深度學習讀書筆記之AE(自動編碼AutoEncoder)
深度學習讀書筆記之AE
宣告:
1)該博文是整理自網上很大牛和機器學習專家所無私奉獻的資料的。具體引用的資料請看參考文獻。具體的版本宣告也參考原文獻。
2)本文僅供學術交流,非商用。所以每一部分具體的參考資料並沒有詳細對應,而且大部分內容都是直接抄NG的源部落格的,如果某部分不小心侵犯了大家的利益,還望海涵,並聯系老衲刪除或修改,直到相關人士滿意為止。
3)本人才疏學淺,整理總結的時候難免出錯,還望各位前輩不吝指正,謝謝。
4)閱讀本文需要機器學習、統計學、神經網路等等基礎(如果沒有也沒關係了,沒有就看看,當做跟同學們吹牛的本錢)。
5)此屬於第一版本,若有錯誤,還需繼續修正與增刪。還望大家多多指點。請直接回帖,本人來想辦法處理。
6)本人手上有word版的和pdf版的,不知道怎麼上傳,所以需要的話可以直接到DeepLearning高質量交流群裡要,群號由於未取得群主同意不敢公佈,需要的同學可以聯絡群主@tornadomeet
一.稀疏自編碼器
1.1一般AE使用方法
下圖是一個自編碼神經網路的示例。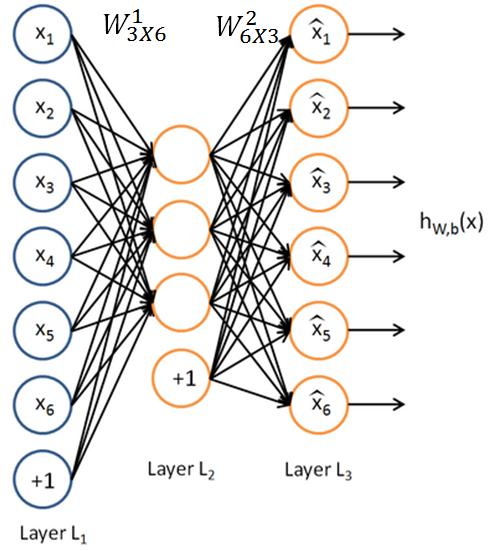
上面是一個三層的自編碼神經網路,分別有L1,L2,L3這三層。
網路經過學習以後,得到的結果是兩個矩陣和兩個偏移量,和偏移量b1、
和b2。
給定輸入x=(x1,x2,x3,x4,x5,x6),根據已知的啟用函式f1,f2,這兩個矩陣和偏移量有如下的性質:
令,從而得到y=(y1,y2,y3),其中f1是sigmoid函式,形式
再令,從而得到z=(z1,z2,z3,z4,z5,z6)其中f2是自等函式,形式f(z)=z.如果輸入資料在0和1之間,也可以用f1是sigmoid函式。
一個訓練得很好的自編碼神經網路滿足x=z。
1.2自編碼AE的意義
只對影象進行解釋。假如是一個L1層10000個節點,L2層100個節點,L3層10000個節點的AE網路,同時所有啟用函式選用sigmoid函式,那麼
用大量的圖片訓練得到

可以看到,不同的隱藏單元學會了在影象的不同位置和方向進行邊緣檢測。顯而易見,這些特徵對物體識別等計算機視覺任務是十分有用的。若將其用於其他輸入域(如音訊),該演算法也可學到對這些輸入域有用的表示或特徵。
如果輸入資料中隱含著一些特定的結構,比如某些輸入特徵是彼此相關的,那麼這一演算法就可以發現輸入資料中的這些相關性。事實上,這一簡單的自編碼神經網路通常可以學習出一個跟主元分析(PCA)結果非常相似的輸入資料的低維表示。
1.3稀疏自編碼AE的優化目標和解法
1.3.1損失函式
假設有一組s1個特徵的樣本樣本X={x1,x2,⋯,xm},經過自編碼網路在L2層和L3層分別成為Y={y1,y2,⋯,ym},Z={z1,z2,⋯,zm},其中L1層,L2層,L3層分別有節點s1,s2,s3個,則損失函式可以表示成下面的形式
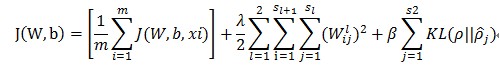
其中
β是一個超引數,控制稀疏性懲罰因子的權重,ρ也是超引數,叫做稀疏性引數。而KL的定義如下
而且是L2層的第j個節點的平均啟用度,定義如下
其中表示L2層的第j個節點在輸入為xi的時候的值.
1.3.2求解
求解步驟如下:
(1) 對於每個訓練樣本x進行迭代:
a)先計算L3層的每一個節點i的誤差
得到的結果是L3層的殘差。
再計算L2層的每一個節點i的誤差
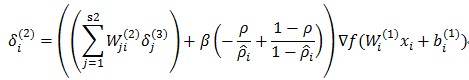
得到的結果是L2層的每個節點i的殘差
b)然後計算和
的梯度,利用上面的殘差
和和
的梯度,利用上面的殘差
c)誤差進行累計,l=1,2
(2)更新和
的權重
致謝
感謝NG的部落格,無私奉獻了這麼多資料
感謝鄧侃率領的一群人翻譯了NG的部落格的所有內容,讓我等小白能看懂。
Deep Learning高質量交流群裡的多位同學:@廈大_影象_風淳 ,@羅傑 ,@Wilbur
參考文獻
[1]http://deeplearning.stanford.edu/wiki/index.php/UFLDL%E6%95%99%E7%A8%8B NG的部落格,鄧侃翻譯版
from: http://blog.csdn.net/mytestmy/article/details/16918641
相關文章
- 深度學習讀書筆記之RBM深度學習筆記
- 『TensorFlow』讀書筆記_降噪自編碼器筆記
- 《學習之道》讀書筆記筆記
- [原始碼解析]深度學習利器之自動微分(3) --- 示例解讀原始碼深度學習
- 《如何高效學習》讀書筆記筆記
- webpack 學習筆記:實戰之 babel 編碼Web筆記Babel
- 《數學之美》讀書筆記&思考筆記
- 讀書筆記(四):深度學習基於Keras的Python實踐筆記深度學習KerasPython
- 深度學習利器之自動微分(1)深度學習
- 深度學習利器之自動微分(2)深度學習
- 編譯原理讀書筆記編譯原理筆記
- 讀書筆記之五筆記
- Keras上實現AutoEncoder自編碼器Keras
- AC自動機學習筆記筆記
- AC 自動機學習筆記筆記
- C語言深度剖析——讀書筆記C語言筆記
- 深度學習聖經“花書”各章摘要與筆記整理深度學習筆記
- 深度學習keras筆記深度學習Keras筆記
- 深度學習 筆記一深度學習筆記
- 用深度學習自動生成HTML程式碼深度學習HTML
- TensorFlow上實現AutoEncoder自編碼器
- 【C語言深度剖析】讀書筆記之 signed ,unsignedC語言筆記
- Deep Learning(深度學習)學習筆記整理系列之(一)深度學習筆記
- JVM讀書筆記之OOMJVM筆記OOM
- 浪潮之巔讀書筆記筆記
- 【筆記】動手學深度學習-預備知識筆記深度學習
- 字尾自動機學習筆記筆記
- Redux 學習筆記 – 原始碼閱讀Redux筆記原始碼
- Redux 學習筆記 - 原始碼閱讀Redux筆記原始碼
- 《深度探索C++物件模型》讀書筆記C++物件模型筆記
- 表驅動法 -《程式碼大全》讀書筆記筆記
- 彙編學習筆記之轉移指令筆記
- JVM學習筆記——自動記憶體管理JVM筆記記憶體
- JNI學習筆記之AS+ndk+gradle自動編譯出so並整合流程筆記Gradle編譯
- 讀書筆記-增量學習-Large Scale Incremental Learning筆記REM
- 【讀書筆記】Android的Ashmem機制學習筆記Android
- 《從陷阱中學習C/C++》讀書筆記C++筆記
- 【讀書1】【2017】MATLAB與深度學習——深度學習(2)Matlab深度學習