Python爬取網頁Utf-8解碼錯誤及gzip壓縮問題的解決辦法
在我們用python3爬取一些網站時,獲取網頁url後進行解析,在採用decode('utf-8')解碼時有時候會出現utf-8無法解碼的問題,比如結果會提示:
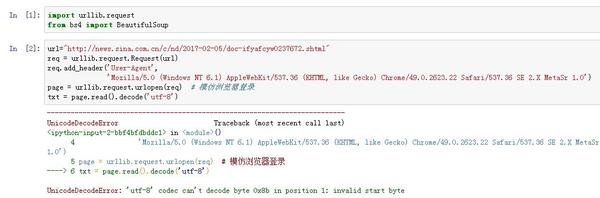
Unicode Decode Error: 'utf8' codec can't decode byte 0xb2 in position 0: invalid start byte
這是因為有些網站進行了gzip壓縮,最典型的就是sina,進行網頁爬蟲經常出現這個問題,那麼為什麼要壓縮呢?搜狗百科解釋為:
HTTP協議上的GZIP編碼是一種用來改進WEB應用程式效能的技術。大流量的WEB站點常常使用GZIP壓縮技術來讓使用者感受更快的速度。這一般是指WWW伺服器中安裝的一個功能,當有人來訪問這個伺服器中的網站時,伺服器中的這個功能就將網頁內容壓縮後傳輸到來訪的電腦瀏覽器中顯示出來.一般對純文字內容可壓縮到原大小的40%.這樣傳輸就快了,效果就是你點選網址後會很快的顯示出來.當然這也會增加伺服器的負載*. *一般伺服器中都安裝有這個功能模組的。
我們在開啟某個新浪網頁,點選右鍵選擇“檢查”,然後Network》All》Headers下的“Request Headers”中就會發現這個字樣:
Accept-Encoding:gzip, deflate, sdch
這個問題有的建議:“看一下設定的header是否存在 'Accept-Encoding':' gzip, deflate',這一句話,如果存在,刪除即可解決。”,但是有時候header不存在這個程式碼,怎麼刪除?如下,我們以開啟某個新浪新聞網頁為例:
import BeautifulSoup
url=’http://news.sina.com.cn/c/nd/2017-02-05/doc-ifyafcyw0237672.shtml’req = urllib.request.Request(url)req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0')
page = urllib.request.urlopen(req) # 模仿瀏覽器登入
txt = page.read().decode('utf-8')
soup = BeautifulSoup(txt, 'lxml')
title =soup.select('#artibodyTitle')[0].text
print(title)```
在run之後仍會出現問題,當把*decode('utf-8')*去掉後得到的頁面是亂碼的。因此,解決的辦法不是如此。
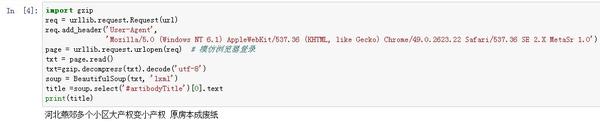
在這裡有兩種解決辦法:(1)採用gzip庫解壓網頁再解碼;(2)使用requests庫解析網頁而不是urllib。
(1)的解決辦法為:在“txt = page.read()”頁面讀取之後,再加入下面這個命令:
txt=gzip.decompress(txt).decode('utf-8')
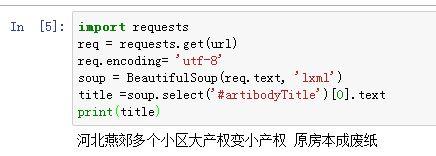
(2)的解決辦法為:
```import requests
import gzip
url="http://news.sina.com.cn/c/nd/2017-02-05/doc-ifyafcyw0237672.shtml"
req = requests.get(url)req.encoding= 'utf-8'```
這是對網頁用設定為‘utf-8’的格式,但是這裡模擬瀏覽器登入需採用這種方式:
headers = { 'Host': 'blog.csdn.net', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:43.0) Gecko/20100101 Firefox/43.0', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Language': 'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3', ….}
綜合以上,我們看一下結果:
***錯誤的方式***
***Gzip******解壓方式***
***Requests******的讀取網頁方式***
相關文章
- Python——Output not utf-8錯誤解決辦法Python
- python爬蟲爬取網頁中文亂碼問題的解決Python爬蟲網頁
- tar包解壓not in gzip format的解決辦法ORM
- 網頁上有錯誤怎麼辦 網頁錯誤的一般解決辦法網頁
- android解壓縮GZIP格式的網頁資料Android網頁
- 不可預料的壓縮檔案末端 解壓出錯的解決辦法
- 網頁證書錯誤怎麼回事 證書錯誤的解決辦法網頁
- iOS路上遇到的錯誤及解決辦法iOS
- PHP編譯錯誤及解決辦法PHP編譯
- 當前頁面指令碼發生錯誤的解決辦法指令碼
- 解決python中文編碼錯誤問題Python
- IE指令碼錯誤怎麼辦 網頁尾本錯誤解決妙招指令碼網頁
- dns錯誤怎麼辦 dns錯誤的解決辦法DNS
- 檢視網頁是否壓縮gzip+編碼方式網頁
- Jekyll 本地除錯部落格遇到的問題及解決辦法除錯
- SAP錯誤提示解決辦法
- ORA-39006錯誤原因及解決辦法
- command 'gcc' failed with exit status 1錯誤問題的解決辦法GCAI
- Sublime Text 2報 Decode error - output not utf-8 錯誤的解決辦法Error
- Sublime Text 2報“Decode error - output not utf-8”錯誤的解決辦法Error
- nginx快取配置及開啟gzip壓縮Nginx快取
- 虛擬化問題及解決辦法
- oracle壞塊問題及解決辦法Oracle
- 爬蟲常見錯誤程式碼及解決措施爬蟲
- linux下gzip的壓縮詳解Linux
- web開發技巧-網頁排版佈局常見問題及解決辦法Web網頁
- scp出現錯誤的解決辦法
- samba一個錯誤的解決辦法!Samba
- Sublime報Decode error - output not utf-8 or cp936 錯誤的解決辦法Error
- Oracle 常見的錯誤問題及解決方法Oracle
- Oracle ORA-27101錯誤及解決辦法Oracle
- 連線oracle錯誤解決辦法Oracle
- nginxFastCGI錯誤Primaryscriptunknown解決辦法NginxAST
- Unable to locate package錯誤解決辦法Package
- oracle 1455 錯誤解決辦法Oracle
- 畢設之錯誤解決辦法
- 關於 resgen.exe已退出 程式碼為 2 的錯誤問題的解決辦法。
- Oracle 錯誤總結及問題解決 ORAOracle