作以及同現實生活中執行Hadoop叢集客戶的討論。如果你也在你的資料中心執行產品級的Hadoop叢集,那麼我希望你能寫下有價值的評論。
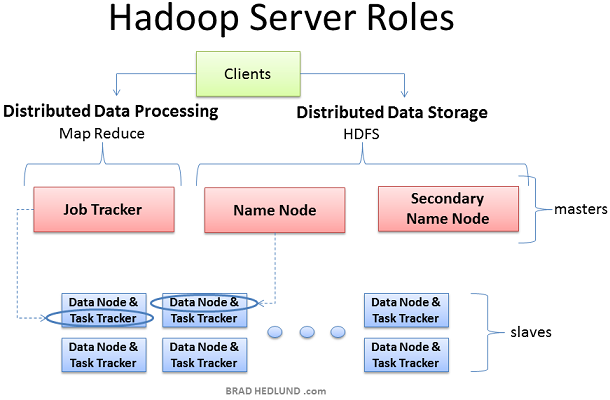
Hadoop叢集部署時有三個角色:Client machines, Master nodes和Slave nodes。
Master nodes負責Hadoop的兩個關鍵功能:資料儲存(HDFS);以及執行在這個資料之上的平行計算,又稱為Map-Reduce。Name node負責排程資料儲存,而Job Tracker則負責並行資料處理的排程(使用Map-Reduce技術)。Slave nodes由大量的機器組成,完成資料儲存以及執行計算這樣的髒活。每個slave node都執行Data node和Task Tracker daemon,這些slave daemon和master nodes的相應daemon進行通訊。Task tracker daemon由Job Tracker管理,Data node Daemon由Name node管理。
Client機器包含了Hadoop叢集的所有設定,但是它既不是Master也不是Slave。Client的角色是向叢集儲存資料,提交Map-Reduce jobs(描述如何處理資料),獲取檢視MR jobs的計算結果。在小型叢集中(40節點)你可能會發現一個物理機器扮演多個角色,比如既是Job Tracker又是Name node,在中等或者大規模叢集中,一般都是用獨立的伺服器負責單獨的角色。
在真正的產品叢集中,不存在虛擬伺服器和虛擬機器平臺,因為他們僅會導致不必要的效能損耗。Hadoop最好執行在linux機器上,直接工作於底層硬體之上。換句話說,Hadoop可以工作在虛擬機器之上,對於學習Hadoop是一個不錯的廉價方法,我本身就有一個6-node的Hadoop cluster執行Windows 7 laptop的VMware Workstation之上

上圖是Hadoop叢集的典型架構。機架伺服器(不是刀鋒伺服器)分佈在多個機架中,連線到一個1GB(2GB)頻寬的機架交換機,機架交換機連線到上一層的交換機,這樣所有的節點通過最上層的交換機連線到一起。大部分的伺服器都是Slave nodes配置有大的磁碟儲存 中等的CPU和DRAM,少部分是Master nodes配置較少的儲存空間 但是有強大的CPU和大DRAM
本文中,我們不討論網路設計的各種細節,而是把精力放在其他方面。首先我們看下應用的工作流程。

為什麼會出現Hadoop? 它又解決了什麼問題? 簡單的說,是由於商業和政府有大量的資料需要快速分析和處理,如果我們把這些巨大的資料切分為小的資料塊分散到多臺計算機中,並且用這些計算機並行處理分配給他們的小塊資料,可以快速的得到結果,這就是Hadoop能做的事情。
在我們的簡單例子中,我們有一個大檔案儲存著所有發給客戶服務部分的郵件,想要快速統計單詞"Refund"被輸入了多少次,這個結果有助於評估對退換貨部門的需求,以指定相應對策。這是一個簡單的單詞計數練習。Client上傳資料到叢集(File.txt),提交一個job來描述如何分析資料,叢集儲存結果到一個新檔案(Result.txt),然後Client讀取結果檔案。
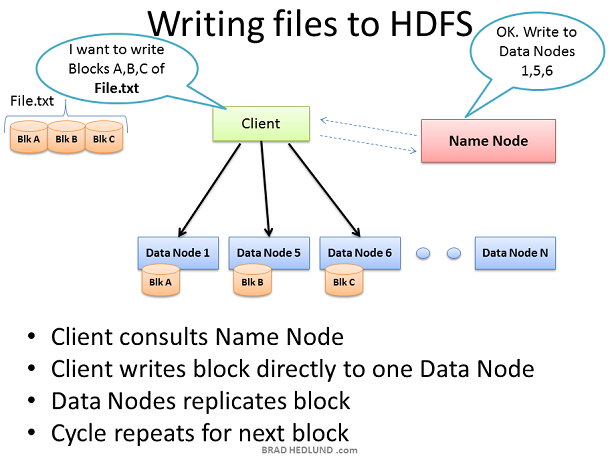
沒有載入資料,Hadoop叢集就沒有任何用途。所以我們首先從載入大檔案File.txt到叢集中以便處理。目標是能夠快速並行處理許多資料,為了達到這個目的需要儘可能多的機器能夠同時操縱檔案資料。Client把資料檔案切分成許多小blocks,然後把他們分散到叢集的不同機器上。塊數越多,用來處理這些資料的機器就越多。同時這些機器一定會失效,所以要確保每個資料塊儲存到多個機器上以防止資料丟失。所以每個資料塊在存入叢集時會進行復制。Hadoop的標準設定是叢集中的每個block有三份copy,這個配置可以由hdfs-site.xml的dfs.replication
引數設定
Client把檔案File.txt分成3塊,對於每一塊,Client和Name node協商獲取可以儲存它以及備份塊的Data nodes列表。Client然後直接寫block資料到Data node,Data node負責寫入資料並且複製copy到其他的Data nodes。重複操作,直到所有的塊寫完。Name node本身不參與資料儲存,Name node僅僅提供檔案資料位置以及資料可用位置(檔案系統後設資料)
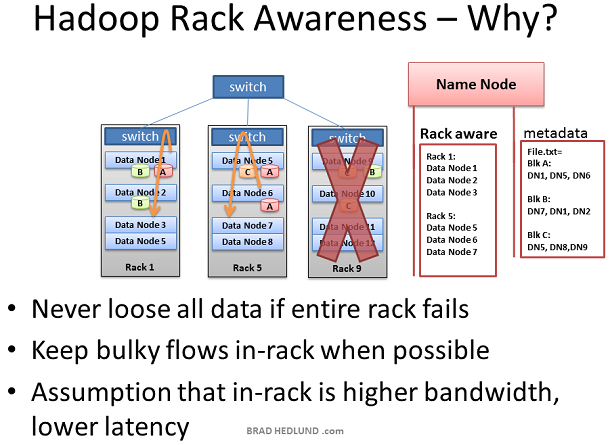
Hadoop引入了Rack Awareness的概念。作為Hadoop系統管理員,你能夠手動定義叢集中每一個slave Data node的rack號。為什麼要把自己置於這種麻煩呢?有兩個關鍵的原因:資料丟失和網路效能。記住每一個資料塊都會被複制到多臺Data node上,以防止某臺機器失效導致資料丟失。有沒有可能一份資料的所有備份恰好都在同一個機架上,而這個機架又出現了故障,比如交換機失效或者電源失效。為了防止這種情況,Name node需要知道Data nodes在網路拓撲中的位置,並且使用這個資訊決定資料應該複製到叢集的什麼位置。
我們還假定同一機架的兩臺機器間相比不同機架的兩臺機器間 有更高的頻寬和更低的網路延遲,在大部分情況下是正確的。機架交換機的上行頻寬通常小於下行頻寬。此外,機架內延遲通常低於機架間延遲。如果上面的假定成立,那麼採用Rack Awareness既可以通過優化位置保護資料,同時提升網路效能,豈不是太cool了。是的,的確是這樣,非常cool,對不對。
別急,Not cool的是Rack Awareness是需要手工定義的,並且要持續的更新它,並且保證這個資訊精確。如果機架交換機可以自動提供它下面的Data node列表給Name node,那就更cool了。或者如果Data nodes可以自動告知Name node他們屬於哪個交換機,一樣很cool.
此外,讓人感興趣的是OpenFlow 網路,Name node可以請求OpenFlow控制器關於節點位置的拓撲情況。
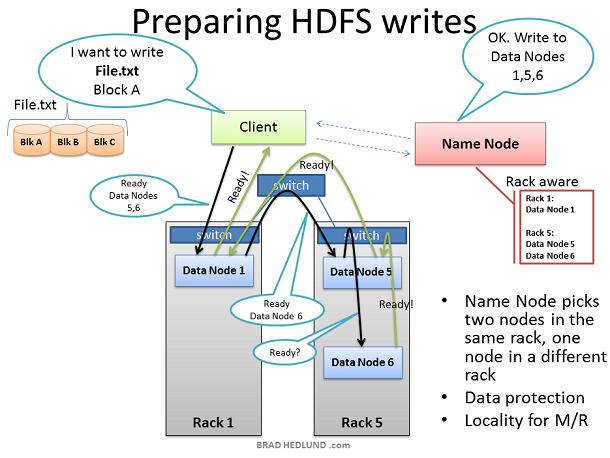
Client準備寫檔案File.txt到叢集時,把檔案劃分為塊,塊A為第一個塊。Client向Name node申請寫檔案File.txt,從Name node獲得許可,並且接收到一個Data nodes列表(3個表項),每一個Data nodes用來寫入塊A的一個copy。Name node使用Rack Awareness來決定這個Data nodes列表。規則是:對於每一個資料塊,兩個 copy存放在一個機架上,另外一個copy存放在另外一個機架上。
在Client寫Block A之前,它要知道準備接受”Block A“ copy的Data nodes是否以及做好了準備。首先,Client選擇list中的第一個節點Data Node1,開啟一個TCP50010連結然後請求:“hey,準備接受一個block,這是一個Data nodes列表(2個表項),Data node5和Data node6”,請確保他們兩個也準備好了“;於是Data Node1開啟一個到Data node5的TCP500100連線然後說:”Hey,準備接受一個block,這是一個Data nodes列表(1個表項),Data node6”,請確保他準備好了“;Data Node5同樣會問Data Node6:“Hey, 準備好接收一個block嗎“
”準備就緒“的響應通過已經建立好的TCP pipeline傳回來,直到Data Node1傳送一個"Ready"給Client。現在Client可以開始寫入資料了。
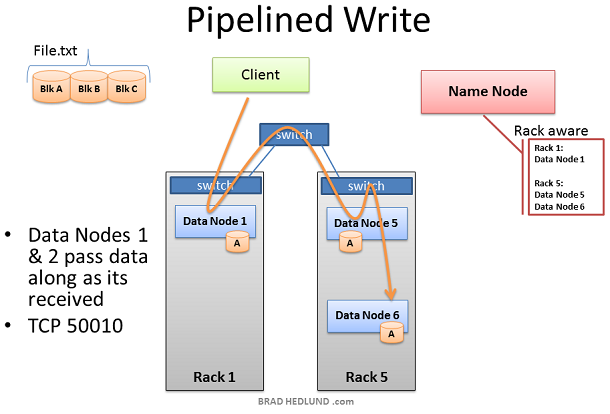
寫入資料的過程中,在涉及寫操作的Data nodes之間建立一個複製pipeline。也就是說一個資料節點接收資料的同時,同時會把這份資料通過pipeline push到下一個Node中。
從上圖可以看到,Rack Awareness起到了改善叢集效能的做用。Data node5和Data node6在同一個機架上,因此pipeline的最後一步複製是發生在機架內,這就受益於機架內頻寬以及低延遲。在Data node1, Data node5, Data node6完成block A之前,block B的操作不會開始。
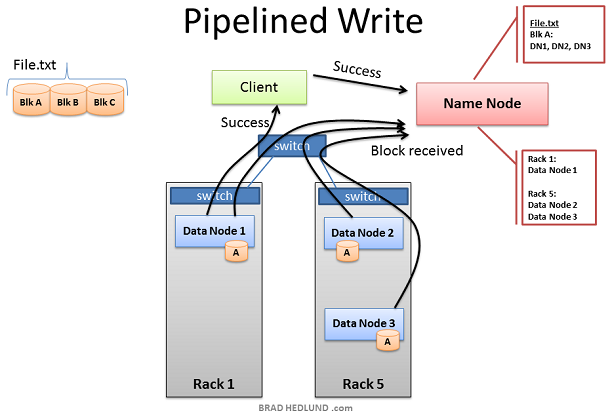
當三個Nodes成功的接收到Block A後,揮傳送"Block received"報告給Name node,同時傳送"Success"到pipeline中,然後關閉TCP事務。Client在接收到Success資訊後,通知Name node資料塊已經成功的寫入。Name node更新File.txt中Block A的metadata資訊(包含Name locations資訊)
Client現在可以開始Block B的傳輸了

隨著File.txt的塊被寫入,越來越多的Data nodes涉及到pipeline中,散落到機架內的熱點,以及跨機架的複製
Hadoop佔用了很多的網路頻寬和儲存空間。Hadoop專為處理大檔案而生,比如TB級尺寸的檔案。每一個檔案在網路和儲存中都被複制了三次。如果你有一個1TB的檔案,那麼將消耗3TB的網路頻寬,同時要消耗3TB的磁碟空間存貯這個檔案。
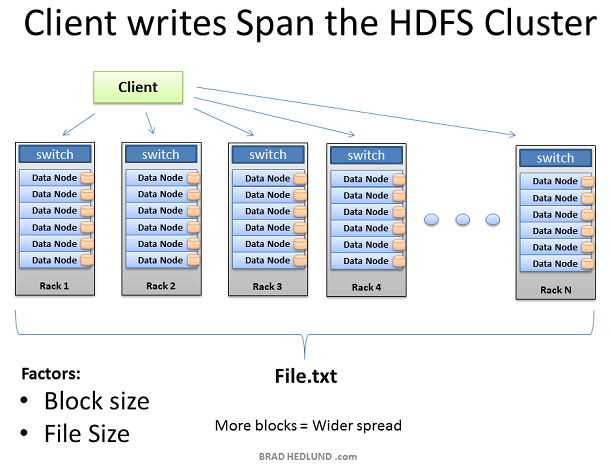
隨著每塊的複製pipeline的完成,檔案被成功的寫入叢集。檔案散落在叢集內的機器上,每個機器儲存檔案的一小部分資料。組成檔案的塊數目越多,資料散落的機器就越多,將來更多的CPU和磁碟驅動器就能參與到並行處理中來,提供更強大更快的處理能力。這也是建造巨大叢集的原動力。當機器的數變多,叢集則變得wide,網路也相應的需要擴充套件。
擴充套件叢集的另外一種方法是deep擴充套件。就是維持機器資料不便,而是增加機器的CPU處理能力和磁碟驅動器的數目。在這種情況下,需要提高網路的I/O吞吐量以適應增大的機器處理能力,因此如何讓Hadoop叢集執行10GB nodes稱為一個重要的考慮。
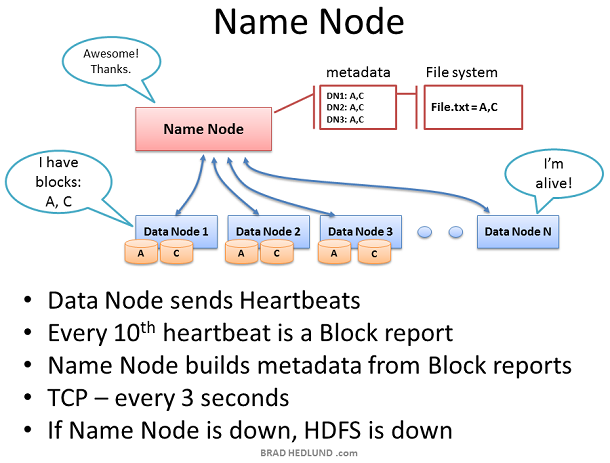
Name node儲存叢集內所有檔案的metadata,監督Data nodes的健康以及協調資料的存取。Name node是HDFS的控制中心。它本身並不儲存任何cluster data。Name node知道一個檔案由哪些塊組成以及這些塊存放在叢集內的什麼地方。Name node告訴Client需要和哪些Data node互動,管理叢集的儲存容量,掌握Data node的健康狀況,確保每一個資料塊都符合系統備份策略。
Data node每3秒鐘傳送一個heartbeats給Name node ,二者使用TCP9000埠的TCP握手來實現heartbeats。每十個heartbeats會有一個block report,Data node告知它所儲存的資料塊。block report使得Namenode能夠重建它的metadata以確保每個資料block有足夠的copy,並且分佈在不同的機架上。
Name node是Hadoop Distributed File System(HDFS)的關鍵部件。沒有Name node,clients無法從HDFS讀寫資料,也無法執行Map Reduce jobs。因此Name node 最好配置為一臺高冗餘的企業級伺服器:雙電源,熱插拔風扇,冗餘NIC連線等。
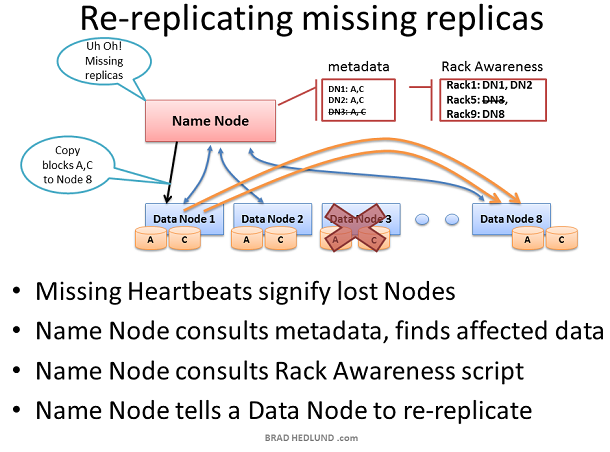
如果Name node收不到某Data node的heartbeats,那麼Name node假定這個Data node當機並且Data node上的所有資料也丟失了。通過這臺dead Data node的block report,Name node知道哪些block copies需要複製到其他Data nodes。Name node參考Rack Awareness資料來選擇接收新copy的Data node,並遵守以下複製規則:一個機架儲存兩份copies,另一個機架儲存第三份copy。
考慮由於機架交換機或者機架電源失敗導致的整個機架Data node都失效的情況。Name node將指導叢集內的剩餘Data nodes開始複製失效機架上的所有資料。如果失效機架上伺服器的儲存容量為12TB,那麼這將導致數百TB的資料在網路中傳輸。
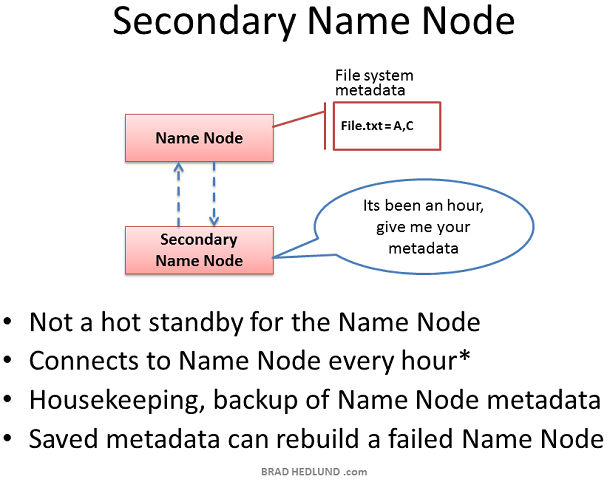
Secondary Name node是Hadoop的一種伺服器角色。一個很普遍的誤解是它提供了對Name node的高可用性備份,實際上不是。
Secondary Name node偶爾會連線到Name node(預設為每小時),同步Name node in-memory metadata以及儲存metadata的檔案。Secondary Name node合併這些資訊到一個組新的檔案中,儲存到本地的同時把這些檔案傳送回Name Node。
當Name node當機,儲存在Secondary Name node中的檔案可以用來恢復Name node。在一個繁忙的叢集中,系統管理員可以配置同步時間為更小的時間間隔,比如每分鐘。
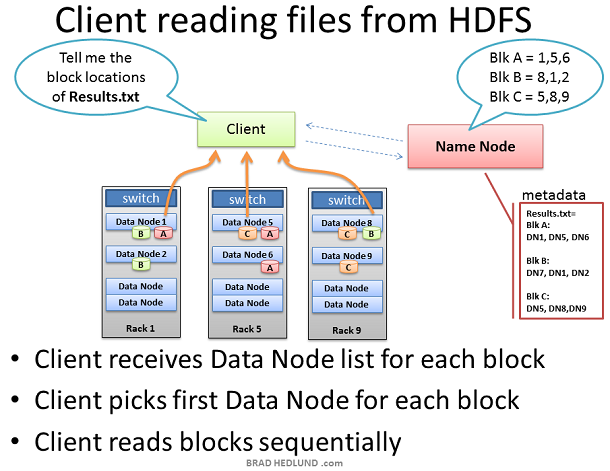
當一個Client想要從HDFS獲取一個檔案時,比如job的輸出結果。Client首先從Name node查詢檔案block的位置。Name node返回一個包含所有block位置的連結串列,每個block位置包含全部copies所在的Data node
Client選取一個資料塊的Data node位置,通過TCP50010埠從這個Data node讀取一塊,在讀取完當前塊之前,Client不會處理下一塊。
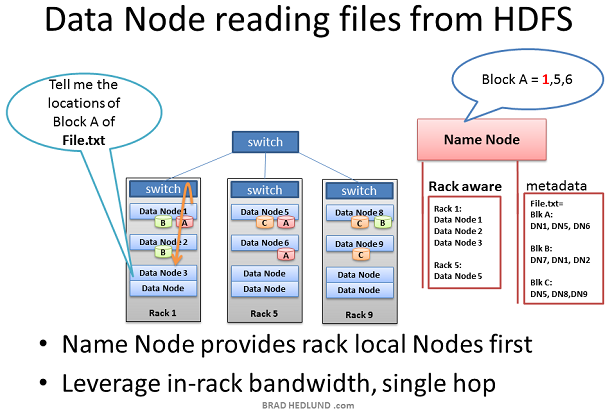
在某些情況下Data node daemon本身需要從HDFS讀取資料塊。比如Data Node被請求處理自身不存在的資料,因而它必須從網路上的其他Data node獲得資料然後才能開始處理。
另外一種情況是Name node的Rack Awareness資訊提供的網路優化行為。當Data node向Name node查詢資料塊位置資訊,Name node優先檢視請求者所在的機架內的Data nodes包含這個資料塊。如果包含,那麼Name node把這個Data node提供給請求的Data node。這樣可以保證資料僅在in-rack內流動,可以加快資料的處理速度以及job的完成速度
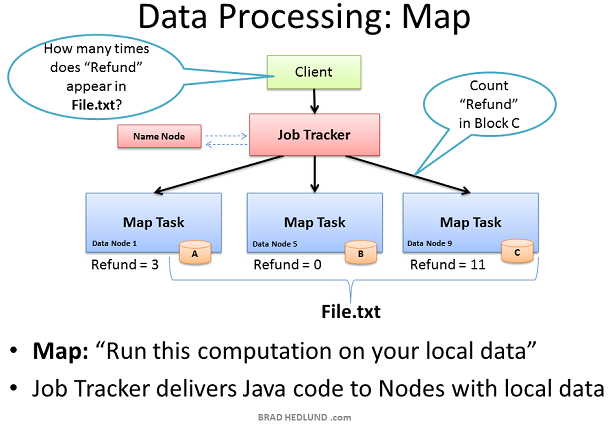
現在File.txt分散到叢集的機器中這樣就可以提供更快更有效的並行處理速度。Hadoop並行處理框架稱為Map Reduce,名稱來自於並行處理的兩個重要步驟:Map和Reduce
第一步是Map 過程,這個步驟同時請求所有包含資料的Data node執行計算。在我們的例子中則是請求這些Data node統計儲存在他們上的File.txt資料塊包含多少此Refund
要達到這個目的,Client首先提交Map Reduce job給Job tracker,傳送請求:“How many times does Refund occur in file.txt”。Job tracker向Name node查詢哪些Data nodes包含檔案File.txt的資料塊。然後Job Tracker在這些Data nodes上執行Java程式碼 在Data node的本地資料上執行Map計算。Task Tracker啟動一個Map task監測這些tasks的執行。Task Tracker通過heartbeats向Job Tracker彙報task的狀態。
當每一個Map task都完成後,計算結果儲存在這些節點的臨時儲存區內,我們稱之為"intermediate data"。下一步是把這些中間資料通過網路傳送給執行Reduce的節點以便完成最後的計算。

Job tracker總是嘗試選擇包含待處理資料的Data node做Map task,但是有時不會這樣。比如,所有包含這塊資料的Data node已經有太多的tasks正在執行,不再接收其他的task.
這種情況下,Job Tracker將詢問Name node,Name node會根據Rack Awareness建議一個in-rack Data node。Job tracker把task分配給這個in-rack Data node。這個Data node會在Name node的指導下從包含待處理資料的in-rack Data node獲取資料。

Map Reduce 框架的第二部分叫做Reduce。Map task已經完成了計算,計算結果儲存在intermediate data。現在我們需要把所有的中間資料彙集到一起作進一步處理得到最終結果。
Job Tracker可以在叢集內的任意一個node上執行Reduce,它指導Reduce task從所有完成Map trasks的Data node獲取中間資料。這些Map tasks可能同時響應Reducer,這就導致了很多nodes幾乎同時向單一節點發起TCP連線。我們稱之為incast或者fan-in(微突發流)。如果這種微突發流比較多,那麼就要求網路交換機有良好的內部流量管理能力,以及相應的buffers。這種間歇性的buffers使用可能會影響其他的網路行為。這需要另開一篇詳細討論。
Reducer task已經收集了所有intermediate data,現在可以做最後計算了。在這個例子中,我們只需簡單的把數字相加就得到了最終結果,寫入result.txt
我們的這個例子並沒有導致很多的intermediate data在網路間傳輸。然而其他的jobs可能會產生大量的intermediate data:比如,TB級資料的排序,輸出的結果是原始資料集的重新排序,結果尺寸和原始檔案大小一致。Map Reduce過程會產生多大的網路流量王權依賴於給定的Job型別。
如果你對網路管理很感興趣,那麼你將瞭解更多Map Reduce和你執行叢集的Jobs型別,以及這些Jobs型別如何影響到網路。如果你是一個Hadoop網路的狂熱愛好者,那麼你可能會建議寫更好的Map Reduce jobs程式碼來優化網路效能,更快的完成Job

Hadoop通過在現有資料的基礎上提供某種商業價值,從而在你的組織內獲得成功。當人們意識到它的價值,那麼你可能獲得更多的資金購買更多的機架和伺服器,來擴充套件現有的Hadoop叢集。
當增加一個裝滿伺服器的新機架到Hadoop叢集中時,你可能會面臨叢集不平衡的局面。在上圖的例子中,Rack1和Rack2是已經存在的機器,儲存著檔案File.txt並且正在執行Map Reduce jogs。當我們增加兩個新的機架到叢集中時,File.txt 資料並不會神奇的自動散佈到新的機架中。
新的Data node伺服器由於沒有資料只能空閒著,直到Client開始儲存新的資料到叢集中。此外當Rack1和Rack2上的伺服器都滿負荷的工作,那麼Job Tracker可能沒有別的選擇,只能把作用在File.txt上的Map task分配到這些沒有資料的新伺服器上,新伺服器需要通過網路跨機架獲取資料。這就導致更多的網路流量,更慢的處理速度。
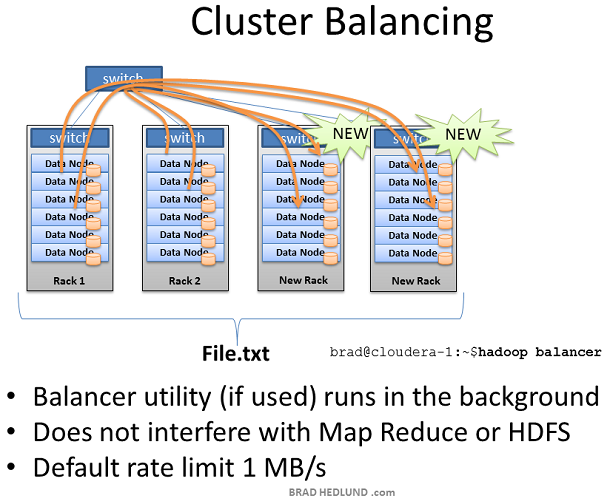
為了處理這種情況,Hadoop包含一個時髦的工具叫做 balancer
Balancer檢視節點可用儲存的差異性,在達到特定的閥值後嘗試執行balance。有很多空閒空間的新節點將被檢測到,然後balancer開始從空閒空間很少的Data node拷貝資料到這個新節點。Balancer通過控制檯的命令列啟動,通過控制檯取消或者關閉balancer
Balancer可用的網路流量是非常低的,預設設定為1MB/s。可以通過hdfs-site.xml的df.balance.bandwidthPerSec引數來修改。
Balancer是你的叢集的好管家。在你增加伺服器時一定會用到它,定期(每週)執行一次也是一個好主意。Balancer使用預設頻寬可能會導致很長時間才能完成工作,比如幾天或者幾周。
相關文章
- 深入理解Hadoop叢集和網路Hadoop
- 機器學習:深入理解LSTM網路 (二)機器學習
- 計算機網路——深入理解TCP/IP計算機網路TCP
- 計算機網路——深入理解HTTP以及HTTPs計算機網路HTTP
- DockOne微信分享(一三三):深入理解Kubernetes網路策略
- 深入理解Linux網路內幕-PART I -通用背景(轉)Linux
- 深入理解mahout基於hadoop的協同過濾流程Hadoop
- hadoop個人理解Hadoop
- 深入淺出Kubernetes網路:容器網路初探
- vLan網路原理解析
- 深入剖析容器網路和 iptables
- 深入理解webpack如何解析程式碼路徑Web
- Hadoop資料分析平臺實戰——070深入理解MapReduce 02(案例)Hadoop
- 理解 TCP/IP 網路棧 & 編寫網路應用TCP
- 理解高效能網路模型模型
- 深入理解Isolate
- 深入理解HashMapHashMap
- 深入理解TransformORM
- 深入理解KVO
- 深入理解 JVMJVM
- 深入理解 GitGit
- 深入理解AQSAQS
- 深入理解JVMJVM
- 深入理解 TypeScriptTypeScript
- 深入理解JavaScriptCoreJavaScript
- 深入理解MVCMVC
- 深入理解 PWA
- 深入理解margin
- 深入理解ReactReact
- 深入理解BFC
- 深入理解reduxRedux
- BFC深入理解
- 深入理解 GCDGC
- 深入理解 requestAnimationFramerequestAnimationFrame
- 深入理解Eureka
- 深入理解copy
- AsyncTask深入理解
- 深入理解RunLoopOOP