1. 引言
最近心血來潮去參加了一個PL/SQL工程師的面試,期間被問到了Oracle分析函式,PL/SQL開發並非我的老本行,在之前的工作中,也很少使用分析函式,原因之一是對資料庫移植問題的考慮;其二是很少遇到非用分析函式不可的情況;其三是分析函式的語法相對複雜,令人缺乏興趣。這幾天看了一些入門內容,發現它們還是很強大的,唯一的遺憾是目前身邊沒有真實的應用場景,所以這裡舉的例子看起來難免有點紙上談兵的感覺。
2. 分析函式(Analytic function)與聚合函式(Aggregate function)
我們先從“ORA-00979: not a GROUP BY expression”說起,相信大家在開始使用SQL的過程中都遇到過這個錯誤,比如你寫了下面這樣的SQL:
FROM film
GROUP BY corp
ORDER BY corp;
ORA-00979錯誤表明,SELECT子句中出現的欄位,要麼包含於GROUP BY子句,要麼作為聚合函式(上面的COUNT)的輸入,除此之外不能包含其它欄位。我們可以修改上面的SQL使它可以正常執行:
FROM film
GROUP BY corp
ORDER BY corp;
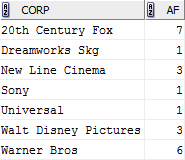
這就引出了聚合函式的一個主要特徵,聚合之後,同組只保留下一條資料,由上圖可知表中由“20th Century Fox”公司出品的影片共有7部,最終記錄是一條。
這符合某些統計需求,然而有時候,我們並不希望聚合函式中的這種“合併”操作,尤其是我們常常希望在SELECT子句出現未參與統計的欄位,此時我們便可以使用分析函式。對於表中的每一行記錄,分析函式都能返回一個統計值,下面我們來看一個具體的例項:
COUNT(*) OVER (PARTITION BY corp) af
FROM film;
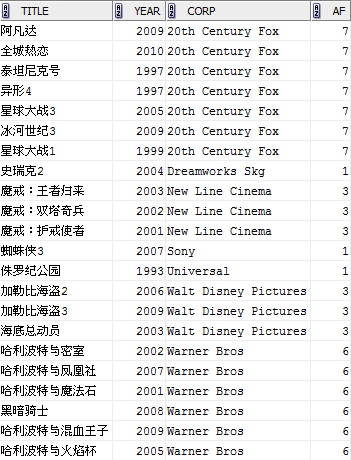
注:PARTITION BY不僅導致分割槽(類似於GROUP BY),而且分割槽之間是排序好的,也算是它的一個“副作用”。
3. 基本語法
function_name(arg1,arg2,...) OVER (<partition-clause> <order-by-clause > <window clause>)
其中<order-by-clause >子句會在下面的例子中穿插提到,<window clause>子句則會在最後一節進行解釋。
另外,還需要提到的一點是,在有分析函式參與的SQL語句中,執行流程依次是:
1) JOIN, WHERE, GROUP BY, HAVING
2) 建立分割槽(通常通過PARTITION BY),而後分析函式將作用於分割槽中的每一行
3) 主語句中ORDER BY(這個我們以前就知道,主語句的ORDER BY總是最後執行)。
4. AVG, SUM, MAX, MIN, COUNT
這些大家熟知的聚合函式,同樣可作為分析函式使用,當然要符合第3節中給出的分析函式的語法,下面我們來看幾個例項:
ROUND(AVG(box_office) OVER (PARTITION BY corp)) af
FROM film;
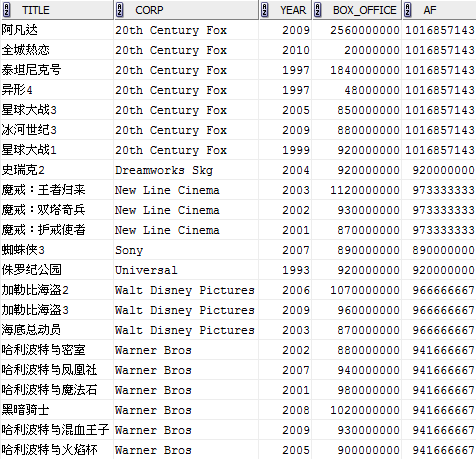
讓我們看看在OVER內應用ORDER BY之後的情形:
COUNT(*) OVER (PARTITION BY corp ORDER BY year) af
FROM film;
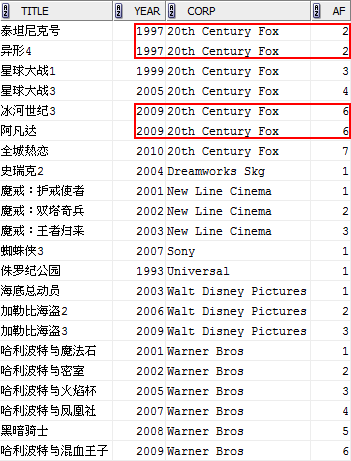
這個結果容易讓人非常困惑,實際上OVER內的ORDER BY子句導致了分割槽(PARTITION)內的資料進行了逐步累加。通常,這種“累加”始於排序後該分割槽的第一條記錄,結束於當前記錄。當排序列出現相同值(比如上面的兩個1997、兩個2009),累加則結束於相同記錄的最後一條。
讓我們再來看一個例子:
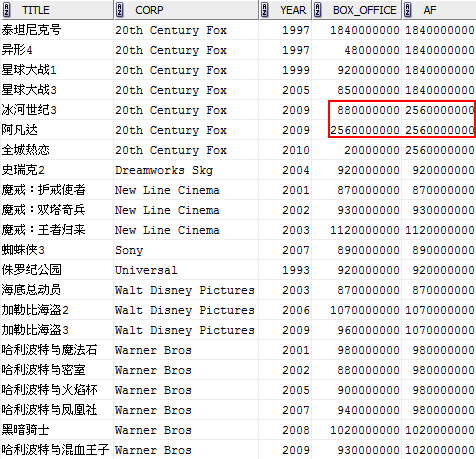
MAX(box_office) OVER (PARTITION BY corp ORDER BY year) af
FROM film;
5. RANK, DENSE_RANK, ROW_NUMBER

 程式碼
程式碼
RANK() OVER (PARTITION BY corp ORDER BY year) r,
DENSE_RANK() OVER (PARTITION BY corp ORDER BY year) dr,
ROW_NUMBER() OVER (PARTITION BY corp ORDER BY year) rn
FROM film;
![]()
RANK, DENSE_RANK, ROW_NUMBER具有類似的行為,只有當排序列包含重複值時,它們的區別才能體現出來。注意上圖中紅色標識部分,對於相同的年份1997,RANK, DENSE_RANK都返回相同的值,不同的時,DENSE_RANK採用密集編號,兩個1之後接著的編號是2。對於ROW_NUMBER,則總是產生連續的編號。
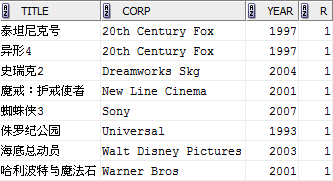
利用這幾個函式的特性,可以相對簡單地實現TOP N的查詢,例如查詢表中各電影公司年份最早的電影:
SELECT title,corp,year,
RANK() OVER (PARTITION BY corp ORDER BY year) r
FROM film
) t
WHERE t.r=1;
6. LEAD, LAG
基本語法:
LEAD(<sql_expr>, <offset>, <default>) OVER (<analytic_clause>)
LAG(<sql_expr>, <offset>, <default>) OVER (<analytic_clause>)
<sql_expr> :通常是欄位名。
<offset> :表示相對於當前行的偏移幅度(對LEAD來說是向後偏移,對LAG來說則是向前),正整數,預設為1。
<default> :當偏移幅度超出該分割槽(PARTITION)的範圍時返回的值。
LEAD(box_office,1,-9999) OVER (PARTITION BY corp ORDER BY box_office) af1,
LAG(box_office,1,-9999) OVER (PARTITION BY corp ORDER BY box_office) af2
FROM film;
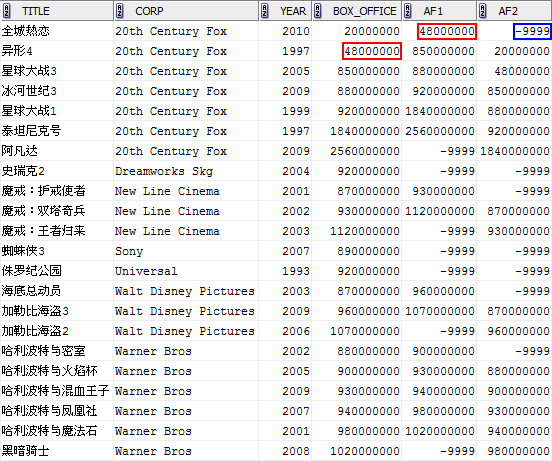
我們先來分析LEAD函式的結果,即上圖中的AF1欄位,對於同一行分割槽內,AF1欄位第N行的值 = 原BOX_OFFICE第N+1行的值,參見紅色標識部分。為什麼是N+1呢?實際這取決到我們在SQL語句中指定的offset,我們上面指定的是1。
如果偏移之後超過了分割槽的範圍,則返回函式中指定的default值,這裡我們指定的是-9999。
LAG與LEAD類似,只不過它的偏移是向前的,這點與LEAD相反。
7. FIRST_VALUE, LAST_VALUE
FIRST_VALUE返回各分割槽內指定排序後的第一條記錄的值,LAST_VALUE則返回最後一條記錄的值。
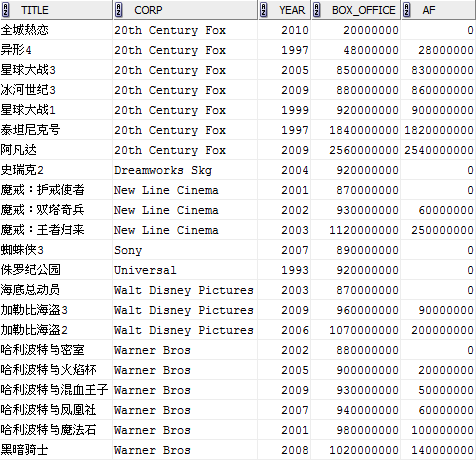
box_office-(FIRST_VALUE(box_office) OVER (PARTITION BY corp ORDER BY box_office)) af
FROM film;
8. Window子句
我們在第3節提到了分析函式中還有一個window clause,該子句為分析函式指定統計“視窗”。在前面的例子中,大多數的統計“視窗”都是整個分割槽(PARTITION),也就是說每個統計結果值都是基於相應分割槽內的所有資料計算而得。使用Window子句則可以將統計“視窗”進一步縮小,我們看一個例子:
MAX(box_office) OVER (PARTITION BY corp ORDER BY year ROWS BETWEEN 2 PRECEDING AND 1 FOLLOWING) af
FROM film;
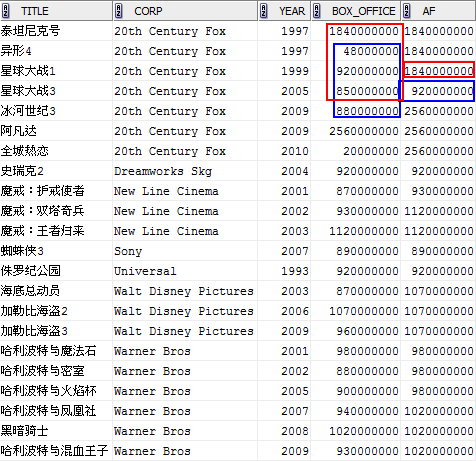
由於分析函式中給定的視窗是ROWS BETWEEN 2 PRECEDING AND 1 FOLLOWING,基本上我們可以按字面意思理解“2 Preceding”跟“1 Following”,這表示“視窗”始於當前行之前兩行,終於當前行之後一行,“視窗”大小共4行,所以我們看最後一列中紅色標識的1840000000是由第1行到第4行中求得的MAX值;而最後一列中藍色標識的920000000則是由第2行到第5行中求得的MAX值。
回過來看Window子句的具體語法:
ROWS BETWEEN <start_expr> AND <end_expr>
其中<start_expr>與<end_expr> 可能是以下形式:
(1) 1, 2, ..., N PRECEDING|FOLLOWING
(2) UNBOUNDED PRECEDING|FOLLOWING
(3) CURRENT ROW
還存在一種更簡單的語法:
ROWS 1, 2, ..., N PRECEDING 或ROWS UNBOUNDED PRECEDING
此時,統計“視窗”預設結束於當前行。
再來看一個綜合例子:
程式碼
MAX(box_office) OVER (PARTITION BY corp ORDER BY year ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) af1,
MAX(box_office) OVER (PARTITION BY corp ORDER BY year ROWS BETWEEN 2 PRECEDING AND UNBOUNDED FOLLOWING) af2,
MAX(box_office) OVER (PARTITION BY corp ORDER BY year ROWS BETWEEN 1 PRECEDING AND 2 PRECEDING) af3,
MAX(box_office) OVER (PARTITION BY corp ORDER BY year ROWS 2 PRECEDING) af4,
MAX(box_office) OVER (PARTITION BY corp ORDER BY year ROWS BETWEEN UNBOUNDED PRECEDING AND 1 FOLLOWING) af5,
MAX(box_office) OVER (PARTITION BY corp ORDER BY year ROWS BETWEEN 1 FOLLOWING AND 2 FOLLOWING) af6
FROM film;
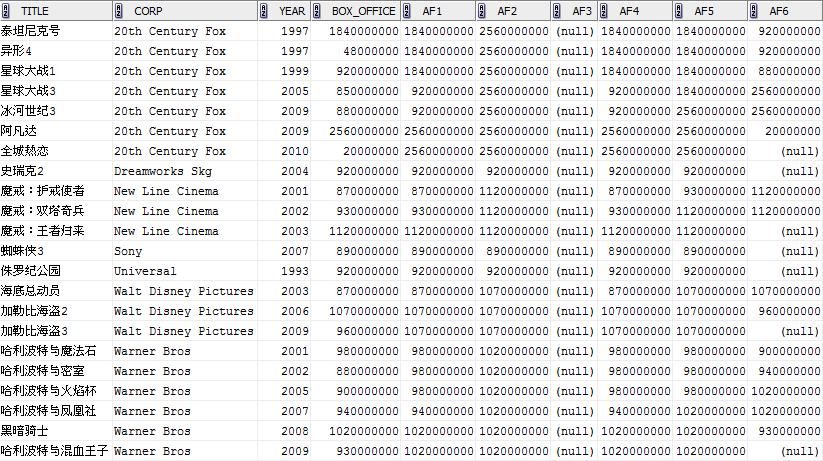
注:可以看到查詢結果中的AF3這一列是NULL值,這是因為我們在指定“視窗”的時候,<start_expr>所指向的記錄一定要位於<end_expr>之前,而產生AF3統計結果的“視窗”是ROWS BETWEEN 1 PRECEDING AND 2 PRECEDING,與要求不符,導致返回NULL。
除了上面用到的視窗子句——我們稱之為Row Type Window,還有另外一種視窗子句,叫作Range Type Window,下面我們來看一個例子:
MAX(box_office) OVER (PARTITION BY corp ORDER BY year RANGE BETWEEN 2 PRECEDING AND 1 FOLLOWING) af
FROM film;
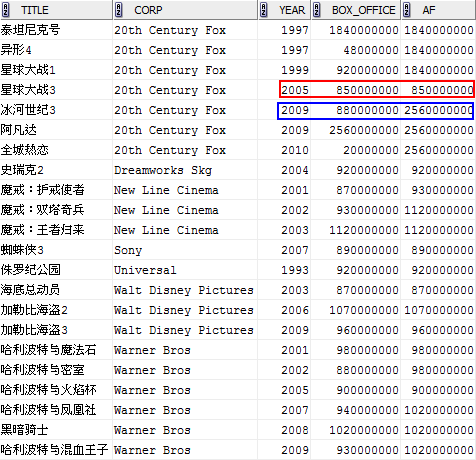
由於我們是按欄位“year”進行排序的,那麼上面的視窗就表示從當前行的年份往前2年,到當前行的年份往後1年,共4年的範圍。
比如對於上圖中紅色標識的行中,該行的視窗即[2003, 2006],由於這個時間段內只有它自己,則返回對應的BOX_OFFICE;再比如藍色標識部分,該行的視窗即[2007, 2010],返回此範圍內的最大值2560000000。
--
到這裡,文章寫完了,文章中介紹了幾個相對比較常見的分析函式,作為入門之用,其它眾多的分析函式在使用上大同小異,有興趣的同仁可以深入研究。祝閱讀愉快。